第3章 软件性能测试
3.1性能测试介绍
3.1.1 性能测试的定义
性能测试在质量ISO2510 2006模型中属于效率,根据维基百科定义,[30]软件性能测试作为软件质量保证必不可少的环节,指的是软件系统或构件对于其及时性要求符合程度的指标;它是一种规范,可以用来量化更改业务指标所产生的影响,进而说明部署软件的风险。一般用响应时间|、QTP、吞吐率、每秒点击数等参数指标进行衡量。
远古时候,人类发现自己的精力是有限的,为了能够到达更远的地方,发明了马车、牛车等用牲口作为动力的车。到了十八世纪随着蒸汽机的发现后,在1769年,法国人N·J·居纽制造了世界上第一辆蒸汽驱动的三轮汽车,人类的代步工具进入了工业化的时代。随着后来普通火车、飞机、高速火车的发明,使人类的远足变得越来越方便快捷。据说在不久的将来,就能坐上胶囊式火车,这种火车的车体在一个完全真空的胶囊中运行,时速非常得快,从北京到上海,20分钟就可到达。
所以性能给人的第一感觉就是“快”。一个软件产品除了功能正确以外,性能是非功能属性中很重要的特性,可以想象下打开一个网站首页每次都超过15秒,这样的网站功能做得再好,也不会有人使用的。另外性能问题也会引起一些很大的问题,见下面几个的案例。
3.1.2 由于性能测试没做到位发生的缺陷
1. 奥运门票事件
2007年10月,北京奥组委向境内公众启动第二阶段奥运会门票预售。由于实行了“先到先得,售完为止”的销售政策,公众纷纷抢在第一时间订票,使票务官方网站的压力激增,承受了超过自身设计容量八倍的流量,系统开工半小时即瘫痪导致系统瘫痪。为此,北京奥组委票务中心对广大公众未能及时、便捷地实现奥运门票预订表示歉意,同时宣布奥运门票暂停销售5天。
2. 12306事件
2014年1月16日是春运第一天,大家通过互联网、电话渠道正式购买列车车票。首轮春运“抢票高峰”刚刚到来,众多网友纷纷称,12306网站网络系统并不稳定,且出现了“串号”问题,用户甚至可轻易获取陌生人的身份证号码、手机号码等隐私信息。
3.淘宝双11事件
2018年11月11日双11如期到来,淘宝与许多电子商务网站一样,在双11推出了许多产品降价促销活动。有些网友采取大量囤货买进,然后挑选自己合适的商品留下,不合适退货的策略。另外双11快递比较多,快递公司工作量猛增,好些网友长时间内收不到货,所以要求退货。由于退货太多,对于淘宝开发人员而言也没有对这个不太重要的模块专门进行过性能测试,从而造成“退货退款”模块瘫痪,使得造成网友无法退货的情形。
4. “艺术升”事件
2019年1月6日,许多艺术生的考生通过“艺术升”APP报名考试,由于系统响应时间非常得慢,甚至造成卡顿。当轮到自己可以报名了出现“XXX院校考点报名人数已满,无法再报名”的现象,引起社会的强烈不满。
那么应该如何做好软件性能测试呢,下面进行详细介绍。
3.1.3 性能测试类型
对于性能测试类型的术语在测试业界是比较混乱的,读者关键在于掌握每种测试类型里面的含义,然后接触其他书籍或文章中,通过内容来达到以不变应万变的目的。本节提到的软件性能测试如图3-1,包括普通性能测试、负载测试(包括并发测试与容量测试)、疲劳性测试、强度测试和配置测试。
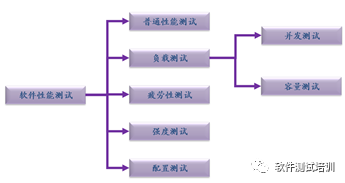
图3-1 软件性能测试类型
1.普通性能测试(Perfoemce Testing)
普通情况下的性能测试是指在低负载、低容量下系统的性能体现。普通性能测试通常在功能测试同时进行,通过测试工程师的抓包或者用户体验来进行测试。
2.负载测试(Load Testing)
负载测试分为并发测试和容量测试。
1)并发测试(Concurrent Testing)
先来介绍一下什么叫并发,如图3-2所示。
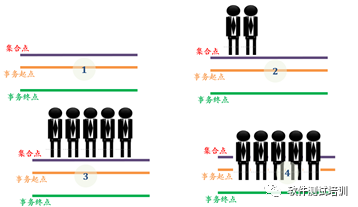
图3-2 并发测试场景
1.没有任何用户到达集合点2.部分用户到达集合点
3. 所有用户到达集合点,开始并发4. 正在进行并发
在图3-2的(1)表示并发操作即将执行,在并发测试执行之前,必须定义好集合点和事务起始点。所谓事务就是需要执行并发的一个业务操作。比如登录系统、查询文章。集合点往往设置在事务起点之前,所有设置的用户在没有达到并发条件之前在集合点等待,一旦达到集合点,就触发并发操作。在图3-2的(2)中上来了部分用户,但是还没有达到并发条件。在图3-2的(3)中达到了并发条件,开始进行并发操作。在图3-2的(4)中正在进行并发操作。
并发测试(Concurrent Testing)是指在一定的软件、硬件及网络环境下,通过运行一种或多种业务在不同虚拟用户数量情况下测试服务器的性能指标是否在用户的要求范围内,用于确定系统能承载的最大用户数、最大有效用户数以及不同用户数下的系统响应时间及服务器的资源利用率。
案例3-1:并发测试。
以并发用户5000开始对某产品的模糊查询功能进行负载测试(数据库中的数据一直保持为10000条),记录错误的虚拟用户+失败的虚拟用户与所有虚拟用户的比值,然后每次增加500个并发用户,每次测试持续时间为10分钟。发现这个记录的比值随着并发用户的增大逐渐增大,当并发用户达到13500时发现这个比值为5.8%(一般认为在5.0%以下为正常,在5.0%以上为不正常),确定这个版本的并发用户的拐点为9500个。(也有一些企业通过查看响应时间来判断,如果响应时间超过设定的值,比如3秒,则说明找到拐点)(容量测试中也可使用二分法来寻找拐点,在第3.1.10节中将进行描述)。
2)容量测试(Volume Testing)
容量测试(VolumeTesting)是指在一定的软件、硬件及网络环境下,例如向数据库中构造不同数量级别的数据记录,通过运行一种或多种业务在一定的虚拟用户数量情况下,获取不同数据级别的服务器性能指标,以确定数据库的最佳容量。
案例3-2:容量测试。
在案例3-1场景下,保持并发用户为4000,数据库数据从10000条开始每次增加1000条记录请求响应时间,每次测试持续时间为10分钟。当数据达到30000后,发现平均响应时间超过规定的3秒,达到3.24秒。所以,确定本次模糊查询模块的容量测试拐点为30000条。(容量测试中也可使用二分法来寻找拐点,在第3.1.10节中将进行描述)。
负载测试的评判结果是基准法,即这一版本的拐点值在通常情况下不得低于上一次的95%以下。在这里特别需要提及的是通常情况,如果产品功能增加了很多或者其他原因,在公司技术高层的协商下是可以低于95%的。
案例3-3:用基准法来评判并发测试。
在案例3-1的产品设计的版本下发布了一个新的版本,得到的最大并发数拐点为9200,最大容量拐点为28000条。与上一次的测试结果比较:并发9200/9500×100%≈97%,28000/30000×100%=93%。所以,这次性能测试中并发测试结果是正常的,而容量测试是不正常的,需要进一步定位容量测试性能降低的原因。
3. 疲劳性测试(Stress Testing)
疲劳性测试(StressTesting)是指在一定的软件、硬件及网络环境下,通过模拟大量的虚拟用户向服务器产生负载,使服务器的资源处于极限状态下长时间连续运行,以测试服务器在高负载情况下是否能够稳定工作。通常在70%~80%最高负载下持续运行48小时。这里的负载可以是并发负载也可以是容量负载,甚至既可以是并发负载+容量负载,在并发负载+容量负载同时作用下,通常取50%~60%并发负载和50%~60%容量负载进行测试。
案例3-4:疲劳性测试。
在案例3-1场景下(数据库中的数据一直保持为10000条),将并发用户设置为最大并发用户的75%,即9500×75%=7125,持续运行48小时,使用监控软件监控应用服务器以及数据库设备的各个资源的使用率情况。48小时后,通过查看测试日志,发现在第36小时34分,服务器端查询进程的内存出现了飙升,持续12秒后降到0点,这时查询进程的CPU使用率也一下降到0点,确定在这个时刻可能存在一个内存溢出的问题而导致系统宕机。
疲劳性测试是在拐点下进行测试的,见图3-3所示。
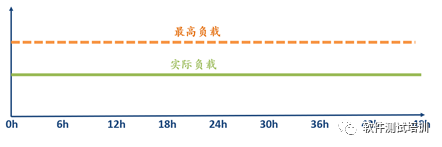
图3-3 疲劳性测试
4.强度测试(Strength Testing)
强度测试(StrengthTest)在高于性能测试拐点的情形上,测试软件的表现形式。严格来说,强度测试是应该属于可靠性测试范畴的,但是它与负载测试中的拐点息息相关,所以在性能测试中进行介绍。图3-4是标准的强度测试。
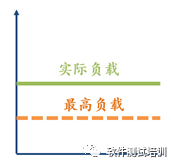
图3-4 标准的强度测试
疲劳测试是在最高负载之下运行的,而强度测试是在最高负载之上运行的。并且强度测试运行持续长度比较短,而疲劳测试需要持续长度比较长。一般在标准强度测试下很难发现问题,往往在图3-5两种情形下发现的问题最多。
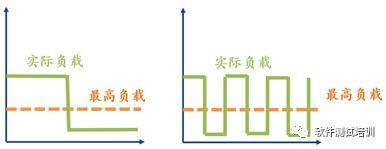
图3-5 衍生的强度测试
在图3-5左边,系统在高于最高负载之上运行,然后突然将系统负载降到最低,观察各项性能指标是否有能力恢复正常。在图3-5右边,系统的负载忽高忽低,这种情况在实际中是经常遇到的,当系统终于高压状态运行,系统的监控系统发现超载,启用保护模块,把负载降为正常。当系统达到正常状态后,监控系统认为运行正常,禁用保护模块,造成系统又处于最高负载运行状态。在这种“过山车”的情形下也是容易发现问题的,这样的测试类型也可叫做浪涌测试。。
5.配置测试(Configuration Testing)
配置测试(ConfigurationTesting)是指在不同的软件、硬件、环境以及网络环境配置下,通过运行一种或多种业务在一定的虚拟用户数量情况下获得不同配置的性能指标,用于选择最佳的设备及参数配置。
案例3-5:配置测试。
对某款Web软件在几个主流的服务器上(Windows Server 2019、Ubuntu、openSUSE、Mac)不同的浏览器(IE、Edge、Chrome、Firefox、Safari),Tomcat不同的运行模式下运行,测试其性能情况。
3.1.4 性能测试指标
1.响应时间(Response Time)
响应时间=用户响应时间+前端响应时间+网络响应时间+服务器端响应时间+数据库响应时间,是反映系统处理效率的指标之一。
响应时间是从开始到完成某项工作所需时间的度量。嵌入式产品,响应时间不包括人的反应时间,而对于其他产品,大多数都是人机交互的,响应时间体现在人的直观体验感受。在B/S系统中有一个著名的2/5/10原则,即网页在0-2秒内显示,所有用户可以接受;在2-5秒内显示,大部分用户可以接受;5-10秒内显示,只有少部分用户可以接受;10秒以上就几乎没有用户可以接受了。
另外合理的响应时间要与用户需求相结合,如在银行输入系统中,导入数据花费2个小时,那么输出响应能在20分钟内完成,性能就很不错了。
通过图3-6可以看出,响应时间=B1+W1+S1+W2+D+W3+S2+W4+B2,其中。
•W1、W2、W3、W4。网络响应时间。
•B1、B2。前端响应时间。
•S1、S2。服务器响应时间。
•D=数据库处理时间。
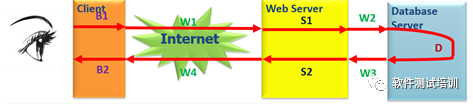
图3-6 响应时间
案例3-6:某网站的表单提交响应时间。
一个网站前端使用的是HTML5+CSS3+JavaScript+Ajax技术,服务器语言采用的是JSP+JavaBean技术,数据库采用的是Orcale。该网站某个表单提交的响应时间包括如下步骤。
(1)用户输入信息提交表单的时间。
(2)前端验证输入信息的时间。
(3)前端处理输入信息的时间。
(4)前端输入信息传输到Web Server的时间。
(5)jsp+javabean程序处理输入信息的时间。
(6)输入信息从Web Server到Oracle的传输时间。
(7)Oracle插入数据处理时间。
(8)Oracle将插入数据成功与否的信息传输到Web Server的时间。
(9)Web Server将插入数据成功与否的信息传输到前端的时间。
(10)前端插入数据成功与否的信息展示时间。
(11)用户接收到显示信息的时间。
2. 吞吐率(Throughput Rate)
吞吐率是单位时间内的吞吐量。吞吐量是服务器所能处理事务的能力。吞吐率的单位为字节数/秒、业务数/秒、点击数/秒、请求数/秒。随着负载的增加,吞吐率往往增长到一个峰值后,然后下降,队列变长。注意:在性能测试领域吞吐量是没有意义的,吞吐率才有意义。比如说某台服务器可以处理5T大小的数据,那么多的数据是1小时内处理完毕还是一天(24小时)处理完毕?如果是1小时内处理完毕,吞吐率为5T/h,性能是非常不错的;但是如果是24小时内处理完毕,吞吐率为5T÷24=208 G/h,性能就差很多。
为了让各位更好地理解吞吐率。以马路作为一个例子,见图3-7。

图3-7 马路的吞吐率
当马路上只有一辆车子运行,车子运行是非常畅通的,吞吐量也为1;随着汽车越来越多,单位时间内通过的车越来越多,也就是说这时候马路上车的吞吐量为n(n>1);随着更多的车子加入,马路达到饱和,出现了堵车的情形。虽然想进入这条马路上的车和在这条马路上的车为k,但是马路上最多可以行使的车保持在m辆(n<m<k)。也就是说马路达到了拐点,最多处理能力为同时行驶m辆车。。
案例3-7:理发师模型
理发师模型是经典的解释吞吐率与响应时间的模型。比如有一家理发馆,里面有3名理发师,每个理发师水平相当,每给一位顾客理发需要10分钟的时间,如表3-1所示。
表3-1理发师模型
设置并发数 | 总响应时间 | 平均响应时间 | 实际并发数 |
|---|---|---|---|
1 | 10分钟×1=10分钟 | 10分钟/1=10分钟 | 1 |
2 | 10分钟×2=20分钟 | 20分钟/2=10分钟 | 2 |
3 | 10分钟×3=30分钟 | 30分钟/3=10分钟 | 3 |
4 | 20分钟×1+10分钟×3=50分钟 | 50分钟/4=12.5分钟 | 3 |
5 | 20分钟×2+10分钟×3=70分钟 | 70分钟/5=14分钟 | 3 |
6 | 20分钟×3+10分钟×3=90分钟 | 90分钟/6=15分钟 | 3 |
7 | 30分钟×1+20分钟×3+10分钟×3=120分钟 | 120分钟/7=17.1分钟 | 3 |
8 | 30分钟×2+20分钟×3+10分钟×3=150分钟 | 150分钟/8=18.75分钟 | 3 |
9 | 30分钟×3+20分钟×3+10分钟×3=180分钟 | 180分钟/9=20分钟 | 3 |
… | |||
•当有1个人来理发的时候,需要10分钟的理发时间、平均响应时间为10分钟、实际并发数为1。
•当有2个人来理发的时候,2个人可以同时进行,共需要10×2=20分钟的理发时间、平均响应时间仍旧为20/2=10分钟、实际并发数为2。
•当有3个人来理发的时候,3个人仍旧可以同时进行,共需要10×3=30分钟的理发时间、平均响应时间仍旧为30/3=10分钟、实际并发数为3。
•当有4个人来理发的时候,3个人可以同时进行,但有1个人需要等到下一轮,这个时候需要20分钟×1+10分钟×3=50分钟的理发时间、平均响应时间为50/4=12.5分钟、由于理发师没有增加,实际并发数仍旧为3。
•当有5个人来理发的时候,3个人可以同时进行,2个人需要等到下一轮,这个时候需要20分钟×2+10分钟×3=70分钟的理发时间、平均响应时间为70/5=14分钟、由于理发师没有增加,实际并发数仍旧为3。
•当有6个人来理发的时候,3个人可以同时进行,3个人需要等到下一轮,这个时候需要20分钟×3+10分钟×3=90分钟的理发时间、平均响应时间为90/6=15分钟、由于理发师没有增加,实际并发数仍旧为3。
•当有7个人来理发的时候,3个人可以同时进行,3个人需要等到下一轮,1个人需要等到两轮,这个时候需要30分钟×1+20分钟×3+10分钟×3=120分钟的理发时间、平均响应时间为120/7=17.1分钟、由于理发师没有增加,实际并发数仍旧为3。
•当有8个人来理发的时候,3个人可以同时进行,3个人需要等到下一轮,2个人需要等到两轮,这个时候需要30分钟×2+20分钟×3+10分钟×3=150分钟的理发时间、平均响应时间为150/8=18.75分钟、由于理发师没有增加,实际并发数仍旧为3。
…
图3-8和图3-9分别是理发师模型平均响应时间、实际并发数与设置并发数对应曲线。
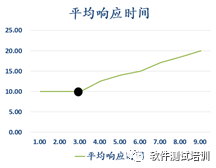
图3-8 理发师模型平均响应时间与设置并发数对应曲线
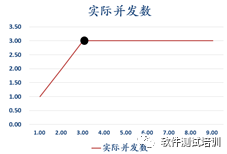
图3-9 理发师模型实际并发数与设置并发数对应曲线
在不到拐点的场景下,随着设置并发数的增加,平均响应时间基本保持不变,并且实际并发数与设置并发数保持一致;当超过拐点的场景下,随着设置并发数的增加,平均响应时间持续上升,而实际并发数在最高值保持不变。这与软件性能测试的情形是基本吻合的。如果要提高性能从硬件上考虑可以增加理发师,从软件上考虑可以加强理发师水平,减少给每一位顾客理发的时间。
3. 资源利用率(Resource Utilization)
资源利用率=资源实际使用量/总的资源可用量。资源利用率反映系统能耗指标,包括。
•CPU利用率。
•内存利用率。
•硬盘空间利用率。
•网络带宽利用率。
图3-10上面是某一进程对于CPU的利用率曲线图,图3-11下面是某一进程对于虚拟内存和物理内存的使用量的曲线图。

图3-10 CPU的资源利用率
图3-11 内存的资源利用率
4. 性能计数器(Performance Counter)
性能计数器是反映系统性能的重要参考指标。如何通过查看这些计数器来观察系统性能是需要通过平时积累的。关于Linux性能计数器的问题在Linux性能监控中结合命令行进行讨论,将在第3.2.2节中进行详细描述。Windows性能监控可以通过“开始菜单->控制面板->管理工具->性能”查看,如图3-12所示,将在第3.21节中进行详细描述。除了操作系统计数器,还有数据库计数器、中间件计数器、Web Service计数器等。
图3-12 在Windows下查看计数器
5. 并发用户数与在线用户数(Number of Concurrent Users、Number of Online Users)
并发用户数与在线用户数的区别在于,并发用户数是一批用户同时在干同一件事情(事务),如登录系统,可参见4.3.2-1章节介绍。而在线用户数指一些用户在系统上,有些在浏览网页、有些在查询、有些进入系统,还有些在做其他与系统无关的事情等。
案例3-8:并发用户数与在线用户数。
一个网站有3000人在线。30%的用户(900人)在浏览页面、20%的用户(600人)在填写订单、5%的用户(150人)在提交订单、15%的用户(450人)在查询订单、30%的用户(900人)干其他事情,比如做饭,照顾孩子。在这3000人里面,不考虑页面定时更新的情况下,实际对系统产生压力的仅仅为处于提交订单、查询订单的600人,占所有在线用户的20%。
6.思考时间(Tinking Time)
思考时间也称休眠时间,从业务角度来说,该时间指的是用户在操作时,每个请求之间的间隔时间。
案例3-9:思考时间
某个用户登录系统后,过了5秒,开始往模糊查询中输入查询内容,从输入到按点击用了10秒,查询结果出来后,停留了20秒又进入某个查询结果的详细页面。这里,登录后5秒,输入花费的10秒,停留的20秒都是思考时间。
在思考时间设置中LoadRunner提供了按照录制时间、录制时间的倍数、录制时间的某一百分比空间和一个固定的值4种方式。而在不加插件的情况下,JMeter只能设置一个固定的值。
3.1.5性能测试环境
性能测试对环境是非常重要的,特别是网络环境。

图3-13 测试环境与工作环境在一起

图3-14 测试环境各个客户端不在一个网段下
在图3-13中,测试环境与工作环境在一起,既使得别人的正常工作不能进行,也使得测试的数据不准确。在图3-14中,测试环境各个客户端在两个不同的网段下进行(这里是C类网),大家都知道跨网段是需要路由的,路由里面有软件,会干扰性能测试的数据,从而也会造成测试数据不准确。图3-15的环境是正确的。所有的性能测试机器都在一个网段下,且与工作环境相隔离。
图3-15 正确的性能测试环境
3.1.6 观察性能的四个维度
图3-16展示的是通过终端用户、系统运维人员、软件设计开发人员和性能测试人员四个维度来观察系统的性能。
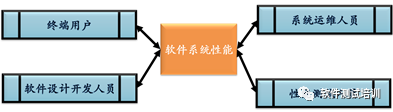
图3-16 观察性能的四个维度
1.从终端用户角度看性能
对于最终用户,性能主要体现在响应时间,第3.4.1节介绍性能响应时间包括响应时间=用户响应时间+前端响应时间+网络响应时间+服务器端响应时间+数据库响应时间。而这里面的过程对用户来说是透明的,用户只关心按下鼠标到页面出现所希望的信息之间的时间越短越好。
2.从系统运维人员角度看性能
从运维人员的角度来看,软件性能除了包括单个用户的响应时间外,更要关注大量用户并发访问时的负载,以及可能的更大负载情况下的系统健康状态、并发处理能力、当前部署的系统容量、可能的系统瓶颈、系统配置层面的调优、数据库的调优,以及长时间运行的稳定性和可扩展性。比如一个产品有两种设计方案,这两种设计方案体现了两种不同的性能。
•方案一。最多支持100万个在线用户,平均响应时间为3秒。
•方案二。最多支持500万个在线用户,平均响应时间为5秒。
作为技术人员可能比较看重方案一,因为平均响应时间为3秒,比方案二5秒要快2秒。但是方案一仅能支持100万个在线用户,而方案二是它的五倍,可以支持500万个在线用户。所以作为系统运维人员肯定会选择方案二的。
3.从软件设计开发人员角度看性能
软件设计开发人员角度需要从以下5个维度来看性能。
1)算法设计
•核心算法的设计与实现是否高效。
•必要时,设计上是否采用buffer机制以提高性能,降低 I/O。
•是否存在潜在的内存泄露。
•是否存在并发环境下的线程安全问题。
•是否存在不合理的线程同步方式。
•是否存在不合理的资源竞争。
2)架构设计
•站在整体系统的角度,是否可以方便地进行系统容量和性能扩展。
•应用集群的可扩展性是否经过测试和验证。
•缓存集群的可扩展性是否经过测试和验证。
•数据库的可扩展性是否经过测试和验证。
3)性能最佳实践准则
•代码实现是否遵守开发语言的性能最佳实践。
•关键代码是否在白盒级别进行性能测试。
•是否考虑前端性能的优化。
•必要的时候是否采用数据压缩传输。
•对于既要压缩又要加密的场景,是否采用先压缩后加密的顺序。
4)数据库
•数据库表设计是否高效。
•是否引入必要的索引。
•SQL 语句的执行计划是否合理。
•SQL 语句除了功能是否要考虑性能要求。
•数据库是否需要引入读写分离机制。
•系统冷启动后,大量缓存命不中的时候,数据库承载的压力是否超负荷。
5)软件性能的可测试性
•是否为性能分析(Profiler)提供必要的接口支持。
•是否支持高并发场景下的性能打点。
•是否支持全链路的性能分析。
4.从测试人员角度看性能
由于性能牵扯到代码、系统架构、数据库、硬件、操作系统、中间件等几乎涵盖计算机知识的方方面面,所以性能测试工程师如在第2.2.2节所述,应该是一专多能的T型人才的集合体。性能测试人员对软件性能需要做到以下几点。
•根据性能测试目标以及线上数据收集,精准的性能测试场景设计和计算能力。
•性能测试场景和性能测试脚本的开发和执行能力。
•测试性能报告的分析解读能力。
•性能瓶颈的快速排查和定位能力。
•性能测试数据的设计和实现能力。
•面对互联网产品,全链路压测的设计与执行能力,能够和系统架构师一起处理流量标记、影子数据库等的技术设计能力。
•深入理解性能测试工具的内部实现原理,当性能测试工具有限制时,可以进行扩展二次开发。
•极其宽广的知识面,既要有“面”的知识,比如系统架构、存储架构、网络架构等全局的知识,还要有大量“点”的知识积累,比如数据库 SQL 语句的执行计划调优、JVM 垃圾回收(GC)机制、多线程常见问题等等。
3.1.7 性能测试的判断标准
对于功能测试,判断测试用例是否测试通过,往往是比较容易的,只要不发生错误并且满足用户的需求即可。而对于性能测试该如何来评判性能测试是否通过呢?可以考虑以下三个方面。
•根据用户需求来判断。
如果用户对性能有明确的需求,比如登录操作,不得小于3秒,那么测试工程师就可以就这个需求来进行测试。另外系统运行过程不发生内存溢出、死锁等故障也应该属于隐性的性能需求。
•根据业内标准来判断。
比如第3.1.4-1节提到的2/5/10法则,前端响应时间不得超过全部响应时间的30%等都是业内不成文的性能标准。
•根据基准测试结果来判断。
一般而言,本次测试的度量指标不得小于上次版本的95%以下。
3.1.8性能测试的场景
一般根据性能测试的类型及各个类型的组合来设计性能场景,常见的性能测试场景如下。
•普通测试场景。
•并发测试场景。
•容量测试场景。
•疲劳测试场景。
•强度测试场景。
•配置测试场景。
•并发+疲劳场景。
一般采用65%-75%的并发峰值,持续测试48小时。
•容量+疲劳场景。
一般采用65%-75%的容量峰值,持续测试48小时。
•容量+并发+疲劳场景
65%的并发峰值,65%的容量峰值,持续测试48小时。
•多业务测试场景。
有多个业务组合形成的测试场景,一般将前面的性能场景测试完毕以后再进行,否则发生问题难于定位。
3.1.9 性能测试的干系人
由于各种原因都可能造成性能问题,所以性能测试干系人包括。
•客户代表。
•产品经理。
•销售人员。
•市场人员。
•项目经理。
•研发人员。
包括需求分析师、架构设计师、开发工程师、测试工程师等。
•运维人员。
包括DBA、技术支持工程师等。
3.1.10 负载测试的二分法找拐点法
负载测试包括并发测试和容量测试,寻找性能拐点往往是这种测试的关键。以往寻找拐点往往采取递进法,即给出一个起点,比如500个并发用户,进行并发测试,如果通过,再加100,变成600个并发用户,进行并发测试。通过这样的方法进行层层递进来寻找拐点。可以想象一下,如果并发拐点为3000,岂不需要测试25次才可找到拐点。这里来介绍二分法找拐点的方法。
二分法找拐点的方法请参看图3-17所示。
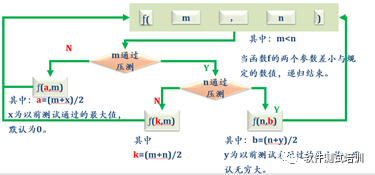
图3-17 二分法找拐点的方法
(1)寻找m,n两个值,其中m<n,建议初始的时候m与n之间的差距拉得大一些。
(2)对m进行并发/容量测试。
(3)如果m测试不通过,说明拐点比m小,寻找新的m值a,假设以前测试过的最小值为x(如果没有,令x=0)。那么a=( m + x)/2,返回第(1)步。
(4)如果m测试通过,说明拐点比m大,对n进行并发/容量测试。
(5)如果n测试通过,说明拐点比m大比n小,选择新的n值a,a=(m+n)/2,返回第(1)步。
(6)如果n测试不通过,说明拐点比n大,寻找新的n值b,假设以前测试过的最大值为y(如果没有,令y=∞)。那么a=( n + y)/2,返回第(1)步。
(7)当n-m<=某一固定的值,当前值即为拐点值,递归结束。
案例3-10:负载测试的二分法找拐点法
使用二分法测试寻找并发测试的拐点,如果n-m<50,即为找到拐点。
(1)令m=1000, n=5000,对1000进行并发测试,持续10分钟,没有发现异常,测试通过,说明拐点比1000大。
(2)对5000进行并发测试,持续10分钟,发现异常,测试失败,说明拐点比5000小。此时n-m=5000-1000=4000>50。
(3)选择新的n=(1000+5000)/2=3000,此时n-m=5000-3000=2000>50,对3000进行并发测试,持续10分钟,发现异常,测试失败,说明拐点比1000大但比3000小。
(4)选择新的m=(1000+3000)/2=2000,此时n-m=3000-2000=1000>50,对2000进行并发测试,持续10分钟,没有发现异常,测试通过,说明拐点比2000大但比3000小。
(5)选择新的m=(2000+3000)/2=2500,此时n-m=3000-2500=500>50,对2500进行并发测试,持续10分钟,没有发现异常,测试通过,说明拐点比2500大但比3000小。
(6)选择新的m=(2500+3000)/2=2750,此时n-m=3000-2750=250>50。对2750进行并发测试,持续10分钟,没有发现异常,测试通过,说明拐点比2750大但比3000小。
(7)选择新的m=(2750+3000)/2=2875,此时n-m=3000-2875=125>50。对2875进行并发测试,持续10分钟,没有发现异常,测试通过,说明拐点比2875大但比3000小。
(8)选择新的m=(2875+3000)/2=2938,此时n-m=3000-2938=62>50。对2938进行并发测试,持续10分钟,没有发现异常,测试通过,说明拐点比2938大但比3000小。
(9)选择新的m=(2938+3000)/2=2969,此时n-m=3000-2969=31<50,所以认为并发拐点为2938。
这样仅对8个数值进行了测试就找到了拐点。
另外需要说明的是并发测试的拐点没有容量测试那么明显,所以在找到拐点之后,需要对这个值进行多次验证,确保是真正的拐点。而容量测试的拐点往往表现特别明显,拐点上与拐点下的性能表现得很明显。
扩展阅读:0.618黄金分割数法方程x/(1-x)=(1-x)/x的解≈0.618,0.618又称作黄金分割数,黄金分割数是一个无理数。它经常被用于各个方面,比如绘画、雕塑、植物、建筑、宇宙、军事、数学等。前面提到的是二分法。如果当前判断拐点大于m小于n,下一个值取:(n-m)×0.618+m,这个方法在数学上已经证明比二分法收敛速度快,而且是一维里面是最快的,所以大家也可以采用0.618黄金分割数法来寻找拐点。 |
|---|
3.1.11 全链路压测
正如第3.1.2-3节描述,2018年双11,淘宝“退货退款”模块瘫痪。对于“退货退款”模块往往是一个被忽视的性能测试模块,但是自从这个事故发生之后。各大互联网公司对全链路压测试得到了非常重视。京东、淘宝、腾讯等网商企业现在都在双11到来之前至少半年就开始筹划全链路压测了。全链路压测往往在晚上00:00-5:00在线进行测试,但是也要看公司具体而定。由于LoadRunner是通过并发用户的License收费的,并且收费是相当昂贵的。而JMeter是一个基于Java多线程来实现虚拟用户的开源工具,自身就占用很多的系统资源,所以也被排除。而现在作为全链路压测工具基本上选用Gatling。
Gatling是一个开源的基于Scala、Akka、Netty 实现的高性能压测框架,较之其他基于线程实现的压测框架,Gatling 基于AKKA Actor 模型实现,请求由事件驱动,在系统资源消耗上低于其他压测框架(如内存、连接池等),使得单台压测机可以模拟更多的用户。
另外由于全链路压测是在线上进行的,所以要确保测试数据与真实数据分离,在全链路压测完毕,需要把压测数据全部删除。