近日Stability AI推出了一款名为Stable Audio的尖端生成模型,该模型可以根据用户提供的文本提示来创建音乐。在NVIDIA A100 GPU上Stable Audio可以在一秒钟内以44.1 kHz的采样率产生95秒的立体声音频,与原始录音相比,该模型处理时间的大幅减少归因于它对压缩音频潜在表示的有效处理。
架构
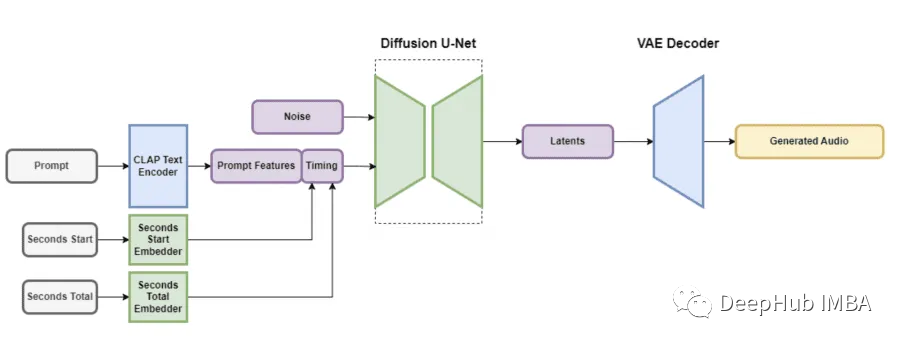
自动编码器(VAE),一个文本编码器和U-Net扩散模型。VAE通过获取输入音频数据并表示为保留足够信息用于转换的压缩格式,因为使用了卷积结构,所以不受描述音频编解码器的影响,可以有效地编码和解码可变长度的音频,同时保持高输出质量。
文本提示通过预先训练的文本编码器(称为CLAP)无缝集成。这个编码器是使用精心策划的数据集从头开始构建的,可以保留了文本特征包含了足够的信息,可以在单词和相应的声音之间建立有意义的联系。从CLAP编码器的倒数第二层提取的这些文本特征,然后通过U-Net的注意力层进行引导。
为了生成用于时间嵌入的音频片段,需要计算两个关键参数:片段的起始时间(以秒为单位)(称为“seconds_start”)和原始音频文件的总持续时间(以秒为单位)(称为“seconds_total”)。这些值被转换成离散学习的嵌入,在输入到U-Net的注意层之前与查询令牌连接。在推理阶段,这些值作为条件允许用户指定所需的最终音频输出长度。
Stable Audio中的扩散模型是一个U-Net架构,具有强大的9.07亿个参数,灵感来自Moûsai 模型。它结合残差层、自注意力层和交叉注意力层,基于文本和时间嵌入对输入数据进行有效降噪。
数据集
Stable Audio在包含超过80万个音频文件的广泛数据集上进行了训练。这个多样化的集合包括音乐、音效、乐器样本及其相关的文本元数据,总时长超过19,500小时。这个广泛的数据集是通过与音乐库AudioSparx的合作而提供的。
总结
Stability AI的Stable Audio AI模型标志着人工智能驱动的听觉创造力的重大飞跃。它为音乐和声音爱好者打开了新的视野。在未来还会提供进一步增强模型、数据集和训练技术的体系结构,发布基于Stable Audio的开源模型,并将提供必要的代码,以方便定制音频内容生成模型的训练。
项目的官方网站:
https://www.stableaudioweb.com/