推荐书籍阅读顺序
推荐阅读顺序:
首先阅读关于二进制的内容:需要多做一些练习题:首推《程序是怎样跑起来的》
再然后了解计算机组成:里面的一些关键硬件,首推《普林斯顿计算机公开课》,里面讲解的计算机通识不仅全面而且也有深度 也容易理解(也可以看程序是怎样跑起来的),看完前面讲解硬件的内容之后 可以再去看《计算机是怎样跑起来的》
计算机网络 首推:《计算机是怎样跑起来的》这里面讲解的计网的基础很好理解,看完之后再去看《普林斯顿》里面的术语很专业,需要一些基础。
剩下的编程语言和计算机网络里面有趣的东西也可以去《普林斯顿》这本书,里面讲的很多计算机历史上的一些有趣的东西 很适合没有基础的人去看下 可以扩展不少见识。
什么是磁盘?

磁盘是由什么组成的?磁盘是如何进行存储数据的?
磁盘磁盘就是一个盘,这个盘由 带有磁性的物质组成。
磁盘 通过在转动的磁盘上改变对应区域 磁性物质的方向来进行存储数据。
数据存储在密集的轨道上,传感器通过逐条读取来访问。当计算机运行时你听到的嗡嗡作响和咔哒声就是这样产生的——传感器在转动的磁盘表面滑动。
磁盘存储信息首先*需要磁针转动到对应信息存在的磁盘轨道(也叫做磁道) 上,然后磁盘开始转动 找到这个轨道上 信息具体所在的扇区(概念下面会解释) *进行修改。
磁道,扇区,簇的概念
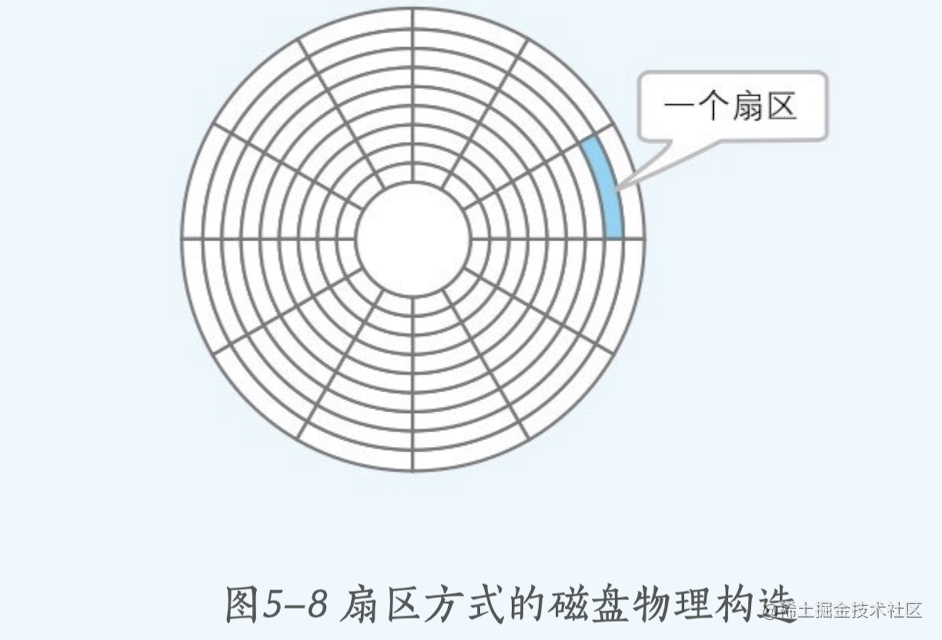
- 磁道:硬盘是一个大的磁盘,把磁盘按照同心圆的不同半径 分为多个不同的同心圆(同心圆也就是 磁道)
- 扇区:每个磁道里面会把圆分为固定区域,每个区域叫做一个扇区,每个扇区固定大小为512个字节。
- 簇:Windows在逻辑方面(软件方面)对磁盘进行读写的单位是扇区整数倍簇:根据磁盘容量的不同,1簇可以是512字节(1簇=1扇区)、1KB(1簇=2扇区); 容量越大磁盘的簇越多,但是对于软盘来说 1簇固定等于一个扇区大小等于512个字节
关于簇的使用有限制:不同文件必须用的是不同簇(硬盘简单粗暴不需要判断是哪个文件只需划分好即可,空间换时间),因此不管多大多小的文件最起码都要占用一簇的空间(一簇也就是整数倍的扇区空间),在软盘上即使存储一个字节在软盘和硬盘存储的时候也要占用一个扇区(512个字节),这虽然是浪费,但也是权衡。
在硬盘中簇的大小 设定 太大和太小会有哪些影响?
在软盘中一簇固定为512字节,所以不考虑软盘只考虑硬盘。
硬盘中簇的东西可以随意设定(可能是一个扇区也可能是多个扇区)
簇的值设定太小的话 虽然对于小文件存储很友好(因为存储文件最少为一个簇,所以小文件占用空间最少,可以增加存储容量)但是对于大文件传输来说 会增加 磁盘的读写次数(原来 一个簇是5kb,读写10kb文件需要两次,但是一个簇是1kb就需要读写10次了)
因此,不管是多么小的文件,都会占用1簇的空间。这样一来,所有的文件都会占用1簇的整数倍的磁盘空间。
簇的值设定太大的话,虽然对于大文件存储很友好(读写次数变少了),但是对于 小文件存储来说 即使只有一个字节也会占很大的硬盘空间(因为最少也要占一个簇,簇如果很大造成的空间浪费会更严重)
磁盘的逻辑结构:文件系统
为什么需要文件系统?
磁盘里面存储的数据是没有任何逻辑结构的,如果用户还需要去这个大盘子里面找自己需要的数据(猜测存储的时候需要记下自己在哪个磁轨扇区存储的,下次再去对应的地方读取),那么肯定会遭唾弃的。
因此 需要把磁盘按照不同区域磁轨扇区进行 有序 有结构层次 的组合,这个整合的工作就是操作系统里面的文件系统帮我们做的。
存储盘(C盘,D盘)就是一个很好的例子。当运行一个类似于Windows上的Explorer或Mac OS X的Finder之类的程序时,存储空间会以文件夹和文件的形式分层展示。
为了方便理解,假设文件和文件夹在磁盘内部是顺序进行存储的
那么第一个磁轨到第三个磁轨是C盘,第四个磁轨到第五个磁轨是D盘;其中C盘里面的第一个磁轨第五个扇区到第二个磁轨的第二个扇区存储的是C盘这个文件夹里面的用户文件夹,再往里第五个到第六个扇区是用户文件夹里面的用户密码信息,第六个到第七个扇区是用户账户信息)成 文件夹和文件,这个过程就是操作系统里面非常重要的文件系统 帮我们做的。
文件系统是如何进行抽象的?
文件系统是对磁盘的抽象逻辑结构
文件是随意可以编辑的,无法在磁盘上分配一段固定大小的空间进行存储,所以文件的内容在磁盘上存储的时候不是顺序存储而是 分散在不同的扇区里面。
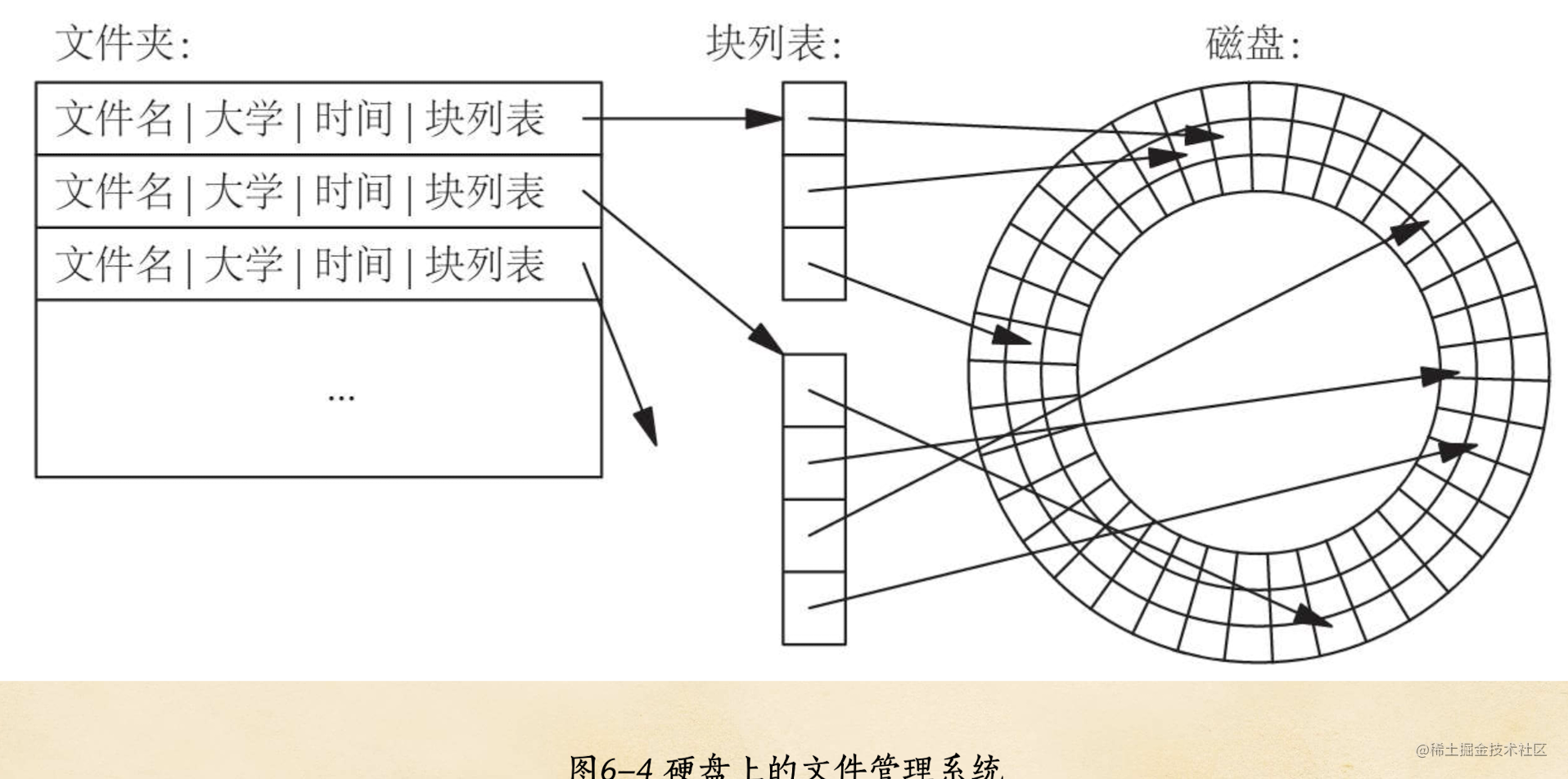
因此需要一个块列表来管理这些文件里面的不同内容分别对应在不同的哪个磁盘位置(扇区)里面,如下图所示:
比如a文件的块列表就会记录 第一个到第十个字符的磁盘位置是在a,c,d扇区中保存的,第十一个字符到第二个字符又是在另外一个扇区中
每个文件夹都会记录 保存在里面的 文件名称,文件最后修改时间,文件对应的块列表
通过上面的描述也可以看到文件夹也是一个文件,只不过快列表里面记录的不是文件里面 内容的磁盘位置,而是这些文件的快列表(嵌套)
如何操作文件?
#include <stdio.h>
void main() {
//打开文件
FILE *fp =fopen("MyFile.txt", "w");
//写入文件
fputs("你好", fp);
//关闭文件
fclose(fp);
}作为硬件的磁盘媒介,就如同树木的年轮一样,被划分为了多个扇区,并以扇区为单位对磁盘进行读写。如果直接对硬件进行操作的话,那就变成了通过向磁盘用的I/O指定扇区位置来对数据进行读写了。
操作系统把磁盘的扇区管理抽象成了 文件管理,需要对文件进行操作,就需要把文件从磁盘的扇区加载到内存里面,内存里面操作完成之后需要同步到磁盘的扇区职责。

下面解释为什么需要把文件加载到内存里面才能操作而不是在硬盘里面直接进行操作的原因。
什么是内存
为了更加透彻的方便理解什么是内存,之前写过一篇文章介绍 如何通过锁存器制作一个内存,在这里可以点击链接进行回顾:
juejin.cn/post/713784…
回顾一下一个重要的点:Ram为什么叫做随机存取存储器?
因为可以*快速的随机访问一个位置的信息(只需指定行号和列号) *;与之相对的是顺序访问(比如磁盘),不会像以前那种老式的录像带 如果想要到最后一集还需要从头快进到结尾
磁盘和内存的区别是什么?磁盘为什么不能替代内存?
从存取的实现原理看
从定义上来看,RAM是随机存储不管访问内存里面哪个位置的时间都相同;反观磁盘还需要通过转动磁盘和操作磁针 修改磁性物质 来说,速度会快很多。
引用书里面的一句话:
硬盘空间比RAM便宜大约100倍,然而它的读取速度也慢很多。硬盘读取每条轨迹大约要花10毫秒,数据的传输速度大约为100MB每秒。
可以看到硬盘有多”慢“,但是CPU的速度是很快的,所以即使CPU可以直接读出并运行磁盘中保存的程序,由于磁盘读取速度慢,程序的运行速度还是会降低。
所以如果cpu不操作内存而是直接操作硬盘的话 指令的读取执行就会慢很多,表现出来就是很卡。总之,存储在磁盘中的程序需要读入到内存后才能运行。
从作用上来看
从作用上来看:内存是通过电进行存储的,一断电信息就会丢失;但是磁盘不会,磁性物质会永久存储
替代磁盘的闪存出现:磨损均匀特性
越来越多的笔记本开始使用固态硬盘,也就是利用闪存(闪存的名字叫做flash)来代替转动的机械硬盘。
闪存也是非易失性的,信息保存为电路里的电荷,每一个电路元件上的电荷不需要加电就可以保持其状态。
闪存既可以通过读取电荷来访问信息,也可以擦去和重新写入新的值。闪存更快、更轻、更可靠,也不像传统硬盘那么容易摔坏。
闪存(SSD)设备的驱动程序和硬盘不同,且设备自身通过复杂的代码来记录设备中信息的具体存储位置。 这是因为闪存设备会__受限于每一部分的使用次数。
设备中的软件追踪每一个物理块的使用次数,并通过移动数据来保证每块的使用频率基本相同,这个过程叫做磨损均匀。
出于这个原因,闪存用于手机、照相机以及种种类似设备之中。现阶段闪存相比传统硬盘每字节的价格更贵,然而这个价格正在很快地下降,闪存很快将取代传统机械硬盘用于笔记本电脑中。
(这个需要下来查资料看下为什么,而且如果能够和内存一样做到随机读写一样的速度那么替代内存有何不可,具体和传统的磁针方式存储数据有什么区别)
什么是CPU
juejin.cn/post/713821…
CPU中的控制引脚
cpu如何区分传输的数据是内存发的还是IO发的:MERQ引脚 & IORQ引脚
下面是一些介绍cpu如何区分内存和io 输入输出数据的问题:
- 因为cpu的数据和地址总线引脚不仅会和内存链接也会和i9链接,所以cpu该如何区分数据 是 内存给的还是i9给的?
答案是cpu又设定了单独的引脚来设置读取的是内存还是io:
cpu上的ME RQ引脚会链接 内存的ce引脚,当设定是0代表是内存给的数据,设定是 1代表是iO给的数据;
cpu上的IORQ 引脚 会链接 IO控制器上的iorq引脚和ce引脚来共同作用:都为0代表用的是iO,都为1代表用的是内存
为什么IO需要两个引脚共同作用:因为计算机不仅仅只有一个io控制器,iorq和ce相当于是总开关和分开关的作用(iOrq代表用的是IO控制器的数据,ce代表用的是具体哪个IO控制器的数据)
传输的数据是 cpu给内存/IO的还是内存/IO 给cpu的:RQ&WR引脚
数据和地址总线 传输的数据是 cpu给内存/iO的还是内存/IO给cpu的?
这两种情况 对应cpu上的两个引脚RD和WR:
当RD打开时代表 cpu 告诉 内存/IO接受数据;
WR打开时代表cpu告诉内存/io要输出数据
所以 rd和wr就是用来做这个事情的
CPU的这两个线分别和内存的RD,WR引脚连接
但是对于iO来说一个引脚可以代表两个值,因此iO只有一个引脚和cpu的RD引脚链接(0代表接受,1代表输出)
IO地址空间里面 和 内存地址空间 的 区别?
内存中存放着程序,程序是指令和数据的集合
I/O中临时存放着用于与周边设备进行输入输出的数据
iO不需要内存那么多的地址引脚(因为内存需要存储大量的程序和数据)只需要能够标识 传输 哪个端口 哪种数据即可(iO的作用就很简单了,只需知道 传输的是哪个端口的数据即可
CPU中的寄存器
IO控制器是什么
为什么要出现IO控制器
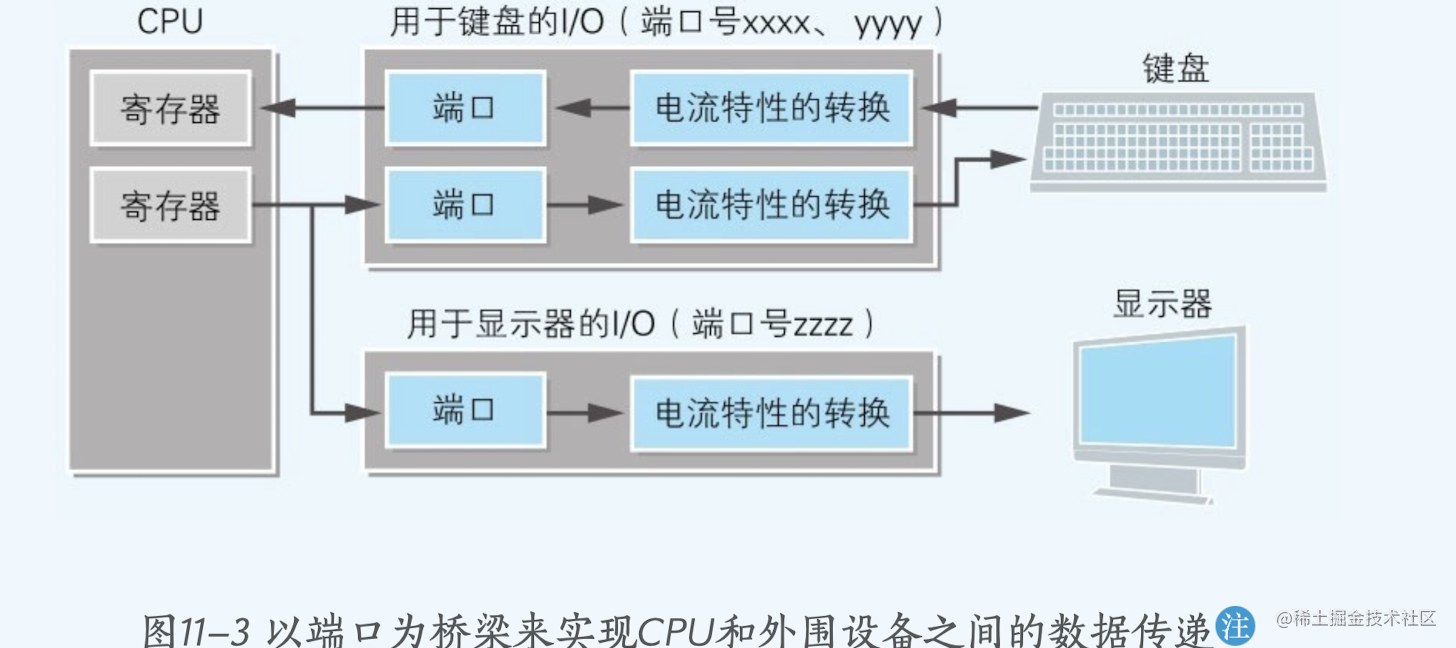
计算机主机里面内置了很多个同外部设备链接的连接器(比如用于和键盘交互的连接器,和鼠标,和显示器....)由于电压不同,数字信号及模拟信号的电流特性也不同,计算机主机和外围设备是无法直接连接的,所以为了解决这个问题,I/O控制器就很有必要了。
什么是端口:IO端口号
- *不同的外部设备有各自独立的IO控制器(因为不同外部设备的电压不同) *,比如用于键盘的IO和显示器的IO控制器不一样。
- 端口:IO内部提供了很多寄存器用来存储计算机和外设交换的数据,因此也叫作端口(计算机和外设之间的港口)。
- 一个IO可以提供一个端口也可以提供多个端口(比如下图键盘的iO就有两个端口,显示器就只有一个端口)
- CPU和IO传输数据的总线:io设备和主存一样,可以用来传输数据和指定端口地址。通过地址总线传输端口号来指定io设备选择哪个端口地址操作,数据通过数据总线进行传输到对应的端口上,控制总线控制读取还是写入。
端口内部的数据寄存器和状态寄存器
每个端口不仅有一个存储端口数据的寄存器还有一个存储端口状态(读取还是写入)的寄存器,也就是说两个端口就有四个寄存器。
通过CPU的地址总线来 切换使用IO里面的 不同端口的数据寄存器还是状态寄存器
这四个寄存器只能支持两个端口和外部设备交互,这四个寄存器在io里面的排布是四个地址空间,最开始的0号 地址空间指向第一个端口的数据寄存器,接下来是 其他端口的数据寄存器,最后再把各端口的状态寄存器往下排。
什么是驱动程序
为什么需要驱动程序
要想操作外部设备就需要知道 外部设备具体有哪些特性,这对操作系统来说很复杂 *(关心细节) ,因此不同设备都有自己不同的一套驱动程序 (关心抽象) *。
对操作系统 来说 驱动程序提供的 接口 屏蔽了 设备的特性,提供给操作系统的是一套标准化的接口。
比如打印机打印 a字符:
对具体硬件设备,驱动程序调用 具有特性的设备完成工作(比如对于黑白打印机的驱动来说操作系统调用打印 打出来的就是黑白字符;而对于彩色打印机 操作系统同样调用打印,打印出来的字符就是彩色的)
操作系统调用驱动提供出来的 标准化的接口,驱动程序内部 负责实现功能(具体的设备调用)
操作系统在出厂时已经内置了很多驱动程序,比如说网卡的驱动,键盘的驱动,鼠标的驱动。
所以 驱动程序是 操作系统和具体硬件设备 之间沟通的桥梁
即插即用的外设
驱动程序一般当新的设备连接到操作系统时,就会自动安装该设备的驱动程序,只有安装了对应设备的驱动程序才可以对这个设备进行操作。
如果之后再追加新的网卡(NIC)等硬件的话,就需要向操作系统追加该硬件专用的设备驱动。操作系统可以正常调用驱动程序,驱动程序可以调用外部设备)
也有的情况这种情况很常见,比如链接了一个ardunio的开发版就需要下载对应的驱动才能操作这块板子。
程序里面一般会内置dll文件,便于上层开发对这个设备的处理程序
操作系统内置驱动程序
- 启动过程中有一个环节就是把当前可用设备的驱动程序加载到运行的系统中(也就是加载到内存中)。可用的设备越多,加载要花的时间就越长。
- 新设备随时有可能出现。在把外部磁盘插入USB插槽后操作系统会检测到这个新设备,根据设备驱动程序接口的某个部分确认它是一个磁盘,然后加载USB磁盘驱动程序与这个磁盘通信。
一般来说,没有必要寻找新的驱动程序,因为所有设备的接口都是标准化的,操作系统本身已经包含了必要的代码,而驱动设备的特殊程序也已经包含在设备自身的处理器中。
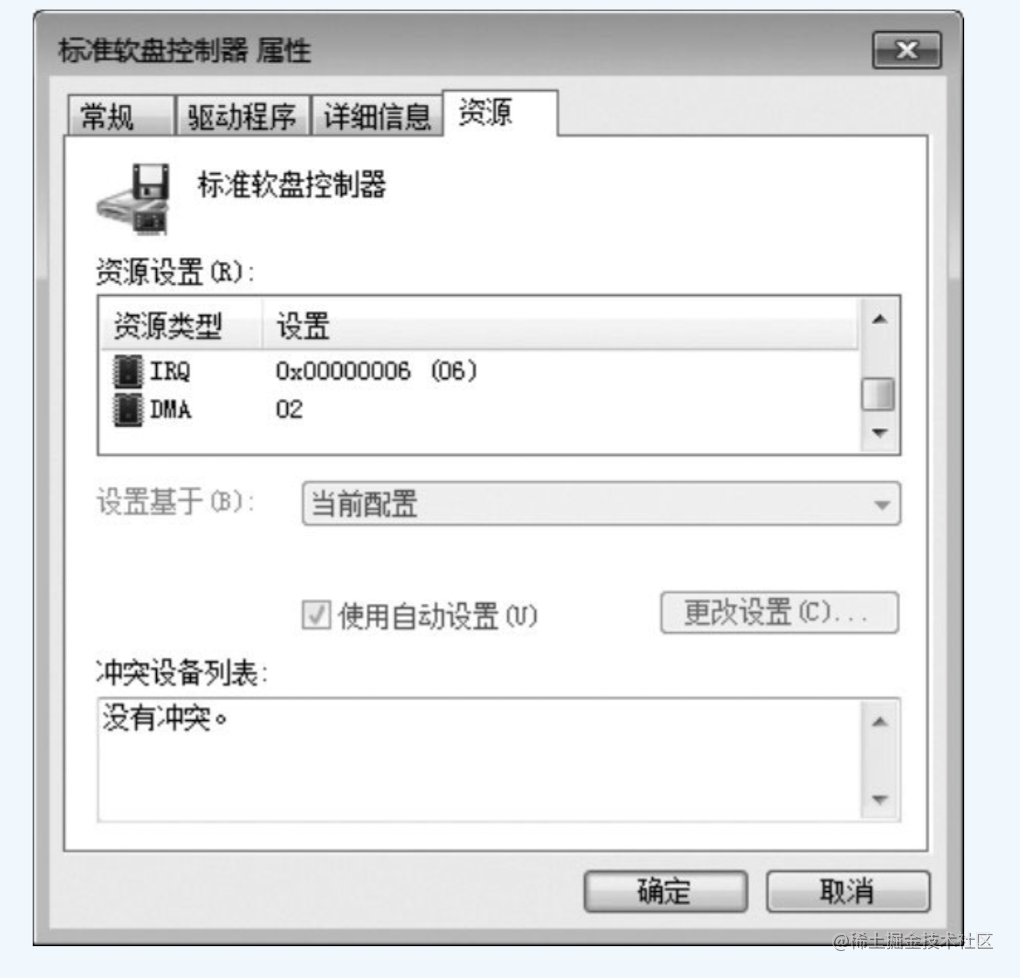
什么是中断:IRQ
在上图软盘控制器里面 “I/O范围”下面有一个“IRQ”项目,对应的值是0x00000006(06)。IRQ(Interrupt Request)是中断请求的意思。那么,IRQ主要是用来做什么的呢?
比如用户按下了键盘或者鼠标,CPU需要立即相应对应的操作,而不是等待运行的程序运行完再处理键盘发出的操作,这个时候就需要中断机制了。
IRQ是用来暂停当前正在运行的程序,并跳转到其他程序运行的必要机制。该机制称为中断处理。
中断处理在硬件控制中担当着重要角色。因为如果没有中断处理,就有可能出现处理无法顺畅进行的情况。
从中断处理开始到请求中断的程序(中断处理程序)运行结束之前,被中断的程序(主程序)的处理是停止的。
中断编号和中断处理程序
- *实施中断请求的是连接外围设备的I/O控制器,负责实施中断处理程序的是CPU。 *为了进行区分,外围设备的中断请求会使用不同于I/O端口的其他编号,该编号称为中断编号。
在控制面板中查看软盘驱动器的属性时,IRQ处显示的数值06,表示的就是用06号来识别软盘驱动器发出的中断请求。
- 操作系统及BIOS会提供响应中断编号的中断处理程序
- 假如同时有多个外围设备进行中断请求的话,中断控制器会把从多个外围设备发出的中断请求有序地传递给CPU
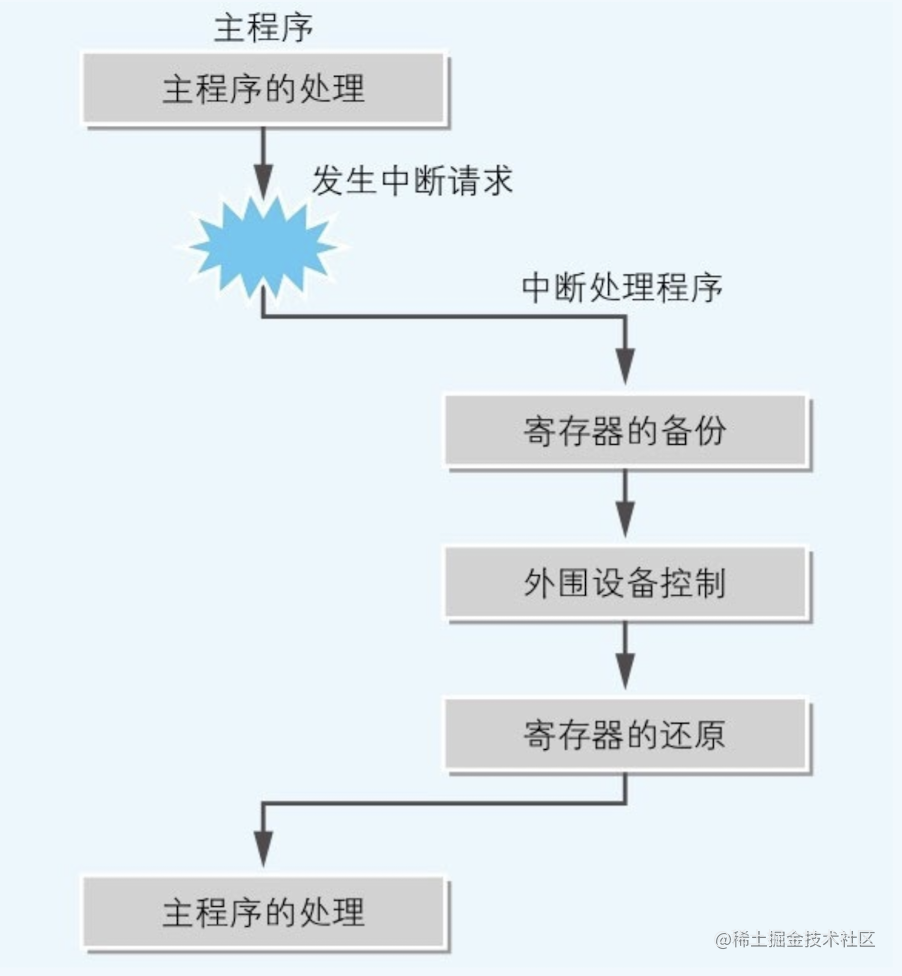
整体处理流程
整个中断触发到响应到恢复的流程是:
- CPU接收到来自中断控制器的中断请求后,会把当前正在运行的主程序中断,并切换到中断处理程序。
- 中断处理程序的第一步处理,就是把CPU所有寄存器的数值保存到内存的栈中。
- 在中断处理程序中完成外围设备的输入输出后,把栈中保存的数值还原到CPU寄存器中。
- 然后再继续进行对主程序的处理。

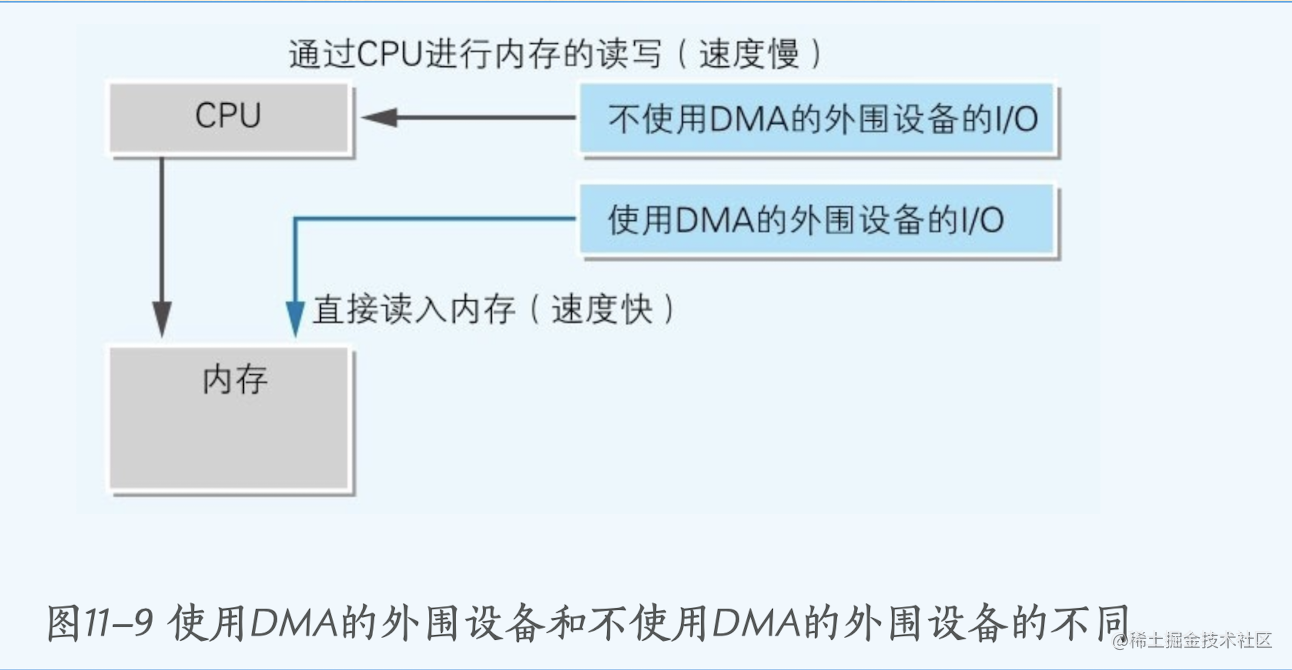
什么是DMA
为什么会出现DMA
内存的总线引脚会与cpu和硬盘/外设的总线引脚在一条线上一起链接。因为cpu的速度和 硬盘/外设与 内存通信的速度 不是一个量级,cpu可以在这通信的过程中做很多事但却需要等待通信结束和内存交互,因此为了节省cpu的资源出现了DMA
DMA是指在不通过CPU的情况下,外围设备直接和主内存进行数据传送,也叫直接存储访问
磁盘等都用到了这个DMA机制。通过利用DMA,大量数据就可以在短时间内转送到主内存。之所以这么快速,是因为CPU作为中介的时间被节省了
CPU借助DMA通道,来识别是哪一个外围设备使用了DMA
如何打开/关闭 DMA:控制CPU引脚busrq,busak
BUSRQ:控制CPU从电路中隔离
先解释busrq开关:如果这个开关关闭的话,CPU就会从电路中隔离,这样CPU和内存就不会有通信了
之前内存上的引脚只和cpu进行了链接 因此和内存访问需要通过cpu才能进行通信。
但是现在 内存引脚添加了硬盘设备的引脚,再通过busrq把cpu的引脚全部隔离(通过升高电阻)了之后,这样内存就不会和CPU进行通信了
BUSAK:控制外设可以直接和内存通信
在解释busak,把busrq关了之后只代表cpu不会和内存通信了,但是也需要同样让硬盘可以和内存进行通信,busak就是做这个事情的
这个busak开关和硬盘的引脚进行链接,这个引脚可以控制硬盘是否能和内存通信:
硬盘上有一个g1,g2引脚 他们和cpu的busak引脚链接,如果这个ak是关的 那么硬盘也会从电路中隔离 (通过升高电阻),如果是开的,电流就会通过这样硬盘就可以和内存通信了。
可以在如何做一个计算机里面找到这个G1,G1引脚还有和CPU连接的busak引脚
总结
也就是说busrq控制的是cpu自己的引脚是否能发送出数据,busak是控制硬盘是否能发送出数据
这两个必须一起设置,当设置busrq让cpu从电路中隔离,设置busak让硬盘接入电路,这样硬盘的数据就可以直接传入到内存中,这种直接存储访问叫做dma,不经过cou直接访问内存
IO控制器总结:I/O端口号、IRQ、DMA通道
I/O端口号、IRQ、DMA通道可以说是识别外围设备的3点组合
不过,IRQ和DMA通道并不是所有的外围设备都必须具备的。
- 计算机主机通过软件控制硬件时所需要的信息的最低限,是外围设备的I/O端口号。
- IRQ只对需要中断处理的外围设备来说是必需的
- DMA通道则只对需要DMA机制的外围设备来说是必需的。
假如多个外围设备都设定成同样的端口号、IRQ及DMA通道的话,计算机就无法正常工作了。这种情况下,就会出现“设备冲突”的提示。
总结:如何做一个计算机?
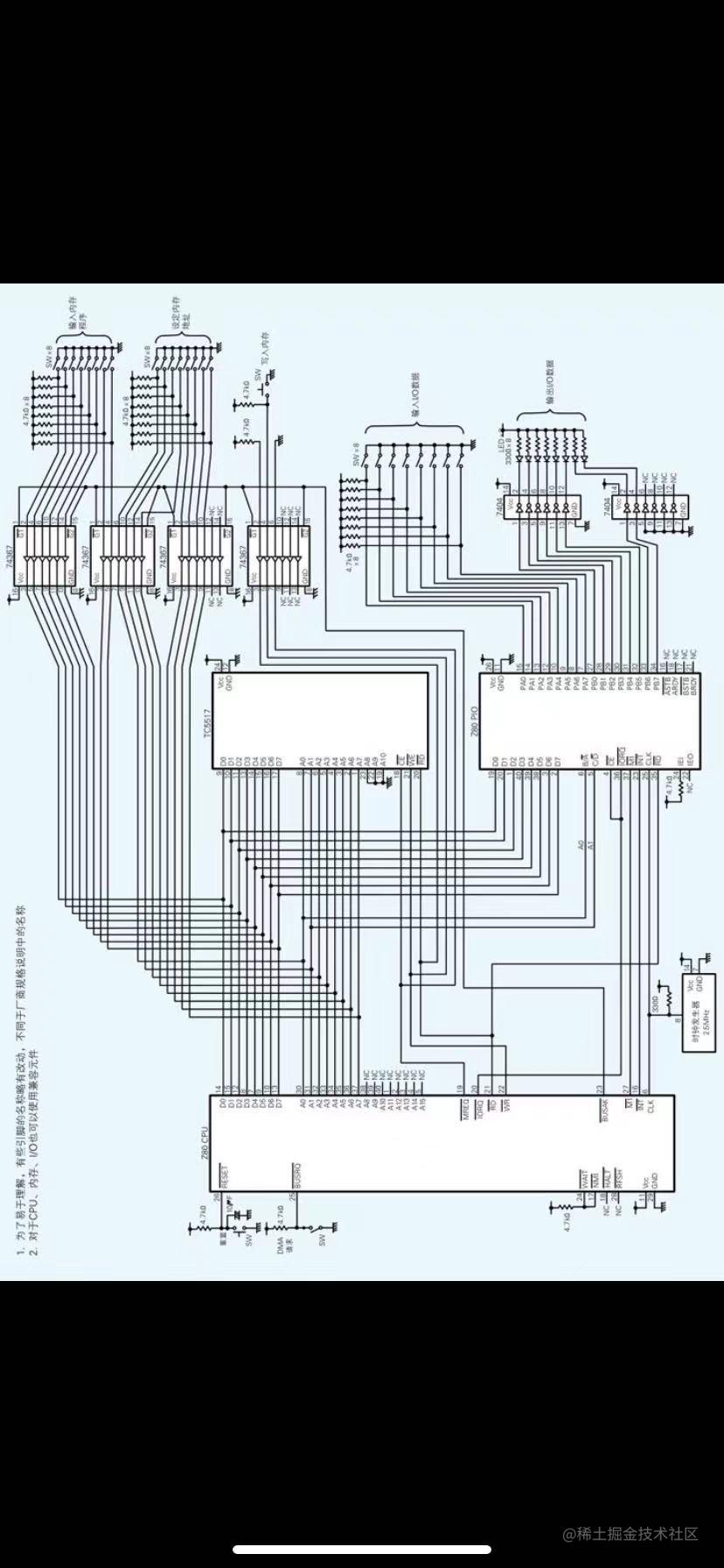

上面讲的一系列的都是为了做这个程序用的
通过DMA吧程序直接输入到内存当中
- 首先 需要把程序输入到硬盘中,然后把程序载入到内存中,对应这个例子来说 不需要这么高级的功能,我们手动输入程序 让他直接从硬盘输入到内存当中即可:
打开DMA 开关(关闭cpu的busrq和busak引脚,这两个必须一起设置,当设置busrq让cpu从电路中隔离,设置busak让硬盘接入电路,这样硬盘的数据就可以直接传入到内存中)
- 接着打开硬盘上的写入内存的引脚让内存可以接受硬盘总线传递的数据,然后拨动硬盘上的地址/数据总线 的引脚开关 分别输入程序的地址和程序的指令,接下来关闭硬盘写入内存的通道,这时代表程序已经写入到内存中
cpu reset:CPU的PC寄存器指向内存开头,跟随时钟信号运行程序
- cpu拨动reset引脚,这样程序就可以运行了,
程序指令内容是接受iO设备a端口的输入并反馈给io设备b端口的led灯
IO和CPU进行通信:CPU接受IO A端口的外设 设备数据,cpu输出数据给B端口的设备
- IO 和cpu通信:io设备的 a端口是一个开关,用于接受8bit的数据,当收到消息时,iO的中断引脚会给cpu 发送一个中断信号;接着cpu会打开iorq(io request)和ce(有多个io设备因此ce是分开关代表具体哪个io)引脚代表cpu现在和io设备通信而不是和内存
- 通过cpu的a0,a1地址总线引脚设置cpu用iO里面哪个端口的哪个寄存器
对应只有两个端口的i9来说 内部00号地址是a端口数据,01是b端口数据,10是a端口状态,11是b端口状态。
- 再根据是接受端口输入数据还是给端口输出数据 决定是否打开rd(读取)引脚开关;再然后就可以通过数据总线(d0-d7)传递数据了。
cpu通过地址总线传输的地址 控制IO设备使用哪个端口的寄存器
- 这样cpu就可以从a端口接受到对应的数据了,之后就是输出给io的另一个b端口(引脚的设置和a端口 差不多)b的端口链接的是led灯,因此a端口输入的数据就会体现在b端口led上
这段程序只实现了一个简单的功能,那就是通过拨动连接到Z80 PIO上的指拨开关控制LED的亮或灭。
虚拟内存的出现
实际上运行程序所需的内存要比 物理内存多很多,比如安卓上每个进程都有四个g的内存,更不用说后台的程序了,怎么解决?
通过 虚拟内存来解决,根据二八法则百分之八十的数据都是不需要的,也就是说在内存里的数据并不是都需要,因此对这些不需要的数据可以先放到磁盘里面,等到用的时候在把磁盘里面的东西王内存里面加载。
内存放入磁盘叫做 page out,磁盘加载到内存叫做page in 。
这个过程叫做SWAP,每次进行SWAP的 单位是page 页,在winodws上 1个page是4kb
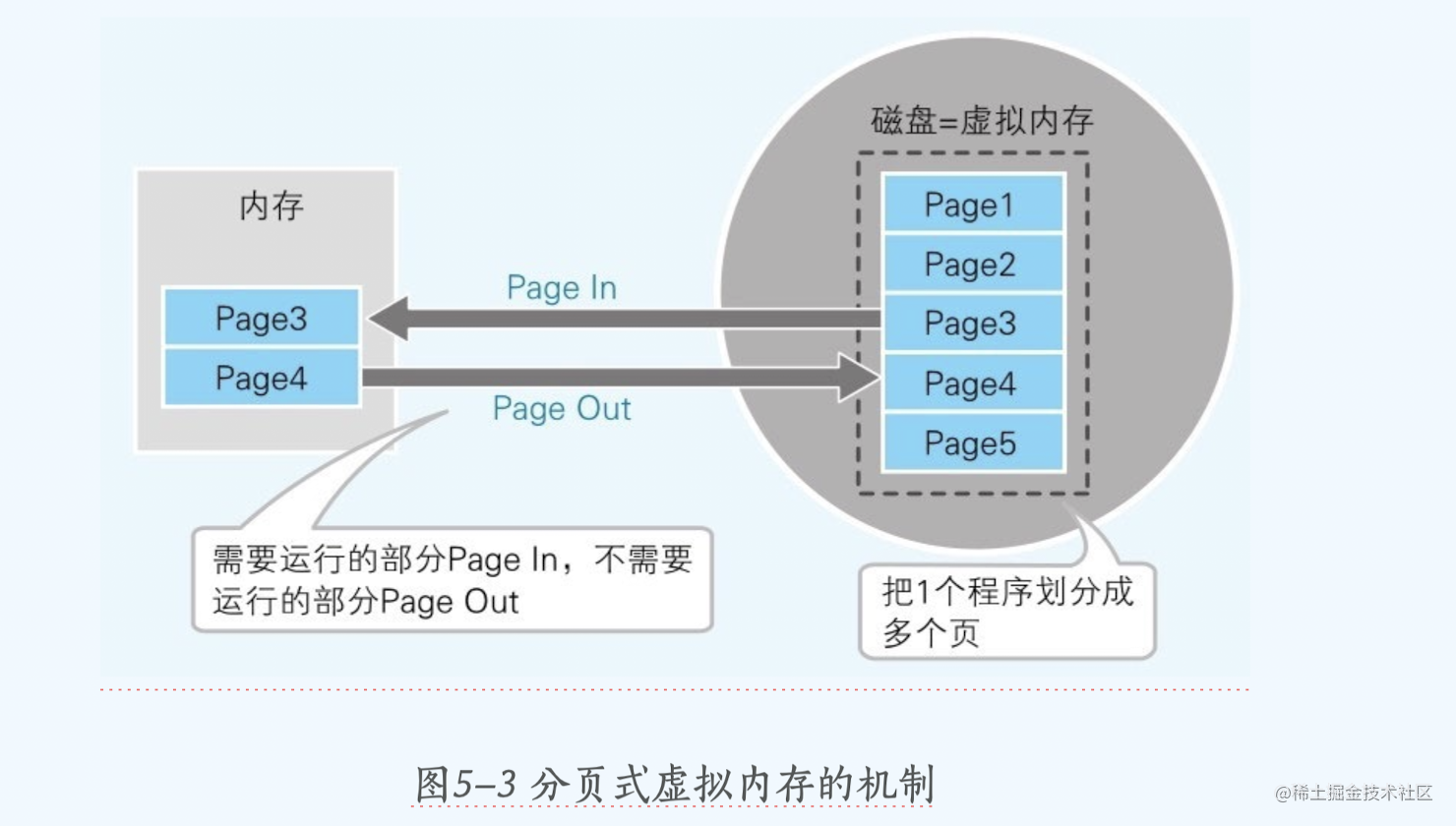
虚拟内存的局限性
上面说的虚拟内存 虽然可以缓解一些内存压力,但是如果内存很紧张,由于SWAP和磁盘的交互也会导致很卡顿,所以还是需要从减小内存占用量出发思考问题:
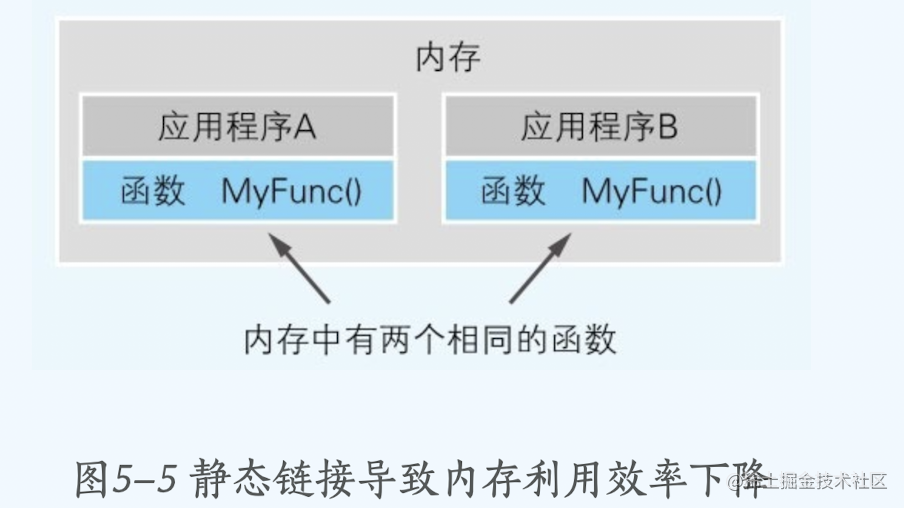
使用dll动态链接库
对于多个程序来说 可能用的程序库有很多一样的如果每个进程内存空间里都加载一份 就会导致内存不必要的浪费,相反用动态链接的话 共享库只会加载一次,只会占用一份内存空间,其他程序通过共享来减少程序的大小。
动态链接的概念会在下面讲解汇编的时候解释

在c语言的函数调用时加上 std_call
该标志代表标准调用方式,默认情况下c语言调用是用的普通的call指令。
首先简单 介绍下c语言里面的函数调用:在c语言里面传递函数参数的方式是通过 栈进行的,返回值是通过寄存器存储的。
栈 是占用的内存里面的 空间因此在函数调用后需要 把这块空间 清理掉(注意 栈清理掉并不会影响程序 异常因为返回值 是存储在寄存器里面,调用方不会因为返回值的内存被清理 产生异常) 。
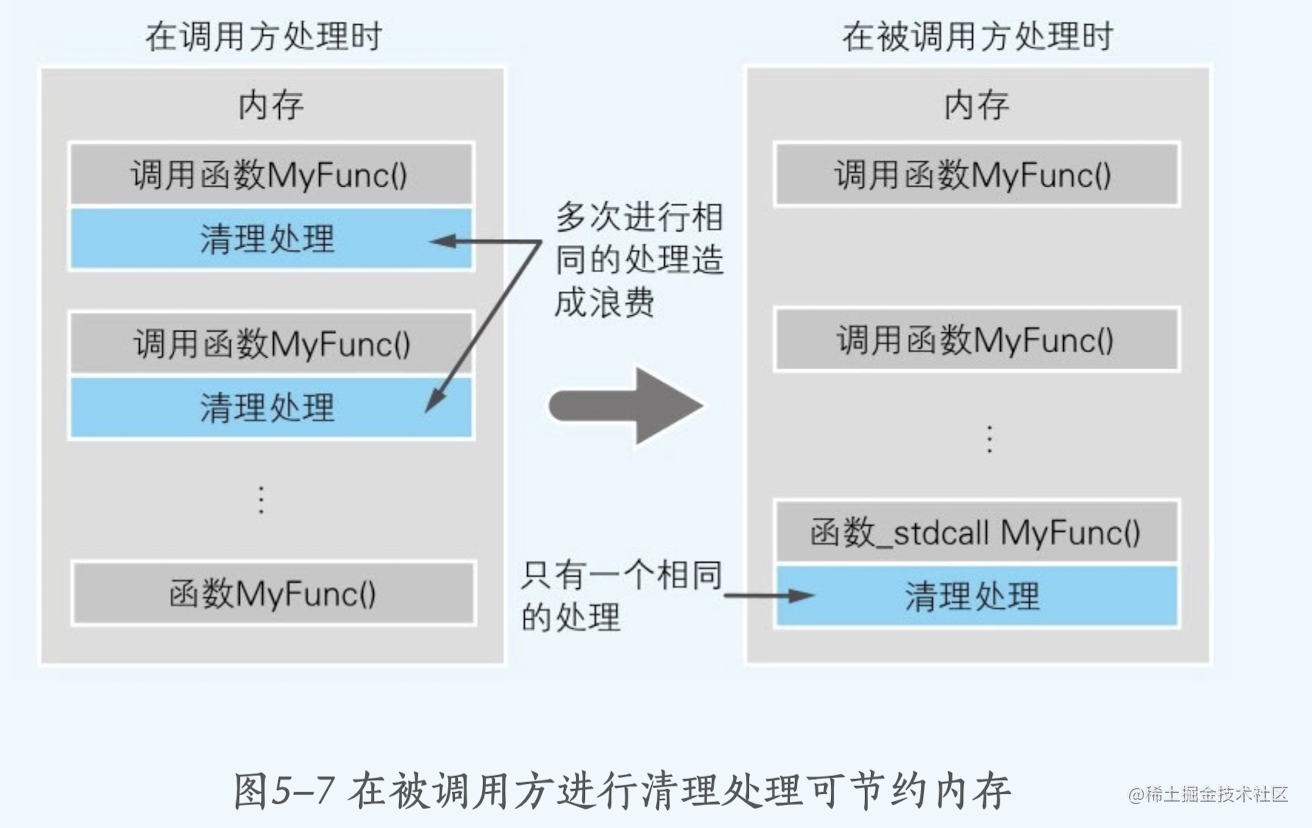
介绍下这两个调用方式有什么区别:对于内存清理工作来说 默认情况下 是在调用处 函数结束后 进行内存清理工作的(因为不知道调用函数需要传入多少参数 ,也就不知道该清理多少参数,所以只能在调用完函数之后在进行清理参数的工作),这种情况会有什么问题呢?
清理参数的代码 是编译器在编译期间 自动添加的,对于多个调用同一函数的 调用处 都会 进行添加清理代码,这也是一个代码空间对浪费。
但是如果对于 知道传输多少参数的情况下 (也就知道清理代码是固定的)就不需要了 ,清理代码就可以放在 调用函数的里面进行,这样多个调用处的清理代码 就可以只放在一处,大大减少程序 占用的内存空间。
清理处理,比起在函数调用方进行,在反复被调用的函数一方进行时,程序整体要小一些。这时所使用的就是_stdcall。在函数前加上_stdcall,就可以把栈清理处理变为在被调用函数一方进行
操作系统为何出现
当时 没有Windows操作系统出现的时候,软件还要针对不同硬件和不同的操作系统进行做定制。
这些机型虽然都搭载了486及Pentiunm等x86系列的CPU,不过内存和I/O地址的构成等都是不同的,因此每个机型都需要有专门的MS-DOS应用。x86提供有专门用来同外围设备进行输入输出的I/O地址空间(I/O地址分配)。至于各外围设备会分配到什么样的地址,则要由计算机的机型来定。
那时的操作系统并不完善 没有对硬件不同的规格差异做定制化的系统开发,内存和i9的地址空间和构成都是自家硬件管自家的,i9的地址端口分配也是随机的。
因此这部分工作落到了开发者手上,开发者可以直接操作硬件。
在window操所系统出现之后,Windows操作系统会进行兼容不同的硬件从而推出不同的操作系统版本(比如是x86的Windows操所系统还是其他不同硬件的操作系统) **在Windows操作系统上不用担心因为硬件的不同而做定制开发。 **因为Windows已经帮我们把适配的工作做好了。
互联网的发展就是再这样不断完善,不断封装的过程中进步的。
包括后面的java虚拟机则是屏蔽了不同操作系统的差异。不同的操作系统都有对应的java虚拟机,运行java程序时,java虚拟机读取字节码xlass文件转换咸亨对应对本地代码进行运行。
BIOS启动引导程序Bootloader
上电后bios(固定的BIOS扇区里面存储的程序)会检测硬件是否正常(内置了很多硬件的基本程序比如键盘,磁盘,显卡基本程序),还会检查内存和其他组件,以确保它们都可以正常工作。
启动过程还会为接入的设备加载软件组件,即驱动程序,以便操作系统能够使用这些设备
如果正常则会启动引导程序Bootloader(存储在rom磁盘上的引导扇区中) ,引导程序bootloader最大的作用就是启动os操作系统载入内存中运行。
上面的这些运行的程序都是在真实的物理内存地址上运行的,因为文件系统程序还没有启动不能用虚拟内存硬盘进行换页,因此也叫实模式(用的是实际的内存地址)
汇编文件的构成:data,bss,text段
汇编语言在编译后会重新排列数据和指令的顺序,通过segement段把程序分为三种段:分配了初始值的段(data),没有被分配初始值的段(bss),指令段(text)。
段的表示是通过 :段定义(三种类型的段) + segement + 对应段保存的内容 + ends四个部分进行表达的。
这样有顺序的划分保证了内存的连续性,可以对某个类型的数据进行统一操作和管理

通过,除了数据段和指令段还有 运行时动态分配的栈和堆得内存空间。
伪指令segment和ends围起来的部分,是给构成程序的命令和数据的集合体加上一个名字而得到的,称为段定义。
段定义的英文表达segment具有“区域”的意思。在程序中,段定义指的是命令和数据等程序的集合体的意思。一个程序由多个段定义构成。
如何找到对应符号的实际内存地址
基址寄存器存储的就是可执行文件中不同类型段的起始地址(比如上面汇编的数据段,指令段),
编译器按照不同类型对数据进行了重新排列,因此可以让同等类型的数据在内存里是连续排列的:
这样通过基址寄存器里面存储的段起始地址+偏移量就可以找到所在内存中的真实地址
等到运行的时候起始地址是动态分配的内存地址,如果想找数据就去数据段的起始地址+对应偏移量即可,指令段也如此。
data段内需包括哪些信息?
经过重新整理,data中存储的是已经赋值的全局变量信息(包含变量名称和变量所占用的内存空间和对应分配的初始化值)
段内每一行变量需要包含如下信息:
- 标签代表着对应的是哪个变量(编译后的变量和函数前面会带有_)
第一个变量相对段起始地址 的偏移量是0,也就是说a1的偏移量是0;a1的变量名称已经在data中表示了,所占用的字节数是通过
- **所占用的字节数通过dd来描述,一个d代表两个字节,两个d就代表占用四个字节的内存空间。 **两个d是int类型,不同类型不同数量的d,比如三个d
- 对应分配的初始化值在占用字节数dd后面添加
比如
如果是a1变量(int类型)初始值1 在程序的全局变量开头那么在data中存储的数据就是_a1 dd 1
如果接下来全局变量a2(int类型)存储的是2那么就是 _a2 dd 2
bss段内需包括哪些信息?
bss中定义的是未分配初始化值的变量,因此只需要存储变量标签和对应所需的内存空间即可。
bss段里面每一行变量都需包含如下信息:
- 变量标签(和data一样,表示的是变量名)编译后的变量
- db + 占用的字节数+(dup ?) :其中db的含义是define byte表示一个字节的内存空间,后面的数字代表具体占用多少字节;dup?代表值没有确定。
比如:
b1这个int类型的变量是程序里面 没有设置初始值的第一个变量,那么开头第一行信息就是_b1 db 4 dup?
接下来如果是b2这个double这个类型的变量是 程序里面 没有设置初始值的第二个变量,那么第二行信息就是 _b2 db 8 dup?
通过对bss分段单独存储在一个segement中可以很方便的对 这些没有分配初始化值的变量 进行默认分配0。
局部变量如何保存?
局部变量的内存空间是定义在栈里面的,和全局变量不同的是 并没有单独的data和bss段存储,而是在栈里面通过寄存器和栈里面的内存空间存储的。
在程序开始的时候就可以知道该函数需要多少个局部变量减去可以使用的寄存器数量后,剩下的变量就要在栈里面的内存空间存储,因此会在开头先申请局部变量所需的内存空间(栈顶多申请一些内存空间用于存放局部变量)
什么是链接
为什么需要链接?
- 链接目标文件:在编写程序的时候不可能所有函数都会写,所以需要链接器帮我们把代码进行模块化的拆分,必需的目标文件(目标文件指的是编译c程序后的obj后缀的文件)就有启动目标文件用于程序里面的main,函数;
- 链接库文件:但是如果所有文件都通过指定目标文件的方式去做那么指令会非常长(几百个目标文件的情况) ,所以出现了库文件,链接器指定了库文件之后,就会从里面把需要的目标文件 抽取出来和其他目标文件生成exe文件。
像import32.lib及cw32.lib这样的文件称为库文件。库文件指的是把多个目标文件集成保存到一个文件中的形式。链接器指定库文件后,就会从中把需要的目标文件抽取出来,并同其他目标文件结合生成EXE文件
因此 多个目标文件连接到一起生成一个程序的过程叫做链接,链接的指令 里面 需要指定多个目标文件,和库文件最终生成一个可运行的目标程序。
没有链接对应的 目标/库文件 会发生什么
如果程序里面用到了外部变量和函数但是链接的时候没有指定出来所属的目标文件,就会报错:无法解析的外部符号。外部符号指的是外部文件的变量和函数信息
动态链接库和静态链接库的 关系
什么是静态链接库
静态链接库中会存储着 包含外部符号的 目标文件的实体也就是obj文件,在用链接指令 的时候会把 目标文件里的符号表进行解析和替换(链接符号表) 并把需要的文件打到最终的产物里面。
符号表指定了符号和所对应的逻辑地址,这样调用外部符号的时候就知道用哪个地址了。
静态链接库的缺点
由于会存储目标文件,所以缺点就是 对于公用的符号(也就是变量和函数) 比如打印的函数 来说 每个应用程序都会保存一份这个函数的目标文件 每个程序运行的时候都会加载一份到内存里 浪费空间。
动态链接库是什么
而动态链接库里面不会存储 包含外部符号的目标文件的实体,只会存储这个库里面有哪些外部符号和这些外部符号存在的目标文件位置 。
在运行时需要的时候会找到这个位置的目标文件并加载到内存中;如果其他程序也需要 就可以直接用这个加载好的而不用像静态链接库一样把本地的 库目标文件再次加载到内存里面。
会对 公共的库文件内存地址进行映射到自己进城的内存地址里面
在运行中是通过PLT表和GOT表(会存储对应符号的内存地址) 结合起来调用符号的实际内存地址。
如何进行选择哪种链接库
对于只有一个应用用的库文件来说可以设置为静态链接库;但是对于多个程序都用的库文件来说 就需要设置成动态链接库了,因为不可能每个程序都放重复的外部符号 浪费空间
程序如何找到实际的内存地址:headertable再配置信息&不同段记录的偏移
目标文件里面的 变量和函数在运行时内存地址是不固定的,那么如何保证调用变量和调用函数是正确的内存地址呢?
cpu指令调用的时候操作的是真实的内存地址,如何知道真实的内存地址?
由于汇编文件的 数据段和函数段是分别存储在一个连续的线性列表里面的,因此变量和函数具体的内存地址在加载到内存里面之后 是可以通过 各自段的起始地址加上相对各自表的偏移量算出来的
比如a变量相对变量表起始地址十个字节的偏移量,占据五个字节,a变量后面的变量偏移量就是15个字节,函数也是如此也有对应的函数表
那么在哪里记录每个段的起始地址呢?
段的起始地址是运行时候动态分配的 ,目标文件会在开头添加 再配置信息,再配置信息里面会表述 如何将虚拟地址转换为真实的内存地址(再配置信息里面会存储各个不同段和对应段的起始虚拟地址和真实地址的映射关系);再配置信息之后就是 不同类型段的数据了(也就是数据段和函数段)
总结就是分类存储,只动态分配每个类型的起始地址就好,之后同类型的数据都是线性排列在开头之后所以根据偏移量就可以找到具体的内存地址了