文章源自【字节脉搏社区】-字节脉搏实验室
作者-M9kj-team
需求原因:
很多时候通过云悉和情报社区等平台查询到的指纹很详细,然而绝大部分人却不能进行相关中间件甚至相关系统漏洞的查找,只是简单的百度,不过通过百度我们也不可能查询到所有的漏洞,因为许多文章是被robots协议限制的。
举个例子:我搜索db-exploit,百度搜索到的是:https://www.exploit-db.com/,而我们要的网站是:http://cve.mitre.org/这个就是说明百度也不能完整的查询到我们所需要的,所以说我们就更需要来定制漏洞查询系统这个工具。

实现理想模型图:
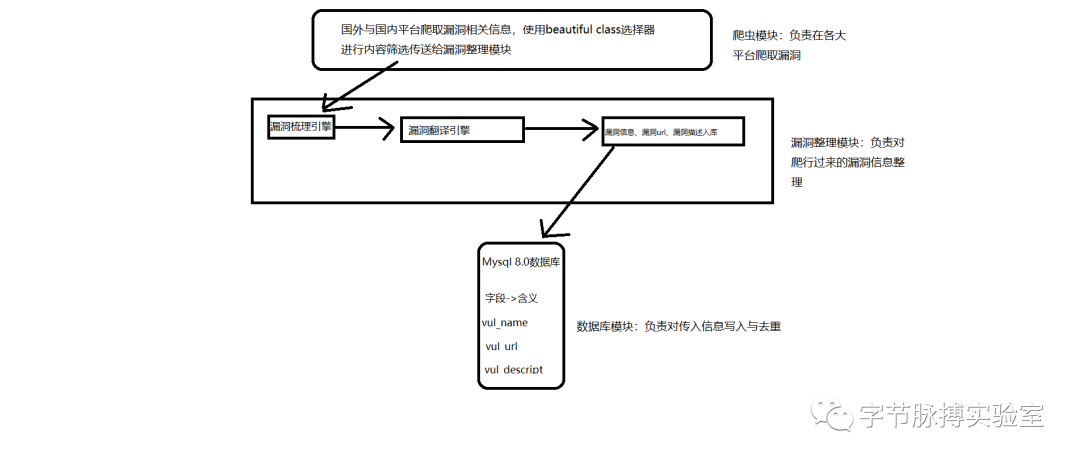
(注意其中的语言识别引擎是调用百度翻译api)
部分小案例:
(ps:项目需要造潜艇,我花了几分钟造出来的草船各位先看看重在领会精神…)
(观众反应:)


我:下面是俺的代码啊
# -*- coding:UTF-8 -*- from bs4 import BeautifulSoup import requests from requests.packages.urllib3.exceptions import InsecureRequestWarning requests.packages.urllib3.disable_warnings(InsecureRequestWarning) #解决编码问题 ? 编码 unicode import io import sys sys.stdout = io.TextIOWrapper(sys.stdout.buffer,encoding='gb18030') #解决编码问题 ? 编码 unicode #公共变量header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/53.0.2785.143 Safari/537.36','Connection': 'keep-alive','accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'}
url = 'http://cve.mitre.org/cgi-bin/cvekey.cgi?keyword=tomcat'

req = requests.get(url=url,headers=header) res = req.text # print(res) soup = BeautifulSoup(res,'html.parser') match = soup.find('div',{'id':'TableWithRules'}) # print(match) tr_match = match.find_all('tr') # print(tr_match) for tr in tr_match: td_match = tr.find_all('td') try: print('搜索到的漏洞名称是:{0},漏洞连接是:{1},漏洞描述是:{2}'.format(td_match[0].a.string,'http://cve.mitre.org/'+td_match[0].a.get('href'),td_match[1].get_text().strip('\n').strip(' '))) except: continue
观众:为什么没有解释? 我:不解释连招,有本事百度哈哈~

小案例程序实现效果:
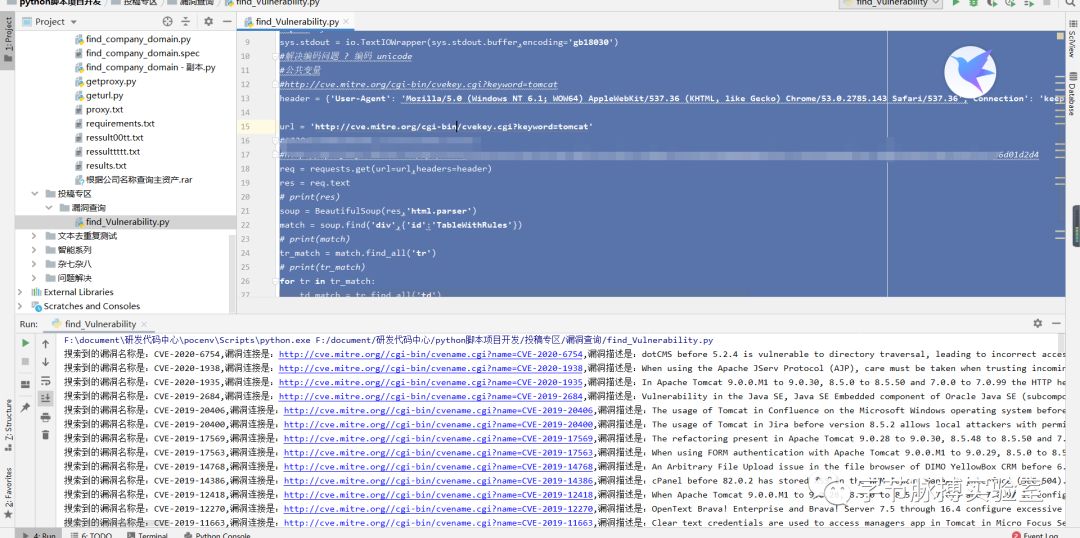
最后我想说:
其实这个实现思路跟我的poc集成攻击软件思路一模一样的,都是基于mysql的一个攻击框架亦或者说是信息搜集框架,只要心里有井哪里都是空,其实大家可以没事看下浪子大神的程序设计思路,感觉非常完美,堪比某些厂商只会调用awvs扫描器接口的封装扫描器。(只要UI美甲方都觉得牛皮,这是个真理)。。。下..下一篇见