引言
是否遇到过,一个简单的业务统计需求却让数据工程师们抓耳挠腮?
是否遇到过,业务峰值周期明显,要么资源大量闲置, 要么线上疯狂告警?
是否遇到过,大数据集群运维复杂,需要投入大量技术工程师?
针对以上痛点, 腾讯云发布云原生数据湖计算服务,协同腾讯云端数据湖体系,帮助企业高效构建云端数据湖架构、降低数据计算成本,提升数据分析敏捷性、激发数据应用价值,助力企业数字化决策。
本文作者:ericshhxie
一、数据湖的前世今生
2010年 Pentaho 公司的创始人兼首席技术官詹姆斯·狄克逊(James Dixon)首次提出数据湖的概念。把数据湖中的数据比作原生态的水——它是未经处理的,原汁原味的。数据湖中的水从源头流入湖中,各种用户都可以来湖里获取、蒸馏提纯这些水(数据)。此时, 大家对于数据湖的理解主要是当作一个集中式的存储系统,允许存储任意规模的结构化和非结构化数据。
随着存 HDFS 和对象存储等技术的发展, 海量数据的低成本存储问题得以解决,用户对湖中数据价值萃取的诉求愈发强烈。至此,数据湖重点从存储转向数据的计算分析,核心在于提升数据分析的敏捷性、增强对数据的洞察力。
2017年前后,兴起了新一轮的 AI 热潮。深度学习和超大规模的神经网络更离不开对海量数据文件的敏捷处理。借助数据湖架构,可以更好地打通数据之间的壁垒,支撑AI 模型训练、推理以及数据预处理。
发展至今, 数据湖已经不再局限于某个技术、某个软件产品,而是涵盖数据湖存储、数据湖计算、数据湖AI的多元化数据架构,满足企业级用户的生产管理需求。
腾讯技术和产品发展至今,几乎任何一个与用户相关的业务数据量都在亿级别,每日系统调用次数从亿到百亿,对海量异构数据的低成本存储和高敏捷分析是最重要的关注点。我们认为:“数据湖是企业新一代数据技术架构,可以赋予客户更高的数据敏捷度、更低的分析成本,而云是数据湖的最佳实践场所”。
二、腾讯云原生数据湖架构
选择 Cloud 还是 Local 的诸多讨论和实践中,成本一直是绕不开的话题。“在云端部署数据架构不如想象的便宜”,国内不少刚开始接触云服务的企业会有如此感叹。反观国外很多中大型企业(例如 Netflix,Pinterest),或者体量较大的中国出海公司(Shareit,Mobvista)更偏向于选择公有云服务。其核心差异是云原生技术的普及和落地,如何更好的利用云服务的优势,达到比本地自建大数据平台更低的IT成本,是云服务厂商和企业用户共同探索的关键点。

为了解决海量异构数据的存储和敏捷分析问题,腾讯云推出了云端数据湖体系,其包含:海量异构数据的存储能力、面向多元化场景的分析能力、音视图文的 AI 智能化能力。客户借助于腾讯云“数据云原生”能力, 高效构建企业级数据湖架构, 降低企业数据成本 、 提升企业数据敏捷性,助力企业数字化决策。

腾讯云数据湖体系围绕数据湖存储、数据湖计算、数据湖 AI,覆盖数据业务全场景,形成综合性云端数据湖解决方案。目前,腾讯云数据湖体系已服务众多内外部客户,算力弹性资源池达500万核,存储数据超过100PB,日采集数据量超500TB,每日分析任务数达1500万,每日实时计算次数超过超过万亿,能支持上亿维度的数据训练。
三、云原生数据湖计算
通常使用大数据分析组件对对象存储中的数据进行分析时, 会面临两个核心问题:
- 如何基于云服务兼容特性屏蔽底层架构,降低计算成本?
- 如何加速和优化存储侧的性能瓶颈?

为了解决数据湖敏捷高效的分析和计算问题,腾讯云推出一款开箱即用的数据湖分析服务——腾讯云数据湖计算(Data Lake Compute,DLC)(官网介绍:https://cloud.tencent.com/product/dlc)。
该服务采用 Serverless 架构,用户无需关注底层架构或维护计算资源,使用标准 SQL 即可完成对象存储服务(COS)及其他云端数据设施的联合分析计算。借助于该服务,用户无需进行传统的数据分层建模,大幅缩减了海量数据分析的准备时间,有效提升企业数据敏捷度。

腾讯云 DLC 服务联合腾讯多个团队深耕核心技术, 以提供一款高性能数据计算服务为目标,实现了如下几个关键技术特征:
数据湖高性能计算
腾讯云 DLC 引入高性能 serverless presto 引擎,针对数据湖底层存储的特点,在稳定性和性能方面做了大量的优化。
数据倾斜多年来一直是数据工程的宿敌,对云原生数据湖架构而言却是个好消息:在数据 scan 阶段,数据热度的巨大差异可以用很少的缓存来撬动很好的加速效果。在腾讯常见的大数据场景中,我们发现 read-only 的请求的缓存命中率高达75%-85%,甚至可能更高。
除了缓存加速,减少数据文件的扫描量在数据湖架构下更重要,如何做好数据排布需要新一代的建模技术。除了分区,分桶等传统技术,稀疏索引在数据湖扮演非常重要的作用。AP 向 TP存储格式设计的靠拢大大加速了分析性能,可以看到一些高性能数仓技术如 clickhouse 都会引入稀疏索引技术,在不过分消耗存储的基础上大大提升了查询性能。
数据湖存储透明加速
客户最关注的问题是:如何把数据快速输送给大数据引擎,让引擎高效率工作。这是腾讯云工程师们一直在思考的问题。
对象存储服务 COS 作为数据湖统一存储服务,在确保数据安全、可靠、无限扩展能力的基础上,针对大数据业务 IO 特点做了进一步性能优化,分别在计算端、AZ 端、存储端提供了性能加速能力。

这三级加速位于数据湖计算引擎和 COS 持久化存储之间,为数据分析和存储系统建了桥梁, 将数据从 COS 对象存储移动到距离数据应用更近的位置,使数据能够更容易被访问到。层次化的加速架构,使得数据的访问速度能比现有方案有数量级的提升。
低成本,无限算力云原生数据湖
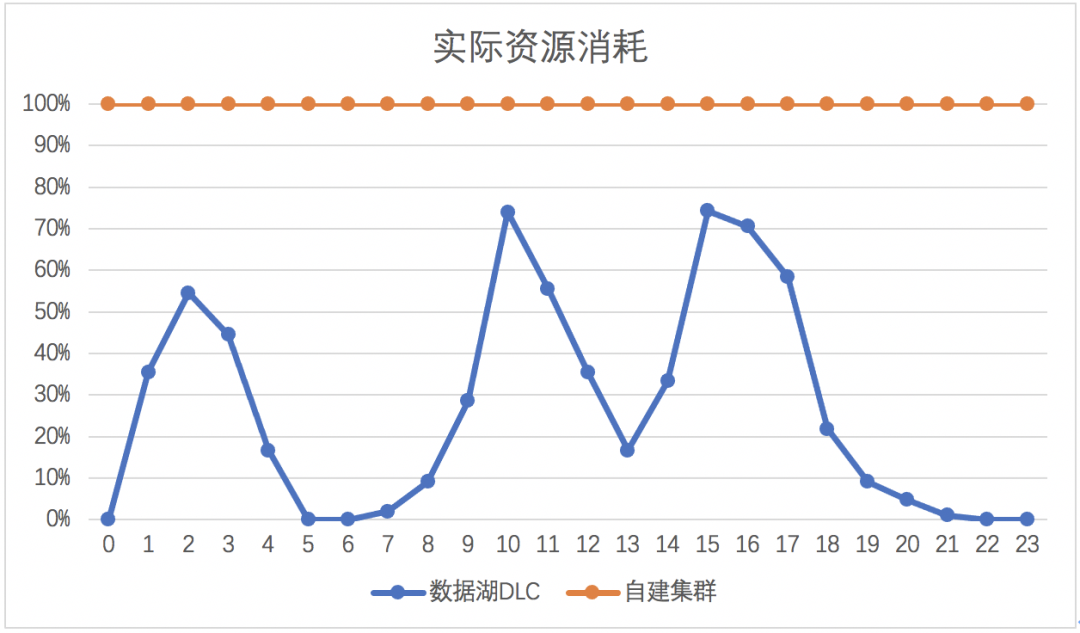
相对于传统固定规模集群,腾讯数据湖技术完全基于腾讯云弹性容器技术(EKS:https://cloud.tencent.com/document/product/457/39804)构建,理论上“无限”的计算资源随时可供秒级调度,满足不同规模的计算任务,使用者再也不用关心底层资源的部署和运维。
在传统基于物理机/虚拟机的大数据架构下,往往要维护一个规模相对固定的计算集群,资源成本存在巨大的浪费。而云数据湖技术真正做到了随用随弃,充分利用弹性计算资源。计算引擎资源的创建、自动扩缩容、删除、秒级监控等功能全部交由 EKS 的控制模块来负责,用户只需直接提交计算任务即可。当 DLC 预测到当前算力即将不足时,动态扩容计算资源以补充算力,作业无须重新执行,大幅度减少集群空闲时的成本浪费,同时又能快速响应各种临时 /backfill 需求。
四、腾讯云原生数据湖技术未来展望
随着企业对数据驱动业务需求的加深,也随着海量数据分析技术的成熟,传统单一的数据架构也没法满足多变的数据分析需求。腾讯云推出云原生数据湖体系,一方面降低数据存储和分析的成本, 另一方面大幅度提升数据分析的敏捷性。
腾讯云数据湖体系架构,未来将会继续在如下几个方面继续深耕,进一步推动云端数据湖的技术发展。
1.灵活高效的计算引擎调度
在大数据领域,没有一个万能的 SQL 执行引擎,不同的计算引擎擅长不同的任务。基于腾讯大数据漂移计算技术,可以智能选择对应最佳的计算引擎,支持数据源下推和 CBO 优化,提供更佳的分析性能。
2.增强数据湖入湖能力
提供更优的数据入湖能力,支持 ACID 事务能力,可以大幅缩短数据入湖操作流程,提升 ETL处理效率。
3.更优的流批处理能力
提供流式增量和批式全量处理能力,使用相同的高性能存储模型,数据不再孤立,架构更简单。
4.更好的兼容性和扩展性
更好的适配支持 Hadoop 生态,对象存储的语义,结合 Cache 能力解决对象存储性能问题。支持智能行列混存,针对读/写不同场景下有更好的性能。
5.更低成本的 Serverless 算力支持
EKS 即将推出更具成本优势的竞价型容器服务, 进一步减少数据湖计算资源的成本消耗,从而更降低用户使用数据湖分析的价格。
关于我们
云+社区「腾讯云存储团队」主页,涵盖了腾讯云存储团队最新动态、团队信息、产品矩阵、技术文档、视频教程等,欢迎关注或留言,给出您的宝贵建议。