
作者 | 厉启鹏
本文以互联网的发展为主线,用叙事的方式向读者再现了消息系统从诞生至今的发展历史。从 1983 年开始,消息系统经历了不同历史时期的历练与打磨,它们的使用方式、功能特性、产品形态、应用场景都发生了非常大的变化。作者选取了五款不同时代的代表性作品,描述了这些产品诞生的历史背景,立足解决的核心问题,并尝试分析它们取得成功的关键因素。最后作者给出了在 Serverless 时代的三个断言,指出了当前消息系统在解决 Serverless 场景存在的核心痛点,展望了未来消息产品应该具备的关键能力,并给出了几款最新流行的适合 serverless 场景的开源消息队列。
开源史前的消息队列
故事要从一位印度小哥说起。1983 年 26 岁的孟买工程师 Vivek Ranadive[1] 从 MIT 毕业后决定创办自己的信息技术公司。当时与硬件相比,软件开发效率非常低。受计算机总线的启发,Vivek 设计了一款软件计算机总线,名为 The Information Bus(TIB),从此消息队列踏入了软件历史,开启了一个全球每年数十亿美金的新市场。

Vivek Ranadiv[2]
1985 年,Vivek 从 Teknekron Corp 获得种子资金,Teknekron Software Systems Inc. (TSS) 诞生了,专注于 TIB 商业化。TIB 主要服务于金融行业,解决证券交易软件之间的数据交换问题。20 世纪 80 年代美国金融交易行业门厅若市,因此 TIB 被广泛使用大获成功。Teknekron 于 1993 年被路透集团收购 [3],1997 年路透成立 TIBCO Softwore[4] 独立运营 TIB 软件解决方案。2014 年 TIBCO Software 通过 Vista Equity Partners 的 43 亿美元的收购,被正式私有化 [5]。
TIB 的成功受到蓝色巨人 IBM 的关注,因为 IBM 的客户也主要来自于金融行业。1990 年 IBM 开始研发消息队列,三年后 IBM WebSphere MQ 产品面世[6,7]。经过不断发展,IBM MQ 成为全球极具竞争力的商业消息系统 [8,9]。根据 Gartner 报告 [10] 2020 年 IBM MQ 每年全球仍有近 10 亿美金的营收, 占全球消息中间件市场份额近三分之一。
开源时代
商业化 MQ 的成功,使其占据了大型企业的应用通信市场,然而高昂的价格却令中小企业望而却步。同时,商业化 MQ 提供商为了维持其竞争壁垒,建立了封闭的产品生态,不与其他 MQ 互通。导致很多大企业同时用了多个 MQ 供应商的产品,彼此却无法打通。例如,应用已经订阅了 TIBCO MQ 消息,若需要消费来自 IBM MQ 的消息,则实现起来会非常困难。这些产品使用不同的 API、不同的协议,因而毫无疑问无法联合起来组成单一的总线。为了解决这个问题,Java Message Service(JMS)在 1998 年诞生了 [11,12]。
JMS 之于 MQ 类似于 JDBC 之于数据库,它试图通过提供公共 Java API 的方式,隐藏单独 MQ 产品供应商提供的实际接口,从而跨越壁垒解决互通问题。从技术上讲,Java 应用程序只需针对 JMS API 编程,选择合适的 MQ 驱动即可,JMS 会打理好其他部分。JMS 确实一定程度上解决了 MQ 之间互通的问题,但当应用通讯底层适配不同的 MQ 时需要代码去胶合众多不同 MQ 接口,这使 JMS 应用程序非常脆弱,可用性下降。很明显,市场急需一个原生支持 JMS 协议的 MQ 出现。
基于这样的背景,2003 年 ActiveMQ 诞生 [13],它是第一个原生支持 JMS 协议的开源消息队列产品。ActiveMQ 完整实现了 JMS。ActiveMQ 的出现解决了适配 JMS 稳定性的问题,受到很多企业的支持。而且 ActiveMQ 是开源产品,鉴于商业版 MQ 高昂的价格,ActiveMQ 深受中小企业的追捧。2005 年 Damarillo 等人围绕 ActiveMQ 项目成立了 LogicBlaze 公司 [14],该公司 2 年后被 IONA 收购 [15]。
JMS 有一个比较严重的不足,只针对于 Java 应用。其他语言开发的程序无法使用 JMS 完成信息的交换,在此背景下,真正的救世主 AMQP 出现了。AMQP[16](Advanced Message Queuing Protocol)在 2003 年时被 John O'Hara 提出,由摩根大通牵头联合 Cisco, IONA,Red Hat, iMatix 等成立了 AMQP 工作组,用于解决金融领不同平台之间的消息传递交互问题。AMQP 是一种协议,更准确的说是一种 Binary Wire-Level Protocol(链接协议)。这是其与 JMS 的本质差别,AMQP 不从 API 层进行限定,而是直接定义网络交换的数据格式。这使得实现了 AMQP 的 Provider 天然性就是跨平台的。意味着我们可以使用 Java 的 AMQP Provider,同时使用一个 Python 的 Producer 加一个 Ruby 的 Consumer。从这一点看,AMQP 可以用 HTTP 来进行类比,不关心实现的语言,只要大家都按照相应的数据格式去发送报文请求,不同语言的 Client 均可以和不同语言的 Server 链接。AMQP 的 Scope 要比 JMS 更广阔。
显然市场上需要一个完全实现 AMQP 协议的消息队列产品。2007 年由 Alexis 和 Matthias 联合创办的公司 Rabbit Technologies 成立 [17],同年该公司推出了第一个完全实现 AMQP 协议的消息队列产品 RabbitMQ,该公司 2010 年被 VMware 收购 [18]。RabbitMQ 用 Erlang 语言开发,性能非常好,微秒级延时。因为对 AMQP 的完全支持,较之 IBM MQ 等商业产品以及实现 JMS 的 ActiveMQ,其更加开放,可以支持更多的应用接入集成。而且较之同时代的 AMQP 其他实现产品比如 Apache Qpid[19],其多语言客户端、技术文档更加规范、健全,开源社区更加活跃[20][21]。这使得 RabbitMQ 逐渐成为中小企业甚至大企业进行消息交换的理想选择。实际上在全球范围内,RabbitMQ 至今仍然是最成功的开源消息队列之一。

RabbitMQ 架构图 [22]
当然 RabbitMQ 并非完美无缺,恰恰由于其对 AMQP 协议的完美支持,实现过于复杂。这也导致它的吞吐量并不高。
大数据时代
互联网的诞生让企业产生的数据越来越多,2010 年移动互联网的到来,使互联网这个超级入口被彻底引爆。2010 年全球有 19 亿 7 千万网民,占全球人口的 28.7%[23]。因此互联网企业需要处理越来越多的数据,LinkedIn 作为一个全球性的社交网站,2010 年已经有超过 9000 万[24]的会员。它需要每天通过大量日志分析互联网用户的行为,进行产品优化与广告投放。大数据分析的基本范式 Lamdba[25,26]是通过数据采集组件从众多系统中采集数据,然后汇聚到 Spark 或者 Hadoop 等大数据平台。用户行为日志数据是通过分布式的采集程序进行日志获取,Hadoop 可以实现大量数据的批量分析,如何将海量的日志数据传输到 Hadoop 成为一个关键问题[27]。在数据集成的场景中 LinkedIn 最初的方案是通过 ActiveMQ 进行日志传输。然而在大数据集成的场景中,ActiveMQ 的性能问题暴露无疑。它虽然有完整的消息机制、灵活的配置方式以及安全的消息交付保证,但是对于 LinkedIn 传输海量数据的场景,并无帮助[28]。大数据集成场景需要将海量日志数据快速传输到大数据平台,并不需要复杂配置以及 AMQP 协议的支持,最需要的是高吞吐量的传输产品,这一点 AcitveMQ 无法满足。
在这样的背景下,2009 年底 LinkedIn 计划自研了新一代的消息产品 Kafka[29,30],以解决海量网站活动跟踪事件、应用监控指标 [31]、数据库等数据到大数据分析平台的传输。根据 Kafka 创始人 Jay Kreps 的分享,kafka 最初的设计主要有三个要求 [32]:每个节点每秒钟数百兆的数据吞吐量,所有数据都要持久化,数据分布式存储。这其中最大的挑战是既要求高吞吐量又要求消息的持久化。这是一个两难的需求,因为通常情况下如果需要高吞吐量,程序一般会将数据直接放到内存而不是磁盘,因为内存的读取速度更快。而如果需要数据的持久化,一般会将数据存储到磁盘上,但是磁盘读取的速度会非常慢。对于这个问题,研究了消息队列特殊的数据存储与传输模式后,基于对日志深入而独到的见解 [33],并且充分利用了操作系统软硬件的特点,Jay Kreps 团队给出了非常巧妙的设计方案[34],将数据以日志的形式顺序写到磁盘,并且顺序的读日志数据。由于硬盘的特殊结构,顺序写磁盘可以获得超过 100MB/s 的写入速度,甚至高于随机写内存。Kafka 读取数据也是顺序读取,而由于操作系统有 Page Cache 机制的原因,顺序读磁盘也可以获得接近读内存的性能。通过这样的方式,Kafka 虽然将消息写入了磁盘,但是获得了接近内存的读写速度,这就是 Kafka 高吞吐的奥秘。当然,kafka 还采用了批量发送、数据压缩、zero-copy[35] 三项技术,通过这些技术很大程度提高了 kafka 的吞吐量,并保障了消息的持久化。Kafka 高性能读写具体分析可参考这里 [36]。Kafka 的数据存储方式如下图,其将一个 Topic 分成若干个 Partition,生产者在发送数据时会按照一定的规则顺序向 Partition 中写入数据。而对于消息的一些特性,比如事务消息、延时消息、死信队列等,Kafka 并没有实现。
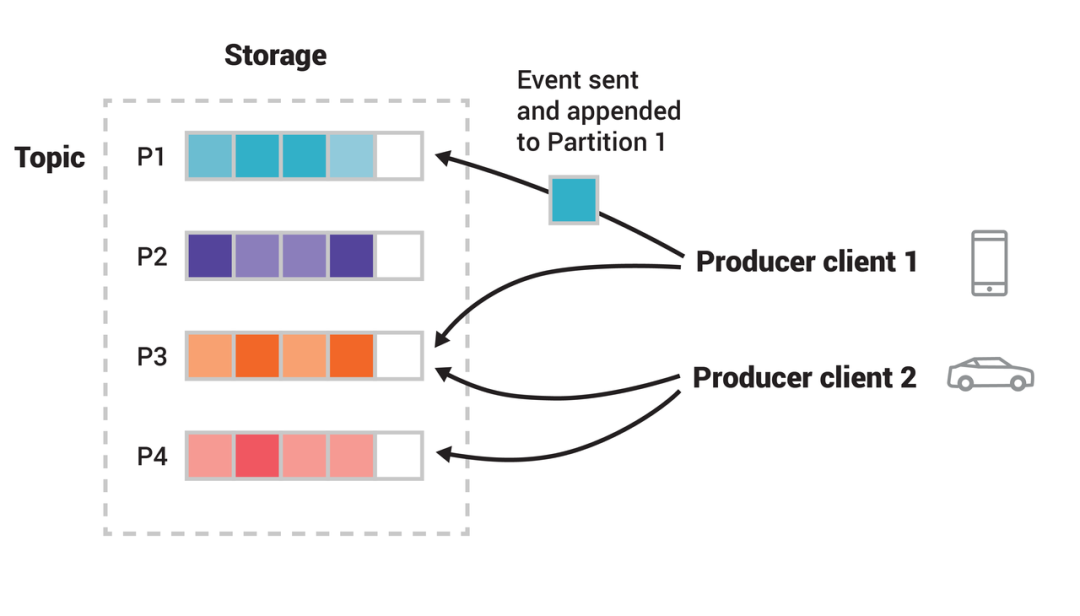
Kafka 的存储模式[37]
基于以上理念设计的 Kafka 达到了非常高的吞吐量,并且能够同时实现数据在磁盘的持久化。下图是 kafka 在 LinkedIn 上线后,Jay Kreps 团队将 kafka 与当时最流行的消息队列 ActiveMQ、RabbitMQ 性能对比情况 [38]。从下图可以看出由于 kafka 在生产消息和消费消息的吞吐量逗比其他两个消息系统有 4 倍以上的优势。
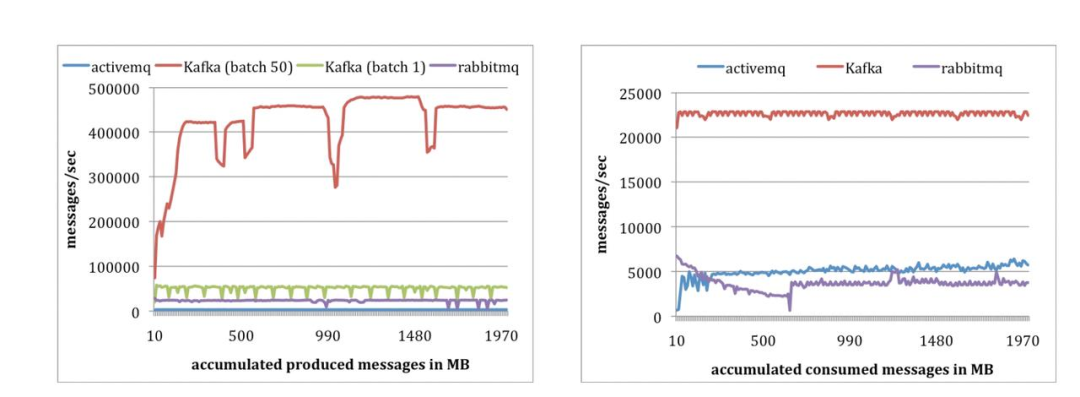
Kafka 于 2010 年底被开源,2011 年 7 月被 LinkedIn 捐献到了 Apache 基金会[39],2012 年 10 月 23 日 Kafka 从 Apache 毕业成为顶级开源项目。Kafka 用其独特的设计方式解决了大数据集成场景常见而且关键的问题,开源之后很快被 Twitter、Netflix、Uber 等硅谷互联网公司大量用于大数据分析场景 [40]。
2014 年 11 月 1 日 Kafka 创始团队成员宣布从 LinkedIn 离职,并创立了公司 Confluent[41],专注于 Kafka 产品的开源与商业化,Benchmark、LinkedIn 等为该公司投资 690 万美金。Confluent 成立之后,为了更全面的解决大数据分析问题,2016 年和 2017 年 Kafka 陆续推出了 Kafka Connect[42]和 KsqlDB 两款生态组件,一举奠定了 Kafka 大数据领域数据传输事实标准的地位。Kafka Connect 主要用于将 Kafka 与周边的产品更好的集成,比如通过 MySQL Source Connector 用户可以更好的将 MySQL 的变更数据抽取到 Kafka 系统。通过 Hadoop Sink Connector 用户可以将 Kafka 中的数据更方便地写到 Hadoop 中。Kafka KsqlDB 旨在实时处理 Kafka 传输的数据。比如大数据传输的过程中通常需要数据过滤、去重等 ETL 操作,借助 Kafka 的 KsqlDB 可以比较好的完成这些工作。下图是增加两个大数据组件后的 Kafka 生态架构图,详细分析可参考这里[43]。
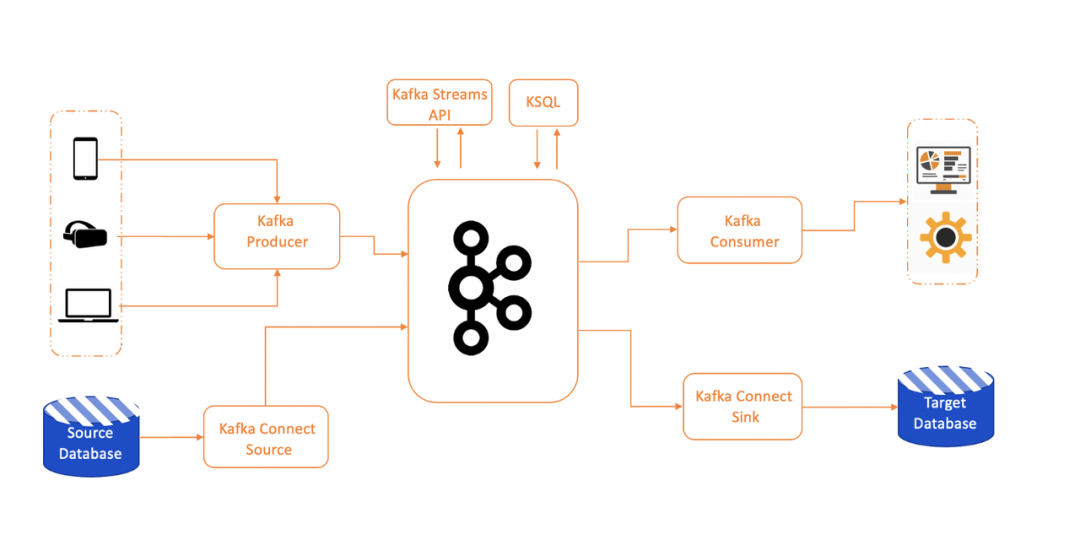
微服务时代
随着互联网的持续发展,越来越多的网民被民主的信息获取方式以及便捷的生活方式所吸引。网民的持续入场,对于互联网公司意味着持续飞速的业绩增长以及一波又一波的股市浪潮。2011 年谷歌市值为 1800 亿美元,员工总数 2.4 万多人[44]。而 2021 年谷歌市值逼近 2 万亿美金 [45],超过 2010 年 10 倍,人数超过 15 万人。然而应用软件,却面临着越来越大的挑战。为了应对数以亿计的网民的访问,应用软件不得不做架构性的重构,以保证越来越多的用户能够更顺滑的访问网站。
在这个大的背景下微服务进入了众多开发者的视野,任何一个技术并不是它发明的时候被人关注,而是需要的时候。微服务就是这样的技术,虽然微服务 [46] 在 2005 年就被提出,但实际上直到 2014 年之后才陆续被用于重构网站的后端系统,以应对越来越多的高并发访问。RocketMQ 就是因为这样的需求诞生的。为了应对双十一海量用户的访问,淘宝、天猫等阿里巴巴的网站陆续做了微服务化的改造。此前,电商系统只有几个大型的后端服务程序构成,为了提高整个网站的高并发能力,后端服务被重新构造成了数百个微服务。2010 年之前,淘宝网站服务通信是通过基于 ActiveMQ 构建的消息平台 Napoli 完成,Napoli 将消息持久化的数据库中 [47]。
随着阿里巴巴电商系统完成微服务改造后,如何为成百上千的微服提供异步通信能力成为关键问题。Napoli 由于需要将数据存储到数据库,吞吐量非常有限,无法支持大规模微服务集群的异步通信。Kafka 开源之后,阿里用 Java 重写了 Kafka 的核心逻辑,并命名为 MetaQ,希望能解决大规模微服务异步交互问题。Kafka 虽然有非常高的吞吐量与持久化能力,但还是无法支撑大规模微服务的场景 [48]。主要有三个核心问题:1 该场景需要较好的消息特性支持,比如事务消息、延时消息。例如,用户通常是在提交订单后付款,如果提交订单后长时间不付款,该订单会被取消。这个场景就用到了延时消息的能力。而 Kafka 没有这方面消息特性的支持。2 微服务场景下对单条消息的质量要求非常高,如果有任何一条消息丢失,就意味着订单数据的丢失。这种情况是业务无法容忍的,而 Kafka 消息丢失的情况时有发生。Kafka 最初的设计是为了提高消息的吞吐量,采用了批量消息发送的方式,该方式不利于消息安全性。大数据场景对于单条消息丢失是可以容忍的,因为单条消息通常不会影响大数据分析的整体结论。3 当 Kafka 创建多个 Topic 时非常不稳定,严重影响整个系统的吞吐量。这与 Kafka 系统模型的设计有很大关系。
鉴于以上情况,阿里自主研发一款可以满足大规模微服务场景的消息队列产品,并命名为 RocketMQ。RocketMQ 可以简单理解为 Kafka 和 RabbitMQ 的合体版。RocketMQ 实现了事务消息、延时消息、死信队列等消息特性。为了保证高吞吐量,RocketMQ 整体上采用的 Kafka 的存储模型,也采用了顺序读写的方案。但是为了提高消息的质量,RocketMQ 并没有采用消息批量发送和接收的方式,而是单条发、单条收。另外为了解决 Kafka 模型在大量 Topic 场景下性能不稳定的问题,RocketMQ 改进了 Kafka 的数据存储机制。Kafka 的设计是每个 Topic 包括若干个 Partition,每个 Partition 同一时刻只会写一个存储文件。当存储文件写满后(例如 1G),再写下一个存储文件。Kafka 的存储目录如下图[49]所示。
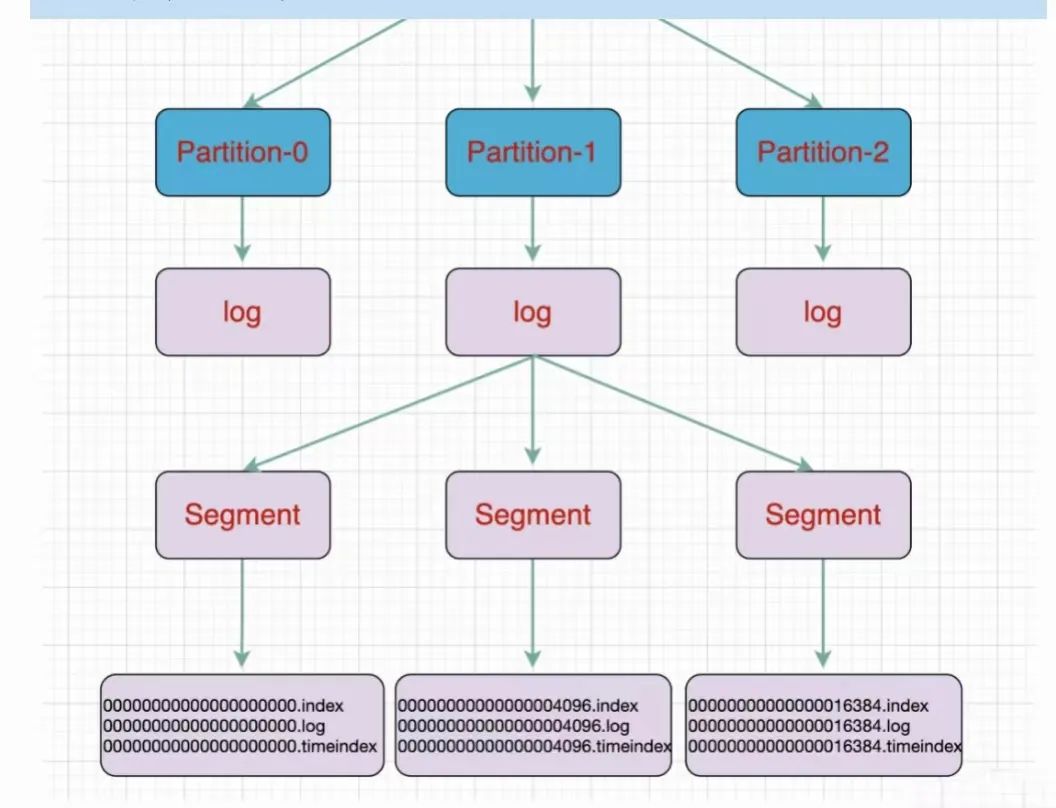
这样的存储机制在 Topic 比较少的情况下并不会有问题,大数据场景下通常 Topic 不需要设置太多。而用在大规模微服务的场景下由于业务的需求,需要设置很多 Topic,通常几百甚至上千个。当 Kafka 设置了几百个 Topic 后,由于其特有的存储模型,每个 Broker 节点会创建数百个文件,而众多的文件在被读取时,部分数据会被加载到操作系统的 Page Cache 中,使用过多的 Page Cache 会令系统极其不稳定。这也是为什么 Kafka 在多 Topic 时,性能表现很差的原因。而 RocketMQ 对这一点进行了改进,RocketMQ 将同一个 Broker 所有的 Partition(RocketMQ 中称之为 Message Queue)中的数据存储到一个日志文件中。这样虽然读取时会稍显复杂,但是可以解决多 Topic 的性能问题。
由于解决了消息队列应用在大规模微服务场景的问题,RocketMQ 在开源后受到互联网公司的很大关注。2019 年 RocketMQ 年获得“中国最受欢迎开源软件”第一名 [50]。在此之前,滴滴、微众银行、同程艺龙、快手等众多的互联网公司大数据分析场景和大规模微服务交互场景都使用了 Kafka,RocketMQ 开源之后,各大公司陆续将大规模微服务场景替换为 RocketMQ[51]。下图是滴滴 RocketMQ 和 Kafka 在使用不同消息大小,在不同 Topic 数量下的对比测试[52]。

从测试可见,最上面第一组数据,使用的是 Kafka 开启消费,每条消息大小为 2048 字节。Topic 数量不断增加,当到 256 Topic 之后,其吞吐急剧下降。第二组是 RocketMQ,Topic 增大影响非常小。第三组和第四组,是上面两组关闭了消费的情况,结论与上面两组基本类似,整体吞吐量会高一点点。
从云计算到云原生
互联网对人类的贡献当然不仅仅是信息的民主化,还为我们催生了云计算技术。2000 年美国知名在线购物平台 Amazon 推出了一项名为 Merchant.com 的电子商务服务[53],以帮助第三方商家在 Amazon 的电子商务引擎之上构建在线购物网站。为了 Merchant.com 项目的顺利推进,Andy Jassy 带人用 API 的方式完全重构了 Amazon 的内部系统,以保证内部团队和第三方商家都可以顺利的与 Amazon 的电商引擎集成。2003 年 Andy Jassy[54]提出了打造互联网操作系统的构想,希望为更多公司提供在线的计算、存储等软件基础设施,帮助用户更简单的构建软件系统。2004 年 AWS 推出了第一个基础设施服务:简单队列服务(SQS)[55]。2006 年陆续推出了 S3 和 EC2,至此 Amazon 的在线 Web 服务基本框架基本形成,也因此为全球创造了一个每年超过数千亿美金[56]的超级大市场——云计算时代大幕被拉开。
云计算为需要构建软件系统的企业提供了非常好的体验,一方面 AWS 等云计算平台提供了虚拟计算机,用户在 AWS 平台上构建软件系统无需再购买计算机,只需租用 AWS 的虚拟计算机即可。另一方面,AWS 还提供了消息队列、数据库、存储等常用组件,使用户构建软件系统非常方便。2010 年之后,互联网公司飞速发展,云计算的需求也越来越强烈。所有的互联网公司都是软件公司,都有构建软件系统的需要。互联网公司要求响应性更高,而且更看重成本,云计算无疑是互联网公司最好的选择。这一点通过 AWS 的财报就可以看出,2006 年 AWS 营收只有 2100 万美金,随着互联网崛起以及全球企业数字化转型热情的高涨,AWS 营收一路飞涨。2021 年全球营收超过 1500 亿美金,Amazon 最高市值逼近 2 万亿美金。
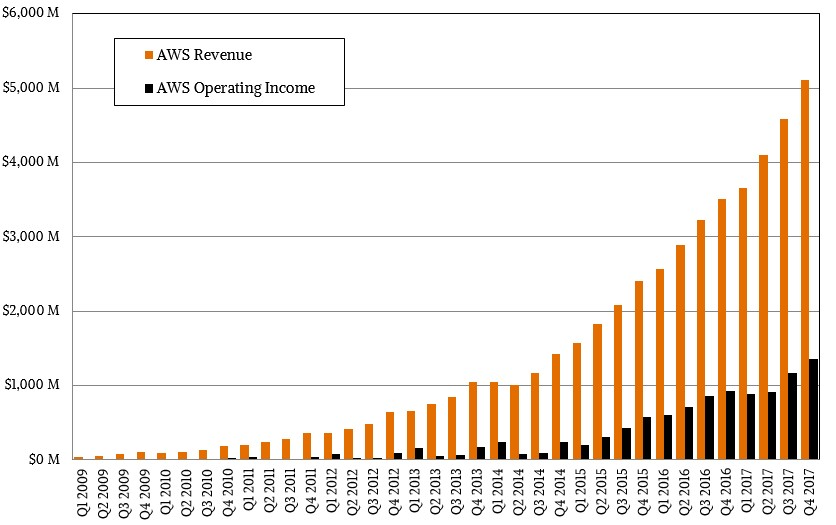
NAVIGATING THE REVENUE STREAMS AND PROFIT POOLS OF AWS[57]
随着云计算在各个企业的深入落地,也暴露出许多问题,其中成本问题最为突出。很多互联网企业基于云厂商的云服务构建软件后发现,成本比之前买服务器还要高很多。采购服务器硬件只需要付费一次,而基于云服务构建需要按时间缴费。例如,市面上采购一个 8 核 16G 的硬件服务器,价格一般在 1.7 万元 [58] 左右。而在某云计算机提供商购买 8 核 16G 的云服务器,每年租用的价格为 1.8 万元[59],与采购一台硬件服务器价格相当。为了解决使用云计算的成本问题,让企业能更好的享受到云计算的红利,云原生在这种背景下诞生了。云原生不仅仅是一类技术,更是一种理念,希望企业用云计算原生的方式去构建软件系统。什么是云计算原生的方式,首先应用是弹性的,按需运行的。按照云计算的愿景,基于云构建的软件应该是有需要才会运行。比如一个网站,没有用户访问时最好不运行,访问的用户多了可以启动更大的集群支撑海量用户访问。由于虚拟机是按量付费,如果基于虚拟机构建的网站在没有访问的时候也运行,一样是需要付费的。所以对于企业来讲,最好的方式是有一类技术,让其构建出按照访问情况运行的软件。Serverless 就是这样的技术,Serverless 为企业用户提供了一种原生使用云计算的关键能力,即只有在需要的时候软件才会运行。
Serverless 一词是 2012 年由 Iron 公司提出 [60],如同云计算一样,Serverless 形态的产品其实早已经存在。2008 年谷歌就推出了 Serverless 形态产品 Google App engine[61]。正如前文所说,任何一个技术并不是在它发明的时候被人关注,而是需要的时候。微服务如此,Serverless 同样如此。2014 年 AWS 推出 Serverless 产品 Lamdba 后,由于使用云计算的互联网企业降本诉求强烈,Lamdba 被越来越多的企业所采用。之后 Azure、GCP 等主流云计算提供商也陆续推出相应的 Serverless 产品。曾经成功预测云计算时代的伯克利大学 2019 年再次撰写《Cloud Programming Simplified: A Berkeley View on Serverless Computing》[62] 一文,预测 Serverless 是云计算下一个十年的发展方向。论文里也给出了关于 Serverless 的定义,简单来讲就是 Serverless Computing,由 FaaS + BaaS(Backend as a Service)构成一个 Serverless 软件架构。特点就是能够按需弹性、按需付费。2020 年 AWS 有一半的用户采用了 Lamdba 构建其业务系统。根据 Datadog 的调查报告,2021 年 Lamdba 被调用的次数相比两年前增长了 350%。

Serverless 时代
虽然 Serverless 已经走过了漫长的道路,但这仅仅是开始。Serverless 颠覆性的运行模式,使软件的架构发生了极大的变化,这也给软件系统的构建带来了非常大的机遇与挑战。Serverless 因为其按需运行的特性非常好的履行了云计算的承诺,也契合了用户将本增效的本质需求,注定会成为云计算下一个十年的主角。一个全新的时代呼之欲出,让我们一起看一下这个新的时代可能的一些变化。
1 EDA 将会替代 SOA 成为未来软件架构的典型范式
Event Driven Architecture(EDA)[63]并不是一种新的技术,但正如前文所言,任何一个技术并不是它发明的时候被人关注,而是需要的时候。没有任何时代像 Serverless 时代一样需要 EDA 技术。因为 Serverless 特有的按需运行的特性,通过 EDA 的方式触发 Serverless 程序将成为最流行的模式。在软件架构演进的历史中基于 Service-oriented architecture(SOA)[64]的设计模式一直是主角,而 RPC 一直是 SOA 架构软件的默认模式,所以过去程序之间的绝大部分通信方式是同步通信。而 Serverless 的出现使得异步通信方式或许会成为主角。下图源自 2022 年是 Datadog 的 Serverless report[65] 。

排名前四的 Lamdba 触发方式中,除了 API GATEWAY,SQS、EVENTBRIDGE、SNS 都采用了异步的方式。可以预见,未来消息系统将是 Serverless 最主要的触发源,企业通过事件驱动的形式构建软件系统将成为新常态。
2 Serverless 将通过事件驱动的方式连接云中的一切。
RPC 这种同步通信模式和消息的异步通信模式非常不同,程序通过 RPC 方式通信如同打电话,需要双向通信。一方发起请求后,对方必须响应,如果不响应通信就会失败。而且同一时间程序只能响应一个 RPC,其他程序只能占线。而异步通信更像在 Facebook 中发一条消息给对方,对方是否在线不影响通信,而且可以同时与多人通信。Serverless 因为采用异步方式通信带来一个巨大的收益,软件集成的成本被大大降低。之前基于 SOA 的软件设计理念,一个系统中所包含的微服务最多在百量级。过多的服务会令系统非常复杂,可用性急剧下降。而通过事件驱动构建的系统可以容纳成千上万的 Serverless 程序,而且受地域的影响比较小。因为过去服务之间基于 RPC 通信,如果两个服务跨云或者跨数据中心有可能因为超时、网络故障等原因导致通信失败,而异步通信这种情况大大降低。
由于异步通信的优势,使得跨云、跨地域基于 Serverless 构建大规模的业务系统成为可能。这将为未来数字化企业构建大规模人工智能、物联网、自动驾驶等系统打开了更多的可能性。比如,未来物联网系统一定是跨云、边、端共同构建,云端负责大数据分析,边缘端负责数据汇聚与实时分析,终端负责数据上报以及命令执行。同时,这种通信方式给企业构建业务系统带来了更多的可能性。过去用户业务系统基本在一个云上构建,但基于多云构建的业务系统会让用户避免厂商锁定、成本更低、竞争力更强。想象这样一种场景,用户需要基于 Serverless 构建一个图像处理的场景。AWS S3 存储图片非常方便,而且成本低,但是谷歌云的图像处理服务精度更高、速度更快。这种情况下最好的解决方案是通过事件驱动的方式跨云构建图像处理通信。图像存储到 AWS 的 S3,每当图像被存储后通过事件的方式触发谷歌云的 Serverless 程序调用图像服务完成图像处理。
3 CloudEvents 将成为未来应用通信新的事实标准。
新的时代需要新的标准,Serverless 时代用户构建的业务系统特点是规模更大、跨范围更广、服务更加多元。前两个特点上文已经解释。对传统的 SOA 架构的系统,主要有若干的用户开发的服务构成,构成相对单一。而 Serverless 时代的业务系统包括大量 Serverless 服务,众多数量的云服务(可能来自不同的云计算提供商)、甚至还可能有物联网设备。大量的跨多云异构系统之间需要频繁的通信,这需要统一的数据标准。而从目前来看,CloudEvents 无疑是最好的选择。CloudEvents 是 CNCF 发起的旨在帮助云提供商之间的函数可移植性和事件流处理的互操作性而制定的标准。它天生具有对 Serverless 非常好的亲和性,而且得到了 Knative、OpenFaaS、Serverless.com[66]、IBM Cloud Code Engine 等众多 Serverless 产品的支持。目前,市场上并没有一款能够完全支持 CloudEvents 协议的消息产品出现。
在 Serverless 时代基于 EDA 构建软件系统,消息系统无疑会成为最核心的基础组件。但是目前的 MQ 在 Serverless 场景下支持事件收发挑战巨大。目前主流的 MQ 大都是在 2010 年左右诞生,当时主要是为了解决大数据和大规模微服务的场景而研发,当时它们对于 Serverless 几乎一无所知。所以站在 Serverless 的视角审视,目前主流 MQ 的架构设计支持基于 Serverless 构建的应用软件会碰到非常多的问题。
主要表现在四方面:第一个问题是传统 MQ 无法直接触发 Lamdba 等 Serverless 产品运行。核心原因是目前 MQ 的消费者与服务直接通信基本都是基于 TCP 协议,无论是 Kafka、RabbitMQ。TCP 是面向连接的协议,通信之前双方需要建立一个 connection,而且需要一直维护这条 connection。而 Serverless 需要面向无连接的通信模型,因为 serverless 有一个非常关键的特性是按需运行,因而无法使用 TCP 通信。所以现在业界主流的 Cloud Function,例如 AWS Lambda、Knative、OpenFaaS 等都是采用 Http 协议进行通信。而且,目前的消息队列大多数采用 Pull 的消费模型,而目前的主流队列都是采用 Push 模型。Gartner 在 2020 年关于如何选择合适的 Event Broker 的报告中也很有预见性的指出了这个问题[67]。
第二个问题是目前消息系统极大的限制了 Serverless 应用的弹性能力。以 Kafka 为例,按照其存储模型,每个 topic 分成若干个 partition。因为每个 partition 只能有一个消费者消费消息,这意味着 kafka 下游系统消费单个 topic 的集群规模不能大于该 topic partition 数量。这在传统的大数据场景中并没有问题。但是如果 kafka 下游是应用是 serverless 集群,问题比较严重。因为即使 serverless 按照扩缩策略弹出很多消费者实例,但是多于 Partition 的消费者只能空闲无法消费数据 [68]。当然开发者可以选择手动修改扩大 partition 的数量,但是这无法响应快速变化的业务。而且当一段时间消费者集群收缩后,过多的 Partition 对系统资源也是很大是浪费。
第三个问题是 Serverless 需要处理大量的云事件,在传输的过程中可能需要对这些事件进行过滤、转换等处理,而目前主流消息队列处理能力比较弱。Kafka 本身没有事件处理能力,其消息过滤能力是通过 KSQL 提供的,RabbitMQ、ActiveMQ 等就没有提供消息处理的能力。
第四个问题目前主流的消息队列在提供负载均衡时大多采用了 Reblance 的机制,每当有使用消息队列的消费者加入到集群或者从集群离开时,都会触发消息队列 Reblance。该机制会触发消费集群所有的客户端重新负载均衡。在 Serverless 场景下,由于系统需要频繁切换启动、停止等动作。这会频繁触发系统的 Reblance,这种情况会给系统带来非常大的开销。
如果想更好的支持 Serverless 场景,从上面分析看,未来的消息系统需要应该具备以下的特点:
· 原生支持 HTTP 协议,消息的接收采用 push 模式,push 模式可以直接将消息推送给 Serverless 系统完成事件的触发。
· 原生支持 CloudEvents[69] 标准事件发送,CloudEvents 是云原生时代全新的事件交互标准,目前得到了诸如 Knative、OpenFaaS 等主流开源 Serverless 平台支持。
· 原生支持 CloudEvents 标准可以将事件直接投递给 Serverless 平台,更方便。
· 提供过滤、转化等更加丰富的事件处理能力。解决当前消息队列的 Reblance 问题。原生基于新的云原生基础设施 Kubertenes 设计,具备自动弹性扩缩的能力。
目前能很好支持 Serverless 场景的消息产品比较少,AWS、Azure 等云计算厂商提供 EventBridge 或许是一个选择,EventBridge 提供了 push 事件的能力可以直接触发 Serverless 程序,而且提供一定的事件过滤等能力。但是云厂商提供的 EventBridge 存在的普遍问题是让自己公司的云产品可以较好的完成事件交互,而对其他公司提供的云产品以及开源产品支持的能力较弱。这导致的结果是企业采用了 EventBrigde 本来是想完成应用之间消息的互通,但却被困在 EventBrigde 中。历史总是惊人的相似,这与 AMQP 协议出现之前的场景非常类似。当然有需求才会催生新的产品和技术,下面是几款近两年诞生的,比较适用于 serverless 场景的消息队列,供读者参考。
Serverless 时代的 MQ
1 Vanus vanus.ai
Vanus(vanus.ai) 是一个开源的无服务器事件流平台,具有内置的事件处理功能。它可以连接云函数、 SaaS、云服务和数据库,帮助用户构建下一代事件驱动的应用程序。Vanus 将存储和计算资源分离,原生支持 CloudEvents 标准。同时其通过内置函数的方式提供了通用、灵活的过滤和转换能力,可以帮助开发者无代码做事件处理。
Vanus 原生基于 Kubertenes 设计,具备完全的弹性能力。可以根据事件流量自动扩展或缩减集群。Vanus 非常轻量,可以 1 键部署,几十秒可以完成安装。而且其无缝集成了 Serverless,可以将事件无缝的投递给 AWS Lambda、Knative 等云函数与 FaaS 平台。
2 Redpanda redpanda.com
Redpanda 是一个开源分布式事件流平台,可用作高性能消息队列。Redpanda 做了原生兼容 Kafka 的设计,而且提供了多项改进,例如更快的性能、更低的延迟和更好的可扩展性。
Redpanda 消息队列允许多个生产者将消息写入单个主题,多个消费者并行读取来自该主题的消息。消息可以缓冲在内存中以实现快速传递,也可以持久保存到磁盘以实现持久性。Redpanda 还提供许多功能,例如复制、分区和压缩,以帮助管理大量数据。使用 Redpanda 消息队列的主要好处之一是它能够实时处理大量数据。这使其成为需要高吞吐量和低延迟的应用程序的热门选择,例如流分析、实时监控和在线游戏。
3 KubeMQ kubemq.io
KubeMQ 也是一个 Kubernetes 原生消息队列和消息系统,为分布式应用程序提供可靠、可扩展和高性能的消息基础设施。它旨在易于在 Kubernetes 环境中部署、操作和使用。
KubeMQ 构建为一组微服务,可以作为容器部署在 Kubernetes 集群上。它包括消息队列、发布 / 订阅消息传递、请求 / 回复消息传递和事件驱动的消息传递等功能。KubeMQ 的主要优势之一是它被设计为具有高可用性和容错性。它包括自动分片、数据复制以及数据备份和恢复等功能,这些功能有助于确保即使在节点故障或网络中断的情况下也能可靠地传递消息。
4 memphis memphis.dev
Memphis 是一个开源的云原生消息队列和流媒体平台。它旨在为分布式应用程序提供可靠且可扩展的消息传递基础架构。Memphis 可以部署在 Kubernetes 上,它支持多种消息模式,包括发布 / 订阅、请求 / 回复和流处理。
Memphis 使用 Rust 构建,Rust 以其性能、可靠性和安全性著称。该平台使用分布式架构,允许水平扩展和高可用性。它还包括消息持久化、消息过滤和消息批处理等功能,有助于确保可靠地传递和处理消息。
Memphis 的主要优点之一是它的简单性和易用性。它提供了一个简单直观的 API,可以与多种编程语言一起使用,包括 Rust、Python 和 Java。此外,它还包括一个基于 Web 的管理控制台,允许用户监控消息流量、查看统计数据和管理消息传递基础结构。
作者简介
厉启鹏,vanus.ai CEO,开源爱好者,北京大学硕士。曾就职于阿里云,Apache RocketMQ PMC , 长期专注于云基础设施及中间件架构设计与研发。
参考文献
- TIBCO Staff.A Look Back: Vivek Ranadivé and TIBCO.TIBCO Blog.January 25, 2013. https://www.tibco.com/blog/2013/01/25/a-look-back-vivek-ranadive-and-tibco/
- Vivek Ranadivé.Wikipedia. https://en.wikipedia.org/wiki/Vivek_Ranadiv%C3%A9
- Lawrence M. Fisher.Reuters Is Buying Teknekron.The New York Times.December 18, 1993. https://www.nytimes.com/1993/12/18/business/company-news-reuters-is-buying-teknekron.html
- TIBCO Software. Wikipedia.https://en.wikipedia.org/wiki/TIBCO_Software
- LAURA LORENZETT.TIBCO Software goes private with $4.3 billion Vista Equity purchase,FORTURN.September 30, 2014. https://fortune.com/2014/09/29/tibco-software-goes-private-with-4-3-billion-vista-equity-purchase/
- Introduction to IBM WebSphere MQ. IBM Website. May 27,2022. https://www.ibm.com/docs/en/ibm-mq/7.5?topic=mq-introduction-websphere
- IBM MQ.Wikipedia.https://en.wikipedia.org/wiki/IBM_MQ
- Compare Amazon MQ. Apache Kafka, Google Cloud Pub/Sub, and IBM MQ. g2.com.https://www.g2.com/compare/amazon-mq-vs-apache-kafka-vs-google-cloud-pub-sub-vs-ibm-mq
- IBM MQ. IBM Product Website.https://www.ibm.com/products/mq
- Application Infrastructure and Middleware Market Share WorldWide 2019-2020.Gartner.2021.
- Jakarta Messaging. Wikipedia. https://en.wikipedia.org/wiki/Jakarta_Messaging#cite_note-jms-101-spec-4
- Mark Hapner,Rich Burridge,Rahul Sharma.Java Message Service,October5,1998.https://web.archive.org/web/20001010161718/http://www.java.sun.com/products/jms/jms-101-spec.pdf
- Apache ActiveMQ. Wikipedia. https://en.wikipedia.org/wiki/Apache_ActiveMQ#cite_note-support-16
- Martin LaMonica.Investors to commercialize open source.CNET.May 20, 2005. https://www.cnet.com/tech/tech-industry/investors-to-commercialize-open-source/
- Stefan Tilkov,Floyd Marinescu.IONA acquires LogicBlaze, supporters of ActiveMQ and ServiceMix ESB.InfoQ.APR 10, 2007. https://www.infoq.com/news/2007/04/iona-buys-logicblaze/
- Advanced Message Queuing Protocol.Wikipedia. https://en.wikipedia.org/wiki/Advanced_Message_Queuing_Protocol
- RabbitMQ.Wikipedia. https://en.wikipedia.org/wiki/RabbitMQ
- Acquisitions.VMware Website. https://www.vmware.com/company/acquisitions.html
- Apache Qpid.Qpid Website.https://qpid.apache.org
- RabbitMQ VS Apache Qpid.libhunt.https://www.libhunt.com/compare-rabbitmq-server-vs-qpid
- Rabbit MQ vs Apache QPID - picking your AMQP broker. batey.info. http://www.batey.info/
- LOVISA JOHANSSON(September 23, 2019),Part 1: RabbitMQ for beginners - What is RabbitMQ? ,CloudAMQP Blog. https://www.cloudamqp.com/blog/part1-rabbitmq-for-beginners-what-is-rabbitmq.html
- INTERNET GROWTH STATISTICS.internetworldstats.com. https://www.internetworldstats.com/emarketing.htm
- Numbers of LinkedIn members from 1st quarter 2009 to 3rd quarter 2016. statista.com . October 2016.https://www.statista.com/statistics/274050/quarterly-numbers-of-linkedin-members/
- Big data architecture style. microsoft.com. https://docs.microsoft.com/en-us/azure/architecture/guide/architecture-styles/big-data
- Lambda architecture. Wikipedia.https://en.wikipedia.org/wiki/Lambda_architecture
- Jay Kreps.The Evolution of Apache Kafka: From In-House Infrastructure to Managed Cloud Service.YouTube.Feb 25,2022. https://www.youtube.com/watch?v=SQX6nGS5RcA
- Tanvir Ahmed.Kafka's origin story at LinkedIn.Linkedin.Oct 20,2019. https://www.linkedin.com/pulse/kafkas-origin-story-linkedin-tanvir-ahmed/ .
- Daniel Gutierrez .A Brief History of Kafka, LinkedIn’s Messaging Platform .insidebigdata.com.April 28, 2016.https://insidebigdata.com/2016/04/28/a-brief-history-of-kafka-linkedins-messaging-platform/
- Jay Kreps on the Last 10 Years of Apache Kafka and Event Streaming.confluent website.
- Apache Kafka.hadoopadmin.co. http://www.hadoopadmin.co.in/hadoop-developer/kafka/https://www.youtube.com/watch?v=aJuo_bLSW6s
- Jay Kreps. Apache Kafka and Real-Time Data Integration.YouTobe.June26, 2016. https://www.youtube.com/watch?v=aJuo_bLSW6s
- Jay Kreps.The Log: What every software engineer should know about real-time data's unifying abstraction.Linkedin.December 16. 2013. https://engineering.linkedin.com/distributed-systems/log-what-every-software-engineer-should-know-about-real-time-datas-unifying
- Ken Goodhope, Joel Koshy, Jay Kreps, Neha Narkhede, Richard Park, Jun Rao, Victor Yang Ye.Building LinkedIn’s Real-time Activity Data Pipeline.Computer Science.2012. http://sites.computer.org/debull/A12june/pipeline.pdf
- Zero-copy. Wikipedia. https://en.wikipedia.org/wiki/Zero-copy
- Talk about Kafka: why is Kafka so fast? developpaper.com . Oct 10, 2021. https://developpaper.com/talk-about-kafka-why-is-kafka-so-fast/
- Kafka 3.2 Documentation.Kafka Website.https://kafka.apache.org/documentation/#introduction.
- Jay Kreps, Neha Narkhede, and Jun Rao. Kafka: a distributed messaging system for log processing. ACM SIGMOD Workshop on Networking Meets Databases, page 6, 2011. https://engineering.linkedin.com/content/engineering/en-us/blog/authors/j/jay-kreps
- Neha Narkhede.First Apache release for Kafka is out!.Linkedin Engineering.January 6, 2012. https://engineering.linkedin.com/kafka/first-apache-release-kafka-out
- Jun Rao,Jay Kreps.Apache Kafka Users.Apache Kafka website.July 25,2106. https://cwiki.apache.org/confluence/display/KAFKA/Powered+By
- Jay Kreps.Announcing Confluent, a Company for Apache Kafka and Realtime Data.Confluent Blog.NOV 1, 2014. https://www.confluent.io/blog/announcing-confluent-a-company-for-apache-kafka-and-real-time-data/
- Open Source Kafka Connect Adds More than a Dozen Connectors. Confluent Blog.April 22, 2016. https://www.confluent.io/press-release/open-source-kafka-connect-adds-more-than-a-dozen-connectors/
- Navdeep Sharma.Understanding the EcoSystem of Apache Kafka.medium.Aug 9, 2019. https://medium.com/@navdeepsharma/the-ecosystem-of-apache-kafka-6087b621d16f
- Alphabet: Number of Employees 2010-2022 | GOOG.macrotrends.2022. https://www.macrotrends.net/stocks/charts/GOOG/alphabet/number-of-employees
- Market cap history of Alphabet (Google) from 2014 to 2022.companiesmarketcap.June 2022. https://zh.m.wikipedia.org/wiki/Google
- Microservices.Wikipedia. https://www.infoq.cn/article/79tlsolfsktqsg9obwwd
- Von Gosling,Wang Xiaorui.Apache RocketMQ - Trillion Messaging in Practice.YouTobe.May 22,2017. https://www.youtube.com/watch?v=H9HGE9VOimY .
- 冯嘉.展望Apache RocketMQ5.0 | 谈RocketMQ的过去、现在和未来.Likes.2018. https://www.likecs.com/show-204717665.html
- https://img-blog.csdnimg.cn/785b9ba8492e45d9841193de2960c784.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5py65pm65YW1,size_20,color_FFFFFF,t_70,g_se,x_16
- 2019年度最受欢迎中国开源软件.2019.Oschina. https://www.oschina.net/project/top_cn_2019
- Apache RocketMQ. https://rocketmq.apache.org/users/
- 江海挺.滴滴出行基于RocketMQ构建企业级消息队列服务的实践.CSDN. November 6, 2018. https://blog.csdn.net/b6ecl1k7BS8O/article/details/83805620
- Ron Miller.How AWS came to be.TechCrunch.July 2, 2016. https://techcrunch.com/2016/07/02/andy-jassys-brief-history-of-the-genesis-of-aws/
- Kevin McLaughlin.Andy Jassy: Amazon's $6 Billion Man.CRN.August 04, 2015. https://www.crn.com/news/cloud/300077657/andy-jassy-amazons-6-billion-man.htm
- Jeff Barr.The AWS Blog: The First Five Years.09 NOV 2009.AWS Website https://aws.amazon.com/cn/blogs/aws/aws-blog-the-first-five-years/
- Guoqiang Yang.IDC:2021年全球云计算市场超900亿美元 阿里云市场份额排名全球第三,STCN.April 28, 2022.https://www.stcn.com/company/gsdt/202204/t20220428_4466952.html
- Timothy Prickett Morgan.NAVIGATING THE REVENUE STREAMS AND PROFIT POOLS OF AWS.The Next Platform.February 5, 2018. https://www.nextplatform.com/2018/02/05/navigating-revenue-streams-profit-pools-aws/
- 戴尔PowerEdge R750xs 机架式服务器参数,Pconline. https://product.pconline.com.cn/server/dell/1453647_detail.html
- 云服务器CVM,Tencent Cloud.https://buy.cloud.tencent.com/price/cvm/calculator?devPayMode=hourly®ionId=33&zoneId=330001&instanceType=S6.2XLARGE16&imageType=linux&systemDiskType=CLOUD_PREMIUM&systemDiskSize=50&bandwidthType=TRAFFIC_POSTPAID_BY_HOUR&bandwidth=5&timeSpan=12&hourlyValue=12
- 洛浩. 一文读懂 Serverless 的起源、发展和落地实践.CSDN.January 18, 2022. https://blog.csdn.net/yunqiinsight/article/details/122565912
- Serverless computing.Wikipedia.https://en.wikipedia.org/wiki/Serverless_computing
- University of California at Berkeley.Cloud Programming Simplified: A Berkeley View on Serverless Computing.February 10, 2019. https://www2.eecs.berkeley.edu/Pubs/TechRpts/2019/EECS-2019-3.pdf
- Event-driven architecture.Wikipedia.https://en.wikipedia.org/wiki/Event-driven_architecture
- Service-oriented architecture,Wikipedia. https://en.wikipedia.org/wiki/Service-oriented_architecture
- The state of Serverless.Datadog.June, 2022.https://www.datadoghq.com/state-of-serverless/
- Serverless.com.https://www.serverless.com/
- Gary Olliffe.Choosing Event Brokers: The Foundation of Your Event-Driven Architecture. Gartner. June 22,2020.page 12.
- Best message queue for HPA on kubernetes.Reddit.2022.https://www.reddit.com/r/kubernetes/comments/uk8pj5/best_message_queue_for_hpa_on_kubernetes/
- Why CloudEvents?.CloudEvents. https://cloudevents.io/