一、Python处理大数据集的痛点
Python是数据分析最好的工具之一,像pandas、numpy、matplotlib等都是Python生态的数据分析利器,但处理大数据集是Python的一大痛点,特别是你在本地电脑进行IO操作时非常慢,像pandas读取上G的文件就得几分钟。
我之前参加过一个交通类的数据科学比赛,主办方让参赛者从官网下载几十G的原始CSV文件,这些数据存在电脑里,然后通过Python来读取、清洗、可视化、建模,每一步都很慢,当时用了多线程、分块读取等各种方法才勉强完成比赛。
当然市面上很多工具可以提升数据处理的效率,比如Pyspark、Modin、Polars等,确实提升不少,但依旧受限于电脑的内存和性能限制。
二、使用下秒数据机器人实现大数据集ETL
既然本地电脑不行,那就只能上云,我的需求是云工具必须要能快速存取数据,且支持SQL查询和Python调用,这样既能在云上完成SQL数据清洗,还能通过Python调用API实现数据抽取。
最近刚好发现了这样一个工具-下秒数据机器人,不光支持大数据集快速上传、SQL查询、Python API调用,还能实现AI数据问答、自助分析等功能,非常方便。

a) 数据集导入
下秒数据机器人支持CSV、Excel、XML、Json及各种数据库等数据导入
下秒数据机器人网站链接:
http://nexadata.cn/mobileSetMessage
如果对数据导入有问题,可以联系下秒的技术支持
b) SQL数据查询
数据导入过程中可以使用SQL进行数据清洗,也可以查询已经导入的数据集

c) Python API调用
几行代码就可以实现Python API数据读取,还支持Java、Javascript、PHP语言调用,再也不用纠结本地电脑内存了。

d) AI数据问答
通过文本提问形式,实现数据的分析和提取

e) 自助分析
下秒数据机器人还提供了各种自助分析的工具,像文本自动分类、ABC分析、留存分析等,无需代码也能分析数据。

三、案例:探索分析葡萄酒质量
有了这个云ETL工具后,用Python来分析数据就方便很多,一方面大数据集可以快速上传和调用,另一方面直接从云上取数,不依赖终端设备,并且你的很多数据处理工作都可以在云上完成,Python取数后直接可以分析和建模。
下面用葡萄酒质量数据集来演示下如何使用下秒数据机器人来存储数据,并使用Python调用接口来进行数据分析。
葡萄酒数据是经典的kaggle比赛数据集,通过葡萄酒各种化学指标来评估葡萄酒的质量,非常具有分析价值。

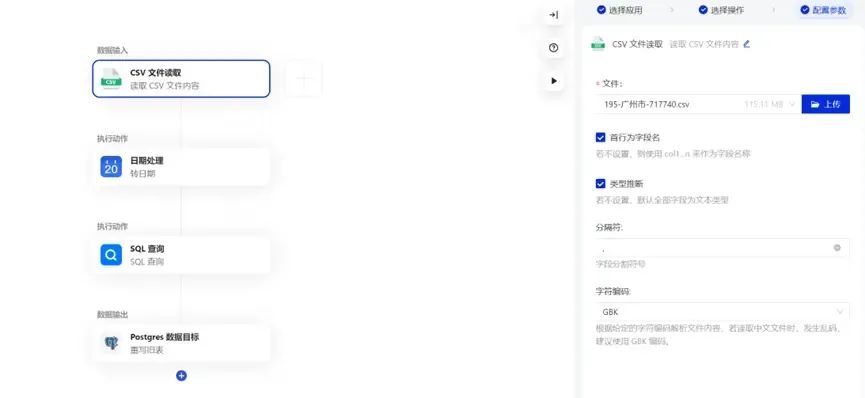
a) 上传数据
直接将葡萄酒数据集csv文件上传到下秒数据机器人平台

上传完成保存后,便建立了一个数据流程任务,然后再构建数据视图,我们便可以使用Python API调用这个数据集。

b) 调用API数据
数据视图有API调用功能,提供了各种编程语言示例代码,我们复制Python示例代码到编辑器里,填好taken便可以调用数据了。

数据取出来是json格式,可以把数据读成pandas dataframe格式,方便查看分析。
import pandas as pd
import requests
# 导入数据,使用下秒机器人存储数据,通过API调用
headers = { "x-token": "tkb31a7c693c8341a8b47e9ce4e32184e9" }
response = requests.get("http://demo.chafer.nexadata.cn/openapi/v1/sheet/sht21JULR9CANs/records?size=500&page=1", headers = headers)
data = response.json()['data']['list']
data = pd.DataFrame(data).astype(float)
data

c) 数据探索可视化分析
接下来就是数据分析过程,使用Python pandas和matplotlib对葡萄酒数据集进行可视化分析。
数据分析的核心目标是评估葡萄酒的质量,评估哪些特征对葡萄酒的品质影响最大,以及葡萄酒不同特征之间有无相关性。
首先查看数据集的描述性统计,像平均值、方差等,观察数据的分布情况
# 查看数据集的描述统计
data.describe()[1:].T.style.background_gradient(cmap='Blues')

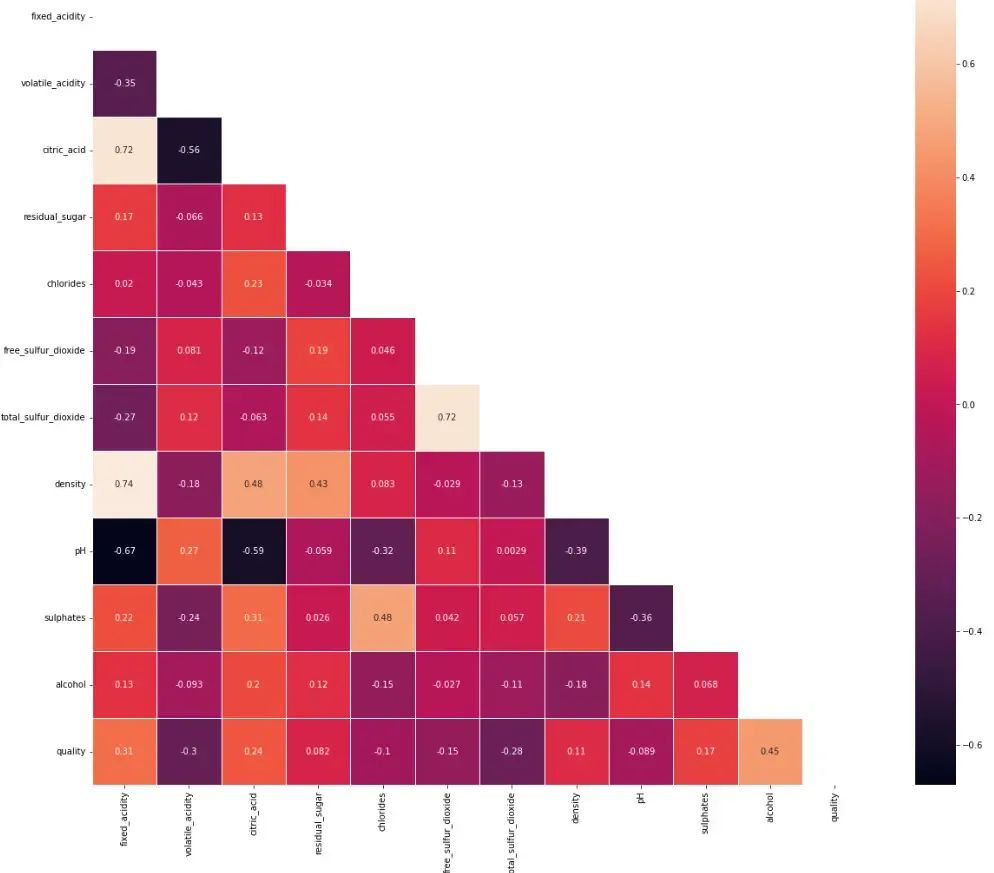
其次各个特征之间的相关性关系,通过颜色深浅可以看出不同特征间的相关关系。
import matplotlib.pyplot as plt
# 查看相关系数
plt.figure(figsize=(20, 17))
matrix = np.triu(data.corr())
sns.heatmap(data.corr(), annot=True,
linewidth=.8, mask=matrix, cmap="rocket")
plt.show()
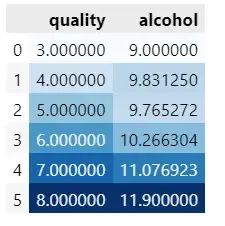
最后查看葡萄酒不同质量情况下,酸度等其他指标的平均值,来判定葡萄酒各指标对质量的影响。
# fixed acidity - quality两者关系
data[["fixed_acidity","quality"]].groupby(["quality"], as_index = False).mean().sort_values(by = "quality").style.background_gradient("Blues")

# fixed acidity - quality两者关系
data[["alcohol","quality"]].groupby(["quality"], as_index = False).mean().sort_values(by = "quality").style.background_gradient("Blues")
# fixed acidity - quality两者关系
data[["pH","quality"]].groupby(["quality"], as_index = False).mean().sort_values(by = "quality").style.background_gradient("Blues")

这里对葡萄酒质量数据做了简单的可视化探索,还有很多东西可以挖掘,比如口感较甜的葡萄酒是否质量更好?什么样酒精度的葡萄酒质量最好?什么样PH值的葡萄酒质量最好等等?
我把数据集和完整代码放在下秒数据机器人网站里,大家可以点击阅读原文去亲自试一试如何操作。
四、总结
对于经常使用Python做数据分析和建模的同学来说,像下秒数据机器人这样的云数据ETL有很多便捷之处,不用担心大数据读取慢,也不用担心换设备没数据可用,你可以专心做分析。