上一篇博客,已经为大家介绍了基于RFM(用户价值模型)的挖掘型标签开发过程(?大数据【企业级360°全方位用户画像】基于RFM模型的挖掘型标签开发),本篇博客,我们来学习基于RFE(用户活跃度模型)的挖掘型标签开发。

RFE模型引入
在正式开始实现需求之前,肯定要给各位朋友们解释下。RFE模型可以说是RFM模型的变体 。RFE模型基于用户的普通行为(非转化或交易行为)产生,它跟RFM类似都是使用三个维度做价值评估。
RFE详解
RFE 模型是根据会员最近一次访问时间R( Recency)、访问频率 F(Frequency)和页面互动度 E(Engagements)计算得出的RFE得分。 其中:- 最近一次访问时间 R( Recency): 会员最近一次访问或到达网站的时间。
- 访问频率 F( Frequency):用户在特定时间周期内访问或到达的频率。
- 页面互动度 E( Engagements):互动度的定义可以根据不同企业或行业的交互情况而定,例如可以定义为页面 浏览时间、浏览商品数量、视频播放数量、点赞数量、转发数量等 。
在RFE模型中,由于不要求用户发生交易,因此可以做未发生登录、 注册等匿名用户的行为价值分析, 也可以做实名用户分析。该模型常用来做用户活跃分群或价值区分, 也可用于内容型(例如论坛、新闻、资讯等)企业的会员分析。 RFM和 RFE模型的实现思路相同, 仅仅是计算指标发生变化。 对于RFE的数据来源, 可以从企业自己监控的用户行为日志获取,也可以从第三方网站分析工具获得。基于RFE模型的实践应用
在得到用户的RFE得分之后, 跟 RFM 类似也可以有两种应用思路: 1:基于三个维度值做用户群体划分和解读,对用户的活跃度做分析。 RFE得分为 313 的会员说明其访问频率低, 但是每次访问时的交互都非常不错, 此时重点要做用户回访频率的提升,例如通过活动邀请、 精准广告投放、会员活动推荐等提升回访频率。 2:基于RFE的汇总得分评估所有会员的活跃度价值,并可以做活跃度排名; 同时,该得分还可以作为输入维 度跟其他维度一起作为其他数据分析和挖掘模型的输入变量,为分析建模提供基础。 比如:- 6忠诚 (1天内访问2次及以上,每次访问页面不重复)
- 5活跃 (2天内访问至少1次)
- 4回流 (3天内访问至少1次)
- 3新增 (注册并访问)
- 2不活跃 (7天内未访问)
- 1流失 (7天以上无访问)
具体代码实现
大家看到这里,应该都发现了,RFE模型和之前我们介绍过的RFM模型非常类似,只不过一个是用户价值模型,一个是用户活跃度模型。 因为同为挖掘型标签的开发,所以流程上大部分的内容都是相似的,下面博主就不详细分步骤介绍了?,关于代码中有任何的疑惑,可以私信联系我哟~import com.czxy.base.BaseModel import org.apache.spark.ml.clustering.{KMeans, KMeansModel} import org.apache.spark.ml.feature.VectorAssembler import org.apache.spark.sql.expressions.UserDefinedFunction import org.apache.spark.sql.{Column, DataFrame, SparkSession, functions}import scala.collection.immutable
/*
@Author: Alice菌
@Date: 2020/6/24 08:25
@Description:
用户的活跃度标签开发*/
object RFEModel extends BaseModel{override def setAppName: String = "RFEModel"
override def setFourTagId: String = "176"
override def getNewTag(spark: SparkSession, fiveTagDF: DataFrame, hbaseDF: DataFrame): DataFrame = {
// 展示MySQL的五级标签数据 fiveTagDF.show() //+---+----+ //| id|rule| //+---+----+ //|177| 1| //|178| 2| //|179| 3| //|180| 4| //+---+----+ // 展示HBase中的数据 hbaseDF.show(false) //+--------------+--------------------+-------------------+ //|global_user_id| loc_url| log_time| //+--------------+--------------------+-------------------+ //| 424|http://m.eshop.co...|2019-08-13 03:03:55| //| 619|http://m.eshop.co...|2019-07-29 15:07:41| //| 898|http://m.eshop.co...|2019-08-14 09:23:44| //| 642|http://www.eshop....|2019-08-11 03:20:17| //RFE三个单词 //最近一次访问时间R val recencyStr: String = "recency" //访问频率 F val frequencyStr: String = "frequency" //页面互动度 E val engagementsStr: String = "engagements" // 特征单词 val featureStr: String = "feature" // 向量 val predictStr: String = "predict" // 分类 // 计算业务数据 // R(会员最后一次访问或到达网站的时间) // F(用户在特定时间周期内访问或到达的频率) // E(页面的互动度,注意:一个页面访问10次,算1次) // 引入隐式转换 import spark.implicits._ //引入java 和scala相互转换 import scala.collection.JavaConverters._ //引入sparkSQL的内置函数 import org.apache.spark.sql.functions._ /* 分别计算 R F E 的值 */ // R 计算 最后一次浏览距今的时间 val getRecency: Column = datediff(current_timestamp(),max("log_time")) as recencyStr // F 计算 页面访问次数(一个页面访问多次,就算多次) val getFrequency: Column = count("loc_url") as frequencyStr // E 计算 页面互动度(一个页面访问多次,只计算一次) val getEngagements: Column = countDistinct("loc_url") as engagementsStr val getRFEDF: DataFrame = hbaseDF.groupBy("global_user_id") .agg(getRecency, getFrequency, getEngagements) getRFEDF.show(false) //+--------------+-------+---------+-----------+ //|global_user_id|recency|frequency|engagements| //+--------------+-------+---------+-----------+ //|296 |312 |380 |227 | //|467 |312 |405 |267 | //|675 |312 |370 |240 | //|691 |312 |387 |244 | //现有的RFM 量纲不统一,需要执行归一化 为RFM打分 //计算R的分数 val getRecencyScore: Column = when(col(recencyStr).between(0,15), 5) .when(col(recencyStr).between(16,30), 4) .when(col(recencyStr).between(31,45), 3) .when(col(recencyStr).between(46,60), 2) .when(col(recencyStr).gt(60), 1) .as(recencyStr) //计算F的分数 val getFrequencyScore: Column = when(col(frequencyStr).geq(400), 5) .when(col(frequencyStr).between(300,399), 4) .when(col(frequencyStr).between(200,299), 3) .when(col(frequencyStr).between(100,199), 2) .when(col(frequencyStr).leq(99), 1) .as(frequencyStr) //计算E的分数 val getEngagementScore: Column = when(col(engagementsStr).geq(250), 5) .when(col(engagementsStr).between(200,249), 4) .when(col(engagementsStr).between(150,199), 3) .when(col(engagementsStr).between(50,149), 2) .when(col(engagementsStr).leq(49), 1) .as(engagementsStr) // 计算 RFE 的分数 val getRFEScoreDF: DataFrame = getRFEDF.select('global_user_id ,getRecencyScore,getFrequencyScore,getEngagementScore) getRFEScoreDF.show(false) //+--------------+-------+---------+-----------+ //|global_user_id|recency|frequency|engagements| //+--------------+-------+---------+-----------+ //|296 |1 |4 |4 | //|467 |1 |5 |5 | //|675 |1 |4 |4 | //|691 |1 |4 |4 | //|829 |1 |5 |5 | // 为了方便计算,我们将数据转换成向量 val RFEFeature: DataFrame = new VectorAssembler() .setInputCols(Array(recencyStr, frequencyStr, engagementsStr)) .setOutputCol(featureStr) .transform(getRFEScoreDF) RFEFeature.show()//+--------------+-------+---------+-----------+-------------+
//|global_user_id|recency|frequency|engagements| feature|
//+--------------+-------+---------+-----------+-------------+
//| 296| 1| 4| 4|[1.0,4.0,4.0]|
//| 467| 1| 5| 5|[1.0,5.0,5.0]|
//| 675| 1| 4| 4|[1.0,4.0,4.0]|
//| 691| 1| 4| 4|[1.0,4.0,4.0]|// 利用KMeans算法,进行数据的分类 val KMeansModel: KMeansModel = new KMeans() .setK(4) // 设置4类 .setMaxIter(5) // 迭代计算5次 .setFeaturesCol(featureStr) // 设置特征数据 .setPredictionCol(predictStr) // 计算完毕后的标签结果 .fit(RFEFeature) // 将其转换成DF val KMeansModelDF: DataFrame = KMeansModel.transform(RFEFeature) KMeansModelDF.show() //+--------------+-------+---------+-----------+-------------+-------+ //|global_user_id|recency|frequency|engagements| feature|predict| //+--------------+-------+---------+-----------+-------------+-------+ //| 296| 1| 4| 4|[1.0,4.0,4.0]| 1| //| 467| 1| 5| 5|[1.0,5.0,5.0]| 0| //| 675| 1| 4| 4|[1.0,4.0,4.0]| 1| //| 691| 1| 4| 4|[1.0,4.0,4.0]| 1| // 计算用户的价值 val clusterCentersSum: immutable.IndexedSeq[(Int, Double)] = for(i <- KMeansModel.clusterCenters.indices) yield (i,KMeansModel.clusterCenters(i).toArray.sum) val clusterCentersSumSort: immutable.IndexedSeq[(Int, Double)] = clusterCentersSum.sortBy(_._2).reverse clusterCentersSumSort.foreach(println) //(0,11.0) //(3,10.0) //(2,10.0) //(1,9.0) // 获取到每种分类以及其对应的索引 val clusterCenterIndex: immutable.IndexedSeq[(Int, Int)] = for(a <- clusterCentersSumSort.indices) yield (clusterCentersSumSort(a)._1,a) clusterCenterIndex.foreach(println) //(0,0) //(3,1) //(2,2) //(1,3) // 类别的价值从高到低,角标依次展示 // 将其转换成DF val clusterCenterIndexDF: DataFrame = clusterCenterIndex.toDF(predictStr,"index")clusterCenterIndexDF.show()
//+-------+-----+
//|predict|index|
//+-------+-----+
//| 0| 0|
//| 3| 1|
//| 2| 2|
//| 1| 3|
//+-------+-----+// 开始join val JoinDF: DataFrame = fiveTagDF.join(clusterCenterIndexDF,fiveTagDF.col("rule") === clusterCenterIndexDF.col("index")) JoinDF.show() //+---+----+-------+-----+ //| id|rule|predict|index| //+---+----+-------+-----+ //|177| 0| 0| 0| //|178| 1| 3| 1| //|179| 2| 2| 2| //|180| 3| 1| 3| //+---+----+-------+-----+ val JoinDFS: DataFrame = JoinDF.select(predictStr,"id") //fiveTageListval fiveTageMap: Map[String, String] = JoinDFS.as[(String,String)].collect().toMap
//7、获得数据标签(udf) // 需要自定义UDF函数 val getRFMTags: UserDefinedFunction = udf((featureOut: String) => { fiveTageMap.get(featureOut) }) val CustomerValueTag: DataFrame = KMeansModelDF.select('global_user_id .as("userId"),getRFMTags('predict).as("tagsId")) //CustomerValueTag.show(false) //|userId|tagsId| //+------+------+ //|296 |180 | //|467 |177 | //|675 |180 | //|691 |180 | //|829 |177 | //|125 |180 | //|451 |180 | //|800 |180 | //|853 |179 | CustomerValueTag}
def main(args: Array[String]): Unit = {
exec()
}
}
知识拓展
这里问大家一个问题,我们在调用K-Means算法进行聚类计算的时候,需要先设定一个K值,那么这个K值具体是多少是如何得到的呢?
就拿本题来说,如果你觉得我们在标签系统中人为地划分成了四类,所以在进行聚类计算的时候,就把K设置成了4的话,那就理解错了。
大多数情况下,我们是无法预先确定K值的大小,所以有认真看过之前介绍机器学习常见面试题的朋友(?关于机器学习的面试题,你又了解多少呢?),肯定对于肘部法则有一定的印象。 手肘法的核心指标是 集合内误差平方和:Within Set Sum of Squared Error, WSSSE 或者叫SSE(sum of the squared errors,误差平方和),公式为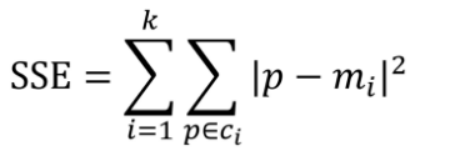
本次所开发的标签,为什么K = 4 呢,接下俩,让我们用代码来讲道理!
我们在原有代码的基础上,添加上这几行代码,然后运行程序,等待结果。 var SSE: String =""
//4 数据分类(不知道哪个类的活跃度高和低)
for(k<-2 to 9){
val model: KMeansModel = new KMeans()
.setK(k)
.setMaxIter(5)
.setSeed(10)
.setFeaturesCol(featureStr)
.setPredictionCol(predictStr)
.fit(RFEFeature)
SSE=k+"-"+model.computeCost(RFEFeature)
println(SSE)
}</code></pre></div></div><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>txt</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-txt"><code class="language-txt" style="margin-left:0"> 友情提示:运行的过程可能非常漫长。为啥勒,毕竟一次KMeans 计算就够久的了,而这个循环要计算8次…</code></pre></div></div><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:38.27%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723194002385273710.jpeg" /></div></div></div></figure><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>txt</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-txt"><code class="language-txt" style="margin-left:0"> 不出所料,经过了N秒之后的等待,终于有了下面的结果。</code></pre></div></div><blockquote><p> 2-185.03108672935983
3-23.668965517242555
4-0.0
5-0.0
6-0.0
7-0.0
8-0.0
9-0.0
代码语言:txt复制 其实看到这里,已经很清楚拐点就是在K = 4 的时候了。但是如果你跟我说莫得办法,看不出来,菌哥还是有妙招!!!
代码语言:txt复制 为了让数据更有画面感,菌哥打开了很久没上号的Echars?,为大家带来了下面的简单小图。
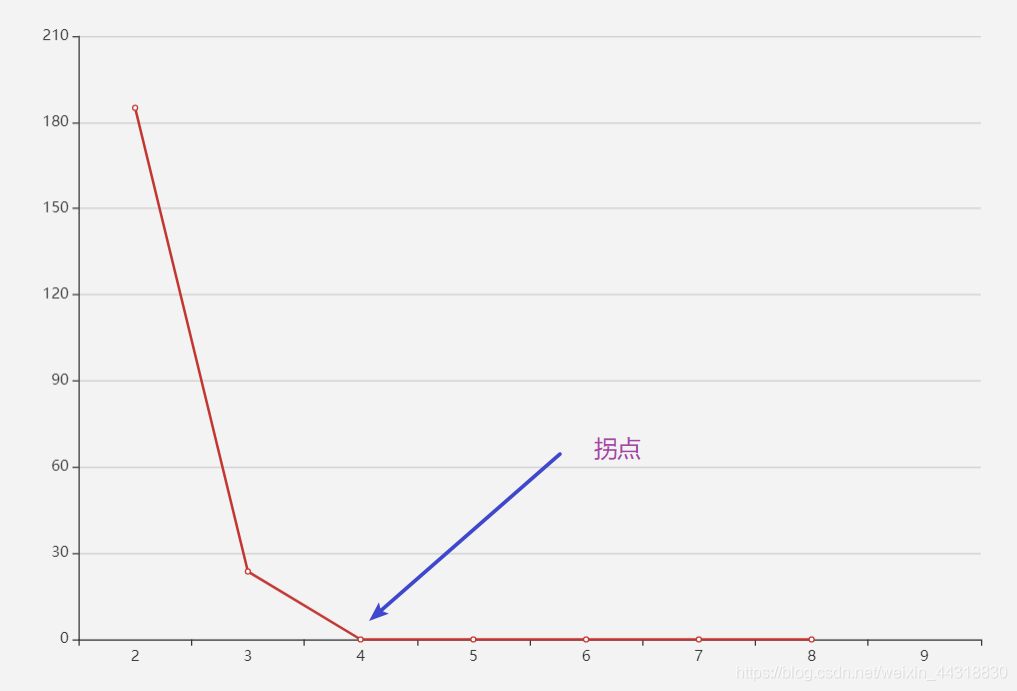
相信看到这里,大家一定没有疑问了吧~
小结
如果以上过程中出现了任何的纰漏错误,烦请大佬们指正?
受益的朋友或对大数据技术感兴趣的伙伴记得点赞关注支持一波?
希望我们都能在学习的道路上越走越远?