12.6.1 预测船员数量
数据集 cruise.csv 包含了船的吨位、大小、乘客密度、船员数量等特征,业务需要建立一个船员数量与其他相关特征的回归模型,从而能估计船员数量。
下面演示机器学习项目的一般流程,并建立回归模型。
1. 初步了解数据
当拿到数据集之后,首先要对数据有比较直观的印象,比如数据的特征都是什么、各个特征的数据分布情况等——对业务和数据越熟悉,越有助于创建有效的模型。
[1]: import pandas as pd
df = pd.read_csv("./data/cruise.csv")
df.head()
[1]: Ship_name ... length cabins passenger_density crew
0 Journey ... 5.94 3.55 42.64 3.55
1 Quest ... 5.94 3.55 42.64 3.55
2 Celebration ... 7.22 7.43 31.80 6.70
3 Conquest ... 9.53 14.88 36.99 19.10
4 Destiny ... 8.92 13.21 38.36 10.00
如果读者调试上述代码,可以显示完整的特征名称,这里因为排版的需要,将部分特征省略。也可以用下面的操作将所有特征名称单独显示出来。
[2]: df.columns
[2]: Index(['Ship_name', 'Cruise_line', 'Age', 'Tonnage', 'passengers',
'length','cabins', 'passenger_density', 'crew'],
dtype='object')
然后,对所有由数字组成的特征进行统计,从而对各特征中的数值分布状况有总体的印象。
[3]: df.describe()
[3]: Age Tonnage passengers length cabins passenger_density crew
count 158.000000 158.000000 158.000000 158.000000 158.000000 158.000000 158.000000
mean 15.689873 71.284671 18.457405 8.130633 8.830000 39.900949 7.794177
std 7.615691 37.229540 9.677095 1.793474 4.471417 8.639217 3.503487
min 4.000000 2.329000 0.660000 2.790000 0.330000 17.700000 0.590000
25% 10.000000 46.013000 12.535000 7.100000 6.132500 34.570000 5.480000
50% 14.000000 71.899000 19.500000 8.555000 9.570000 39.085000 8.150000
75% 20.000000 90.772500 24.845000 9.510000 10.885000 44.185000 9.990000
max 48.000000 220.000000 54.000000 11.820000 27.000000 71.430000 21.000000
由上述描述性统计可知,这个数据集共有 158 个样本。比较各个特征,数据范围分布“不平衡”,比如特征 Age 的数据范围是 4~48 ,Tonnage 的数据则分布在 2.329~220 之间,从统计量标准差 std 也能观察到这种“不平衡”。如果将这样的数据直接用于模型训练,会导致不同特征对模型的影响有较大差异。所以,必须要经过“特征工程”这一步,对原始数据进行变换之后,才能用于训练模型。
2. 标准化变换
所谓标准化,是指“标准差标准化”,即根据平均值和标准差计算每个数据的标准分数:
有的资料将“标准化”和“区间化”笼统地称为“归一化”,这种说法并不正确,因为这是两个完全不同的计算方法,若有意深入理解,请参阅拙作《数据准备和特征工程》第3章3.6节(电子工业出版社)。
在 Python 中有一个实现机器学习的常用的第三方库:Scikit-learn ,官方网站:https://scikit-learn.org/ 。依照惯例,先安装再使用。
% pip install scikit-learn
安装好之后,继续在 JupyterLab 中执行如下代码,实现对数据集 df 中某些特征中数值的标准化。
[4]: from sklearn.preprocessing import StandardScaler
stdsc = StandardScaler()
X_std = stdsc.fit_transform(df.iloc[:,2:])
X_std[:5, :]
[4]: array([[-1.27640208, -1.10498441, -1.19395611, -1.2253308 , -1.18458832,
0.31805658, -1.21526718],
[-1.27640208, -1.10498441, -1.19395611, -1.2253308 , -1.18458832,
0.31805658, -1.21526718],
[ 1.35810515, -0.64731003, -0.37292634, -0.50936264, -0.31409539,
-0.9406764 , -0.31330399],
[-0.61777527, 1.04321543, 1.16961443, 0.78273616, 1.35734078,
-0.33801734, 3.23728127],
[ 0.1725769 , 0.81021512, 0.82544539, 0.44153258, 0.98266985,
-0.17893393, 0.63160983]])
仔细观察 [4] 的输出结果,并且与 [3] 的输出结果对比,先从直观上感受标准化变换的结果——参考前面推荐的拙作《数据准备和特征工程》,则知其然还知其所以然。
3. 选择特征
代码块 [2] 输出的特征,并不是都与特征 crew 的预测有关的,如何选出相关的特征呢?一种比较简单的方法就是计算各个特征之间的相关系数。
在下面的代码中,使用了另外一个数据可视化的第三方库:Seaborn(官方网站:https://seaborn.pydata.org/),它的安装方法是:
% pip install seaborn
利用 Seaborn,能够比较容易地绘制相关系数矩阵的可视化图示(关于相关系数,请参阅拙作《机器学习数学基础》,电子工业出版社)。
[5]: import seaborn as sns import numpy as np cols = df.columns[2:] cov_mat =np.cov(X_std.T)sns.set(font_scale=1.5, rc={'figure.figsize':(11.7,8.27)}) hm = sns.heatmap(cov_mat, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 12}, yticklabels=cols, xticklabels=cols) hm.set_title('Covariance matrix showing correlation coefficients')
输出图示:
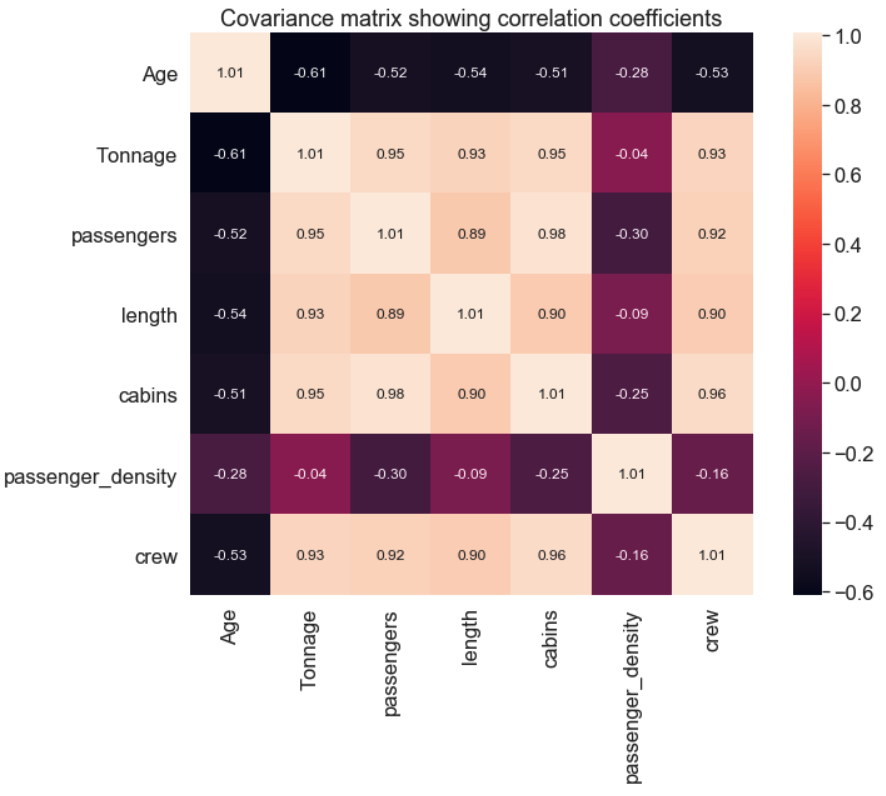
由于特征数量不多,用观察法就可以选出与特征 crew 有较强关系的特征,从而确定用于模型训练的数据集。
[6]: cols_selected = ['Tonnage', 'passengers', 'length', 'cabins','crew']
X = df[cols_selected].iloc[:,0:4].values # 特征
y = df[cols_selected]['crew'].values # 标签
X_std = StandardScaler().fit_transform(X)
y_std = StandardScaler().fit_transform(y.reshape(-1,1))
代码块 [6] 中所得到的 X_td 和 y_td 分别是经过标准化变换之后的数据集,然后将此它们划分为训练集和测试集两部分。
[7] :from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split( X_std, y_std,
test_size=0.4,
random_state=0)
将 X_train 、y_train 用于训练模型——训练集,用 X_test 、y_test 测试模型的预测效果——测试集。
3. 构建模型
在 Scikit-learn 中提供了普通的线性回归模型 LinearRegression 以及分别使用了 L1 和 L2 正则化的线性回归模型 Rige 和 Lasso ,还有一个综合了 L1 和 L2 正则化的 ElasticNet 模型。对于代码块 [7] 的训练集,使用哪一个模型?不能猜,只能逐个尝试。下面分别对 LinearRegression 、 Rige 和 Lasso 模型进行训练和测试。
[8]: from sklearn.linear_model import LinearRegression
lrg = LinearRegression() # 创建模型实例
lrg.fit(X_train, y_train) # 用训练集数据训练模型
lrg.score(X_test, y_test) # 用测试集数据测试模型
[8]: 0.9282797824863903
代码块 [8] 用三步完成了模型的创建、训练和测试,其中 lrg.score() 返回的是该模型实例的决定系数,通常记作
,其计算方法是:
显然,
的值最大是 1 ,它也可以为负数(模型太差了),但此值不是模型预测结果的正确率,虽然越接近于 1 表示预测结果越准确。请读者特别注意,有一些不严肃的资料将 lrg.score() 的结果解释得太随性了。
用与代码块 [8] 一样的步骤,训练和测试 Ridge (通常翻译为“岭回归”)模型。
[9]: from sklearn.linear_model import Ridge
rdg = Ridge(alpha=3)
rdg.fit(X_train, y_train)
rdg.score(X_test, y_test)
[9]: 0.911520190945518
注意比较代码块 [8] 和 [9] ,操作流程没有什么变化,最后返回值有所不同,这意味着什么?
[10]: from sklearn.linear_model import Lasso
las = Lasso(alpha=0.1)
las.fit(X_train, y_train)
las.score(X_test, y_test)
[10]: 0.904787627849592
根据上述三个模型的
值,可以认定 lrg 模型实例更好——这种结论太匆忙。如何选定模型,推荐读者参阅拙作《机器学习数学基础》第6章6.4.5节(电子工业出版社)。
通过上述示例,读者可以初步了解机器学习项目的基本过程。当然,这里没有涉及到算法的原理以及更复杂的数据清洗和特征功能,仅仅通过一个示例了解 Python 语言在机器学习中的运用。