大数据开发总体架构

Flink 概述
Apache Flink 是一个框架和分布式处理引擎,用于对无边界和有边界的数据流进行有状态的计算。Flink被设计为可以在所有常见集群环境中运行,并能以内存速度和任意规模执行计算。目前市场上主流的流式计算框架有Apache Storm、Spark Streaming、Apache Flink等,但能够同时支持低延迟、高吞吐、Exactly-Once(收到的消息仅处理一次)的框架只有Apache Flink。
Flink是原生的流处理系统,但也提供了批处理API,拥有基于流式计算引擎处理批量数据的计算能力,真正实现了批流统一。与Spark批处理不同的是,Flink把批处理当作流处理中的一种特殊情况。在Flink中,所有的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
Flink的主要优势如下
同时支持高吞吐、低延迟
Flink是目前开源社区中唯一同时支持高吞吐、低延迟的分布式流式数据处理框架,在每秒处理数百万条事件的同时能够保持毫秒级延迟。而同类框架Spark Streaming在流式计算中无法做到低延迟保障。Apache Storm可以做到低延迟,但无法满足高吞吐的要求。同时满足高吞吐、低延迟对流式数据处理框架是非常重要的,可以大大提高数据处理的性能。
支持有状态计算
所谓状态,就是在流式计算过程中将算子(Flink提供了丰富的用于数据处理的函数,这些函数称为算子)的中间结果(需要持续聚合计算,依赖后续的数据记录)保存在内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果,以便计算当前的结果(当前结果的计算可能依赖于之前的中间结果),从而无须每次都基于全部的原始数据来统计结果,极大地提升了系统性能。

支持事件时间
时间是流处理框架的一个重要组成部分。目前大多数框架计算采用的都是系统处理时间(Process Time),也就是事件传输到计算框架处理时,系统主机的当前时间。Flink除了支持处理时间外,还支持事件时间(Event Time),根据事件本身自带的时间戳(事件的产生时间)进行结果的计算,例如窗口聚合、会话计算、模式检测和基于时间的聚合等。这种基于事件驱动的机制使得事件即使乱序到达,Flink也能够计算出精确的结果,保证了结果的准确性和一致性。
支持高可用性配置
Flink可以与YARN、HDFS、ZooKeeper等紧密集成,配置高可用,从而可以实现快速故障恢复、动态扩容、7×24小时运行流式应用等作业。Flink可以将任务执行的快照保存在存储介质上,当需要停机运维等操作时,下次启动可以直接从事先保存的快照恢复原有的计算状态,使得任务继续按照停机之前的状态运行。
提供了不同层级的API
Flink为流处理和批处理提供了不同层级的API,每一种API在简洁性和表达力上有着不同的侧重,并且针对不同的应用场景,不同层级的API降低了系统耦合度,也为用户构建Flink应用程序提供了丰富且友好的接口。
Flink的应用场景

事件驱动
根据到来的事件流触发计算、状态更新或其他外部动作,主要应用实例有反欺诈、异常检测、基于规则的报警、业务流程监控、(社交网络)Web应用等。
传统应用和事件驱动型应用架构的区别如图:

数据分析
从原始数据中提取有价值的信息和指标,这些信息和指标数据可以写入外部数据库系统或以内部状态的形式维护,主要应用实例有电信网络质量监控、移动应用中的产品更新及实验评估分析、实时数据分析、大规模图分析等。
Flink同时支持批量及流式分析应用,如图:

数据管道
数据管道和ETL(Extract-Transform-Load,提取-转换-加载)作业的用途相似,都可以转换、丰富数据,并将其从某个存储系统移动到另一个。与ETL不同的是,ETL作业通常会周期性地触发,将数据从事务型数据库复制到分析型数据库或数据仓库。但数据管道是以持续流模式运行的,而非周期性触发,它支持从一个不断生成数据的源头读取记录,并将它们以低延迟移动到终点。例如,监控文件系统目录中的新文件,并将其数据写入事件日志。
数据管道的主要应用实例有电子商务中的实时查询索引构建、持续ETL等。周期性ETL作业和持续数据管道的对比如图:

Flink主要组件
Flink是由多个组件构成的软件栈,整个软件栈可分为4层,如图:

存储层
Flink本身并没有提供分布式文件系统,因此Flink的分析大多依赖于HDFS,也可以从HBase和Amazon S3(亚马逊云存储服务)等持久层读取数据。
调度层
Flink自带一个简易的资源调度器,称为独立调度器(Standalone)。若集群中没有任何资源管理器,则可以使用自带的独立调度器。当然,Flink也支持在其他的集群管理器上运行,包括Hadoop YARN、Apache Mesos等。
计算层
Flink的核心是一个对由很多计算任务组成的、运行在多个工作机器或者一个计算集群上的应用进行调度、分发以及监控的计算引擎,为API工具层提供基础服务。
工具层
在Flink Runtime的基础上,Flink提供了面向流处理(DataStream API)和批处理(DataSet API)的不同计算接口,并在此接口上抽象出了不同的应用类型组件库,例如基于流处理的CEP(复杂事件处理库)、Table&SQL(结构化表处理库)和基于批处理的Gelly(图计算库)、FlinkML(机器学习库)、Table&SQL(结构化表处理库)。
Flink运行架构及原理
YARN架构
Flink有多种运行模式,可以运行在一台机器上,称为本地(单机)模式;也可以使用YARN或Mesos作为底层资源调度系统以分布式的方式在集群中运行,称为Flink On YARN模式(目前企业中使用最多的模式);还可以使用Flink自带的资源调度系统,不依赖其他系统,称为Flink Standalone模式。
本地模式通常用于对应用程序的简单测试。
YARN集群总体上是经典的主/从(Master/Slave)架构,主要由ResourceManager、NodeManager、ApplicationMaster和Container等几个组件构成,YARN集群架构如图:
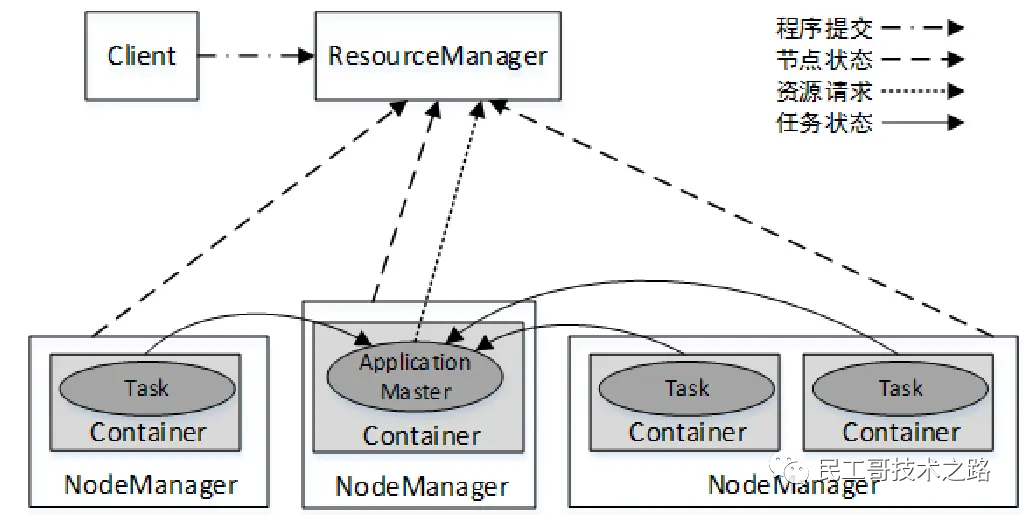
YARN集群中应用程序的执行流程如图。
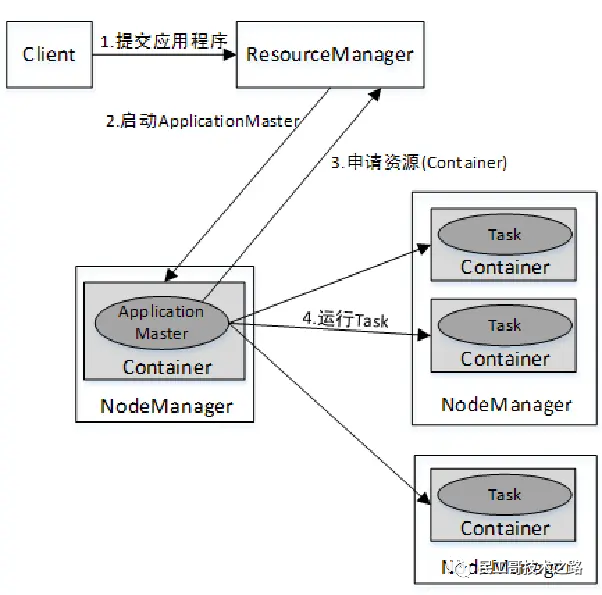
Standalone架构
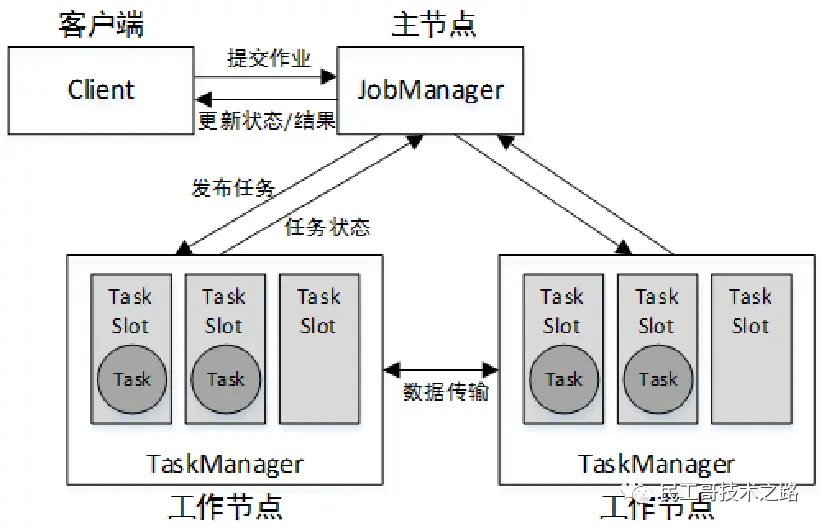
Flink Standalone模式为经典的主从(Master/Slave)架构,资源调度是Flink自己实现的。集群启动后,主节点上会启动一个JobManager进程,类似YARN集群的ResourceManager,因此主节点也称为JobManager节点;各个从节点上会启动一个TaskManager进程,类似YARN集群的NodeManager,因此从节点也称为TaskManager节点。
从Flink 1.6版本开始,将主节点上的进程名称改为了StandaloneSessionClusterEntrypoint,从节点的进程名称改为了TaskManagerRunner,在这里为了方便使用,仍然沿用之前版本的称呼,即JobManager和TaskManager。Flink Standalone模式的运行架构如图:
Client接收到Flink应用程序后,将作业提交给 JobManager。JobManager要做的第一件事就是分配Task(任务)所需的资源。完成资源分配后,Task将被 JobManager 提交给相应的 TaskManager,TaskManager会启动线程开始执行。在执行过程中,TaskManager会持续向JobManager汇报状态信息,例如开始执行、进行中或完成等状态。作业执行完成后,结果将通过JobManager发送给Client。
On YARN架构
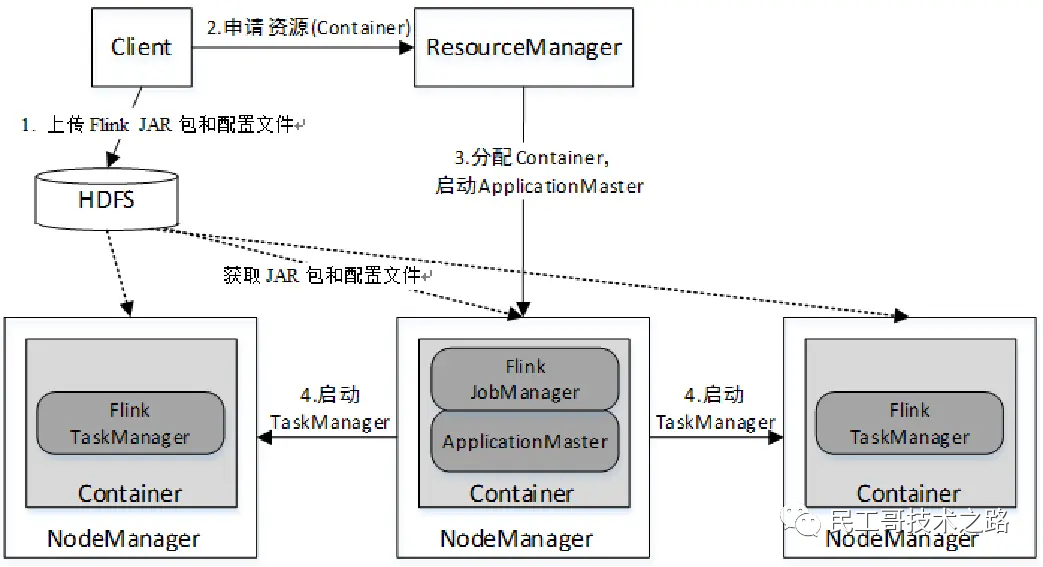
Flink On YARN模式遵循YARN的官方规范,YARN只负责资源的管理和调度,运行哪种应用程序由用户自己实现,因此可能在YARN上同时运行MapReduce程序、Spark程序、Flink程序等。YARN很好地对每一个程序实现了资源的隔离,这使得Spark、MapReduce、Flink等可以运行于同一个集群中,共享集群存储资源与计算资源。
Flink On YARN模式的运行架构如图:
Flink数据分区
在Flink中,数据流或数据集被划分成多个独立的子集,这些子集分布到了不同的节点上,而每一个子集称为分区(Partition)。因此可以说,Flink中的数据流或数据集是由若干个分区组成的。数据流或数据集与分区的关系如图:

Flink安装及部署
Flink可以在Linux、macOS和Windows上运行。前提条件是集群各节点提前安装JDK8以上版本,并配置好SSH免密登录,因为集群各节点之间需要相互通信,Flink主节点需要对其他节点进行远程管理和监控。
从Flink官网下载页面https://flink.apache.org/downloads.html下载二进制安装文件,并选择对应的Scala版本,此处选择Apache Flink 1.13.0 for Scala 2.11(Flink版本为1.13.0,使用的Scala版本为2.11)。
由于当前版本的Flink不包含Hadoop相关依赖库,如果需要结合Hadoop(例如读取HDFS中的数据),还需要下载预先捆绑的Hadoop JAR包,并将其放置在Flink安装目录的lib目录中。
此处选择Pre-bundled Hadoop 2.8.3(适用于Hadoop 2.8.3),如图:

Flink 集群安装
接下来使用3个节点(主机名分别为centos01、centos02、centos03)讲解Flink各种运行模式的搭建。3个节点的主机名与IP的对应关系如表。

Flink 本地模式
接下来讲解在CentOS 7操作系统中搭建Flink本地模式。
上传解压安装包
#将下载的Flink安装包flink-1.13.0-bin-scala_2.11.tgz上传到centos01节点的/opt/softwares目录,然后进入该目录,执行以下命令将其解压到目录/opt/modules中。
$ tar -zxvf flink-1.13.0-bin-scala_2.11.tgz -C /opt/modules/
启动Flink
#进入Flink安装目录,执行以下命令启动Flink
$ bin/start-cluster.sh
启动后,使用jps命令查看Flink的JVM进程,命令如下:
$ jps
13309 StandaloneSessionClusterEntrypoint
13599 TaskManagerRunner
若出现上述进程,则代表启动成功。StandaloneSessionClusterEntrypoint为Flink主进程,即JobManager;TaskManagerRunner为Flink从进程,即TaskManager。
查看WebUI
在浏览器中访问服务器8081端口即可查看Flink的WebUI,此处访问地址http://192.168.170.133/,如图:

从WebUI中可以看出,当前本地模式的Task Slot数量和TaskManager数量都为1(Task Slot数量默认为1)。
Flink集群搭建Standalone模式
Flink Standalone模式的搭建需要在集群的每个节点都安装Flink,集群角色分配如表:

集群搭建的操作步骤如下:
上传解压安装包
#将下载的Flink安装包flink-1.13.0-bin-scala_2.11.tgz上传到centos01节点的/opt/softwares目录,然后进入该目录,执行以下命令将其解压到目录/opt/modules中。
$ tar -zxvf flink-1.13.0-bin-scala_2.11.tgz -C /opt/modules/
修改配置文件
Flink的配置文件都存放于安装目录下的conf目录,进入该目录,执行以下操作。
修改flink-conf.yaml文件
$ vim conf/flink-conf.yaml
将文件中jobmanager.rpc.address属性的值改为centos01,命令如下:
jobmanager.rpc.address: centos01
上述配置表示指定集群主节点(JobManager)的主机名(或IP),此处为centos01。
修改workers文件
workers文件必须包含所有需要启动的TaskManager节点的主机名,且每个主机名占一行。
执行以下命令修改workers文件:
$ vim conf/workers
改为以下内容:
centos02
centos03
上述配置表示将centos02和centos03节点设置为集群的从节点(TaskManager节点)。
复制Flink安装文件到其他节点
在centos01节点中进入/opt/modules/目录执行以下命令,将Flink安装文件复制到其他节点:
$ scp -r flink-1.13.0/ centos02:/opt/modules/
$ scp -r flink-1.13.0/ centos03:/opt/modules/
启动Flink集群
在centos01节点上进入Flink安装目录,执行以下命令启动Flink集群:
$ bin/start-cluster.sh
启动完毕后,分别在各节点执行jps命令,查看启动的Java进程。若各节点存在以下进程,则说明集群启动成功。
centos01节点:StandaloneSessionClusterEntrypoint
centos02节点:TaskManagerRunner
centos03节点:TaskManagerRunner
查看WebUI
集群启动后,在浏览器中访问JobManager节点的8081端口即可查看Flink的WebUI,此处访问地址http://192.168.170.133/,如图:
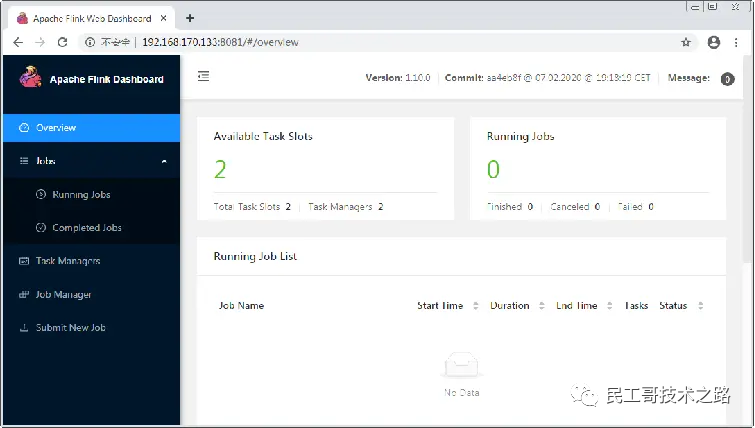
从WebUI中可以看出,当前集群总的Task Slot数量(每个节点的Task Slot数量默认为1)和TaskManager数量都为2。
Flink 集群搭建 On YARN 模式
Flink On YARN模式的搭建比较简单,仅需要在YARN集群的一个节点上安装Flink即可,该节点可作为提交Flink应用程序到YARN集群的客户端。
若要在YARN上运行Flink应用,则需要注意以下几点:
- 1)Hadoop版本应在2.2以上。
- 2)必须事先确保环境变量文件中配置了HADOOP_CONF_DIR、YARN_CONF_DIR或者HADOOP_HOME,Flink客户端会通过该环境变量读取YARN和HDFS的配置信息,以便正确加载Hadoop配置以访问YARN,否则将启动失败。
- 3)需要下载预先捆绑的Hadoop JAR包,并将其放置在Flink安装目录的lib目录中,本例使用flink-shaded-hadoop-2-uber-2.8.3-10.0.jar。具体下载方式见3.1节的Flink集群搭建。
- 4)需要提前将HDFS和YARN集群启动。
本例使用的Hadoop集群各节点的角色分配如表:

在Flink On YARN模式中,根据作业的运行方式不同,又分为两种模式:Flink YARN Session模式和Flink Single Job(独立作业)模式。
Flink YARN Session模式需要先在YARN中启动一个长时间运行的Flink集群,也称为Flink YARN Session集群,该集群会常驻在YARN集群中,除非手动停止。客户端向Flink YARN Session集群中提交作业时,相当于连接到一个预先存在的、长期运行的Flink集群,该集群可以接受多个作业提交。即使所有作业完成后,集群(和JobManager)仍将继续运行直到手动停止。该模式下,Flink会向YARN一次性申请足够多的资源,资源永久保持不变,如果资源被占满,则下一个作业无法提交,只能等其中一个作业执行完成后释放资源,如图:
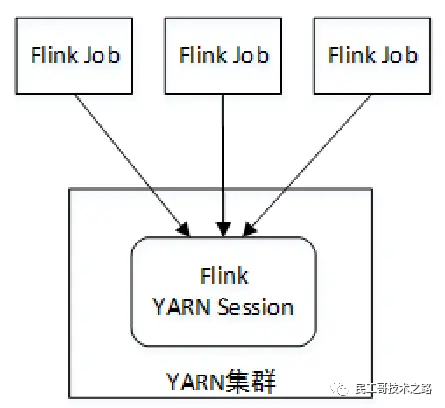
拥有一个预先存在的集群可以节省大量时间申请资源和启动TaskManager。作业可以使用现有资源快速执行计算是非常重要的。
Flink Single Job模式不需要提前启动Flink YARN Session集群,直接在YARN上提交Flink作业即可。每一个作业会根据自身情况向YARN申请资源,不会影响其他作业运行,除非整个YARN集群已无任何资源。并且每个作业都有自己的JobManager和TaskManager,相当于为每个作业提供了一个集群环境,当作业结束后,对应的组件也会同时释放。该模式不会额外占用资源,使资源利用率达到最大,在生产环境中推荐使用这种模式,如图:

Flink YARN Session模式操作
启动Flink YARN Session集群
#在启动HDFS和YARN集群后,在YARN集群主节点(此处为centos01节点)安装好Flink,进入Flink主目录执行以下命令,即可启动Flink YARN Session集群:
$ bin/yarn-session.sh -jm 1024 -tm 2048
上述命令中的参数-jm表示指定JobManager容器的内存大小(单位为MB),参数-tm表示指定TaskManager容器的内存大小(单位为MB)。
启动完毕后,会在启动节点(此处为centos01节点)产生一个名为FlinkYarnSessionCli的进程,该进程是Flink客户端进程;在其中一个NodeManager节点产生一个名为YarnSessionClusterEntrypoint的进程,该进程是Flink JobManager进程。而Flink TaskManager进程不会启动,在后续向集群提交作业时才会启动。例如,启动完毕后查看centos01节点的进程可能如下:
$ jps
7232 NodeManager
6626 NameNode
14422 YarnSessionClusterEntrypoint
14249 FlinkYarnSessionCli
6956 SecondaryNameNode
7116 ResourceManager
17612 Jps
6750 DataNode
此时可以在浏览器访问YARN ResourceManager节点的8088端口,此处地址为http://192.168.170.133/,在YARN的WebUI中可以查看当前Flink应用程序(Flink YARN Session集群)的运行状态,如图

从图中可以看出,一个Flink YARN Session集群实际上就是一个长时间在YARN中运行的应用程序(Application),后面的Flink作业也会提交到该应用程序中。
提交Flink作业
接下来向Flink YARN Session集群提交Flink自带的单词计数程序。首先在HDFS中准备/input/word.txt文件,内容如下:
hello hadoop
hello java
hello scala
java
然后在Flink客户端(centos01节点)中执行以下命令,提交单词计数程序到Flink YARN Session集群:
$ bin/flink run ./examples/batch/WordCount.jar
-input hdfs://centos01/input/word.txt
-output hdfs://centos01/result.txt
上述命令通过参数-input指定输入数据目录,-output指定输出数据目录。
在执行过程中,查看Flink YARN Session集群的WebUI,如图:

当作业执行完毕后,查看HDFS/result.txt文件中的结果,如图:

分离模式
如果希望将启动的Flink YARN Session集群在后台独立运行,与Flink客户端进程脱离关系,可以在启动时添加-d或--detached参数,表示以分离模式运行作业,即Flink客户端在启动Flink YARN Session集群后,就不再属于YARN集群的一部分。例如以下代码:
$ bin/yarn-session.sh -jm 1024 -tm 2048 -d
进程绑定
与分离模式相反,当使用分离模式启动Flink YARN Session集群后,如果需要再次将Flink客户端与Flink YARN Session集群绑定,则使用-id或--applicationId参数指定Flink YARN Session集群在YARN中对应的applicationId即可,命令格式如下:
$ bin/yarn-session.sh –id [applicationId]
例如,将Flink客户端(执行绑定命令的本地客户端)与applicationId为application_ 1593999118637_0009的Flink YARN Session集群绑定,命令如下:
$ bin/yarn-session.sh -id application_1593999118637_0009
执行上述命令后,在Flink客户端会产生一个名为FlinkYarnSessionCli的客户端进程。此时就可以在Flink客户端对Flink YARN Session集群进行操作,包括执行停止命令等。例如执行Ctrl+C命令或输入stop命令即可停止Flink YARN Session集群。
Flink Single Job模式操作
Flink Single Job模式可以将单个作业直接提交到YARN中,每次提交的Flink作业都是一个独立的YARN应用程序,应用程序运行完毕后释放资源,这种模式适合批处理应用。
例如,在Flink客户端(centos01节点)中执行以下命令,以Flink Single Job模式提交单词计数程序到YARN集群:
$ bin/flink run -m yarn-cluster examples/batch/WordCount.jar
-input hdfs://centos01/input/word.txt
-output hdfs://centos01/result.txt
上述命令通过参数-m指定使用YARN集群(即以Flink Single Job模式提交),-input指定输入数据目录,-output指定输出数据目录。提交完毕后,可以在浏览器访问YARN ResourceManager节点的8088端口,此处地址为http://192.168.170.133/,在YARN的WebUI中可以查看当前Flink应用程序的运行状态,如图:

Flink HA 模式部署(基于Standalone)
很容易发现,JobManager存在单点故障(SPOF:S_ingle Point Of Failure_),因此对Flink做HA,主要是对JobManager做HA,根据Flink集群的部署模式不同,分为Standalone、OnYarn,本文主要涉及Standalone模式。

JobManager的HA,是通过Zookeeper实现的,因此需要先搭建好Zookeeper集群,同时HA的信息,还要存储在HDFS中,因此也需要Hadoop集群,最后修改Flink中的配置文件。
conf/flink-conf.yaml修改
必选项
high-availability: zookeeper
high-availability.zookeeper.quorum: DEV-SH-MAP-01:2181,DEV-SH-MAP-02:2181,DEV-SH-MAP-03:2181 high-availability.zookeeper.storageDir: hdfs:///flink/ha
可选项
high-availability.zookeeper.path.root: /flink
high-availability.zookeeper.path.cluster-id: /map_flink
修改完后,使用scp命令将flink-conf.yaml文件同步到其他节点
conf/masters修改
设置要启用JobManager的节点及端口:
dev-sh-map-01:8081 dev-sh-map-02:8081
修改完后,使用scp命令将masters文件同步到其他节点。
conf/zoo.cfg修改
# ZooKeeper quorum peers
server.1=DEV-SH-MAP-01:2888:3888 server.2=DEV-SH-MAP-02:2888:3888 server.3=DEV-SH-MAP-03:2888:3888
修改完后,使用scp命令将masters文件同步到其他节点。
启动HDFS
[root@DEV-SH-MAP-01 conf]# start-dfs.sh
Starting namenodes on [DEV-SH-MAP-01]
DEV-SH-MAP-01: starting namenode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-namenode-DEV-SH-MAP-01.out
DEV-SH-MAP-02: starting datanode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-datanode-DEV-SH-MAP-02.out
DEV-SH-MAP-03: starting datanode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-datanode-DEV-SH-MAP-03.out
DEV-SH-MAP-01: starting datanode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-datanode-DEV-SH-MAP-01.out
Starting secondary namenodes [0.0.0.0]
0.0.0.0: starting secondarynamenode, logging to /usr/hadoop-2.7.3/logs/hadoop-root-secondarynamenode-DEV-SH-MAP-01.out
启动Zookeeper集群
[root@DEV-SH-MAP-01 conf]# start-zookeeper-quorum.sh
Starting zookeeper daemon on host DEV-SH-MAP-01.
Starting zookeeper daemon on host DEV-SH-MAP-02.
Starting zookeeper daemon on host DEV-SH-MAP-03.
【注】这里使用的命令start-zookeeper-quorum.sh是FLINK_HOME/bin中的脚本
启动Flink集群
[root@DEV-SH-MAP-01 conf]# start-cluster.sh
Starting HA cluster with 2 masters.
Starting jobmanager daemon on host DEV-SH-MAP-01.
Starting jobmanager daemon on host DEV-SH-MAP-02.
Starting taskmanager daemon on host DEV-SH-MAP-01.
Starting taskmanager daemon on host DEV-SH-MAP-02.
Starting taskmanager daemon on host DEV-SH-MAP-03.
可以看到,启动了两个JobManager,一个Leader,一个Standby。
测试HA
访问Leader的WebUI:
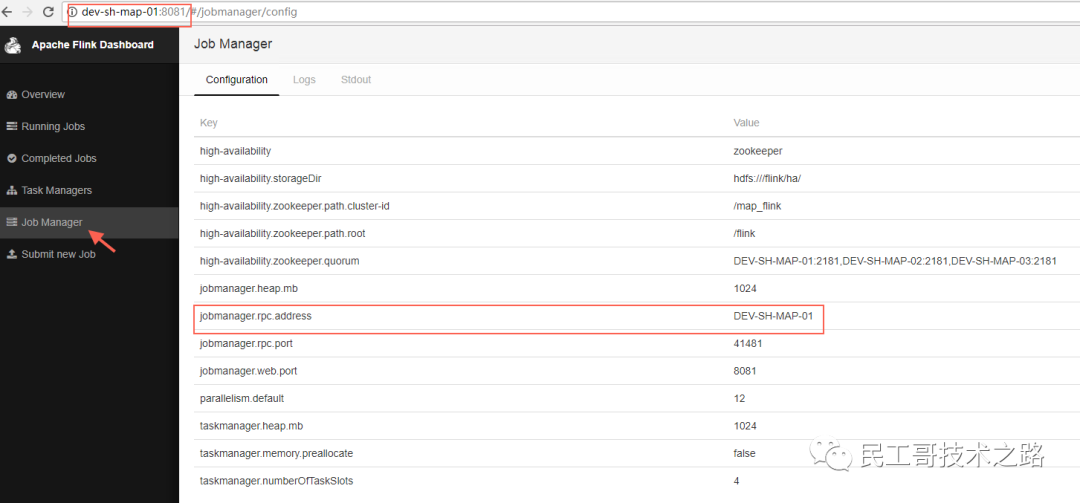
访问StandBy的WebUI
这时也会跳转到Leader的WebUI

Kill掉Leader
[root@DEV-SH-MAP-01 flink-1.3.2]# jps
14240 Jps
34929 TaskManager
33106 DataNode
33314 SecondaryNameNode
34562 JobManager
33900 FlinkZooKeeperQuorumPeer
32991 NameNode
[root@DEV-SH-MAP-01 flink-1.3.2]# kill -9 34562
[root@DEV-SH-MAP-01 flink-1.3.2]# jps
34929 TaskManager
33106 DataNode
33314 SecondaryNameNode
14275 Jps
33900 FlinkZooKeeperQuorumPeer
32991 NameNode
再次访问Flink WebUI,发现Leader已经发生切换。
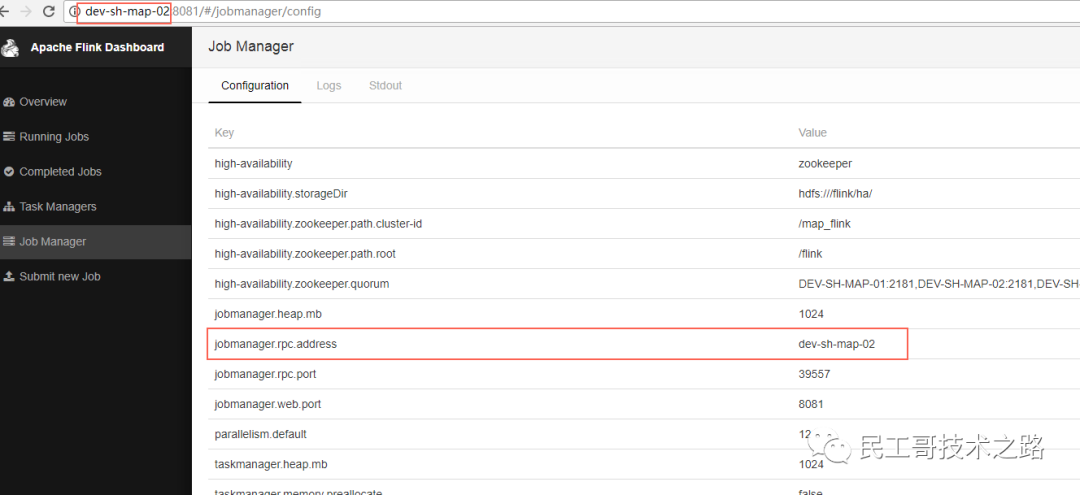
重启被Kill掉的JobManager
[root@DEV-SH-MAP-01 bin]# jobmanager.sh start cluster DEV-SH-MAP-01
Starting jobmanager daemon on host DEV-SH-MAP-01.
[root@DEV-SH-MAP-01 bin]# jps
34929 TaskManager
33106 DataNode
33314 SecondaryNameNode
15506 JobManager
15559 Jps
33900 FlinkZooKeeperQuorumPeer
32991 NameNode
再次查看WebUI,发现虽然以前被Kill掉的Leader起来了,但是现在仍是StandBy,现有的Leader不会发生切换,也就是Flink下面的示意图:

存在的问题:JobManager发生切换时,TaskManager也会跟着发生重启。
参考链接:https://www.jianshu.com/p/b071eb4f768b https://www.cnblogs.com/liugh/p/7482571.html