翻译:林立琨校对:zrx
本文约3700字,建议阅读10分钟本文手把手教你如何将LLM 应用到您的自定义数据中。企业正在竞相采用大型语言模型(也可以被称为LLM)。让我们深入了解如何通过RAG(检索增强生成技术) 构建特定行业的大型语言模型。
公司可以通过使用像ChatGPT 这样的大语言明星提高生产力。但是试着问 ChatGPT "美国目前的通货膨胀率是多少",它会给出答案:
很抱歉造成您的困惑,作为一个人工智能语言模型,我不具备实时数据的浏览能力。我的回答是基于截至 2021 年 9 月的信息。因此,我无法为您提供美国当前的通货膨胀率。
这是一个问题。ChatGPT显然缺少及时相关的背景信息,而这对于做出明智的决策至关重要。
微软如何解决这一问题
在微软 Build 会议 "矢量搜索还不够"(Vector Search Isn't Enough)中,他们介绍了自己的产品,该产品将上下文感知较弱的LLM 与矢量搜索结合起来,以创造更有吸引力的体验。
演讲的出发点与本文相反—他们从弹性搜索(或矢量搜索)的角度出发,认为搜索本身是有限的,而添加LLM 层可以极大地改善搜索体验。
其基本想法是,在LLM 中添加相关上下文可以极大地改善用户体验,尤其是在大多数商业案例中,因为LLM 并没有见过此类数据。当您拥有海量数据,包括 100 多份(或更多)文档时, 矢量搜索有助于选择相关上下文。
矢量搜索 101

矢量搜索101 | Skanda Vivek
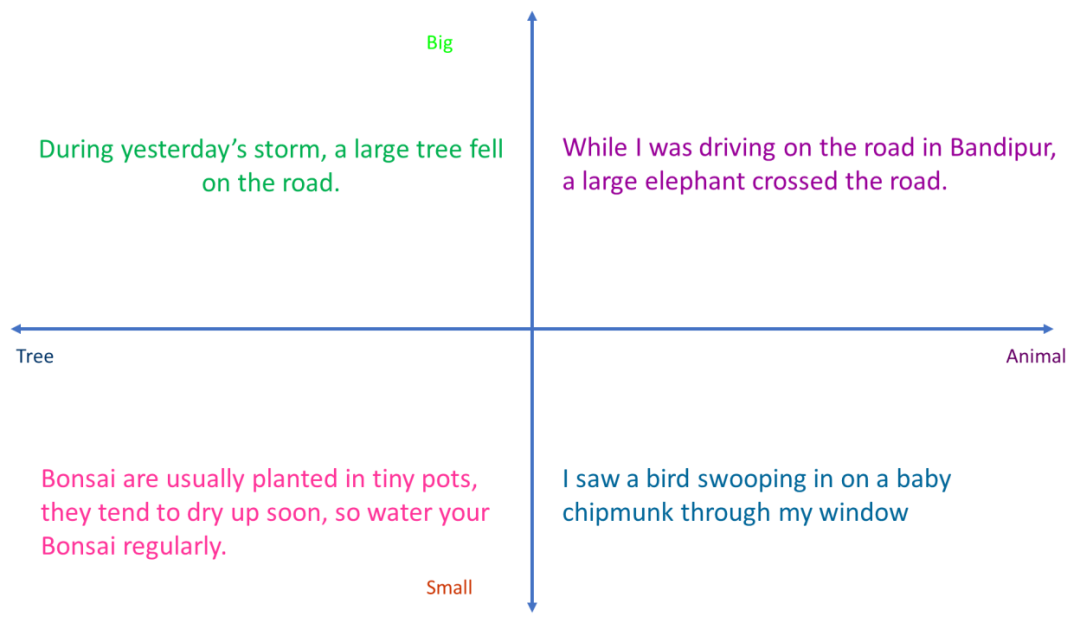
矢量化是将数据转换成多维向量。在上面的案例中,您可以看到2个维度:尺寸和类型。尺寸有 2 种(小或大),类型有 2 个种(树或动物)。这只是一个概念性的例子,当然矢量化也可以扩展到数百个维度(或更多值)。
句子的矢量搜索101 | Skanda Vivek
您也可以用单词或句子代替图片来做同样的事情。请注意,在上述示例中,矢量化能够捕捉语义表征,即它知道关于一只鸟俯冲向一只花栗鼠宝宝的句子应该位于(小鼠,动物)象限,而关于昨天暴风雨时一棵大树倒在路上的句子应该位于(大,树)象限。实际上,嵌入的维度不止 2 个--而是384个(句子或文本块通过BERT 变换器,输出 384个与384维相对应的数字)
矢量搜索 + LLM (RAG)
矢量搜索现在在所有的搜索中都很普遍(谷歌、必应,以及您最喜欢的搜索引擎)。想一想,如果您的整个搜索数据库中只有这4 个文档,您可以问这样一个问题:"请告诉我关于一棵大树的事情。您可以问这样一个问题:"请告诉我关于一棵大树的事情"。
那么输出为:
在昨天的暴风雨中,一棵大树倒在路上。
只是数据库中最相关的文档。但如果您向LLM提出同样的问题(并在最后添加 4 个 "文档"),您将得到以下结果:
(本例中为ChatGPT):
大树通常是一种高耸的大型植物,具有粗壮的树干、树枝和广泛的根系网络。这些树木可以达到令人印象深刻的高度, 通常远远高于周围的植被。它们是许多生态系统的重要组成部分,为各种生物提供树荫、庇护所和食物。
您提到的暴风雨中大树倒在路上的事件表明了恶劣天气条件的威力和影响。强风暴雨会将树木连根拔起或折断,导致道路堵塞,给车辆和行人带来潜在危险。
在您提到的另一种情况下,当您在班迪布尔(Bandipur) 的公路上行驶时,遇到一头大象横穿马路。班迪普尔是位于印度的一个国家公园和野生动物保护区,以其丰富的生物多样性和多样的动物而闻名。大象是班迪普尔的主要物种之一,它们经常穿越该地区,有时还会横穿马路。这样的邂逅凸显了野生动物保护的重要性,以及人类在自然栖息地与动物共存的必要性。
说到盆景,它们是生长在小盆中的微型树木,经过精心造型和修剪以保持其小巧的体型。盆景栽培是一种古老的艺术形式,起源于东亚,现已风靡全球。由于根部空间有限,盆景景树要定期浇水以防止干枯。小盆会导致土壤迅速干燥,因此监测湿度并相应地浇水至关重要。
最后,您提到透过窗户观察到一只鸟俯冲一只小花栗鼠。这种观察反映了大自然的一个行动瞬间,一只鸟可能正在觅食。众所周知,猛禽和某些鸟类(如鹰或猫头鹰)会俯冲花栗鼠等小型哺乳动物,这是它们自然狩猎行为的一部分。目睹这种互动令人着迷,因为它们能让我们对动物王国的活力有更深的了解。
总之,这些自然片段--无论是涉及大树、大象、盆景树还是鸟类捕食--都突出了我们周围自然世界的多样性和奇妙性。
这个答案似乎更加全面。ChatGPT使用的是在数万亿文档中训练出来的内部知识,并结合了所给的上下文。
但是,假设您有不止4个文档--也许是成千上万个,您无法在ChatGPT 提示中找到。在这种情况下,您可以使用矢量搜索来缩小最有可能包含答案的上下文范围,并将其附加到提示中, 然后提出如下相同的问题:
这是它现在给出的(截断的)答案:

ChatGPT answer | Skanda Vivek
您可以有一个数据库,存储文档和嵌入。另一个数据库存储查询,并根据查询找到最相关的文档:
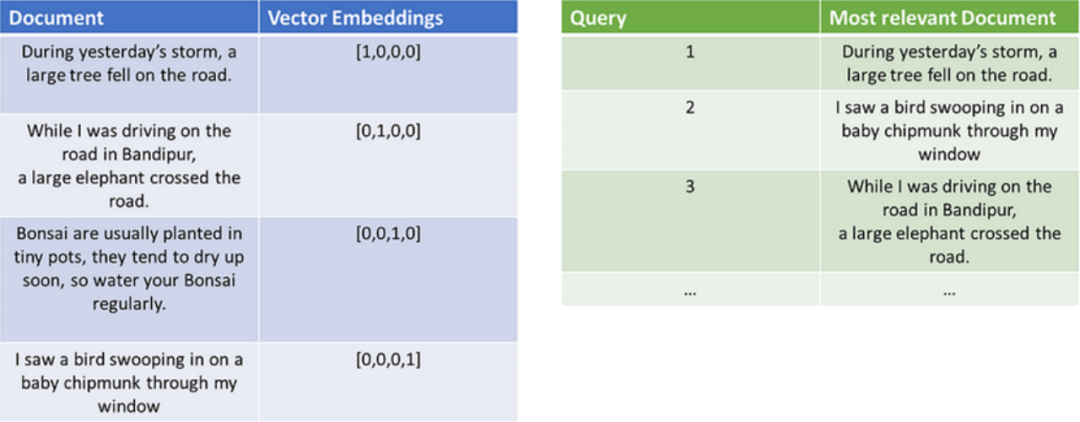
Document DB (左)和 Quey DB (右) | Skanda Vivek
一旦您通过查询获得了最相似的文档,您就可以将其输入到任何LLM,如ChatGPT。通过这个简单的技巧,您就利用文档检索增强了您的 LLM!这也被称为检索增强生成(RAG)。
使用 RAG 建立特定行业的问答模型
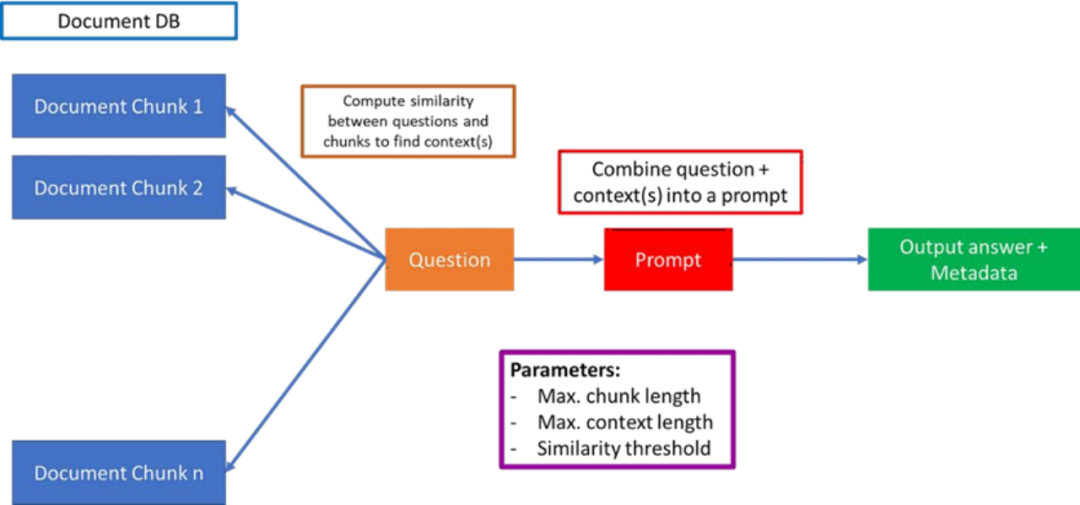
RAG原型 | Skanda Vivek
上图概述了如何构建一个基本的RAG,利用自定义文档的LLM进行问题解答。第一部分是将多个文档分割成易于管理的块,相关参数是最大分块长度。这些块应该是包含典型问题答案的典型(最小)文本大小。这是因为有时您提出的问题可能在文档的多个位置都有答案。例如,您可能会问"X 公司从2015 年到 2020 年的业绩如何?而您可能有一个大型文档(或多个文档),在文档的不同部分包含了公司多年来业绩的具体信息。在理想情况下,您希望捕获包含这些信息的文档的所有不同部分,将它们连接在一起,并根据这些经过过滤和连接的文档块传递给 LLM 进行回答。
最大上下文长度基本上是将各种语块连接在一起的最大长度--为问题本身和输出答案留出一些空间(请记住,像 ChatGPT 这样的 LLM 有严格的长度限制,包括所有内容:问题、上下文和答案。
相似度阈值是将问题与文档块进行比较的方法,以找到最有可能包含答案的顶级文档块。余弦函数是典型的度量方法,但您可能希望使用不同的度量方法。例如,包含关键词的上下文的权重更高。例如,当您向LLM 提出总结文档的问题时,您可能希望对包含 "摘要 "或 "总结 "字样的上下文进行加权。
如果您想通过一种简单的方式测试自定义文档上的生成式问答,请查看我的API (https://rapidapi.com/skandavivek/api/chatgpt-powered-question-answering-over-documents)和在后台使用 ChatGPT 的代码(https://github.com/skandavivek/web-qa)。
由 RAG 推动的 ChatGPT 原型机
让我们通过一个例子来说明RAG的作用。EMAlpha 是一家调研新兴市场的公司--基本上是印度、中国、巴西等新兴国家的经济(完全披露--我是 EMAlpha 的顾问)。该公司正在开发一个由 ChatGPT 支持的app,根据用户输入生成对新兴经济体的观点。仪表盘看起来像这样--你可以比较 ChatGPT 和RAG 版ChatGPT(EM-GPT)的输出,后者能够在后台查询国际货币基金组织(IMF)的金融文件:

EMAlpha中的EM-GPT 从|斯坎达-维韦克
以下是ChatGPT 对 "尼泊尔每年的 GDP 是多少?"这个问题的回答:

ChatGPT回答| Skanda Vivek
ChatGPT 只返回 2019 年之前的 GDP,它说如果您想了解更多信息,请访问 IMF。但是,如果您想知道这些数据在IMF 网站的什么位置,那就很难了,您需要对网站上的文件存储位置有所了解。经过一番搜索,您会发现文件就在这里。即便如此,要想知道 GDP 信息到底在哪里,也需要进行大量的滚动。
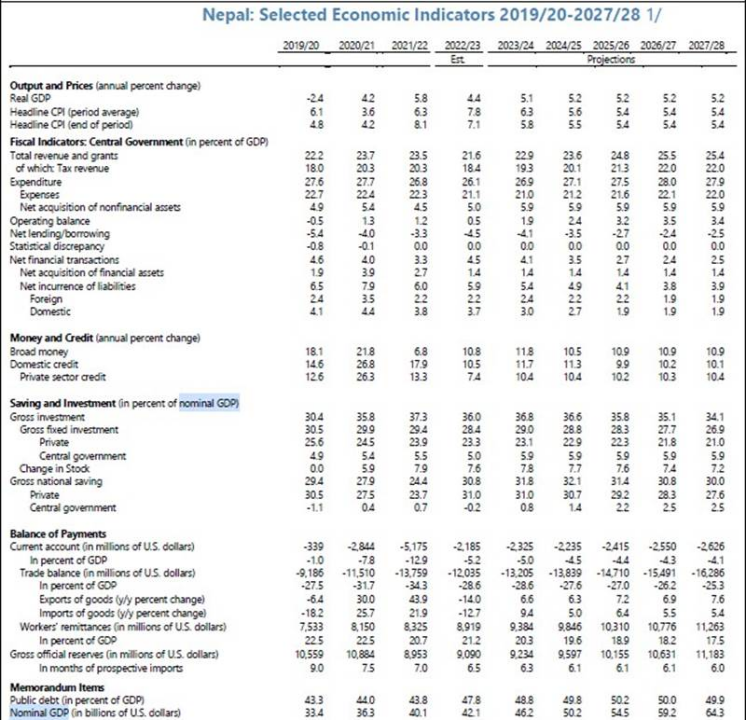
国际货币基金组织关于尼泊尔经济的文件| Skanda Vivek
你可以看到,找到这些数据是很难的。但是,当您向 EM-GPT 提出同样的问题时,它会追踪相关上下文,并找到如下答案:
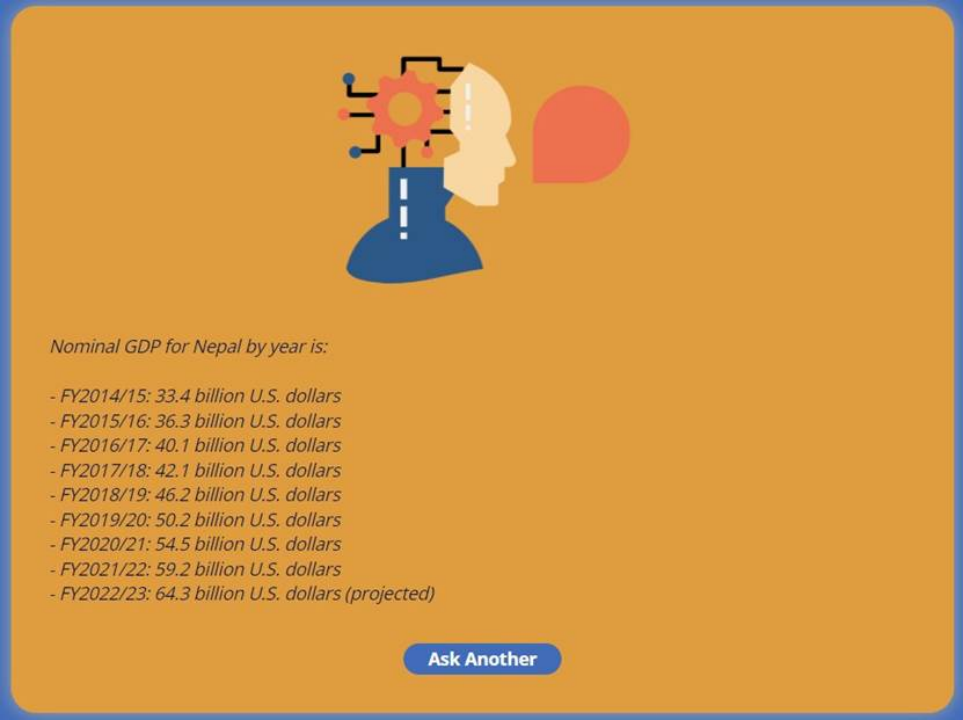
EM-GPT答案 | Skanda Vivek
下面是发送给ChatGPT 回答这个问题的确切提示。令人印象深刻的是,它能够理解这些格式化的文本,提取正确的信息,并将其格式化为人类可读的格式!

使用基于查询的上下文进行聊天GPT 提示 | Skanda Vivek
我花了半个小时才在IMF网站上找到这些信息,而 RAG 修改后的 ChatGPT 只花了几秒钟。仅靠矢量搜索是不行的,因为它最多只能找到 "名义 GDP"这个词,而不能将数字与年份联系起来。ChatGPT 已经在过去的多个此类文档中接受过训练,因此一旦添加了相关上下文,它就知道文本的哪些部分包含答案,以及如何将答案格式化为可读的格式。
结论
RAG提供了一种在自定义文档中使用LLM 的好方法。微软、谷歌和亚马逊等公司都在竞相开发企业可以”即插即用“的应用程序。然而,该领域仍处于起步阶段,在自定义文档上使用矢量搜索驱动的 LLM 的特定行业应用程序可以成为先行者,并在竞争中脱颖而出。
当有人问我应该使用哪种LLM,以及是否要对自定义文档进行微调或完全训练模型,他们低估了LLM 和矢量搜索之间的同步工程的作用。以下是一些可以显著提高或降低响应质量的注意事项:
1. 文档块的长度。如果正确答案更有可能包含在文本的不同部分,并且需要拼接在一起,则应将文档分割成较小的块,以便在查询时附加多个上下文。
2. 相似性和检索度量。有时,单纯的余弦相似性是不够的。例如,如果许多文档包含关于同一主题的相互矛盾的信息,您可能希望根据这些文档中的元数据将搜索限制在某些文档上。因此,除了相似度之外,您还可以使用其他过滤指标。
3. 模型结构。我所展示的架构只是一个原型。为了提高效率和可扩展性,必须考虑各个方面,包括矢量嵌入模型、文档数据库、提示、LLM 模型选择等。
4. 避免幻觉。您可能已经注意到我上面展示的例子几乎是正确的。增强的 ChatGPT 得到了尼泊尔GDP 的正确数字--但是年份错了。在这种情况下,需要在选择提示、以更好的格式提取数据、评估出现幻觉的案例比例以及有效的解决方案之间进行大量的反馈。
现在,您已经知道如何将LLM应用到您的自定义数据中,去构建基于 LLM 的超棒产品吧!
原文标题:Pandas 2.0: A Game-Changer for Data Scientists?
原文链接:Build Industry-Specific LLMs Using Retrieval Augmented Generation | by Skanda Vivek | May, 2023 | Towards Data Science
编辑:黄继彦
译者简介
作者简介
林立锟,香港城市大学计算数学本科,数据科学爱好者,对数学和计算机特别感兴趣,尤其是两者的结合部分特别感兴趣。兴趣是打羽毛球,以及琢磨一些奇奇怪怪的学习工具。希望能够通过自己的努力,将一些更优质的文章,更有价值的内容分享给读者,让大家在学习数据科学时能够更加顺利!