前言
首先咱们先看看舔狗的卑微经历吧

看看这卑微的聊天记录,就是那种你发十句,别人不稀得回一句的那种,虽然是舔狗吧,但也玩出花吗,最近刚发现了一个舔狗网站,来看看怎么把舔狗玩出花吧

分析页面
其实很简单的一个页面,总的流程就是实现点击换页,然后进行文本的获取 先来看看页面

主要就是两步,通过xpath获取到文本和按钮,然后进行分别操作,先来写一下xpath
因为整个页面只有一个按钮标签,所以获取按钮的xpath很简单,如下图所示
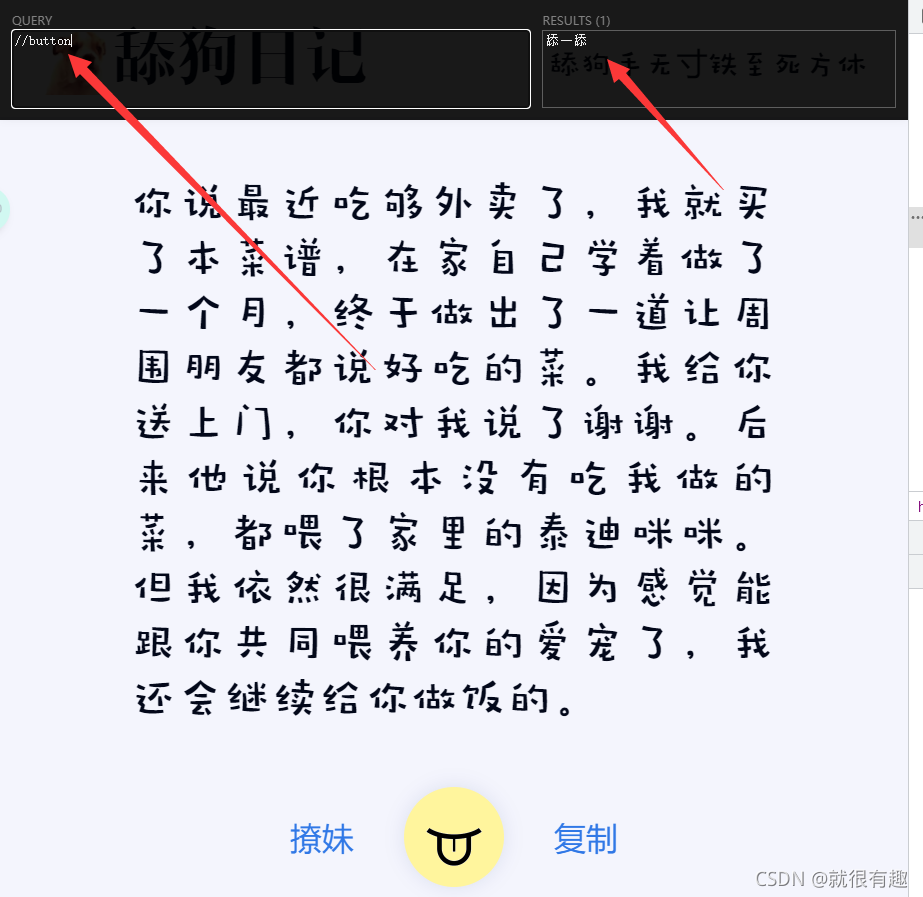
然后来获取文本内容,与按钮相同,该页面中也只有一个article标签,所以很容易写xpath,如下图,很简单就拿到了
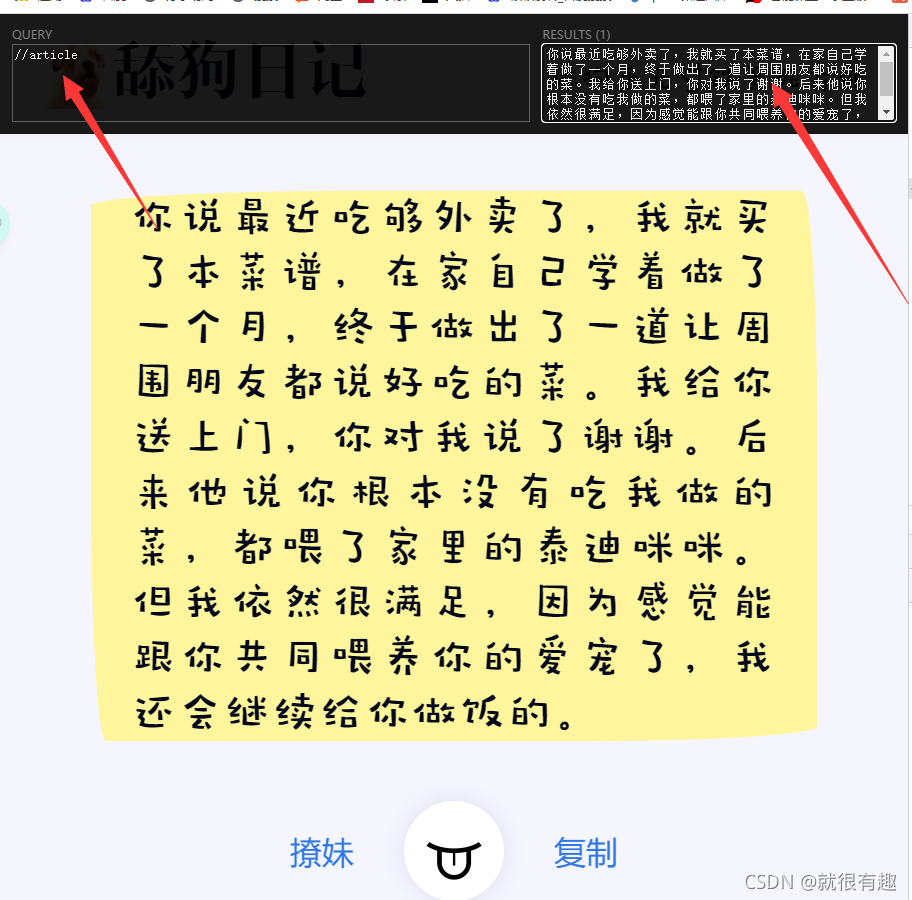
这样其实就完成了,然后接下来就可以开始写代码了
主要代码
selenium伪装
代码语言:javascript
复制
url = 'https://www.nihaowua.com/dog.html'
# 躲避智能检测
option = webdriver.ChromeOptions()
# option.headless = True
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=option)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',
{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
driver.get(url)获取文本内容
代码语言:javascript
复制
text = driver.find_element(By.XPATH, '//article')
print(text.text)获取按钮并点击
代码语言:javascript
复制
button = driver.find_element(By.XPATH, '//button')
button.click()完整代码
代码语言:javascript
复制
url = 'https://www.nihaowua.com/dog.html'
# 躲避智能检测
option = webdriver.ChromeOptions()
# option.headless = True
option.add_experimental_option('excludeSwitches', ['enable-automation'])
option.add_experimental_option('useAutomationExtension', False)
driver = webdriver.Chrome(options=option)
driver.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',
{'source': 'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'
})
driver.get(url)
i = 0;
while 1:
text = driver.find_element(By.XPATH, '//article')
print(text.text)
value = text.text
button = driver.find_element(By.XPATH, '//button')
button.click()
time.sleep(1)
driver.switch_to.window(driver.window_handles[0])成果
这光看不存好像不大符合我这白嫖心理,就把这些内容存在数据库里,有需要sql文件的xdm可以私信我

总之,蛮简单的一个小爬虫,没事的时候写写,防止自己忘了基础使用
仅供学习,侵权必删