
GWAS计算BLUE值2--LMM计算BLUE值 #2021.12.12
本节,介绍如何使用R语言的lme4包拟合混合线性模型,计算最佳线性无偏估计(blue)
1. 试验数据
❝数据来源:Isik F , Holland J , Maltecca C . Genetic Data Analysis for Plant and Animal Breeding. Springer International Publishing, 2017.❞
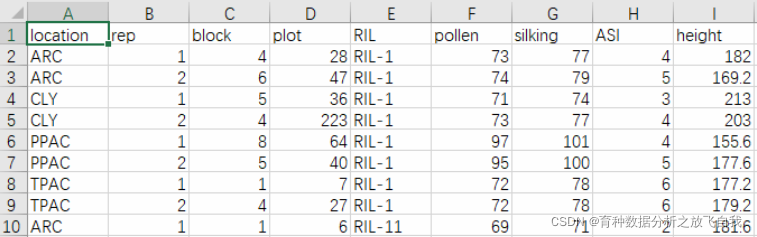
该数据有62个重组自交系(RIL),在4个地点进行试验,随机区组,每个地点2个重复,每个小区种植20株,随机选择5株的表型平均值作为观测值。
2. 读取数据及转换为因子
library(lme4) library(emmeans) library(data.table) library(tidyverse) library(asreml)dat = fread("MaizeRILs.csv",data.table = F)
head(dat)
str(dat)
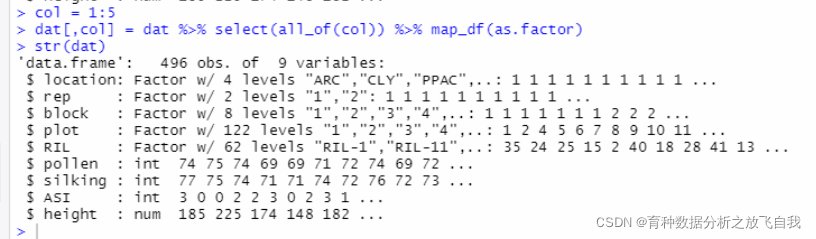
col = 1:5
dat[,col] = dat %>% select(all_of(col)) %>% map_df(as.factor)
str(dat)
之前,我批量转化为因子,都是用for循环,这次用的是map函数,可读性更强。
3. 使用lme4包进行blue值计算
这里,使用lme4包进行blue值计算,然后使用emmeans包进行预测均值(predict means)的计算,这样就可以将predict means作为表型值进行GWAS分析了。
# lme4
m1 = lmer(height ~ RIL + (1|location:RIL) + (1|location) + (1|location:rep), data=dat)
summary(m1)
re1 = emmeans(m1,"RIL") %>% as.data.frame()
head(re1)
这里,
- RIL作为固定因子
- 地点和品种互作,作为随机因子
- 地点内区组,作为随机因子
然后通过emmeans计算RIL的预测均值。
「注意,lme4直接计算的固定因子(RIL)的效应值(BLUE值),不是我们最终的目的,因为它是效应值,有正有负,我们需要用预测均值将其变为与表型数据尺度一样的水平。」
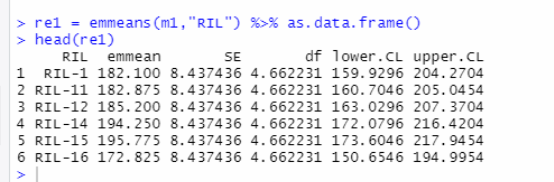
emmeans这一列就是预测均值了。
4. 使用asreml包进行blue值计算
library(asreml)
m2 = asreml(height ~ RIL, random = ~ location + location:RIL + location:rep,data=dat)
summary(m2)$varcomp
re2 = predict(m2,classify = "RIL")$pval %>% as.data.frame()
head(re2)
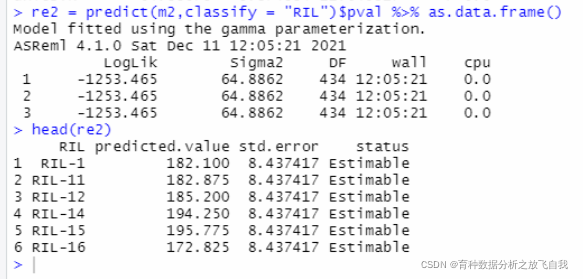
这里,用predict进行预测均值的计算,predicted.value这一列就是blue值,两者结果一致。
5. 你以为这样就结束了?
95%的同学,在计算GWAS分析表型值计算时,都是用上面的模型计算出blue值,然后直接进行计算,其实还有更好的模型。
比如设置每个地点的残差异质,然后和残差同质的模型进行LRT检验,选择最优的模型。
比如设置每个地点与品种的互作的方差异质,比较方差同质的模型,选择最优的模型。
下节见。