首先讨论多标签分类数据集(以及如何快速构建自己的数据集)。
之后简要讨论SmallerVGGNet,我们将实现的Keras神经网络架构,并用于多标签分类。
然后我们将实施SmallerVGGNet并使用我们的多标签分类数据集对其进行训练。
最后,我们将通过在示例图像上测试我们的网络,并讨论何时适合多标签分类,包括需要注意的一些注意事项。
数据集包含六个类别的2,167个图像,包括:
黑色牛仔裤(344图像) 蓝色连衣裙(386图像) 蓝色牛仔裤(356图像) 蓝色衬衫(369图像) 红色连衣裙(380图像) 红色衬衫(332图像)
6类图像数据可以通过python爬虫在网站上抓取得到。

为了方便起见,可以通过使用Bing图像搜索API(Microsoft’s Bing Image Search API)建立图像数据(需要在线注册获得api key,使用key进行图像搜索),python代码:


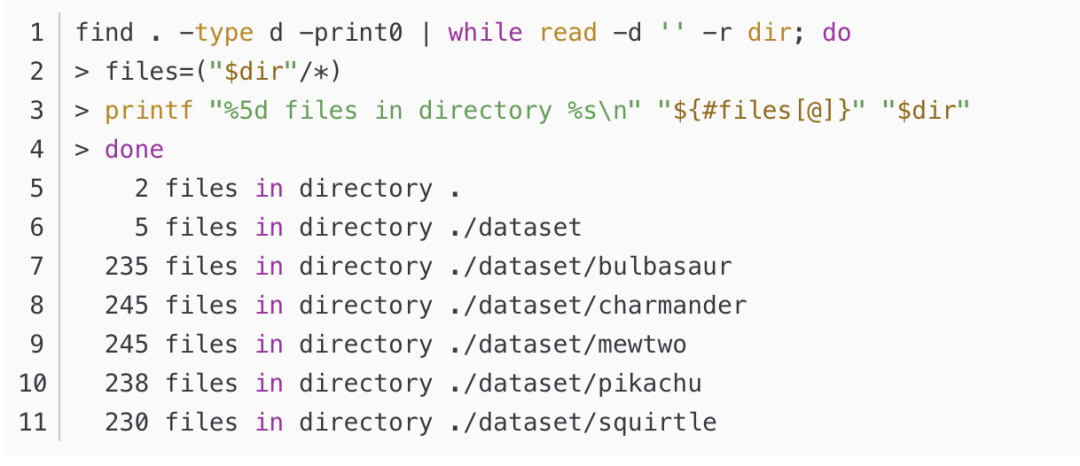
使用find方法得到下载的图像数据数目
多标签分类multi-label classsification
这里给出的是项目的文件结构

多标签分类的网络结构--smallervggnet【Very Deep Convolutional Networks for Large Scale Image Recognition.】
https://arxiv.org/pdf/1409.1556/
smallervggnet.py
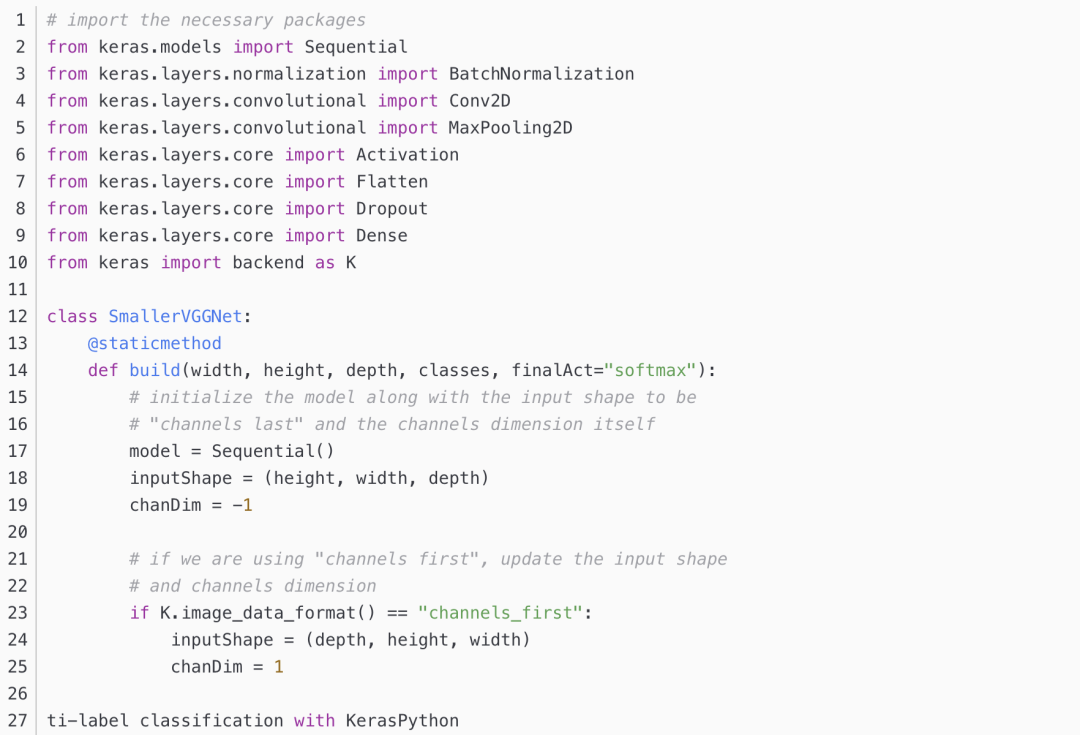


train.py
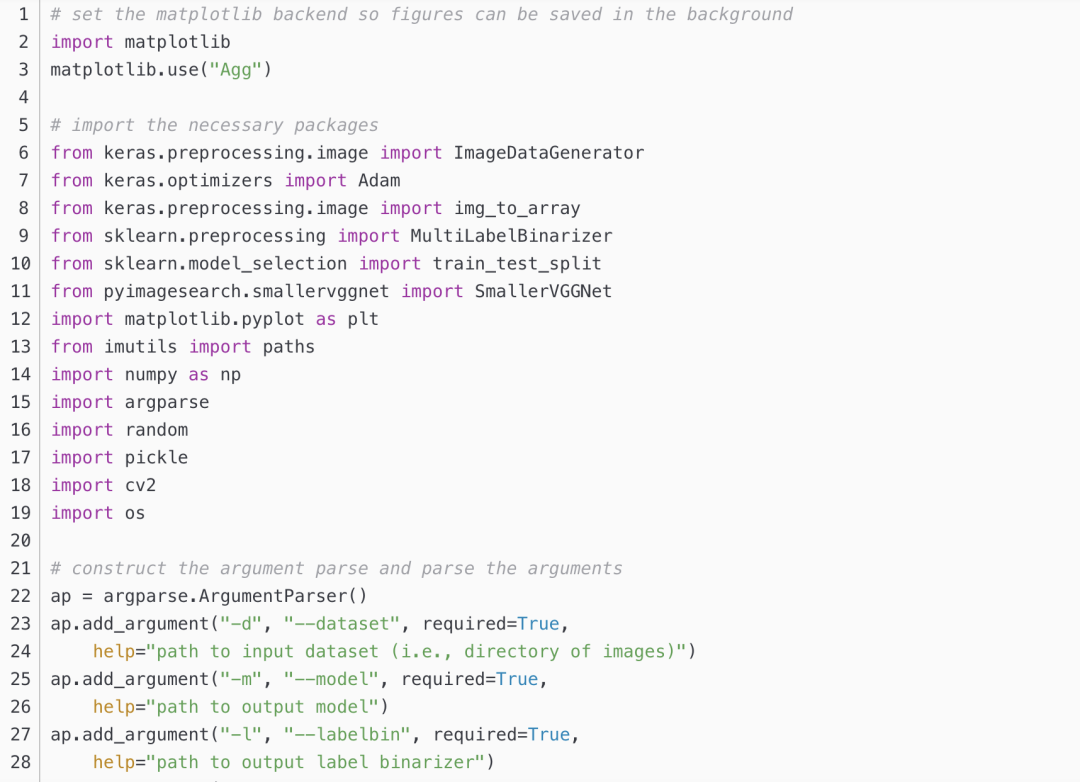


run

继续preprocessing
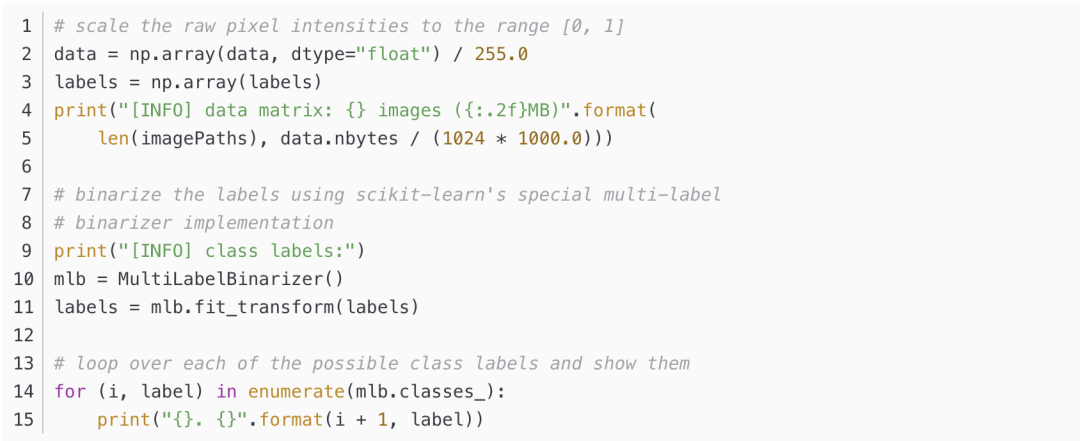
run

构建训练和测试数据集,做数据增强

构建模型,初始化Adam优化器
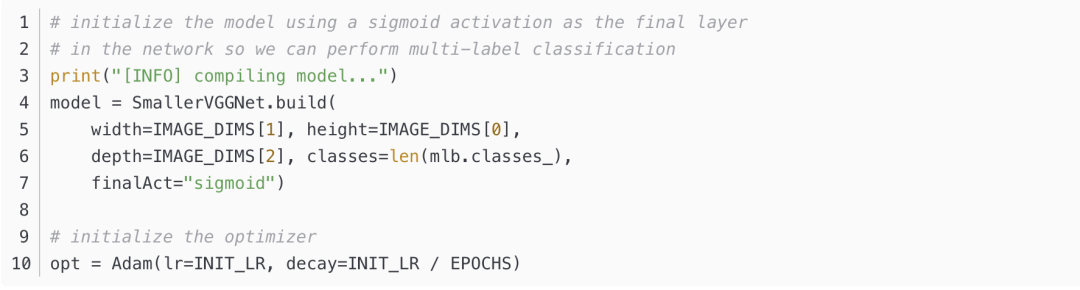
编译模型,开始训练

训练后保存模型,并二值化标签

绘制出acc,loss

绘制好的结果会保存成图片格式保存。
多标签分类模型训练
python train.py --dataset dataset --model fashion.model --labelbin mlb.pickle使用训练完成的模型预测新的图像
classify.py

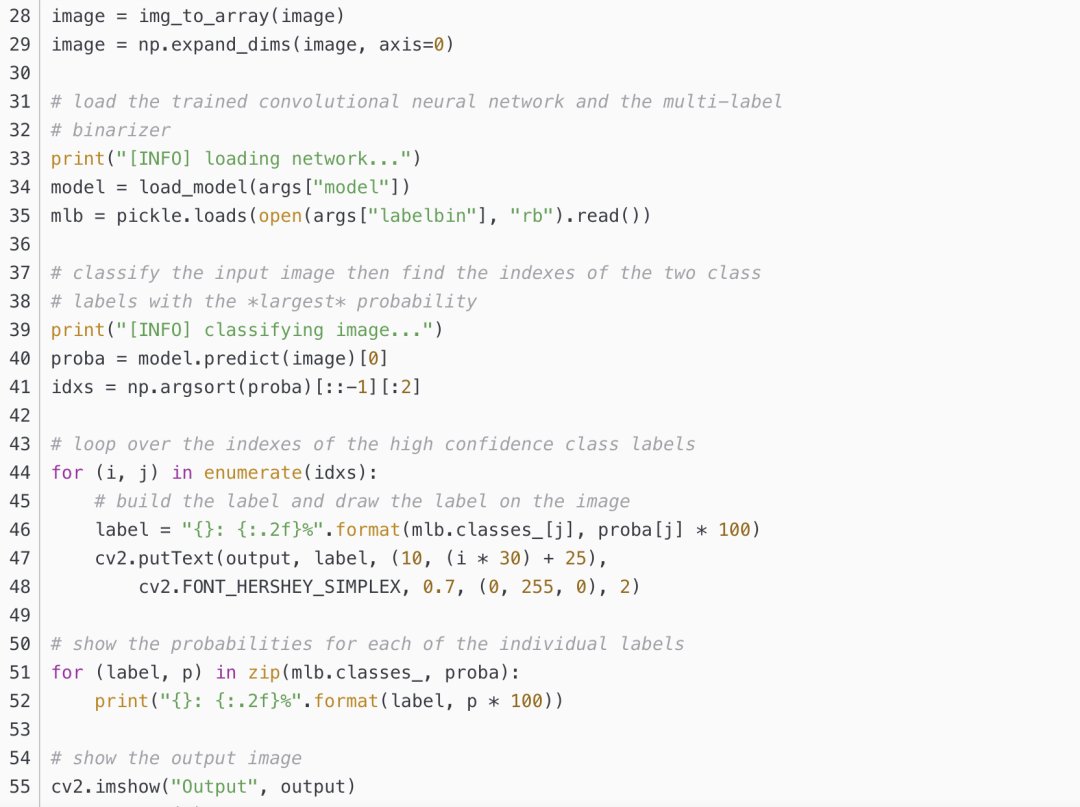
最终显示出预测的分类结果

使用Keras执行多标签分类非常简单,包括两个主要步骤:
1.使用sigmoid激活替换网络末端的softmax激活 2.二值交叉熵作为分类交叉熵损失函数
shortcomings:
网络无法预测没有在训练集中出现过的数据样品,如果出现的次数过少,预测的效果也不会很好,解决办法是增大数据集,这样可能非常不容易,还有一种用的已经很多的方法用在大的数据集上训练得到的权重数据对网络做初始化,提高模型的泛化能力。