视频流程讲解
(咕咕咕中)
背景
当时,在乱搞网站时候,它的默认随机图比较少,心生一念,我自己爬虫爬点下来不就有了?
然而,由于本人过于热衷于充满快乐多巴胺的生活(颓废),很显然就咕咕咕了,也没想着再做。
昨日,爬了ewt后,思绪继续随着时间线向前延伸,想起来要爬图片了!(虽然我现在发现,我大部分文章都会自己发的时候找好配图,随机图好像没大用处??)
另外,因本人技术力有限,无法标明作者,十分抱歉。
ps.只是爬了30页,懒得爬更多了,同时也为了避免不必要的影响。
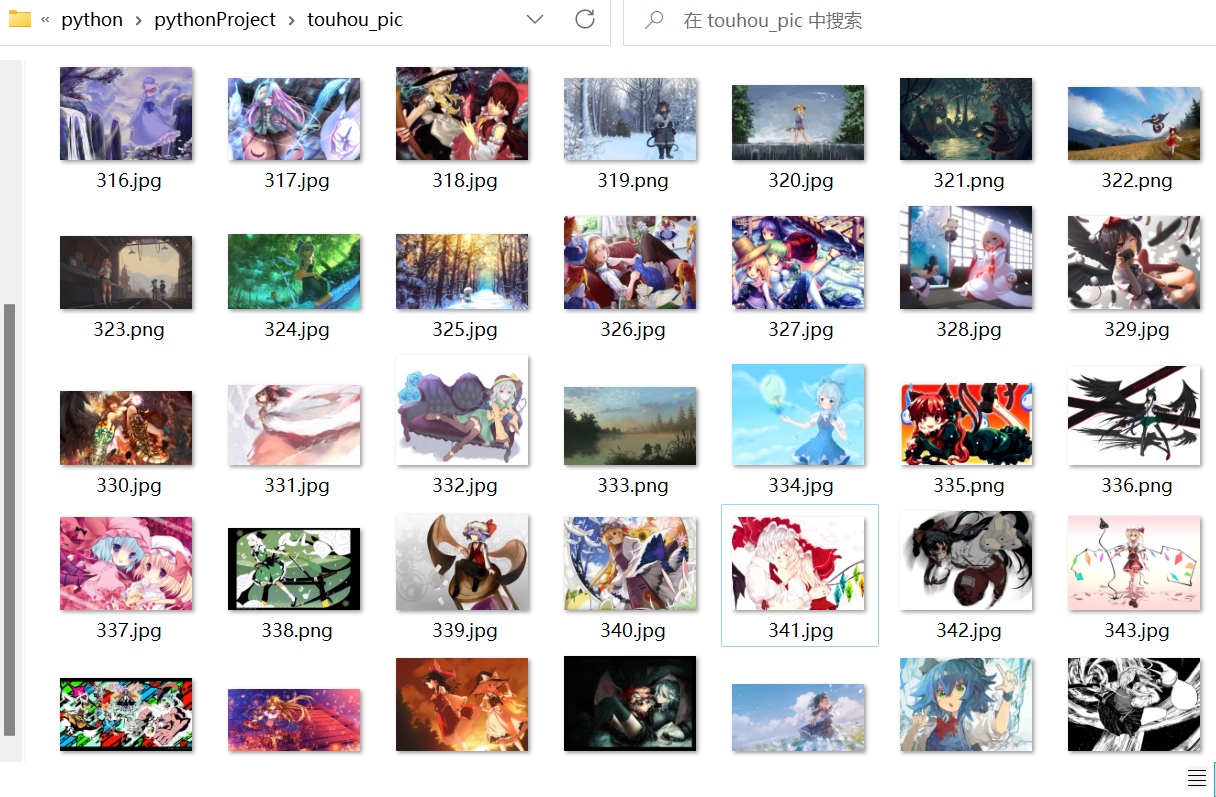
运行结果预览
贴一下爬下来的图片吧(不能保证质量哦QnQ)
小咕一手
upd. 被迫咕,度娘云链接秒挂……

运行要求
- 本代码编写在python3.10版本(不确定低版本会不会有问题)
- requests
- xpath - lxml库
代码
import requests from lxml import etreehttps://wall.alphacoders.com/by_sub_category.php?id=174892&name=%E4%B8%9C%E6%96%B9+%E5%A3%81%E7%BA%B8&filter=4K+Ultra+HD&lang=Chinese&quickload=880+&page=1
base_url = 'https://wall.alphacoders.com/by_sub_category.php?id=174892&name=%E4%B8%9C%E6%96%B9+%E5%A3%81%E7%BA%B8&filter=4K+Ultra+HD&lang=Chinese&quickload=880+&page='
index = 0
for page in range(1,31):
print('正在爬取第'+str(page)+'页')
url = base_url+str(page)
# //img[@class="img-responsive big-thumb thumb-desktop"]/@src
response = requests.get(url=url)
content = response.text
# print(content)
tree = etree.HTML(content)
img_li = tree.xpath('//img[@class="img-responsive big-thumb thumb-desktop"]/@src')
for img_url in img_li:
print('正在爬取第'+str(index)+'张')
img_response = requests.get(url=img_url)
img_content = img_response.content
index += 1
# print(img_url)
extension = '.'+img_url.split('.')[-1]
with open('.\touhou_pic\'+str(index)+extension,'wb')as fp:
fp.write(img_content)
经验教训
爬虫的过程还是要输出的,不知道爬到哪里而不敢轻举妄动的感觉不好受诶。TnT