http是什么
超文本传输协议
协议、多个参与者。计算机之间交流通信的规范,是一个双向协议。
HTTP 通常跑在 TCP/IP 协议栈之上,依靠 IP 协议实现寻址和路由、TCP 协议实现可靠数据传输、DNS 协议实现域名查找、SSL/TLS 协议实现安全通信。此外,还有一些协议依赖于 HTTP,例如 WebSocket、HTTPDNS 等。这些协议相互交织,构成了一个协议网,而 HTTP 则处于中心地位。
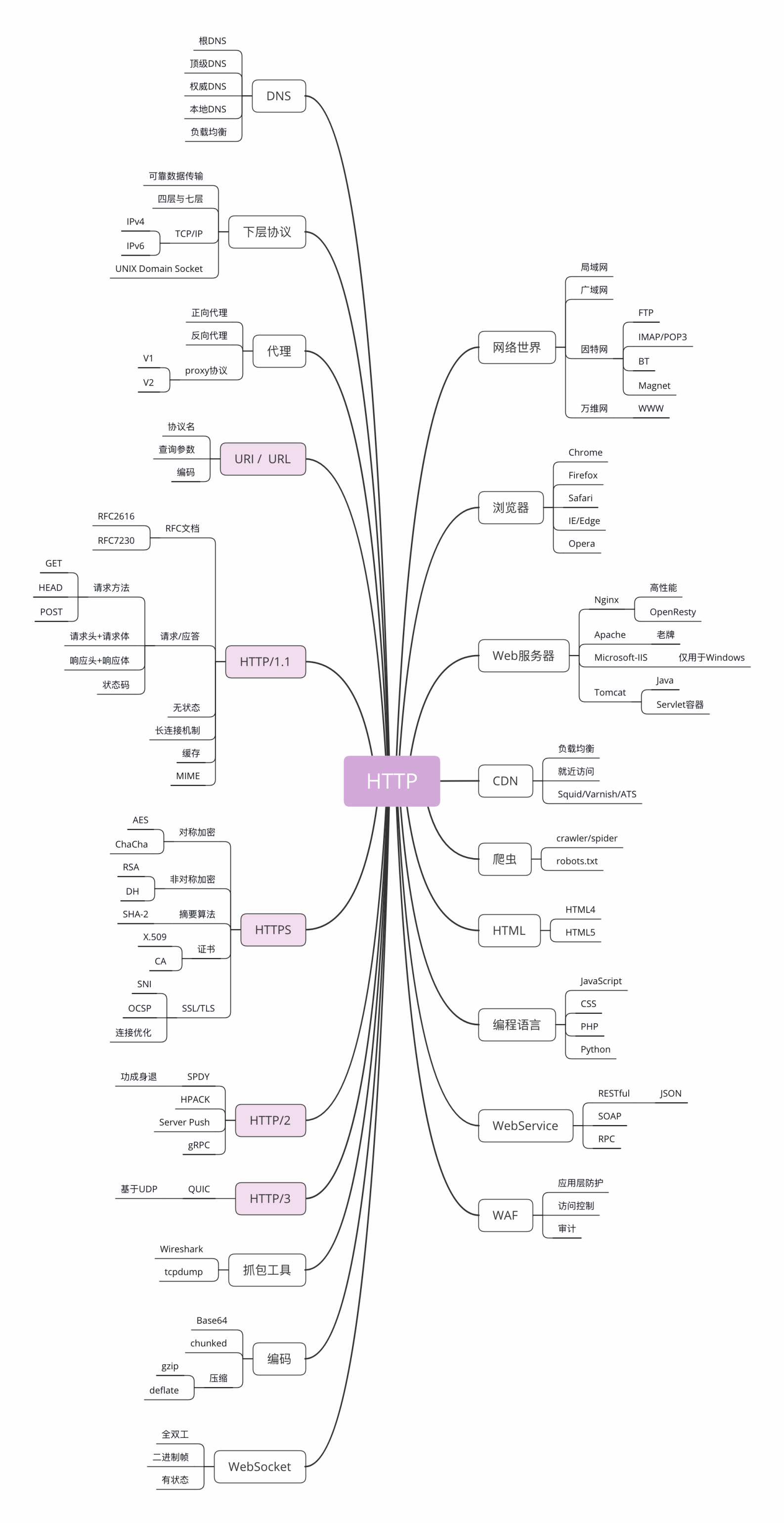
分层模型示意图

**TCP/ IP 模型** 核心是二层的IP 和三层的TCP,HTTP 在四层
“两个凡是”:凡是由操作系统负责处理的就是四层或四层以下,否则,凡是需要由应用程序(也就是你自己写代码)负责处理的就是七层。
DNS 网络请求的第一步 就是域名解析,在应用层 和 CDN 也是在应用层
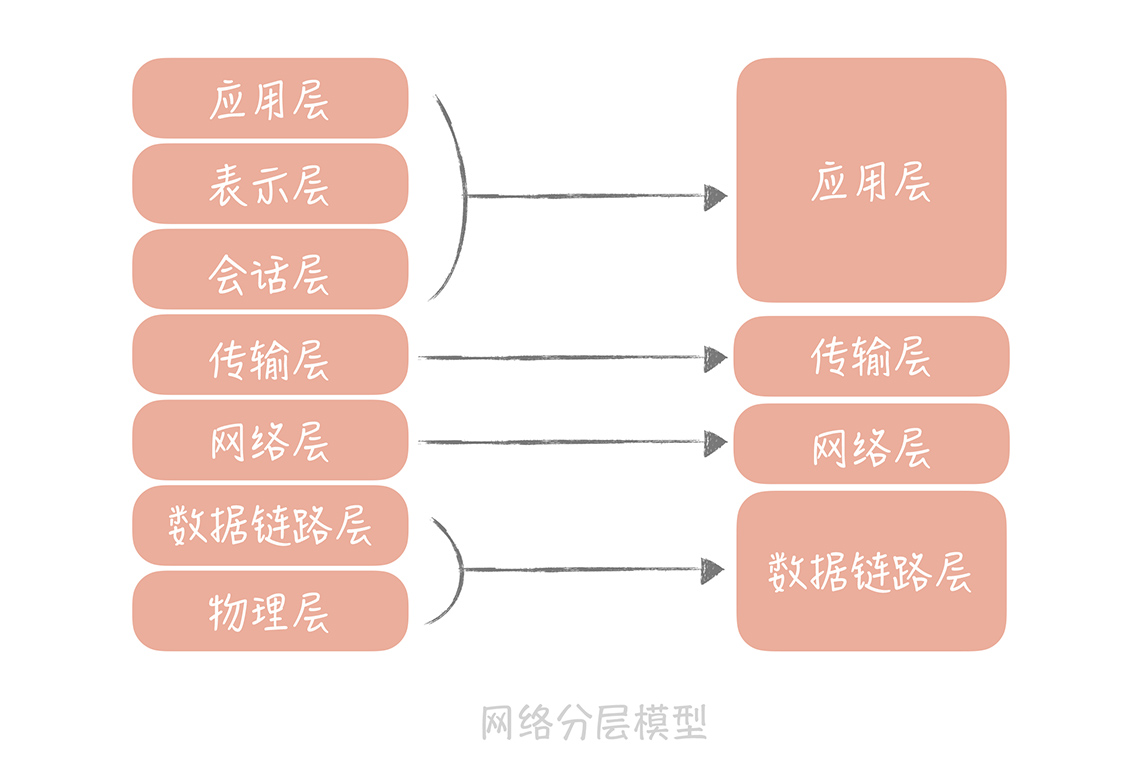
OSI 模型
对应关系
- 第一层:物理层,TCP/IP 里无对应;
- 第二层:数据链路层,对应 TCP/IP 的链接层;
- 第三层:网络层,对应 TCP/IP 的网际层;
- 第四层:传输层,对应 TCP/IP 的传输层;
- 第五、六、七层:统一对应到 TCP/IP 的应用层。
两种分层模型的最大差异,其实还是在会话层和表示层上面。第一到第四层,已经基本统一了。而它们的最高层,虽然一个叫第七层,一个叫第四层或者第五层,表面上虽然并不一致,但实际上都可以用“应用层”来代替。这样既避免了可能的误解,也更加准确地表示了这一层的具体用途。
TCP/IP 协议栈的工作方式
- HTTP 协议里要传输的内容,比如 HTML,然后 HTTP 协议为它加一个 HTTP 专用附加数据。
- 在 TCP 层给数据再次打包,加上了 TCP 头。
- 在 IP 层、MAC 层对 TCP 数据包加上了 IP 头、MAC 头。
- 在 IP 层、MAC 层传输后拆包。
三次握手
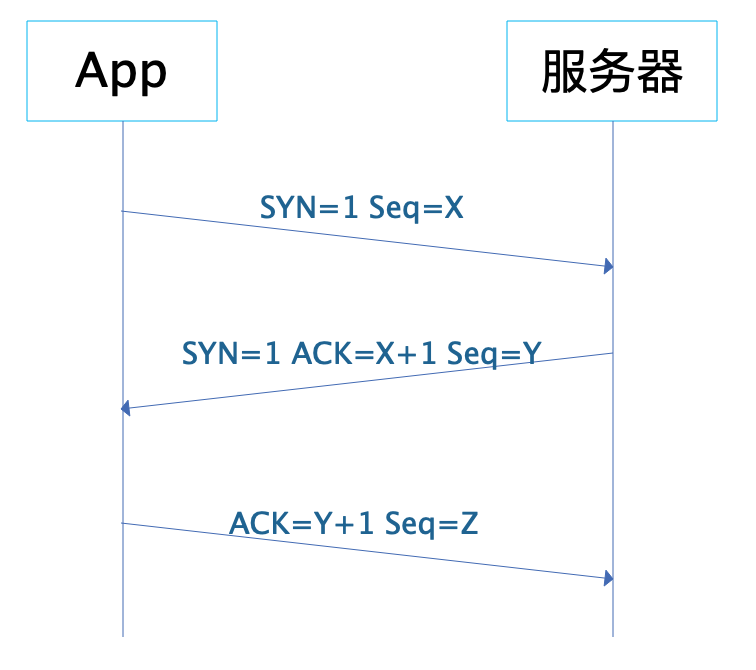
App 和服务器之间发送三次报文才会建立一个 TCP 连接,报文中的 SYN 表示请求建立连接,ACK 表示确认。App 先发送 SYN=1,Seq=X 的报文,表示请求建立连接,X 是一个随机数;服务器收到这个报文后,应答 SYN=1,ACK=X+1,Seq=Y 的报文,表示同意建立连接;App 收到这个报文后,检查 ACK 的值为自己发送的 Seq 值 +1,确认建立连接,并发送 ACK=Y+1 的报文给服务器;服务器收到这个报文后检查 ACK 值为自己发送的 Seq 值 +1,确认建立连接。至此,App 和服务器建立起 TCP 连接,就可以进行数据传输了。
LB(负载均衡)
http1.1
- 增加了 PUT、DELETE 等新的方法;
- 增加了缓存管理和控制;
- 明确了连接管理,允许持久连接;
- 允许响应数据分块(chunked),利于传输大文件;
- 强制要求 Host 头,让互联网主机托管成为可能。
http 2.0
- 二进制协议,不再是纯文本;
- 可发起多个请求,废弃了 1.1 里的管道;
- 使用专用算法压缩头部,减少数据传输量;
- 允许服务器主动向客户端推送数据;
- 增强了安全性,“事实上”要求加密通信。
CDN
cdn 好处,它可以缓存源站的数据,让浏览器的请求不用“千里迢迢”地到达源站服务器,如果 CDN 的调度算法很优秀,更可以找到离用户最近的节点,大幅度缩短响应时间。
基本的网络加速外,还提供负载均衡、安全防护、边缘计算、跨运营商网络等功能,能够成倍地“放大”源站服务器的服务能力
IP
主要目的是解决寻址和路由问题
TCP
“传输控制协议”,它位于 IP 协议之上,基于 IP 协议提供可靠的、字节流形式的通信,是 HTTP 协议得以实现的基础。
每个 TCP 分组都会带着一个唯一的序列号被发出,而所有分组必须按顺序传送到接收端。如果中途有一个分组没能到达接收端,那么后续分组必须保存到接收端的 TCP 缓冲区,等待丢失的分组重发并到达接收端。这一切都发生在 TCP 层,应用程序对 TCP 重发和缓冲区中排队的分组一无所知,必须等待分组全部到达才能访问数据。在此之前,应用程序只能在通过套接字读数据时感觉到延迟交互。这种效应称为 TCP 的队首阻塞。
使用“keepalive_timeout”指令,设置长连接的超时时间,如果在一段时间内连接上没有任何数据收发就主动断开连接,避免空闲连接占用系统资源。 使用“keepalive_requests”指令,设置长连接上可发送的最大请求次数。比如设置成 1000,那么当 Nginx 在这个连接上处理了 1000 个请求后,也会主动断开连接。
开发人员开发时,如果明确知道本次访问已经完成,应该在请求头中加上 connection:close(客户端)
url
组成
- 协议名:即访问该资源应当使用的协议,在这里是“http”;
- 主机名:即互联网上主机的标记,可以是域名或 IP 地址,在这里是“nginx.org”;
- 路径:即资源在主机上的位置,使用“/”分隔多级目录,在这里是“/en/download.html”。
代理
- 匿名代理:完全“隐匿”了被代理的机器,外界看到的只是代理服务器;
- 透明代理:顾名思义,它在传输过程中是“透明开放”的,外界既知道代理,也知道客户端;
- 正向代理:靠近客户端,代表客户端向服务器发送请求;
- 反向代理:靠近服务器端,代表服务器响应客户端的请求;
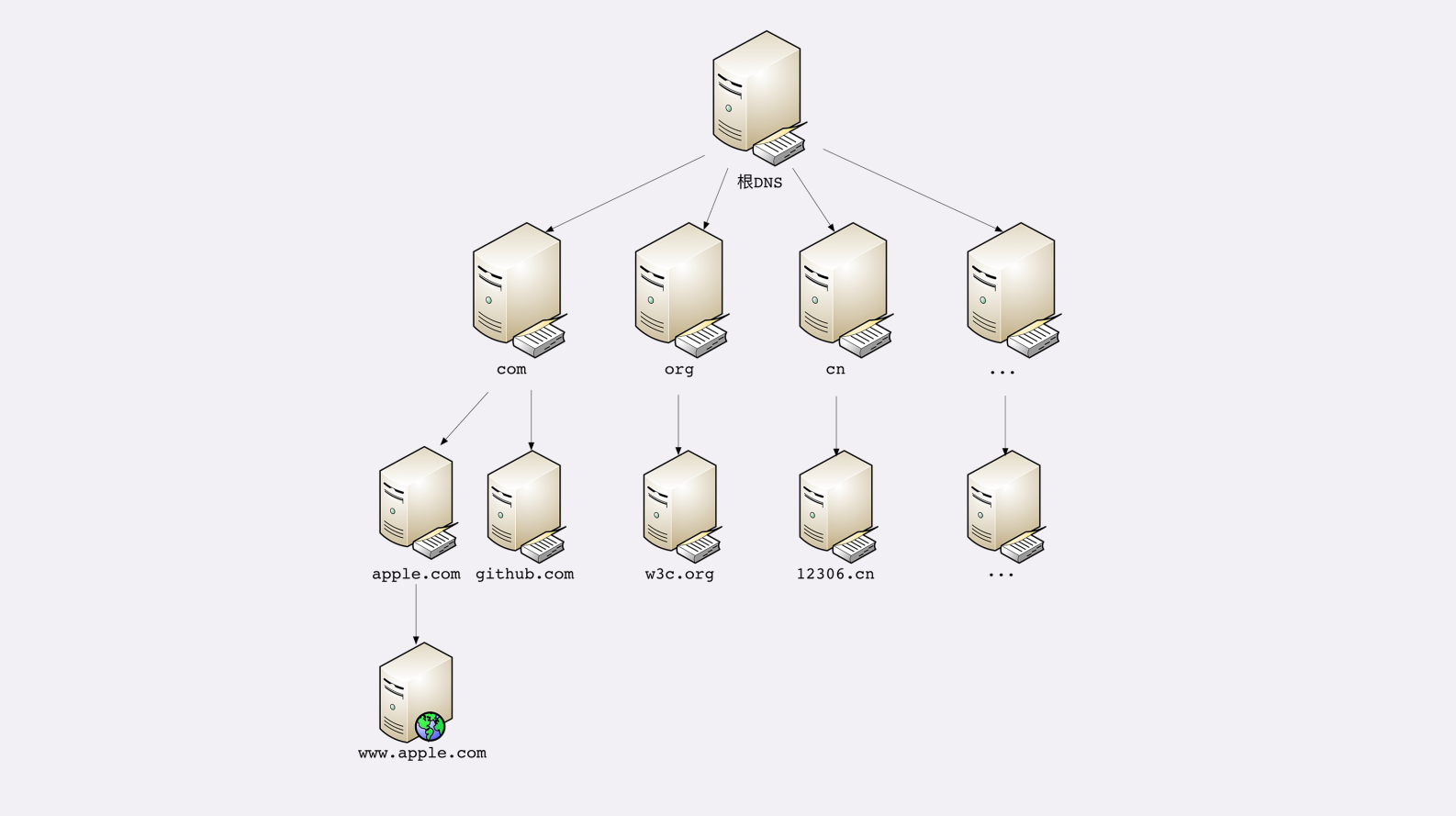
DNS
DNS 的核心系统是一个三层的树状、分布式服务,基本对应域名的结构:
- 根域名服务器(Root DNS Server):管理顶级域名服务器,返回“com”“net”“cn”等顶级域名服务器的 IP 地址;
- 顶级域名服务器(Top-level DNS Server):管理各自域名下的权威域名服务器,比如 com 顶级域名服务器可以返回 apple.com 域名服务器的 IP 地址;
- 权威域名服务器(Authoritative DNS Server):管理自己域名下主机的 IP 地址,比如 apple.com 权威域名服务器可以返回 www.apple.com 的 IP 地址。
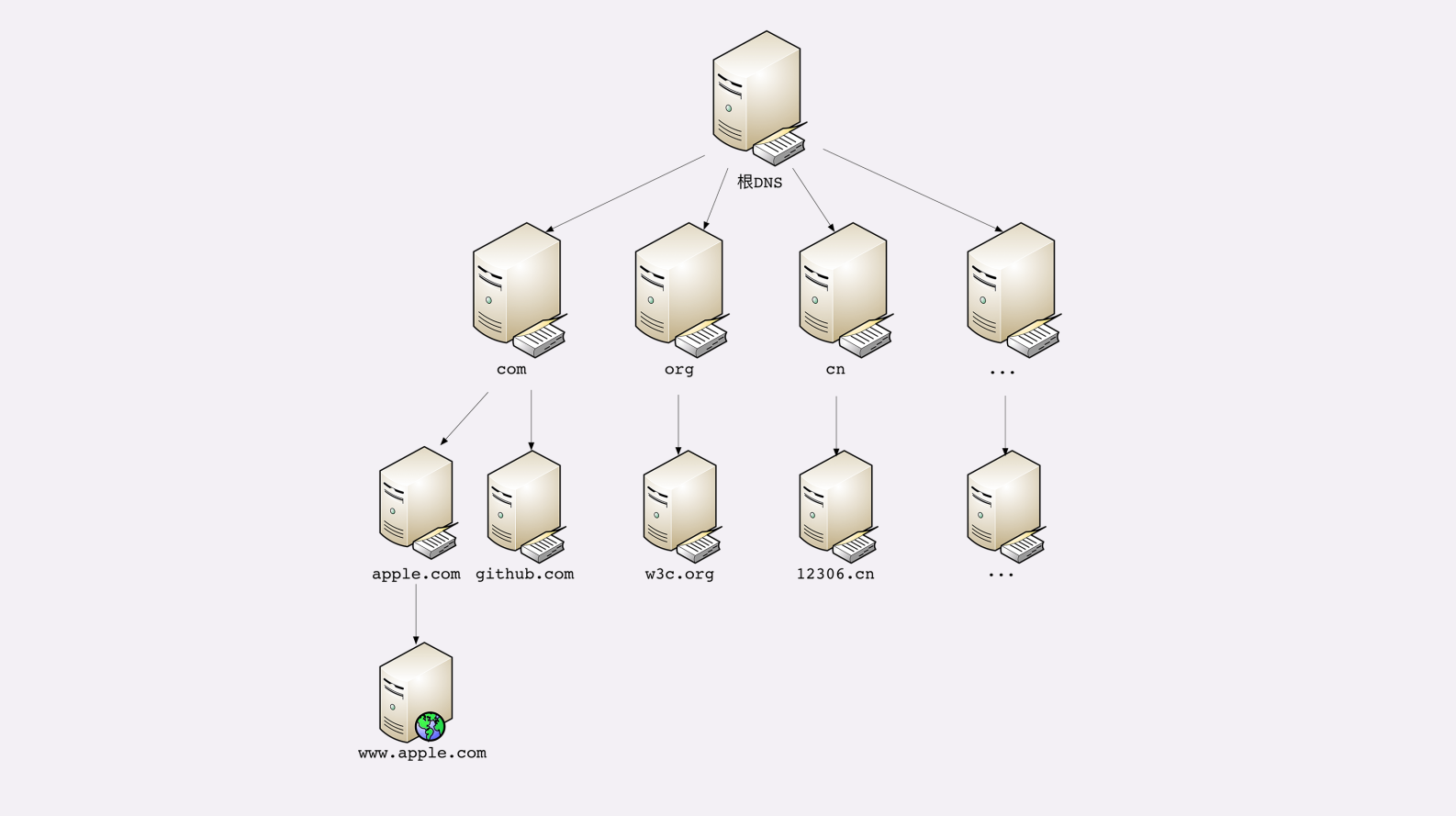
操作系统会对DNS解析做缓存
DNS解析过程
浏览器缓存->操作系统dnscache ->hosts文件->非权威域名服务器->根域名服务器->顶级域名服务器->二级域名服务器->权威域名服务器。
这些远程查询都是基于UDP协议,通常使用53号端口。
状态码
- 1××:提示信息,表示目前是协议处理的中间状态,还需要后续的操作;
- 2××:成功,报文已经收到并被正确处理;
- 200 成功
- 204 响应头后没有 body 数据。
- 3××:重定向,资源位置发生变动,需要客户端重新发送请求;
- 301 你的网站升级到了 HTTPS,原来的 HTTP 不打算用了,这就是“永久”的,所以要配置 301 跳转,把所有的 HTTP 流量都切换到 HTTPS。
- 302 网站后台要系统维护,服务暂时不可用,这就属于“临时”的,可以配置成 302 跳转,把流量临时切换到一个静态通知页面,浏览器看到这个 302 就知道这只是暂时的情况,不会做缓存优化,第二天还会访问原来的地址。
- 304 它用于 If-Modified-Since 等条件请求,表示资源未修改,用于缓存控制。它不具有通常的跳转含义,但可以理解成“重定向已到缓存的文件”(即“缓存重定向”)。
- 4××:客户端错误,请求报文有误,服务器无法处理;
- “400 Bad Request”是一个通用的错误码,表示请求报文有错误,但具体是数据格式错误、缺少请求头还是 URI 超长它没有明确说
- “403 Forbidden”实际上不是客户端的请求出错,而是表示服务器禁止访问资源。原因可能多种多样,例如信息敏感、法律禁止等
- 404 路径错误
- 405 Method Not Allowed:不允许使用某些方法操作资源,例如不允许 POST 只能 GET;
- 406 Not Acceptable:资源无法满足客户端请求的条件,例如请求中文但只有英文;
- 408 Request Timeout:请求超时,服务器等待了过长的时间;
- 409 Conflict:多个请求发生了冲突,可以理解为多线程并发时的竞态;
- 413 Request Entity Too Large:请求报文里的 body 太大;
- 414 Request-URI Too Long:请求行里的 URI 太大;
- 429 Too Many Requests:客户端发送了太多的请求,通常是由于服务器的限连策略;
- 431 Request Header Fields Too Large:请求头某个字段或总体太大;
- 5××:服务器错误,服务器在处理请求时内部发生了错误。
- 500 服务器内部错误
- “502 Bad Gateway”通常是服务器作为网关或者代理时返回的错误码,表示服务器自身工作正常,访问后端服务器时发生了错误
- 503 是一个“临时”的状态,很可能过几秒钟后服务器就不那么忙了,可以继续提供服务,所以 503 响应报文里通常还会有一个“Retry-After”字段,指示客户端可以在多久以后再次尝试发送请求。
短连接
客户端与服务器的整个连接过程很短暂,不会与服务器保持长时间的连接状态,所以就被称为“短连接”(short-lived connections)。早期的 HTTP 协议也被称为是“无连接”的协议。
短连接的缺点相当严重,因为在 TCP 协议里,建立连接和关闭连接都是非常“昂贵”的操作。TCP 建立连接要有“三次握手”,发送 3 个数据包,需要 1 个 RTT;关闭连接是“四次挥手”,4 个数据包需要 2 个 RTT。
长连接
在 HTTP/1.1 中的连接都会默认启用长连接。不需要用什么特殊的头字段指定,只要向服务器发送了第一次请求,后续的请求都会重复利用第一次打开的 TCP 连接,也就是长连接,在这个连接上收发数据。
可以在请求头里明确地要求使用长连接机制,使用的字段是 Connection,值是“keep-alive”。
性能优化。
因为“请求 - 应答”模型不能变,所以“队头阻塞”问题在 HTTP/1.1 里无法解决,只能缓解,有什么办法呢?
HTTP 里就是“并发连接”(concurrent connections),也就是同时对一个域名发起多个长连接,用数量来解决质量的问题。
HTTP 协议建议客户端使用并发,但不能“滥用”并发。RFC2616 里明确限制每个客户端最多并发 2 个连接。不过实践证明这个数字实在是太小了,众多浏览器都“无视”标准,把这个上限提高到了 6~8。后来修订的 RFC7230 也就“顺水推舟”,取消了这个“2”的限制。
“域名分片”(domain sharding)技术,还是用数量来解决质量的思路。
HTTP 协议和浏览器不是限制并发连接数量吗? 那就多开几个域名,比如 shard1.chrono.com、shard2.chrono.com,而这些域名都指向同一台服务器 www.chrono.com,这样实际长连接的数量就又上去了。
重定向
外部重定向,服务器会把重定向的地址给浏览器,然后浏览器再次的发起请求,地址栏的地址变化了。
内部重定向,服务器会直接把重定向的资源返给浏览器,不需要再次在浏览器发起请求,地址栏的地址不变。
内部重定向对于用户来说成本低,因为只在网站服务器内部跳转
应用场景(SSO)
HTTPS
SSL/TLS
SSL 即安全套接层(Secure Sockets Layer),在 OSI 模型中处于第 5 层(会话层)
TLS 由记录协议、握手协议、警告协议、变更密码规范协议、扩展协议等几个子协议组成,综合使用了对称加密、非对称加密、身份认证等许多密码学前沿技术。
对称加密
指加密和解密时使用的密钥都是同一个,是“对称”的。只要保证了密钥的安全,那整个通信过程就可以说具有了机密性。
TLS 里有非常多的对称加密算法可供选择,比如 RC4、DES、3DES、AES、ChaCha20 等,但前三种算法都被认为是不安全的,通常都禁止使用,目前常用的只有 AES 和 ChaCha20。
优化
客户端 HTTP 性能优化的关键就是:降低延迟。
我正在参与2023腾讯技术创作特训营第三期有奖征文,组队打卡瓜分大奖!