在这篇文章中,我将重新创造卡牌游戏《炉石传说》卡组制作工具的卡牌排名算法
什么是《炉石传说》
炉石传说-一个虚拟纸牌游戏
对于那些不知道的人来说,《炉石传说》是一款策略纸牌游戏,其目标是创建一个包含30张纸牌的卡组并与对手对抗,将对手降至0命值的玩家将首先获胜。在竞技场游戏模式中,玩家一次抽30张牌,每次在3张牌中选择。
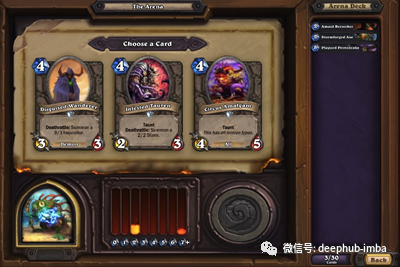
在《炉石传说》中有许多获胜策略,玩家在决定选择哪张纸牌时需要考虑许多因素:
魔法值——什么时候可以使用的纸牌是受你有多少魔法值的限制的,所以有一个魔法值是很重要的(让你可以打出每个回合需要打出的纸牌)
卡牌价值——当你用完卡牌时,你很难获胜,所以拥有能够抽取/生成更多卡牌的卡牌很重要
节奏牌——当你打出快节奏的牌时,对比赛的影响就会更大,因为它们可以改变输赢的局面
配合—— 一些卡与其他卡更好的工作,和一些卡是反协同!
HearthArena是一个为玩家提供竞技场工具的网站,玩家可以通过给每一张卡牌分配一个分数来进行选择(分数越高的卡牌越好)。
heartarena算法是如何工作的?
HearthArena 算法内置了人类知识和机器的计算。首先,人们会根据上面提到的一些标准来评估一张卡片的好坏,从而分配标准化分数。牌和胜率的数据也会从玩家每天数据中收集。然后,这些数据被用来训练一个机器学习模型,该模型被应用于对卡片分数进行微小调整。

大量卡牌数据和胜率的数据可以使模型被训练出来更好的进行模式识别,而不需要我们进行更多的操作(端到端)。例如,如果两张卡牌相互协作并提高了它们所处卡牌的胜率,那么该模型便能够把握这种趋势并进行微调以反映这种协作。
重建HearthArena 算法
我的目标是模仿《HearthArena》的做法——给出到目前为止所选纸牌和当前3个选择的信息,为每个选择分配分数。然而,为了实现这一目标,我也创造了一个模型,即为任何30张纸牌的卡组分配分数。
这个项目有两个主要部分——获取卡组和胜率的数据并重新格式化,以及建立预测分数的模型。首先,获取数据。
在Python的Requests和BeautifulSoup库的帮助下,我能够从HearthArena的网站上获取胜率的数据。然而,棘手的部分是决定这个监督学习模型需要什么数据。
监督学习是基于标记数据的模型训练。例如,如果我想根据一个人的身高(输入)预测一个人的体重(输出),我将需要关于人的身高和体重的训练数据,因此我训练的数据被标记为——人的体重是已知的。回到HearthArena,我将尝试基于当前选择和关于之前纸牌选择的信息(输入)预测分数(输出),所以我将需要所有这些作为训练数据。
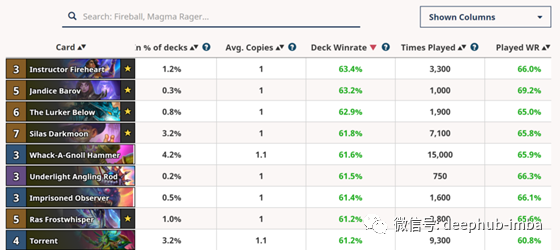
但是我只能找到关于卡牌的信息和它们的胜率(如Fireheart - 66%胜率),所以我缺少之前挑选的卡牌和相应的分数的数据。因此,我将注意力转向创建一个监督学习模型,以预测给定特定卡组(输入)的总体卡组得分(输出)。对于这个模型,我拥有所有我需要的数据——牌组列表以及相关的胜率,它们可以被规范化以获得牌组分数。
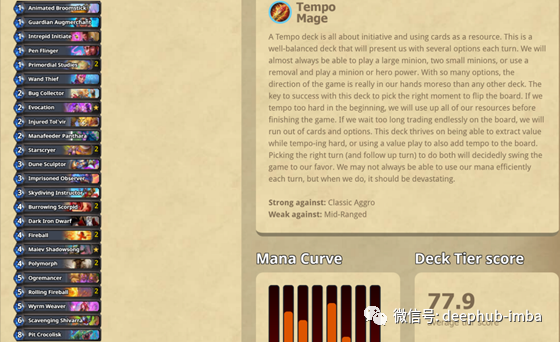
在提取数据之后,有必要对其进行格式化,以便能够将其输入模型。所以使用《炉石传说》API来提取所有可玩纸牌的列表,卡组列表(deck)被转换成以下格式:
+------------------+-----+-----+-----+-----+-----+ | Card Name | A | B | C | ... | Z | +------------------+-----+-----+-----+-----+-----+ | Deck #1 Counts | 1 | 2 | 0 | ... | 1 | | Deck #2 Counts | 0 | 1 | 0 | ... | 0 | | ... | ... | ... | ... | ... | ... | | Deck #100 Counts | 1 | 0 | 3 | ... | 1 | +------------------+-----+-----+-----+-----+-----+
#Counts refers to the number of that card in the deck
#Sum of counts across all cards for each deck = 30
将这些牌数和相应的牌组分数输入线性回归模型,我们可以看到,即使模型被训练了5000轮,也会有相当高的损失(误差)。
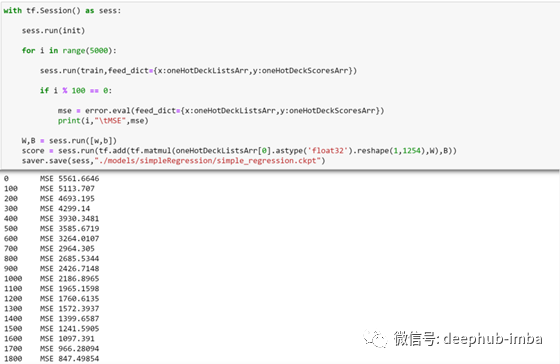
#Evaluation Metrics
{'average_loss': 8.609376,
'label/mean': 75.03246,
'loss': 86.09376,
'prediction/mean': 74.83777,
'global_step': 5000}#Prediction by Linear Regressor
array([[71.079025]], dtype=float32)
#Actual score
array([73.3])
相比之下,DNN回归模型即使在更短的时间(1000步)的训练下也优于线性回归模型。
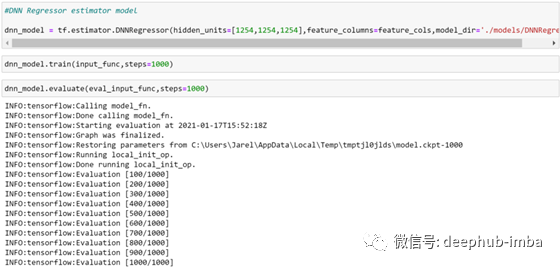
#Evaluation Metrics
{'average_loss': 3.021388e-05,
'label/mean': 75.03246,
'loss': 0.0003021388,
'prediction/mean': 75.031525,
'global_step': 1000}#Prediction by DNN Regressor (much better performance!)
[{'predictions': array([73.30318], dtype=float32)}]
#Actual score
array([73.3])
完成主要目标
但我并不满足于预测给定卡组的得分。所以在深入探索《HearthArena》后,我惊讶地发现了不同卡组的数据。
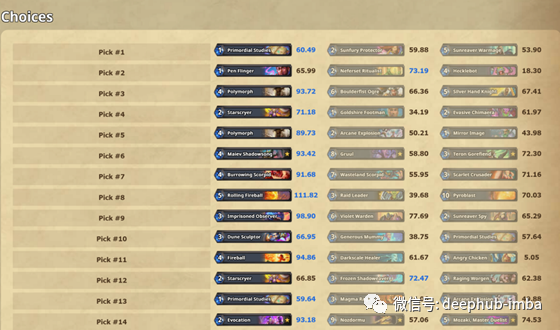
现在我有了关于几十张纸牌的数据,以及之前挑选的纸牌。需要明确的是,我所构建的模型并没有遵循hearttharena的算法,即让玩家手动分配每张卡片的分数,并让算法对分数进行微调,而是尝试着在没有玩家干预的情况下模仿hearttharena的算法。
作为一个简短的说明,有检索数据约392卡组,各有30中挑选3卡,我有392 x 30 x 3 = 35280数据用来进行计算,这大样本量还帮助在训练中更精确的模型。
再次,我重新格式化了数据,然后在此数据上训练线性回归模型和DNN回归模型。这次的线性回归模型表现很差。
#Evaluation Metrics {'average_loss': 1083.2366, 'label/mean': 61.46461, 'loss': 10832.366, 'prediction/mean': 45.357845, 'global_step': 2000}#Prediction by Linear Regressor (rather poor performance)
[{'predictions': array([79.04803], dtype=float32)},
{'predictions': array([82.29574], dtype=float32)},
{'predictions': array([77.59356], dtype=float32)}]
#Actual scores
['Air Raid', 'Guardian Augmerchant', 'Holy Light']
[64.56, 64.69, 15.85]
DNN回归模型在预测卡片得分方面表现出色。

#Evaluation Metrics
{'average_loss': 315.33557,
'label/mean': 61.46461,
'loss': 3153.3557,
'prediction/mean': 57.02432,
'global_step': 1000}#Prediction by DNN Regressor (much better performance!)
[{'predictions': array([67.01109], dtype=float32)},
{'predictions': array([82.476265], dtype=float32)},
{'predictions': array([17.470245], dtype=float32)}]
#Actual scores
['Air Raid', 'Guardian Augmerchant', 'Holy Light']
[64.56, 64.69, 15.85]
这样我们得到了一个可以在竞技场中绘制牌组时应用的模型。在使用这个模型运行了几次之后,我可以说它在分配分数方面相当准确,我基本上同意这个算法所做的选择。
最后总结
作为一名狂热的竞技场玩家,我一直想要深入挖掘HearthArena算法的内部工作原理,而随着我在Tensorflow中新学到的技能,这成为了现实。我仍然感到惊讶的是,虽然优秀的竞技场玩家在做出节奏、价值和协同效应等选择时会考虑许多因素,但使用Tensorflow构建的深度学习模型并不依赖于你指定它所寻找的趋势。
对于那些希望自己着手这样一个项目的人,我从这次经历中获得了一些更重要的收获:
- 使用Tensorflow提供的预估器,模型训练、评估和预测相对容易;困难的部分是处理数据和维度
- 在任何类似的项目中,确定你需要什么数据,并且可以合理获得什么数据,无疑是最大的挑战。准备好理解如何使用提供的api
- 最重要的是,相信自己,愿意尝试。当我第一次开始这个项目的时候,我很难想象能够达到我的目标,但是我的信念有了飞跃,并且对结果感到惊喜!
最后给出这个项目的代码:https://github.com/Jareltey/Hearthstone-Deckbuilder
作者:Teyjarel
deephub翻译组