目标网址:
代码语言:javascript
复制
https://mm.enterdesk.com/dalumeinv/1.html
进入网站后下拉即可看到以下内容:

点击任意图片,进入图片详情页,里面为一组图片,包含大图和缩略图:

此网页禁止鼠标右键,按ctrl+u进行查看网页源代码,发现图片链接可在网页源代码中获取;每张图片有两条链接,对比两条链接发现其中一条多了参数_360_360,而没有此参数的链接为高清原图,另一条为标清图!
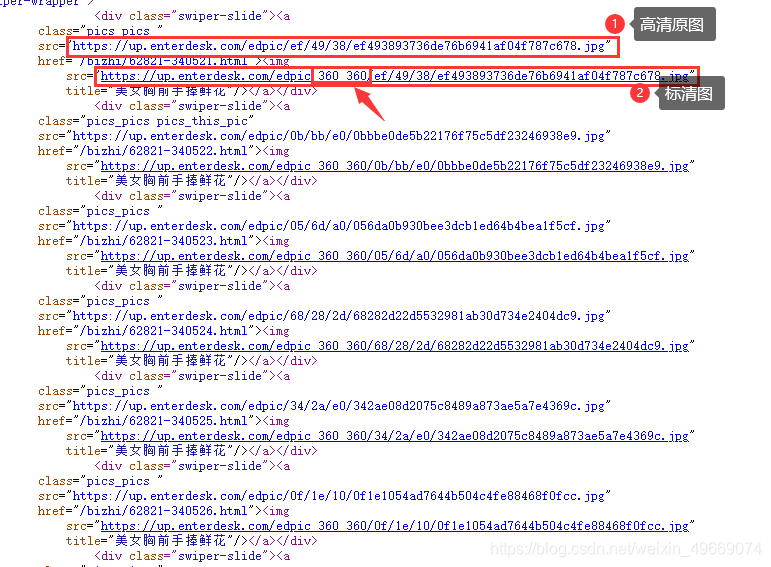
详情页是由首页链接进入的,我们再退到首页,按ctrl+u进行查看网页源代码;发现网页源代码中存在进入详情页的链接,由此可推断首页和详情页都为静态加载的网页!

在首页下拉网页,发现其会不断加载数据,但网址却没有发生变化:

但单独点击下方翻页操作,网址会发生变化:

由此可见,进行翻页操作我们只需要更改网址的参数即可:
代码语言:javascript
复制
https://mm.enterdesk.com/dalumeinv/1.html
https://mm.enterdesk.com/dalumeinv/2.html
https://mm.enterdesk.com/dalumeinv/3.html
爬取代码基本和以前所讲解的差不多,本文仅给出核心代码:
代码语言:javascript
复制
def main(html_url): # 传入首页url
response = get_response(html_url) # 请求函数接收首页url并请求数据
urls = re.findall('<a href="(.*?)" target="_blank">.*?</a>', response.text)[31:47] # 提取详情页url
for link in urls:
response_ = get_response(link)# 请求函数接收详情页url并请求数据
image_url = re.findall('src="(https://up.enterdesk.com/edpic/.*?)"', response_.text)[1:] # 提取图片url
url_data(image_url) # 返回图片url
urls这一行[31:47]以及image_url这一行之所以用进行切片,是因为正则表达式提取的内容包含其它一些链接,所以需要去除:

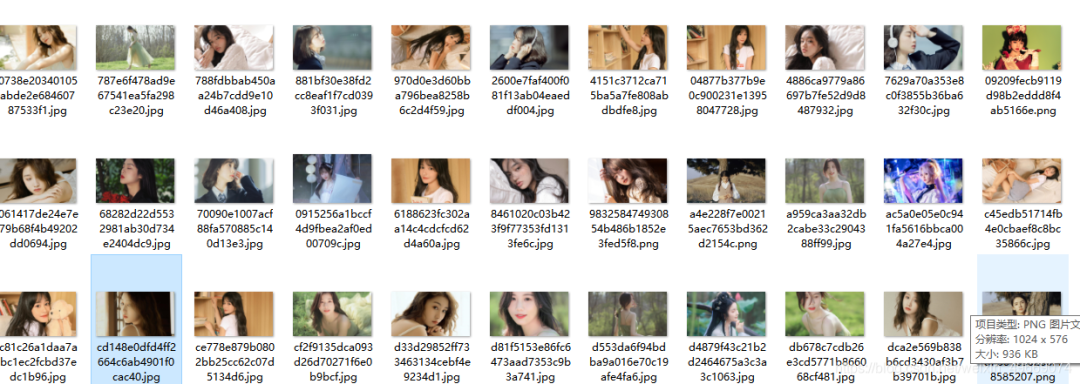
图片展示:
结语:
- 本文图片以及文本仅供学习、交流使用,不做商业用途,如有问题请及时联系我们以作处理。提供的结论仅供参考,还请独立思考。