text-to-image太火,tiktok都直接在app里面上线了,必须跟近形式
昨天Stable Diffusion模型被放出来之后,找时间试了试快速试了试,效果比disco diffusion/latent diffusion好了一大截,同样的prompt出的图明显看出SD模型更懂语义,图能更consistent(当然也还是有很多不成样的图)。同时发现速度巨快,在我的36核台式机上纯用CPU都只需要75秒左右就能出一张512x512,需要内存不过7-8G。于是把之前搞的prompts全堆上一天画了700多张图,cherrypick几张看看

应该是某个外星

画人始终是个挑战,不论哪个模型,尤其是脸和手,背面避开了最难的地方

军舰的后半段没了,前面还有点意思

有点油画的意思

金字塔工地还蛮宏大

伊甸园? 远景避开了画人的尴尬

somewhere I want to live

有点霸气,但是脑勺后面的东西不太对

梵高style,屋顶有点不太对

莫奈style

破坏小黄人

赌博兔having fun

有点萌的老虎玩具

这马画的不错

萌版stormtrooper,手还是不行,像截肢了一样

眼睛有时候也是问题,一只好的,一只不行

meow
虽然跟Imagen/Parti对比还有差距,总体来说已经有了很大进步,不过总还是有细节不太对,希望能很快支持in-painting,这样还可以修补
今天还花了一下午写了个简陋的桌面前端,这样如果有算力不错的机器就不用去Hugging Face上去排队了
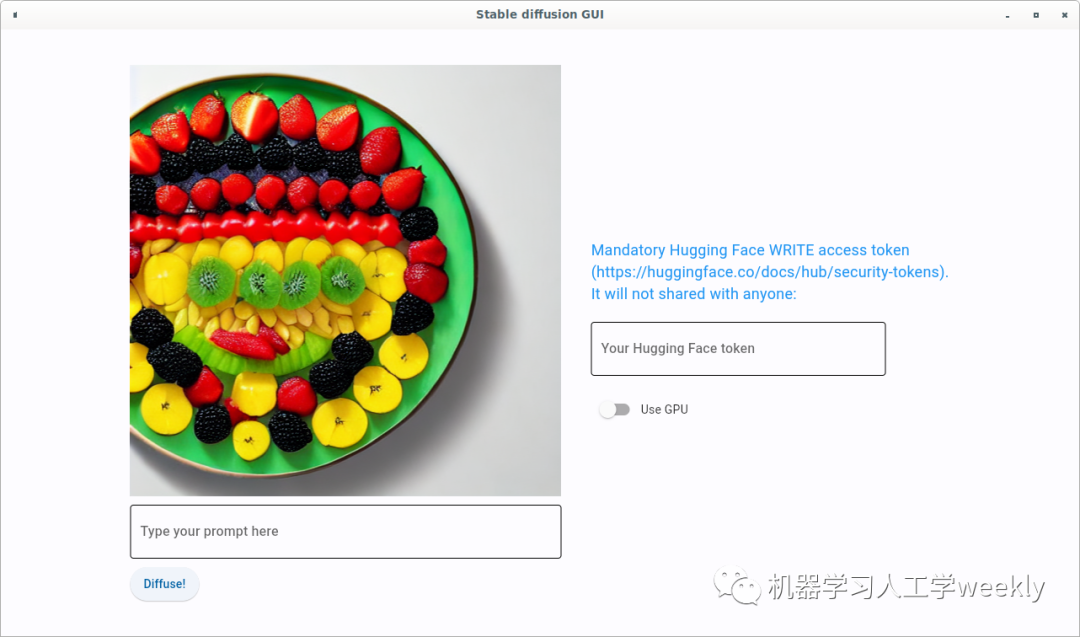
目前能跑,可能明天先扔个v0.1到GitHub上吧,后续再探索做prompt自动生成什么的。prompt engineering真是太重要了,现在越发觉得最大的瓶颈是prompt,在出图如此快的情况下,如何找到好的prompt成为关键,新的炼丹术。所以才会有PromptBase这样的网站进行prompt售卖