《计算机系统(2)》学习笔记
叶茂林 2023.6.24-2023.6.30
计算机系统漫游
Amdahl定理
对系统某部分的加速时,其对系统整体性能的影响程度取决于该部分工作的所占的比重和加速程度。
系统为加速时所需时间为Told,某部分处理所占比例为α,该部分性能提升倍数为κ。即该部分工作需要α*Told时间,性能提升后需要α*Told/ κ。
那么新的处理时间为:Tnew=(1- α)Told+α*Told/κ=Told[(1-α)+α/κ]
加速比:S = 1/ ((1 − α) + α/k)
信息的表示和处理
信息存储
进制转化
十六进制转换为二进制:
通过展开每个十六 进制数字,将其转换为二进制格式
十六进制数0x173A4C

二进制转换为十六进制:
首先将二进制数字分为每4位一组来转换为十六进制。如果位总数不是4的倍数,最左边的一组可以少于4位,前面用0补足。
二进制数11 1100 1010 1101 1011 0011

十六进制转换为十进制:
用相应的16的幂次方乘以每个十六进制数字。
十六进制数0x7AF

十进制转换为十六进制:
除以十六取余。
314156
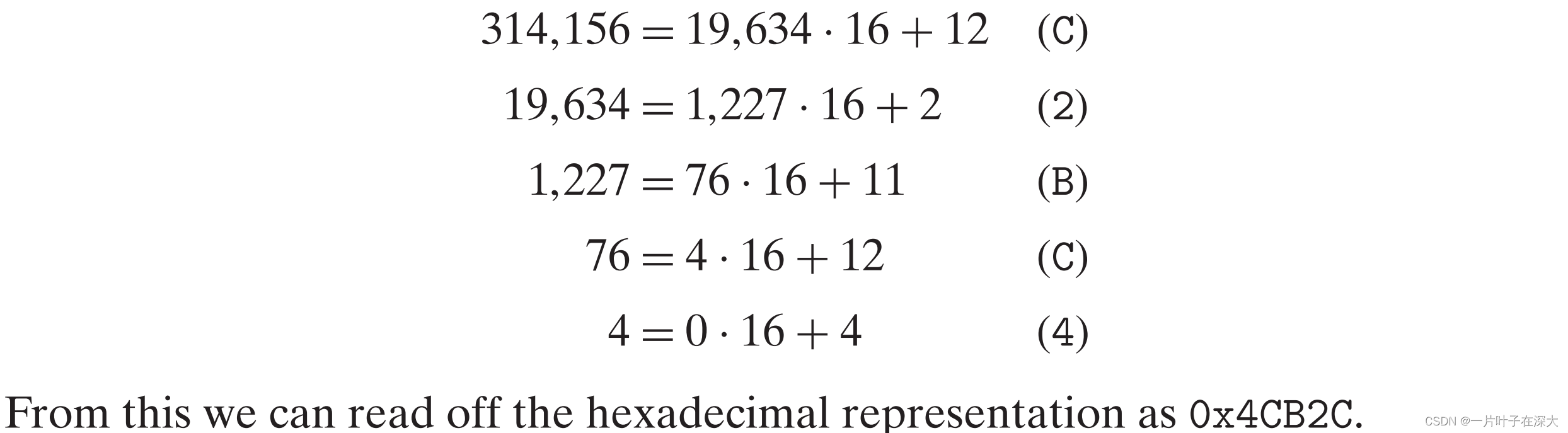

十六进制数为:0x4CB2C
字数据大小
字长:指明指针数据的大小。
对于一个字长为w位的机器而言,虚拟地址的范围为0~2w -1,程序最多访问2w个字节。
小端法
小端序是指机器选择在内存中按照从最低有效字节到最高有效字节的顺序存储对象。
以一个位于 0x100 处,类型为 int,十六进制值为 0x01234567 的变量为例。其中 0x01 是最高位有效字节,0x67 是最低位有效字节。

小端法:低位数在低地址,x86机器,Intel兼容机,Google的Android,Apple的iOS。
大端法
大端序是指机器选择在内存中按照从最高有效字节到最低有效字节的顺序存储对象。
以一个位于 0x100 处,类型为 int,十六进制值为 0x01234567 的变量为例。其中 0x01 是最高位有效字节,0x67 是最低位有效字节。

大端法:低位数在高地址,IBM机器。
ARM微处理器:双端法。
布尔代数
以二元集合{0,1}或{TRUE(真),FALSE(假)}基础上定义的代数
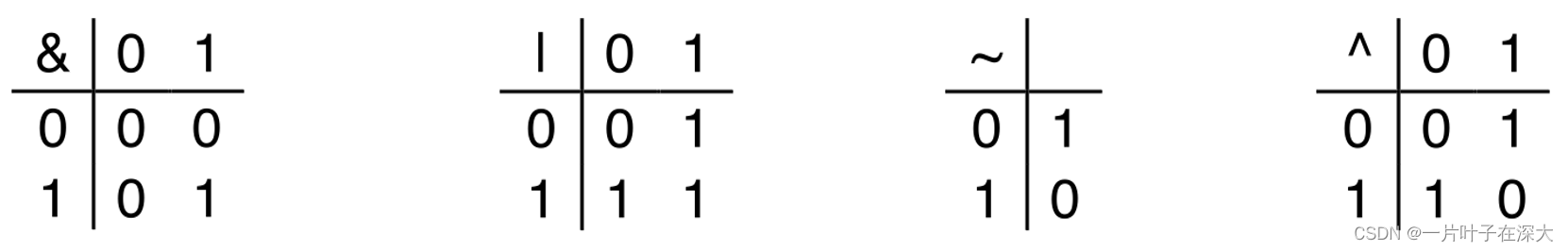
位级运算
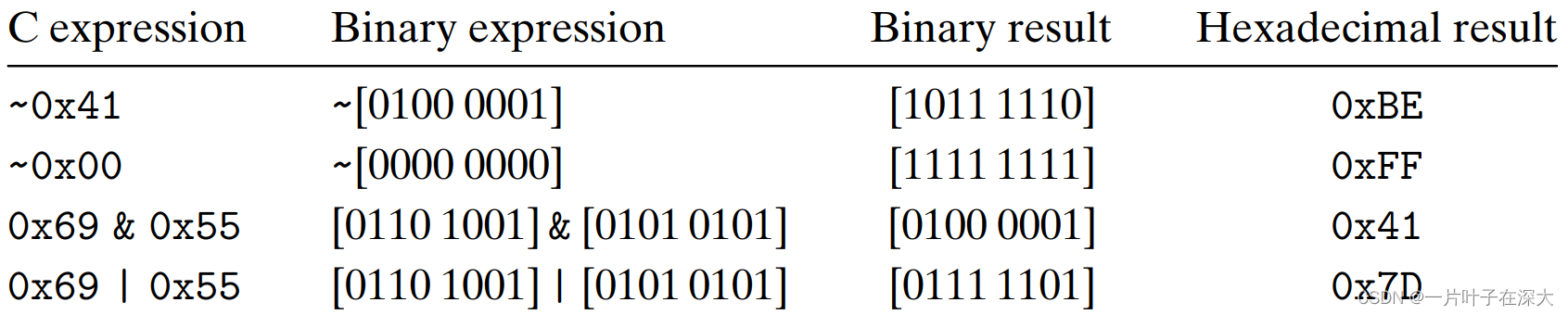
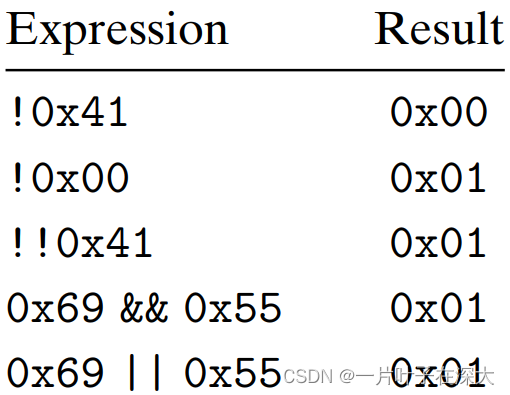
逻辑运算
C语言中提供了一组逻辑运算符||、&&和!,分别对应于OR、AND和NOT 运算。
所有非零的参数都表示TRUE,参数零表示FALSE。
返回1来表示结果为TRUE,返回0来表示结果为FALSE。
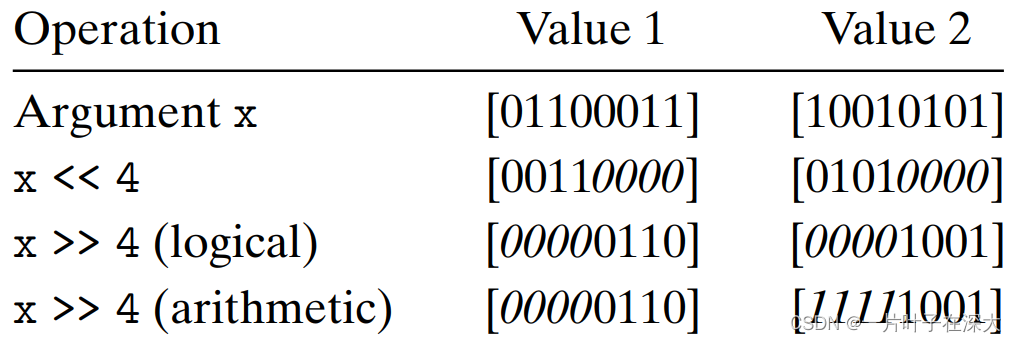
移位运算
左移:在右端补0。
算术右移:在左端补最高有效位。
逻辑右移:在左端补0。
整数表示
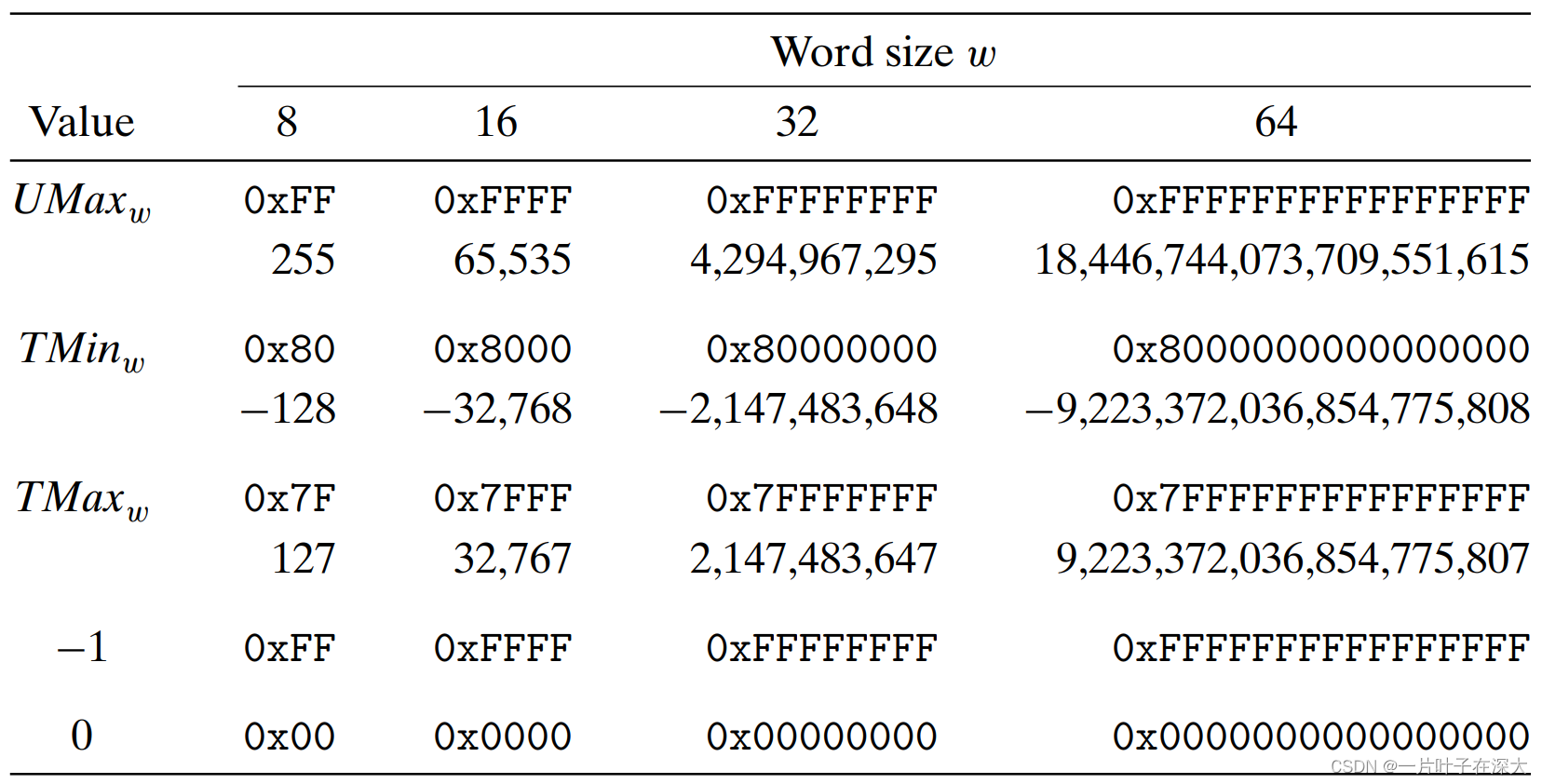
无符号数编码
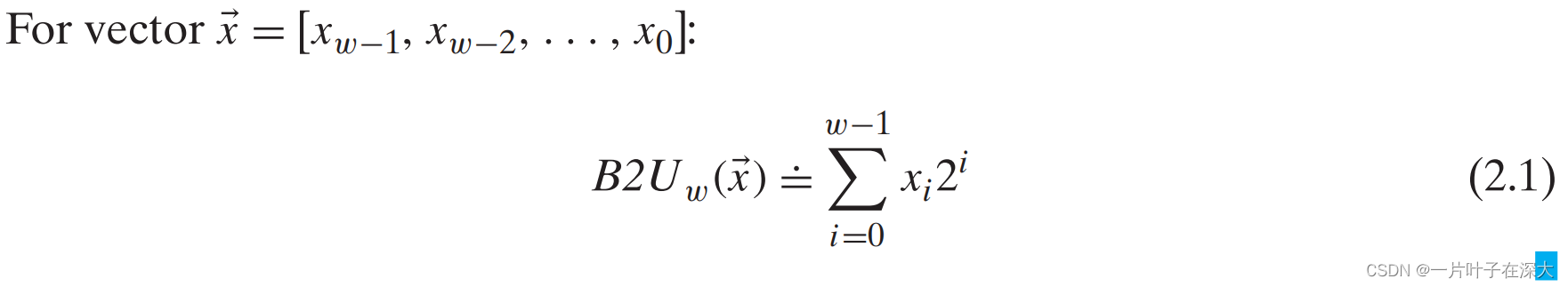
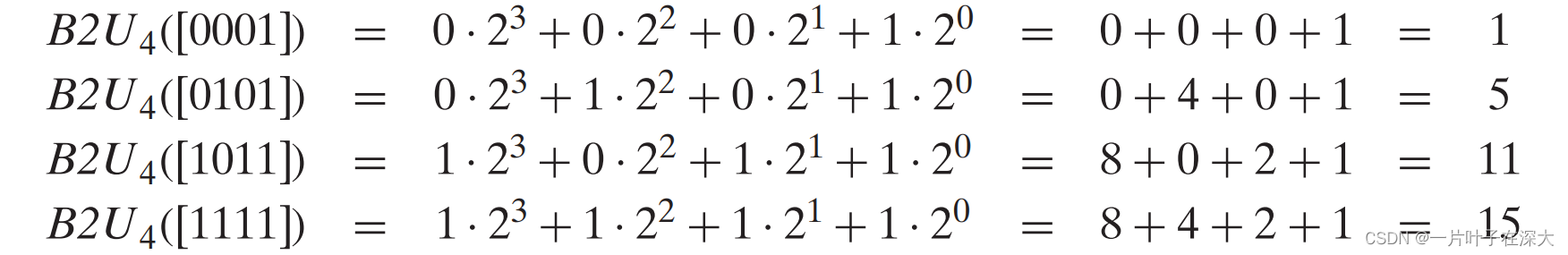
补码编码
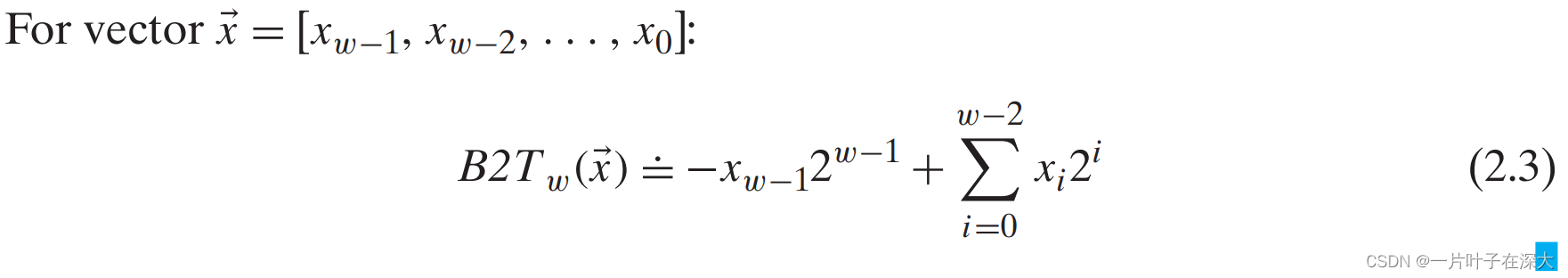
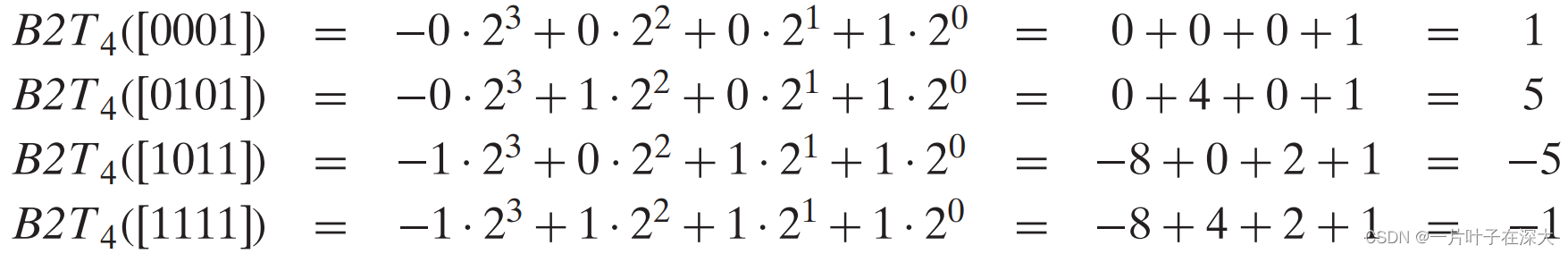
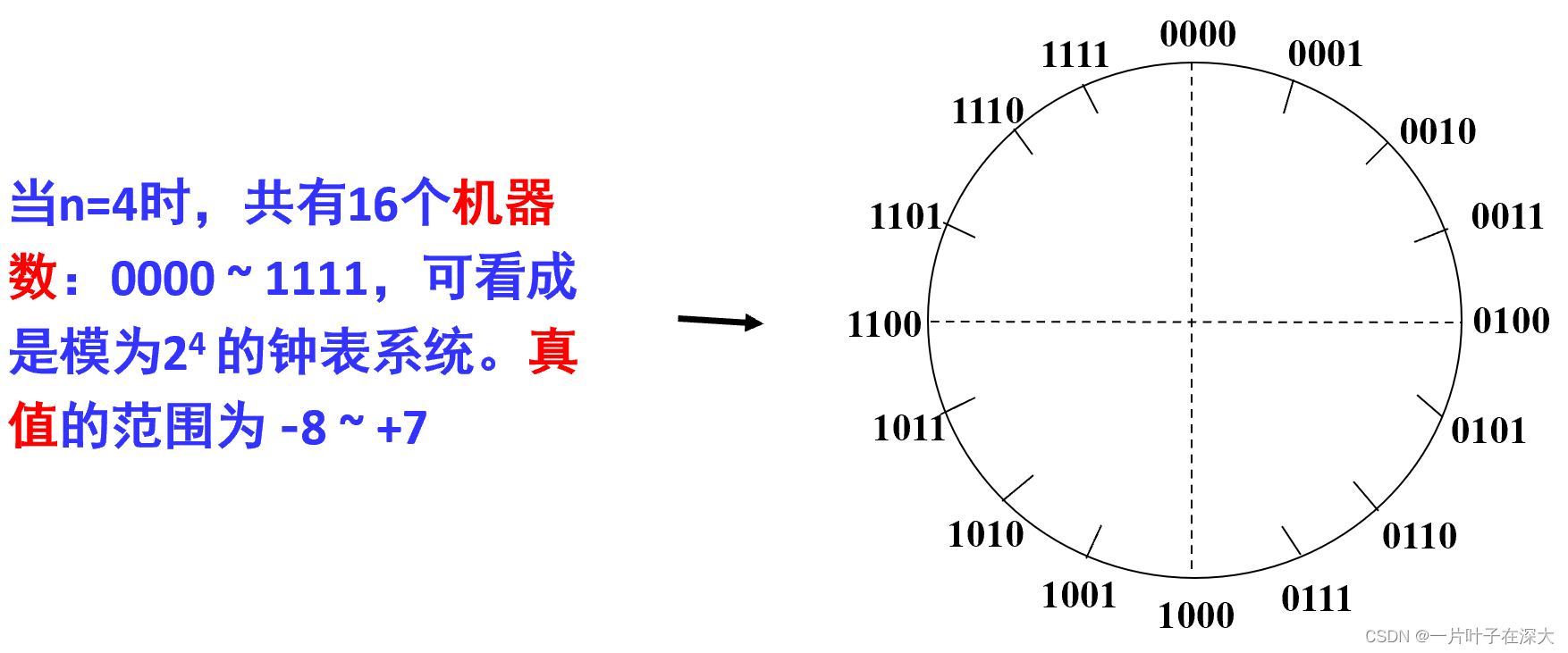
Umax、Tmin和TMax
求一个数的补码表示

有符号数和无符号数之间的转换
当表达式同时含有有符号数和无符号数的时候,在同位长的情况下,默认将有符号数强制转换为无符号数进行运算。
强制类型转换的结果保持位值不变,只是改变了解释位值的方式,即位表示是一样的,改变的只是解释方式。
补码转换为无符号数
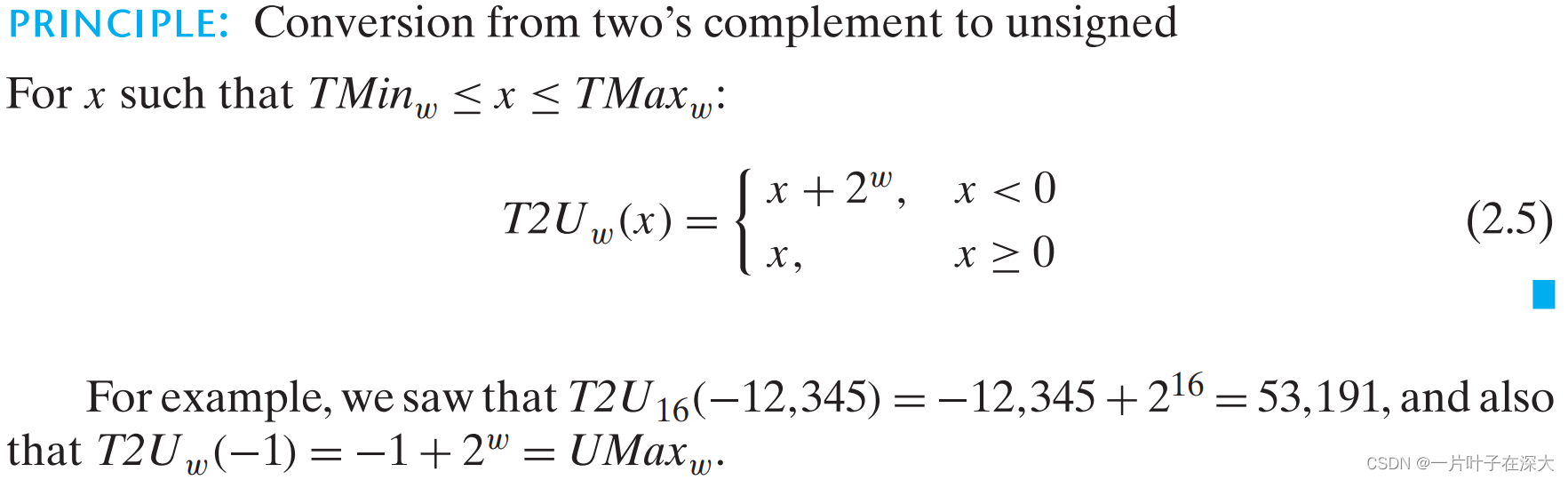
无符号数转换为补码
扩展数的位表示
无符号数零扩展:位开头添加0。
有符号数补码符号位扩展:位开头添加最高有效位的值。
运算时,先改变位大小,再完成有符号到无符号的转换。
截断数字
截断无符号数:直接丢弃高位。
截断有符号数:先当成无符号数截断,再当成有符号数。
整数运算
无符号加法
直接丢弃最高进位如果当前位数无法表示和。
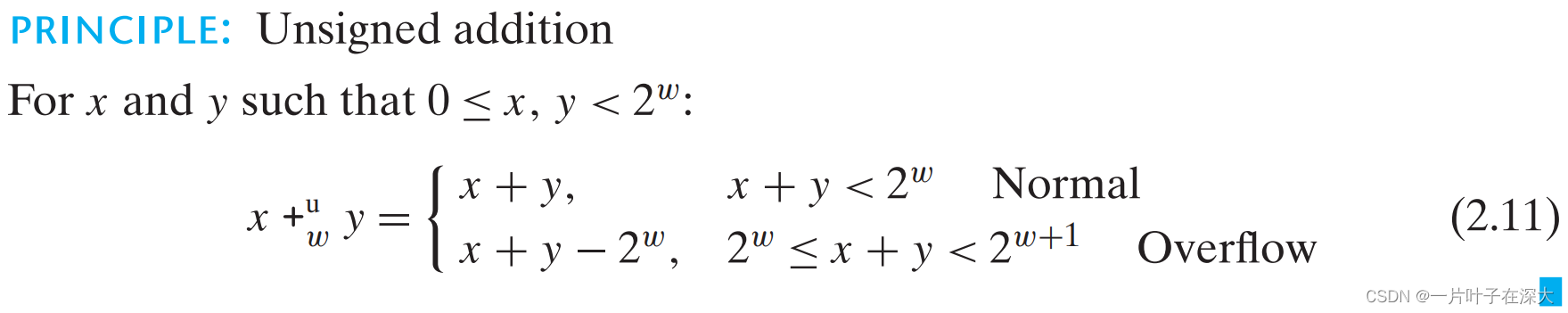
无符号数求反
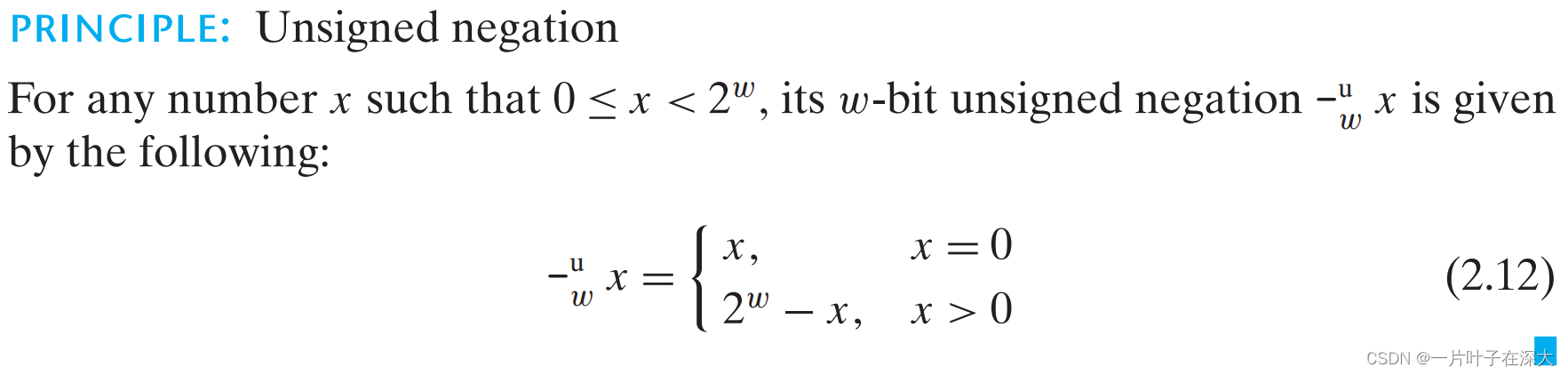
有符号整数加法
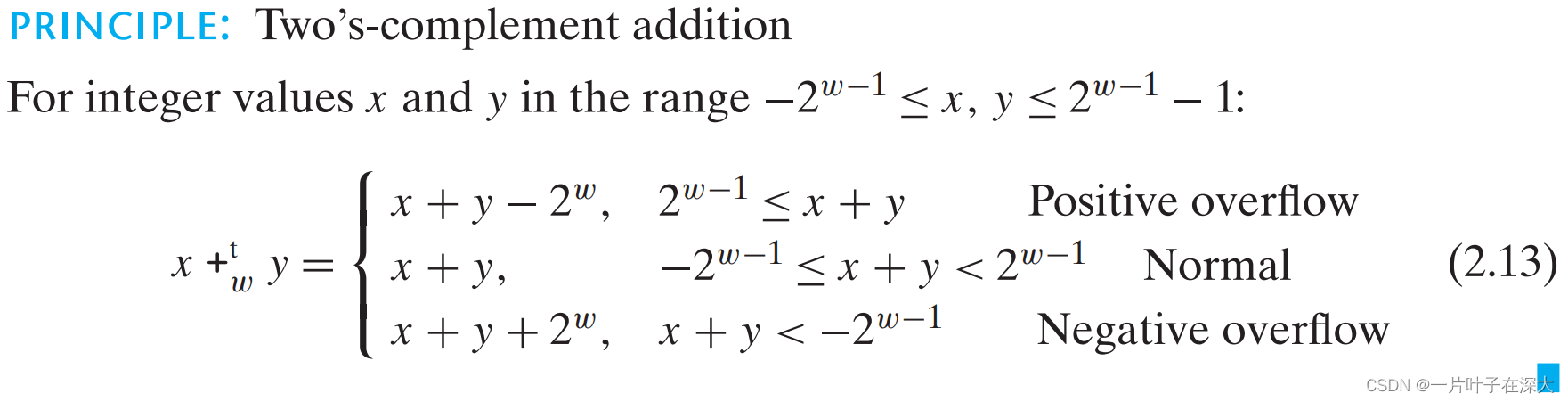
补码的非
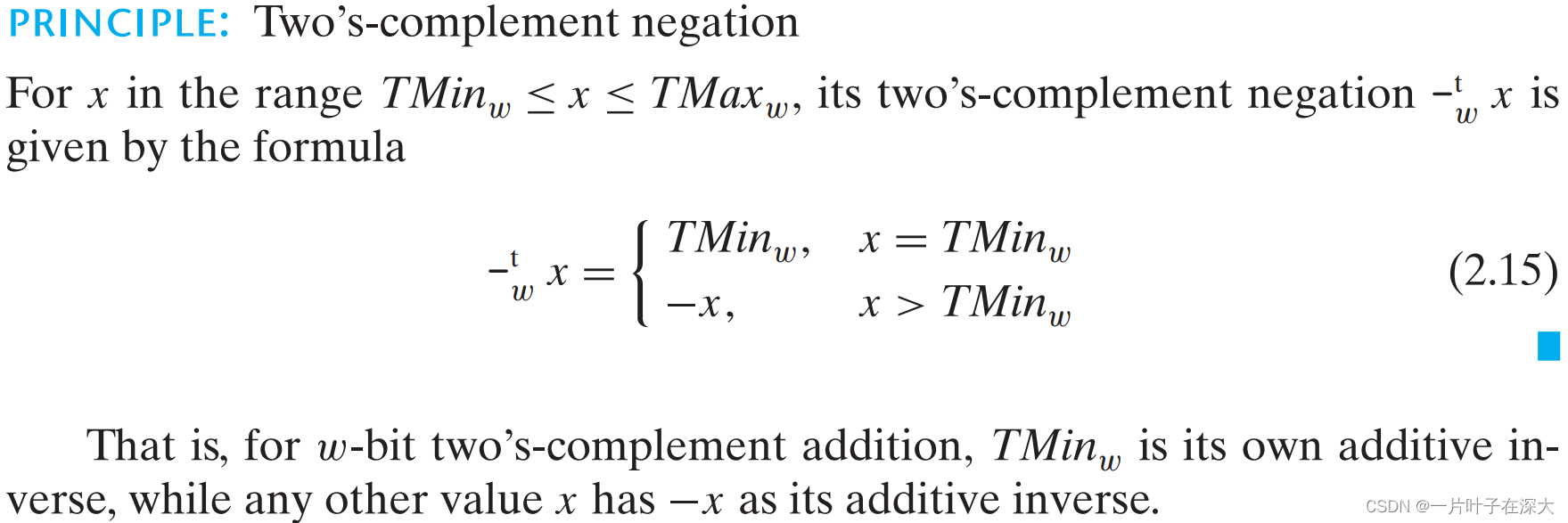
无符号乘法

补码乘法

浮点数
小数换算
整数部分除二取余,小数部分乘二取整。

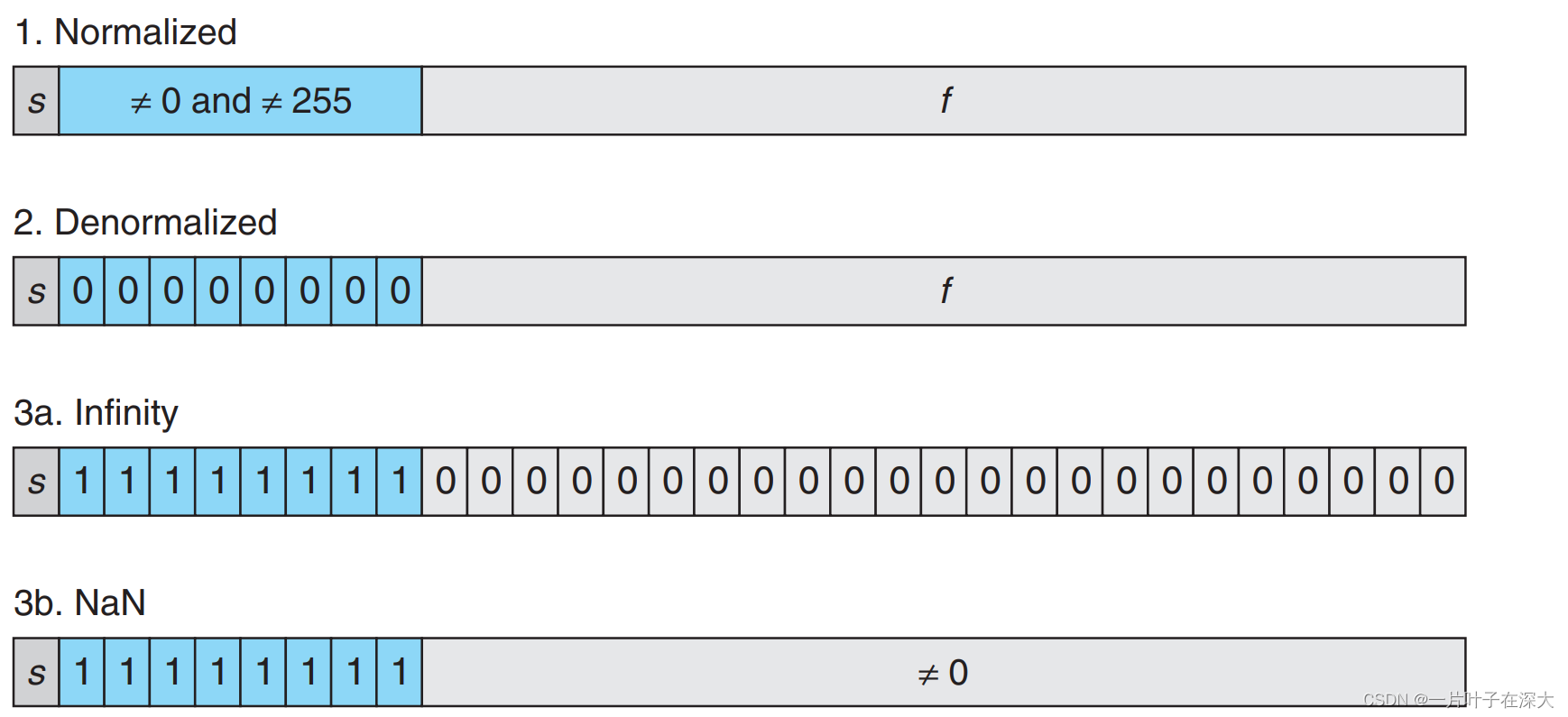
IEEE浮点表示
V=(-1)s×M×2E
符号s:s=1表示负数,s=0表示正数。
尾数(fraction)M:范围[1,2)或者[0,1)。
阶码(exp)E:对浮点数加权,2的E次幂。



舍入
IEEE规定了四种舍入方式,分别为:向0舍入、向下舍入、向上舍入以及向偶数舍入。
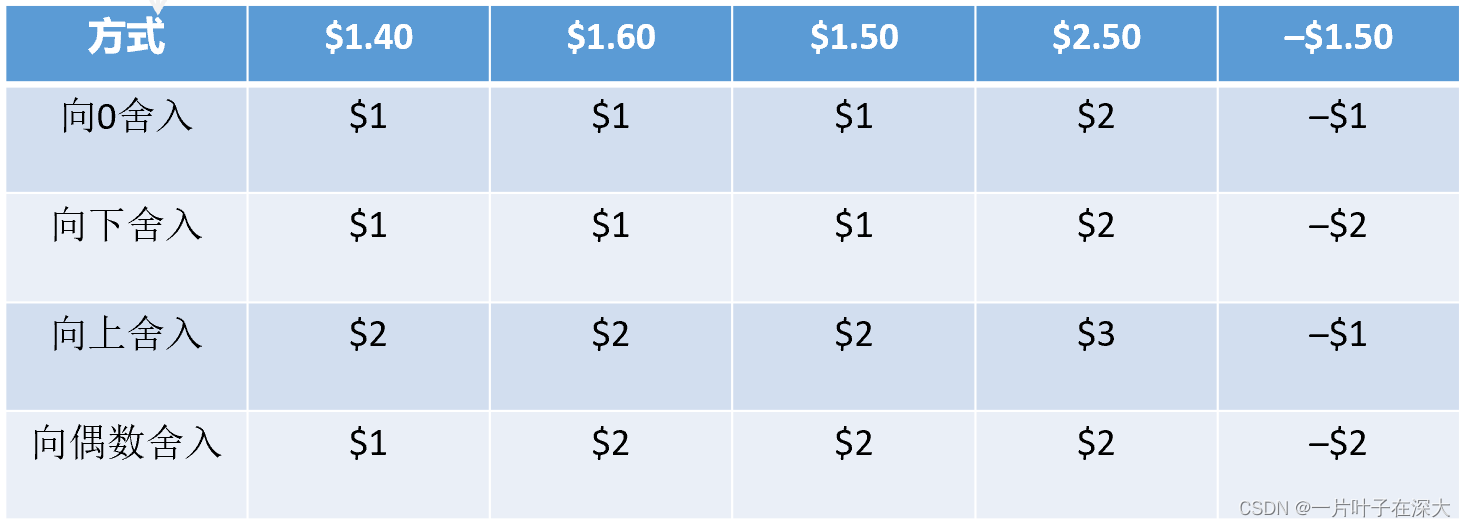
默认向偶数舍入。
浮点数加法
阶码对齐,尾数右移相加
1.010*22 + 1.110*23= (0.1010 + 1.110)*23
= 10.0110 * 23
= 1.0011 * 24
= 1.010 * 24
浮点数乘法

程序的机器级表示
访问信息
寄存器访问
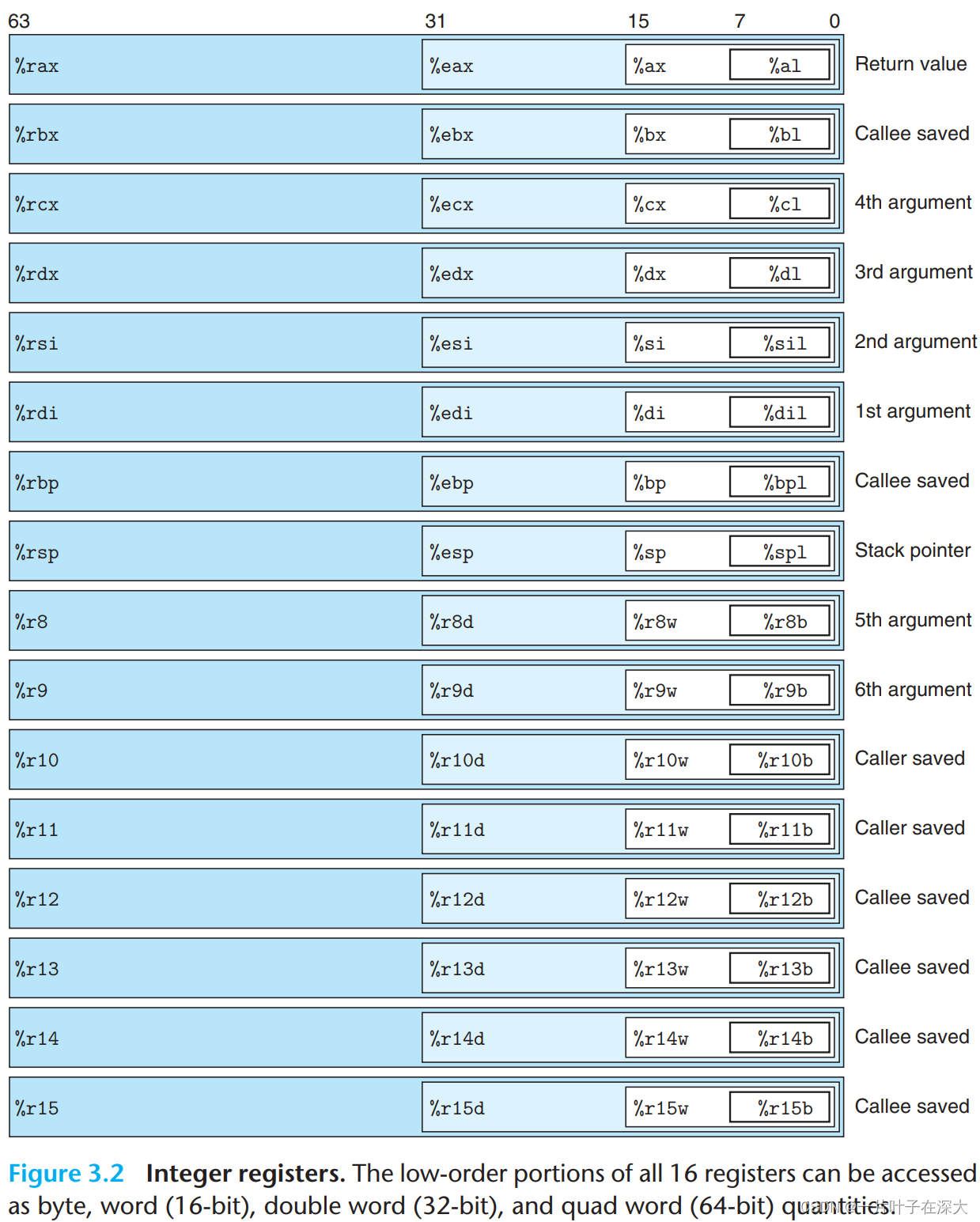
对寄存器低四位赋值时,高四位自动清零。
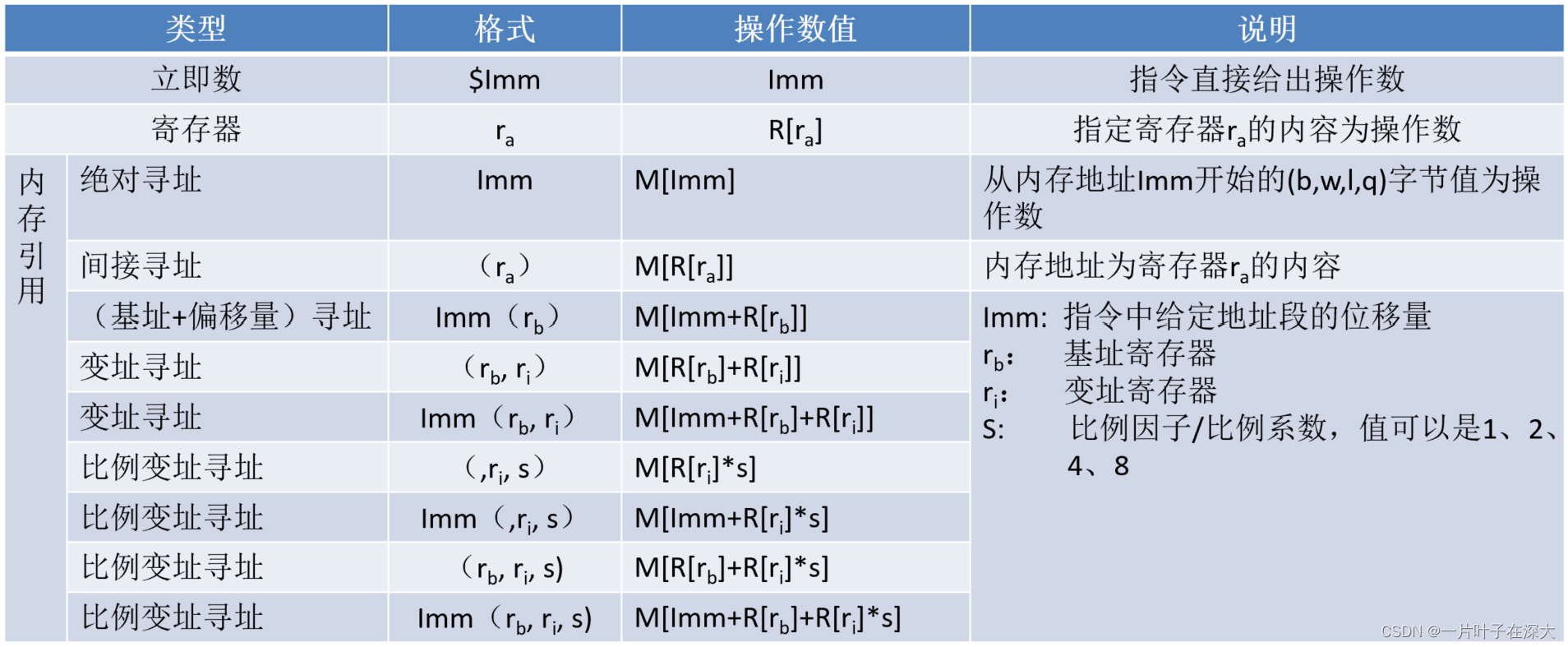
三种数据寻址方式:
立即数、寄存器、内存引用。
数据传送指令
等大小
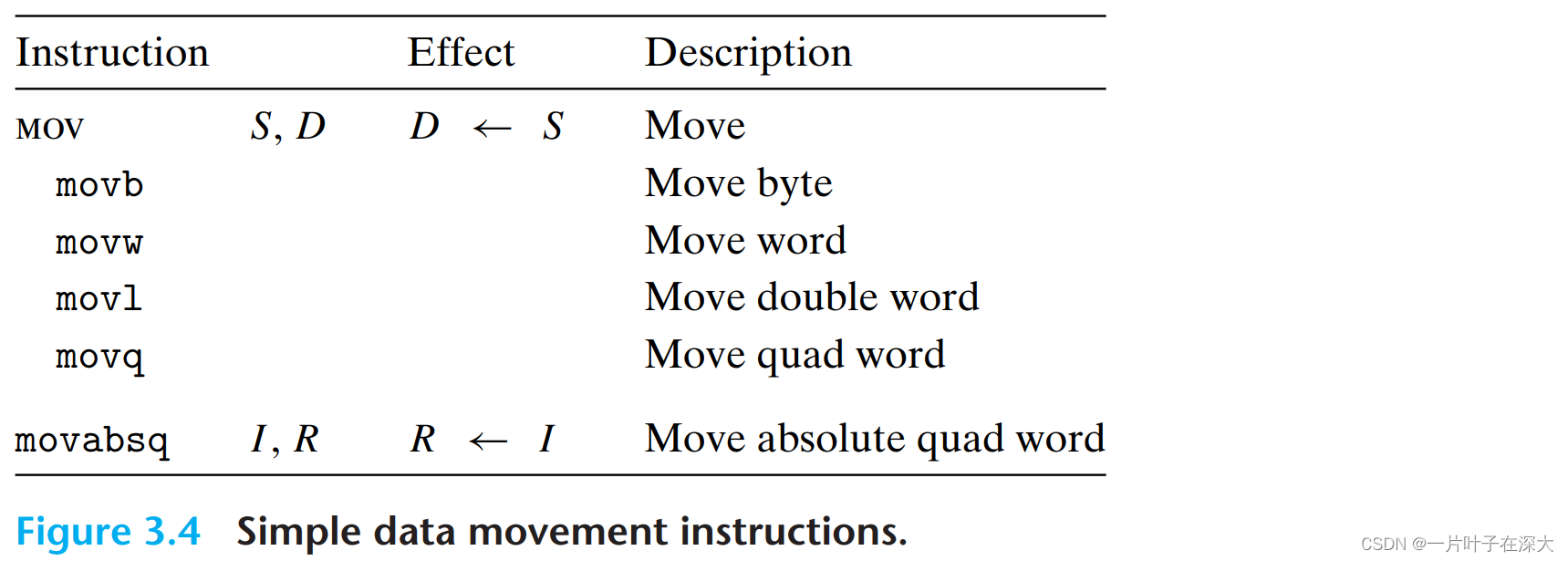
不等大小,零扩展
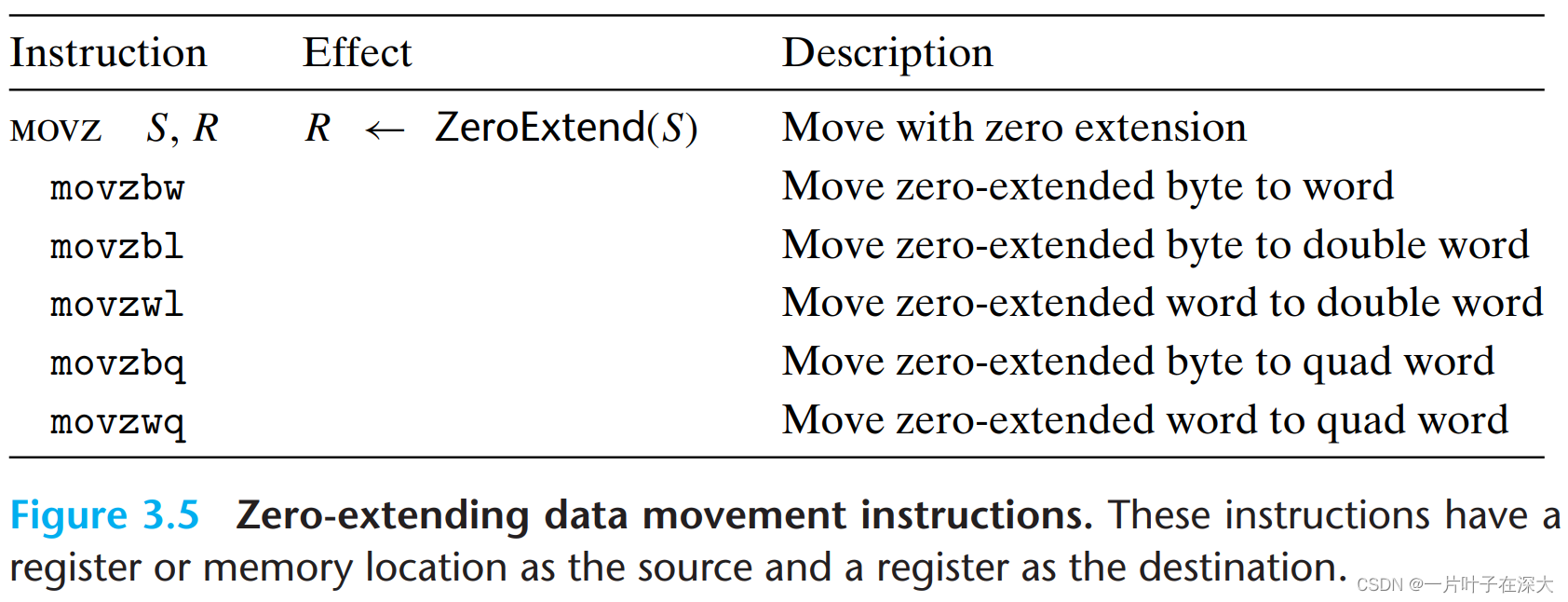
不等大小,符号扩展
弹栈和出栈

算数和逻辑操作
算法和逻辑运算指令
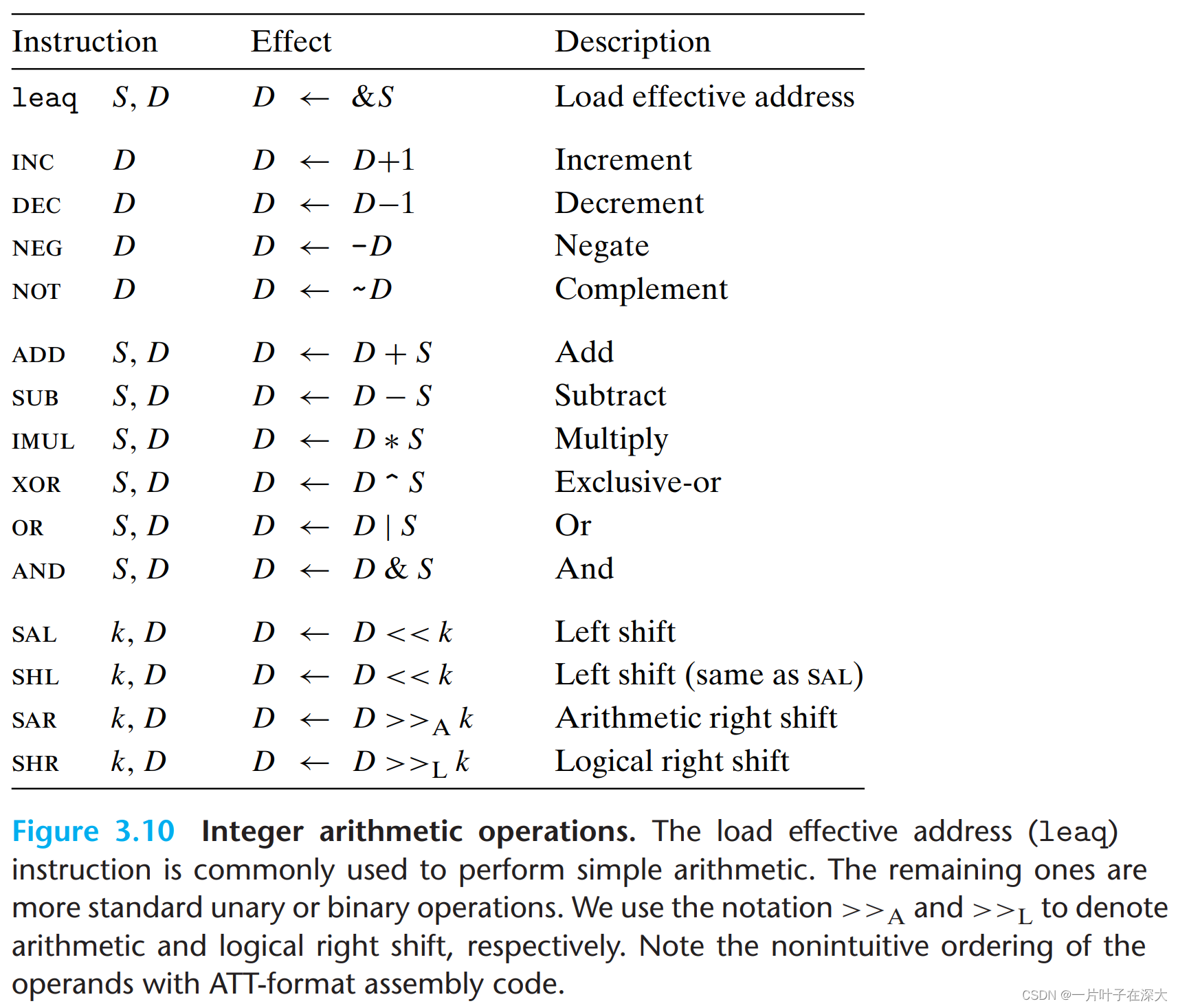
特殊算术操作
两个64位数的全128运算
指令中只给出一个操作数,另一操作数:乘法%rax,除法%rdx:%rax
隐含目的操作数:乘法 %rdx:%rax,除法商%rax、余数%rdx

控制
条件码
条件码(condition code)寄存器,其值描述最近的算术或逻辑操作的属性。
CF (Carry Flag): 进位标志(无符号数的溢出)
ZF(Zero Flag): 结果为零标志
SF(Sign Flag): 符号标志,结果为负时SF=1
OF(Overflow Flag): 溢出标志,正溢出或负溢出
以下指令只改变标志位。
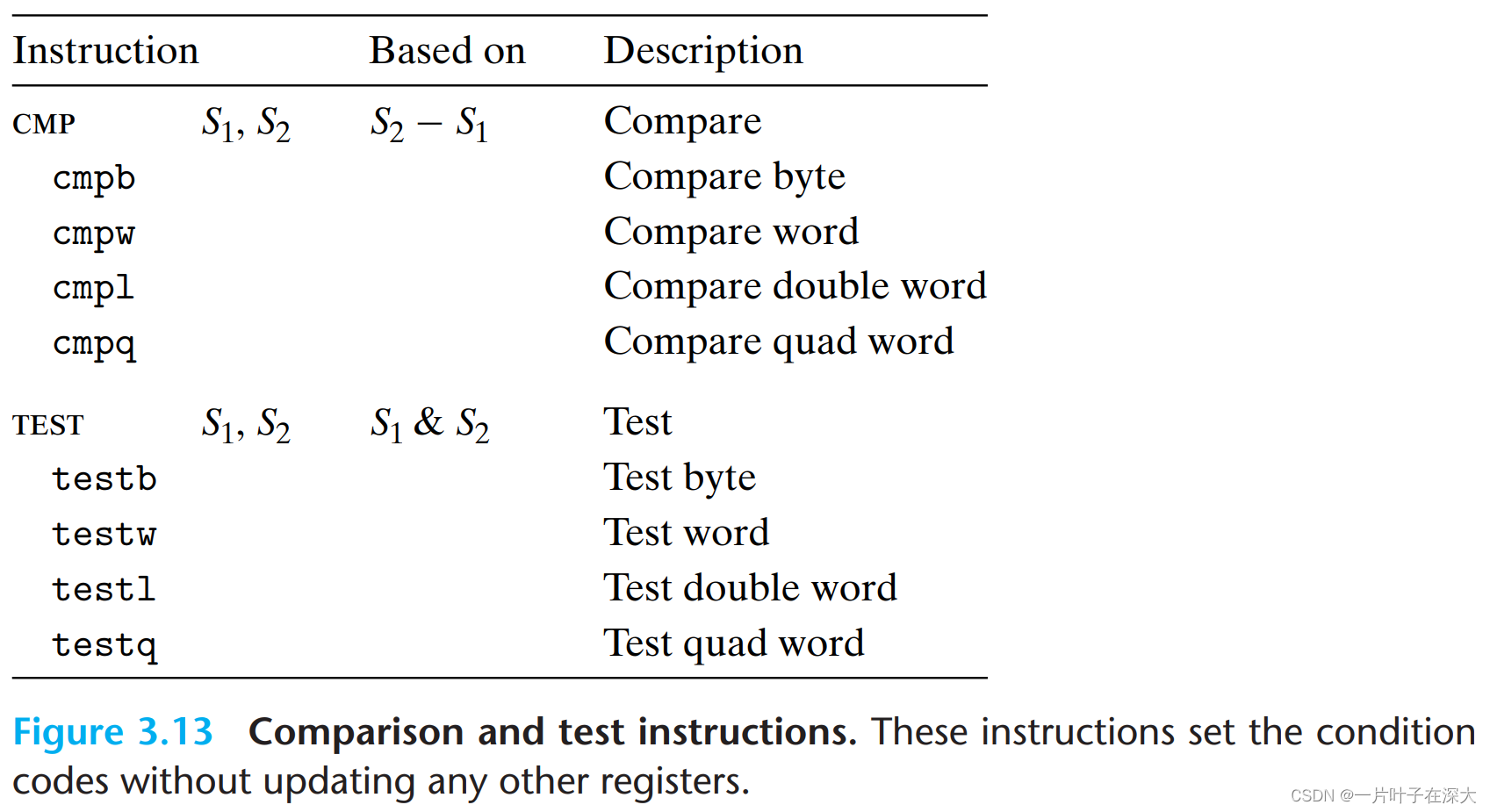
访问条件码
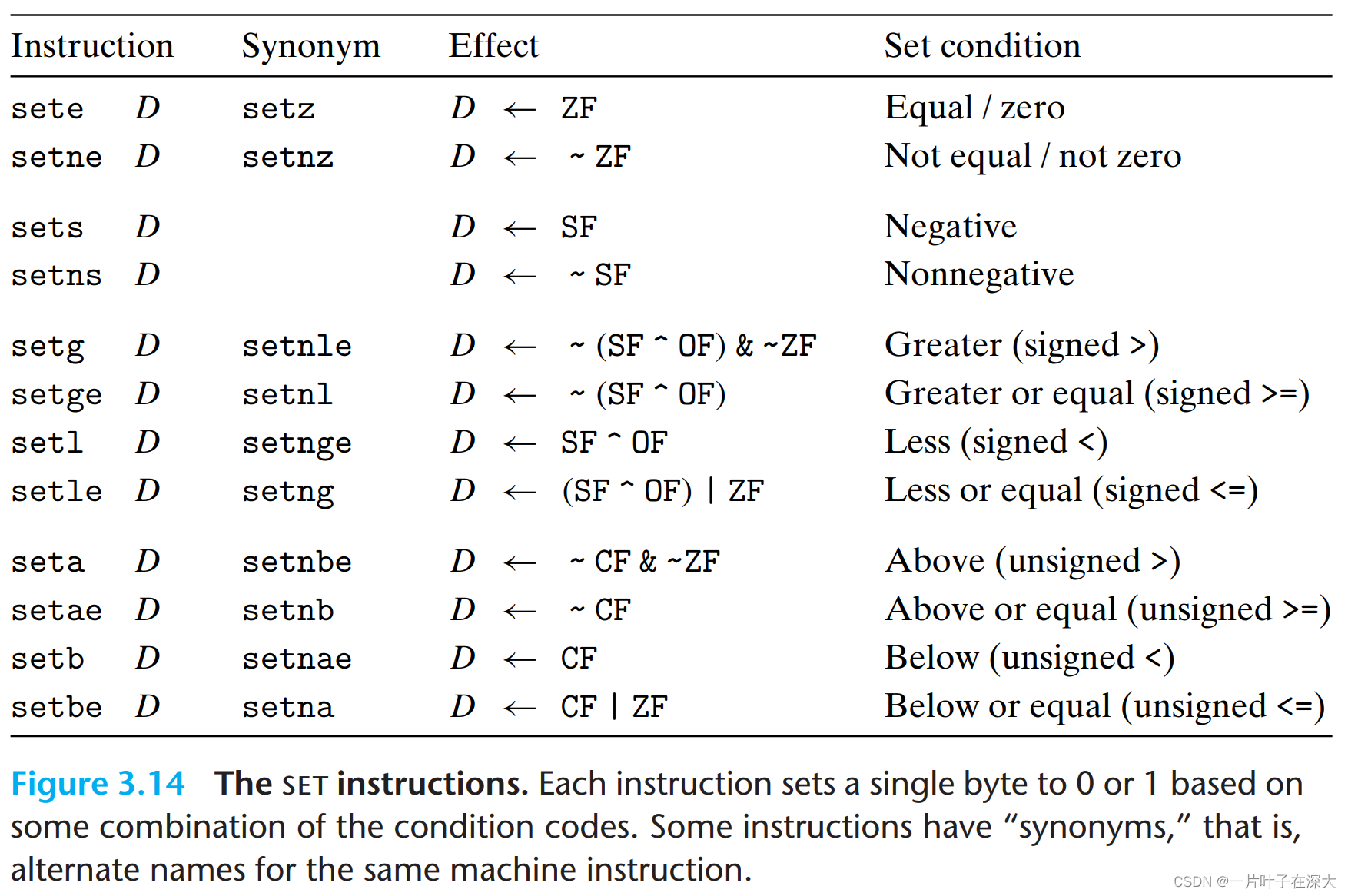
跳转指令
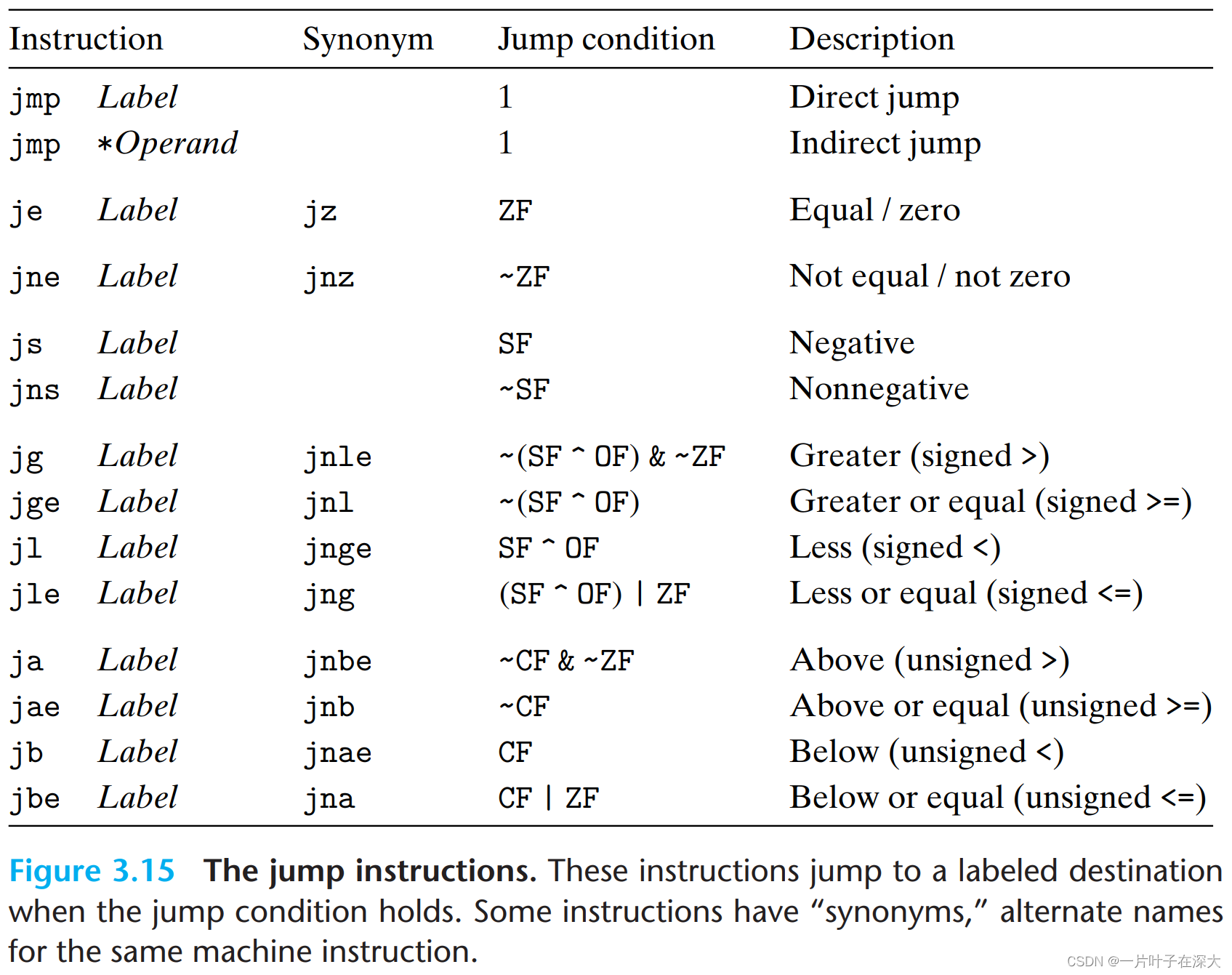
实现条件分支if-else

条件传送指令
当传送条件满足时,把S复制到目的R。
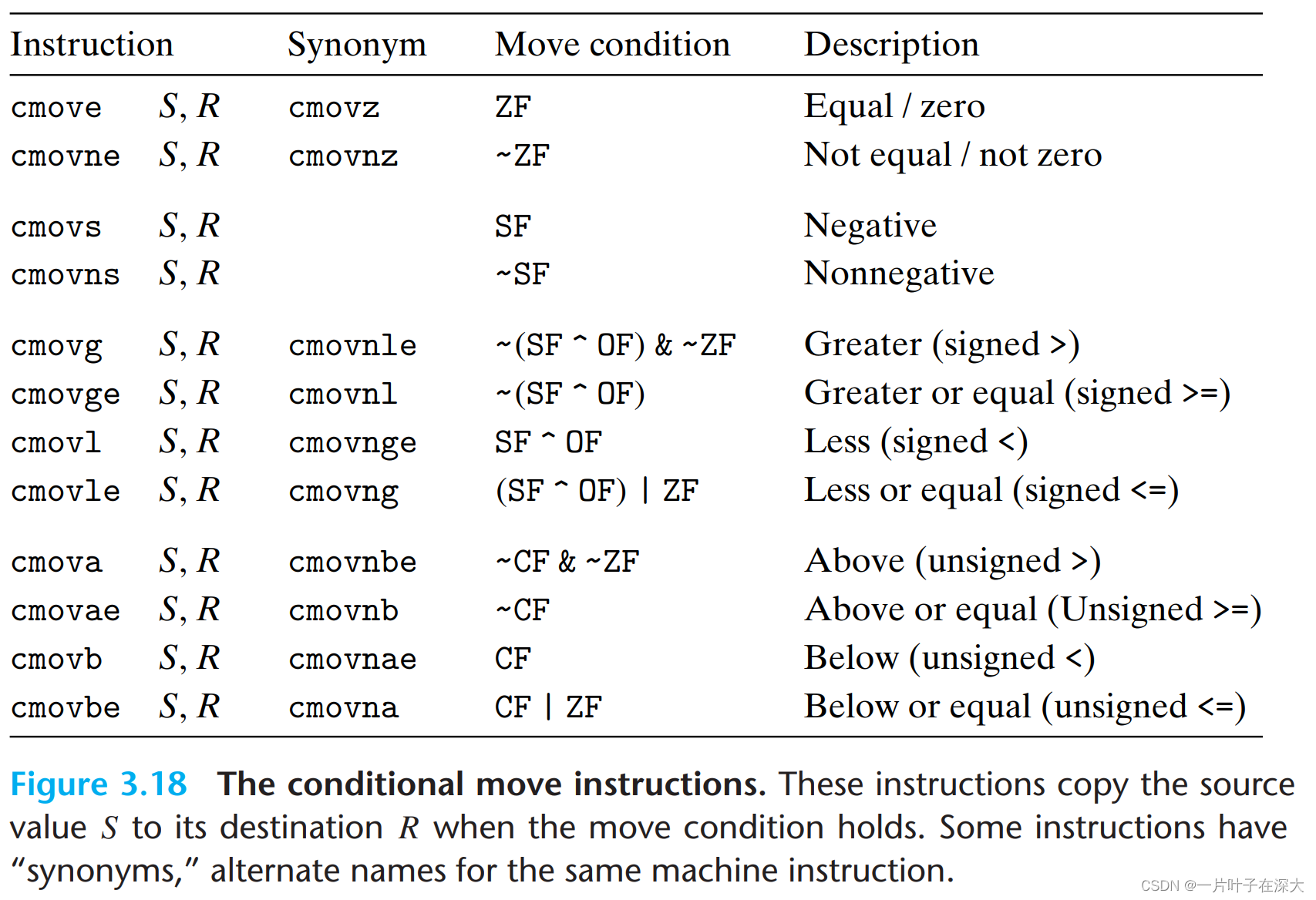
do-while循环

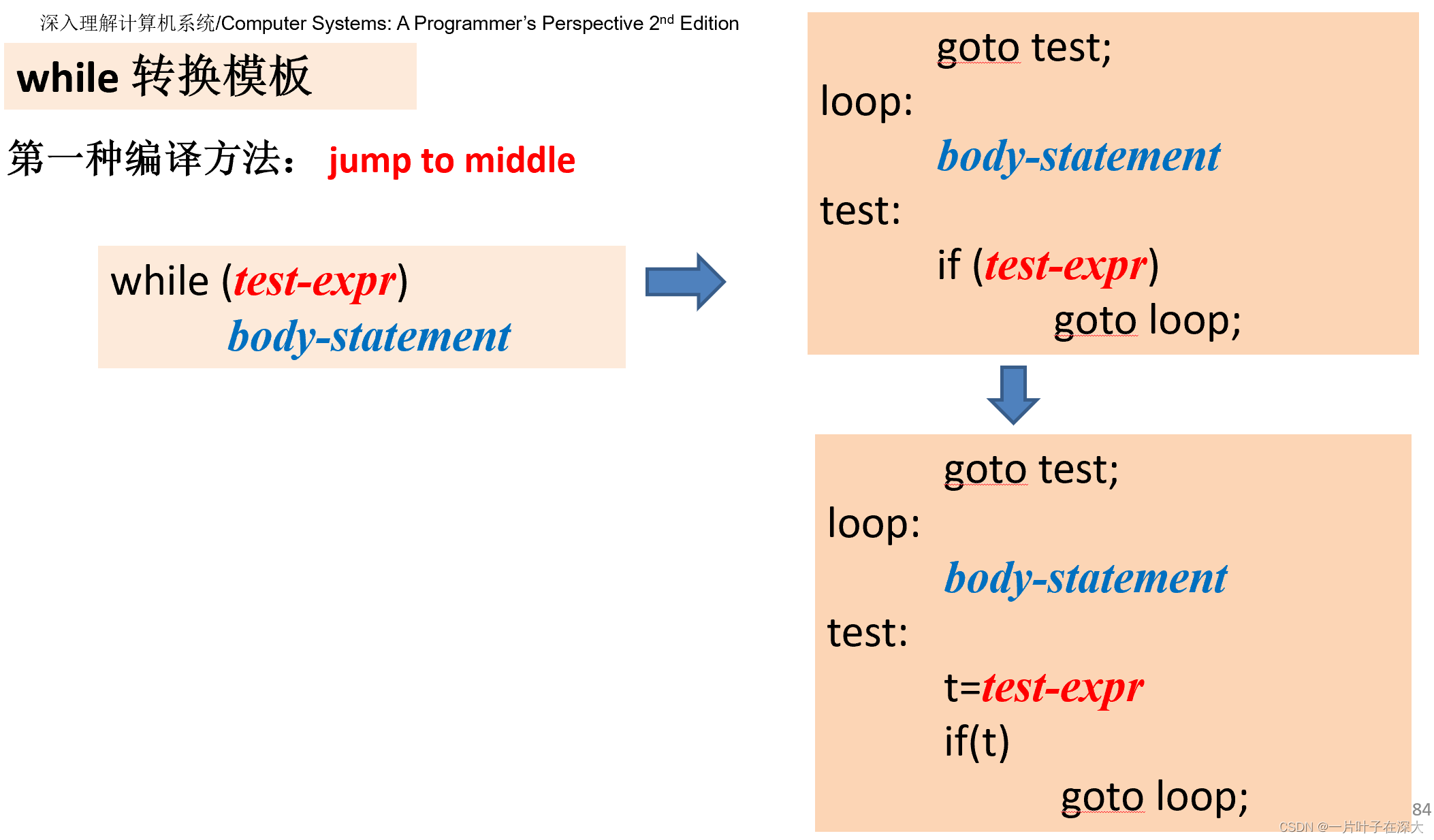
while循环
第一种方法,先跳转到测试
第二种方法,先测试再开始do-while循环

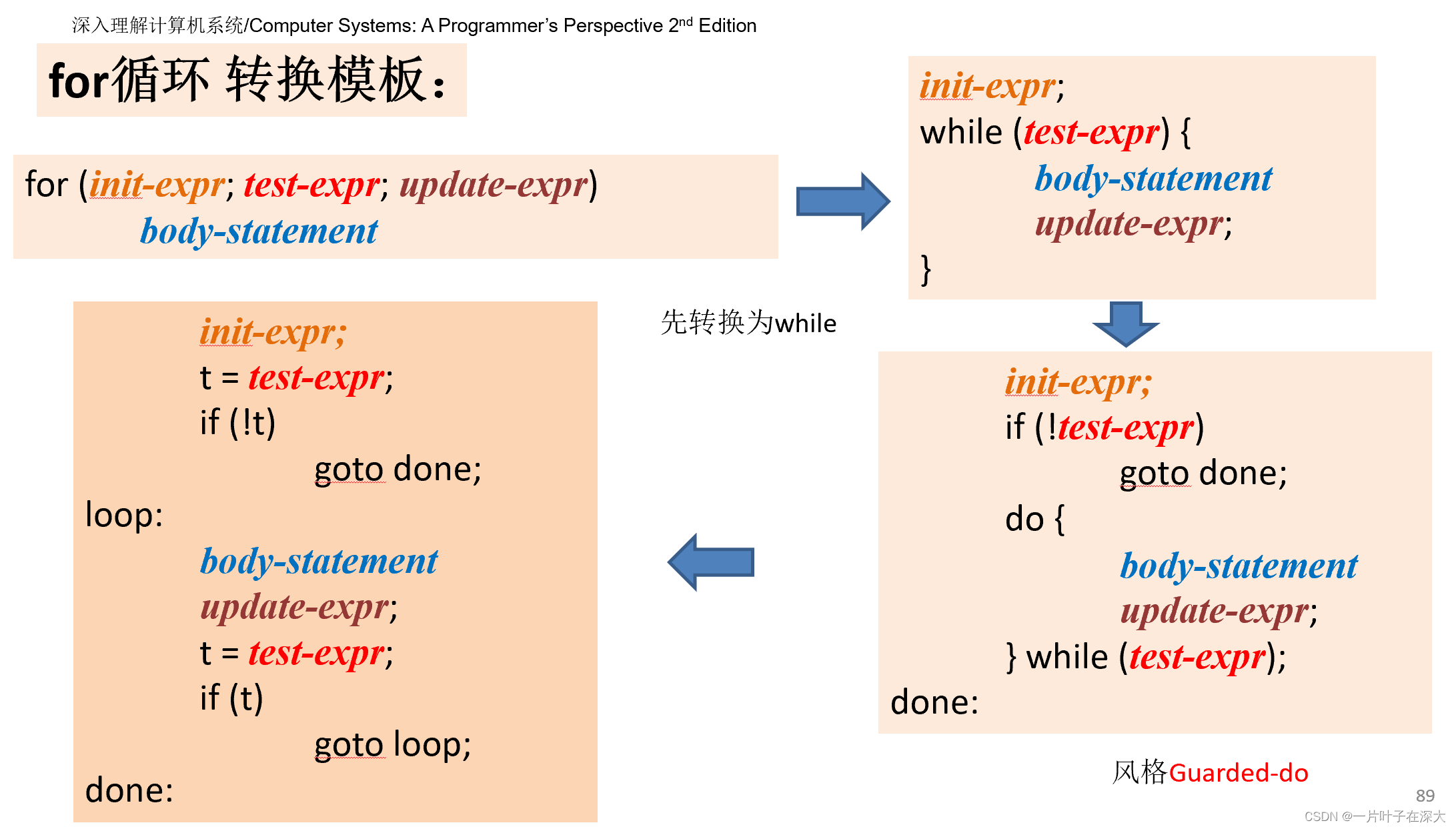
for循环
先初始化,然后变成while循环
Switch
Switch语句可以通过if-else语句来实现,事实上也是如此,当情况的数量少于4个时,switch语句将翻译为if-else语句,当超过4个情况时,并且值的范围跨度比较小时就会使用跳转表
过程
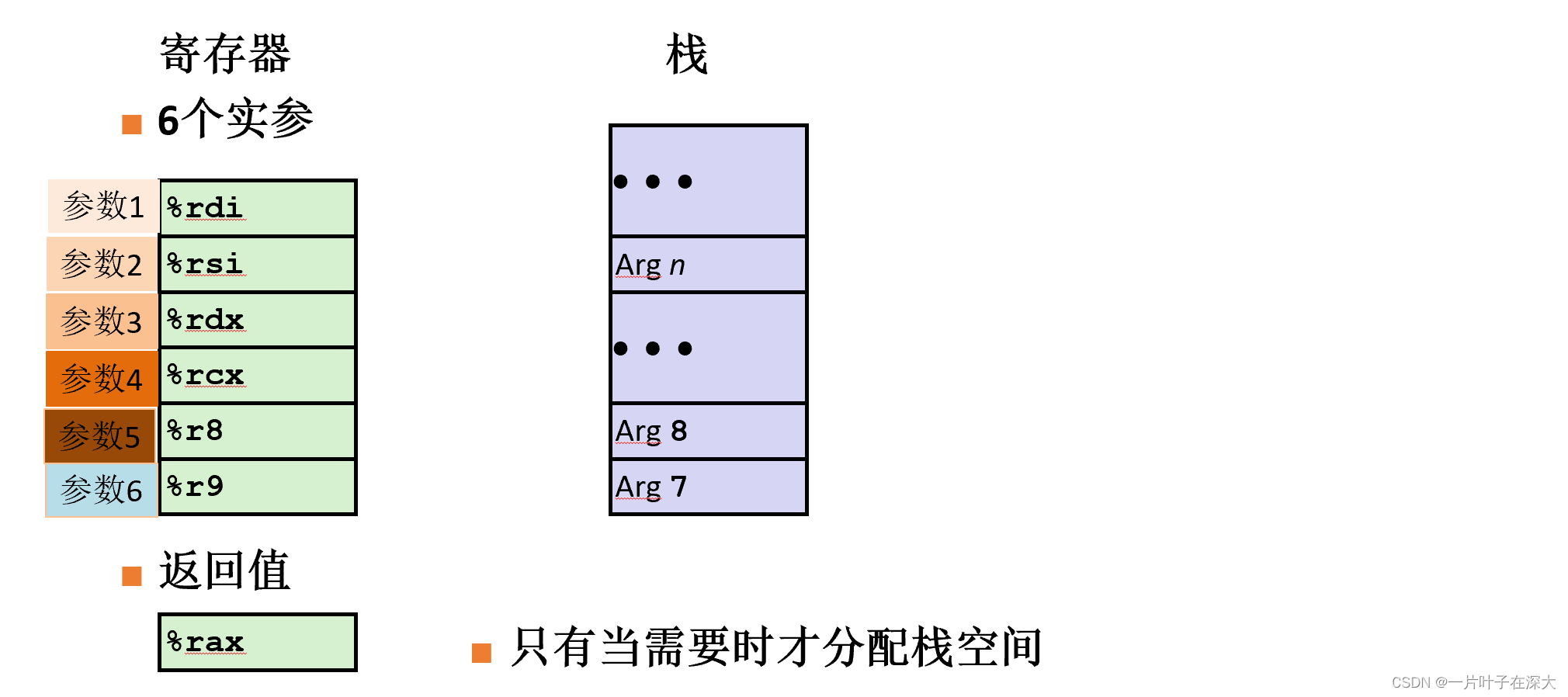
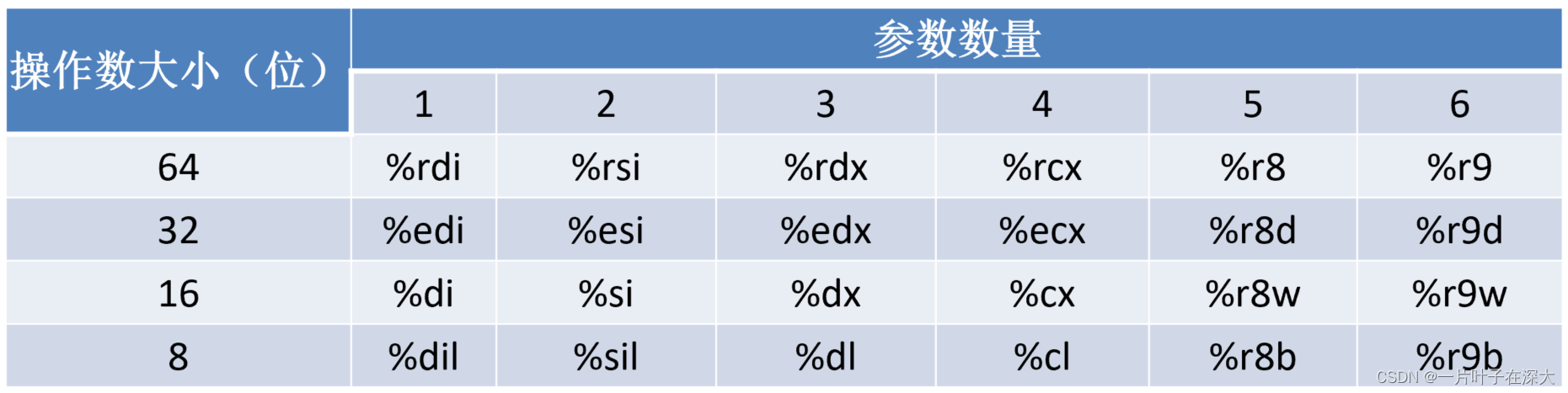
运行时栈
栈的作用:过程参数、返回地址、寄存器保存(用于修改后恢复,现场保存)、局部变量。

转移控制
支持调用和返回的指令
call指令:返回地址入栈,跳转到所指的地址——被调用过程的起始地址。
返回地址:调用结束后的下一条指令的地址。
ret指令:从栈中弹出一个地址,跳转到该地址。
过程数据存储
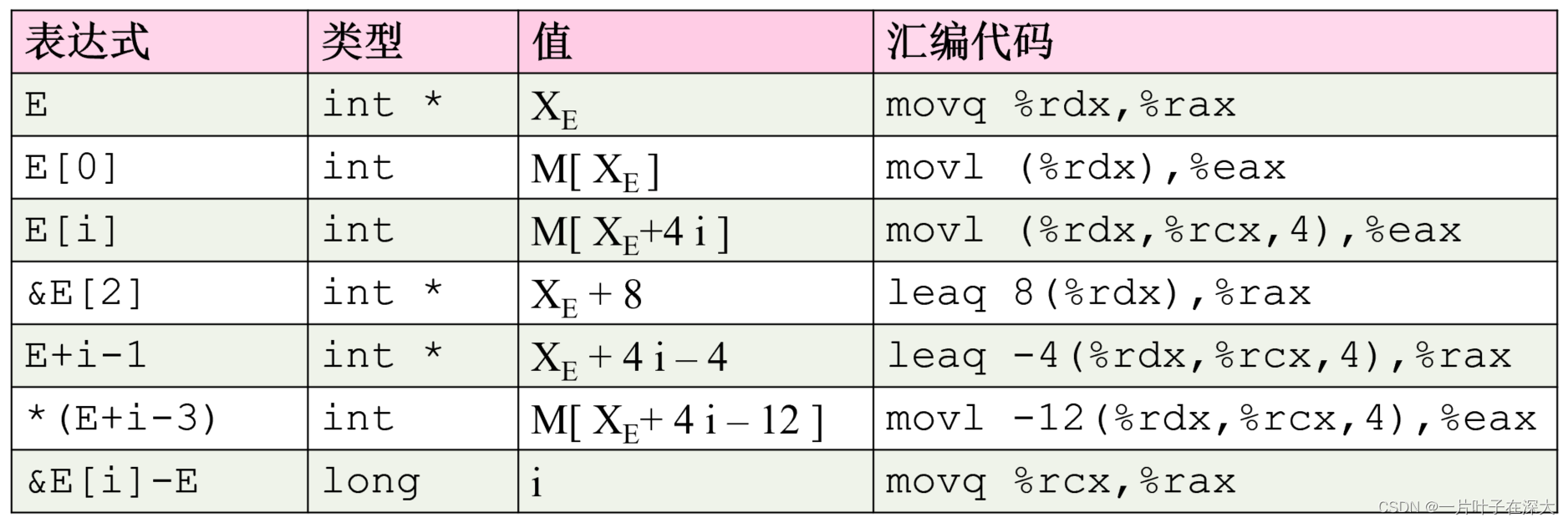
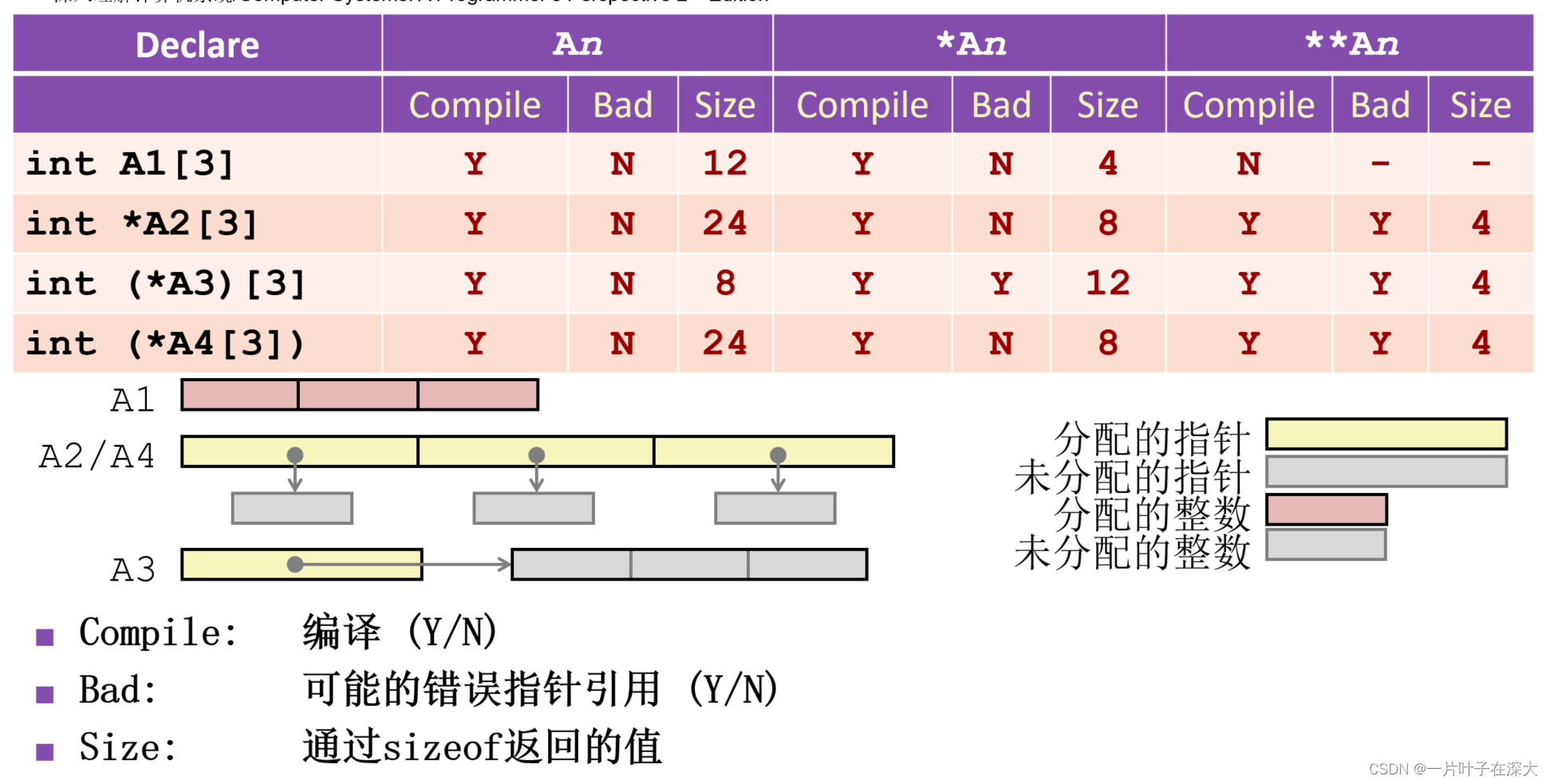
数组
指针运算
int E[18]

数据对齐
以结构体中最长元素类型为对齐。
在机器级程序中将控制与数据结合起来
理解指针
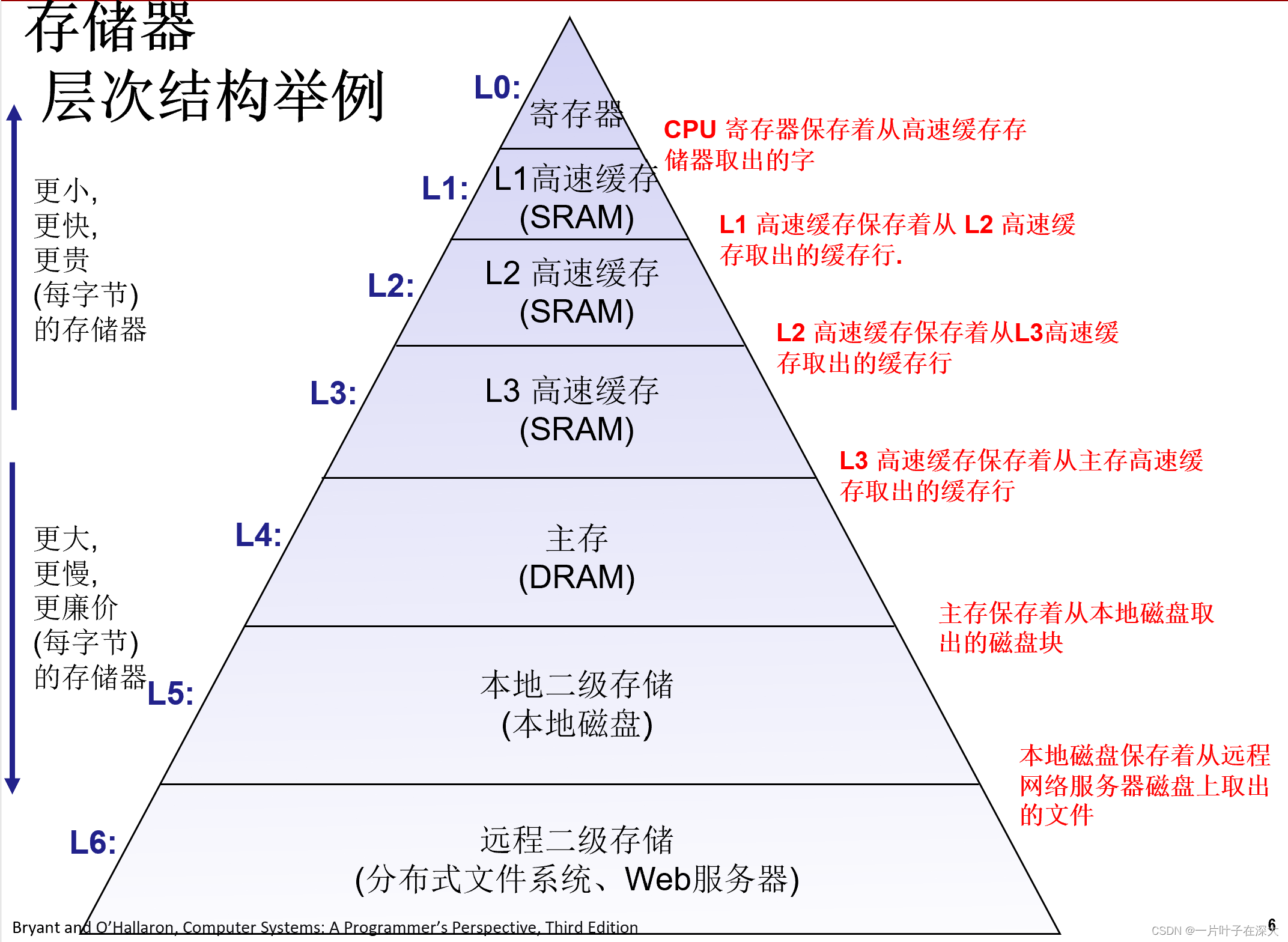
存储器层次结构
存储技术
存储器
随机访问存储器
cache是静态RAM,不用刷新。
内存是动态RAM,靠电容有无存储的电荷来表示1和0,电荷会因漏电而消失,因此需要刷新。
磁盘存储

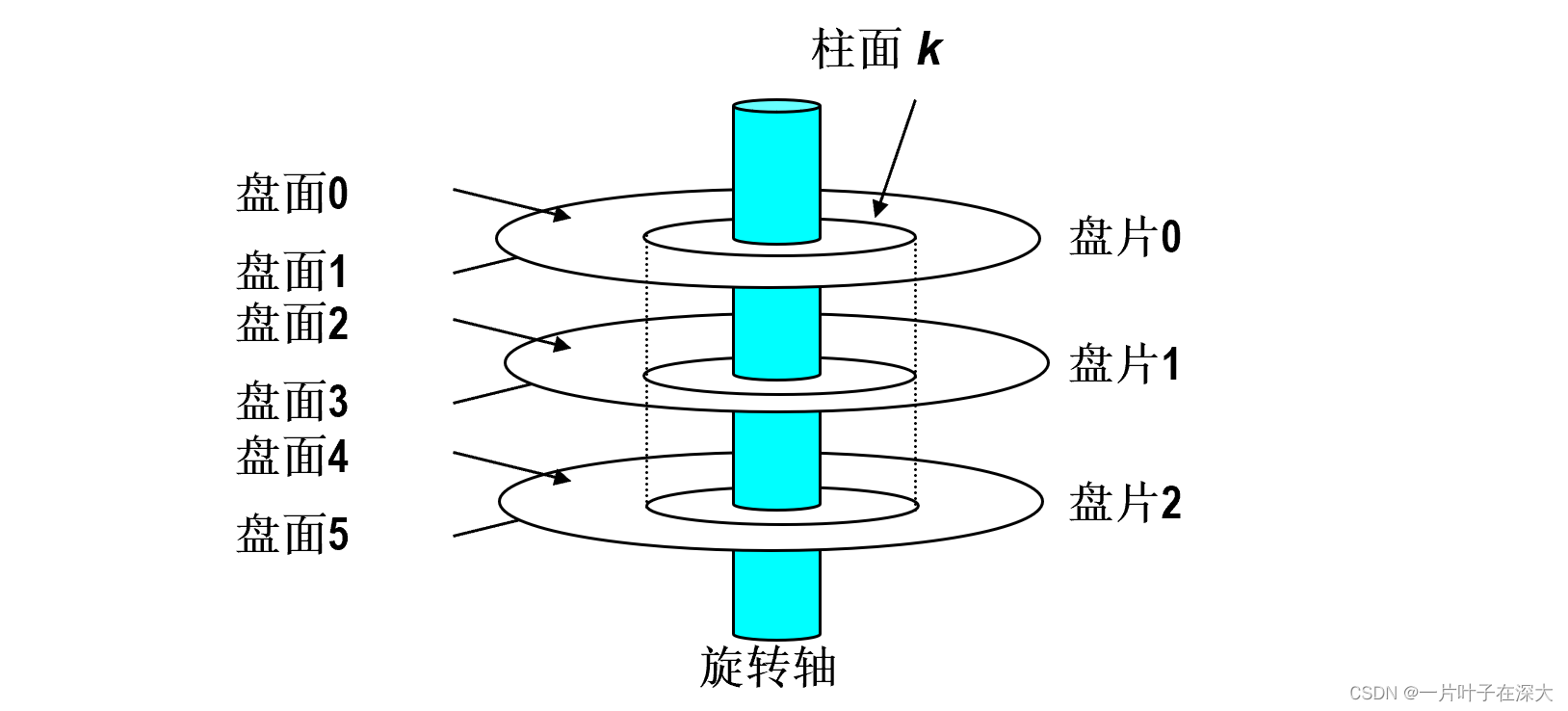
磁盘结构
- 磁盘由双面的盘片组成
- 每张盘面上密集地排布着环形磁道
- 每条磁道上有多个扇区,每个扇区由间隙隔开

- 对齐的磁道形成一个柱面
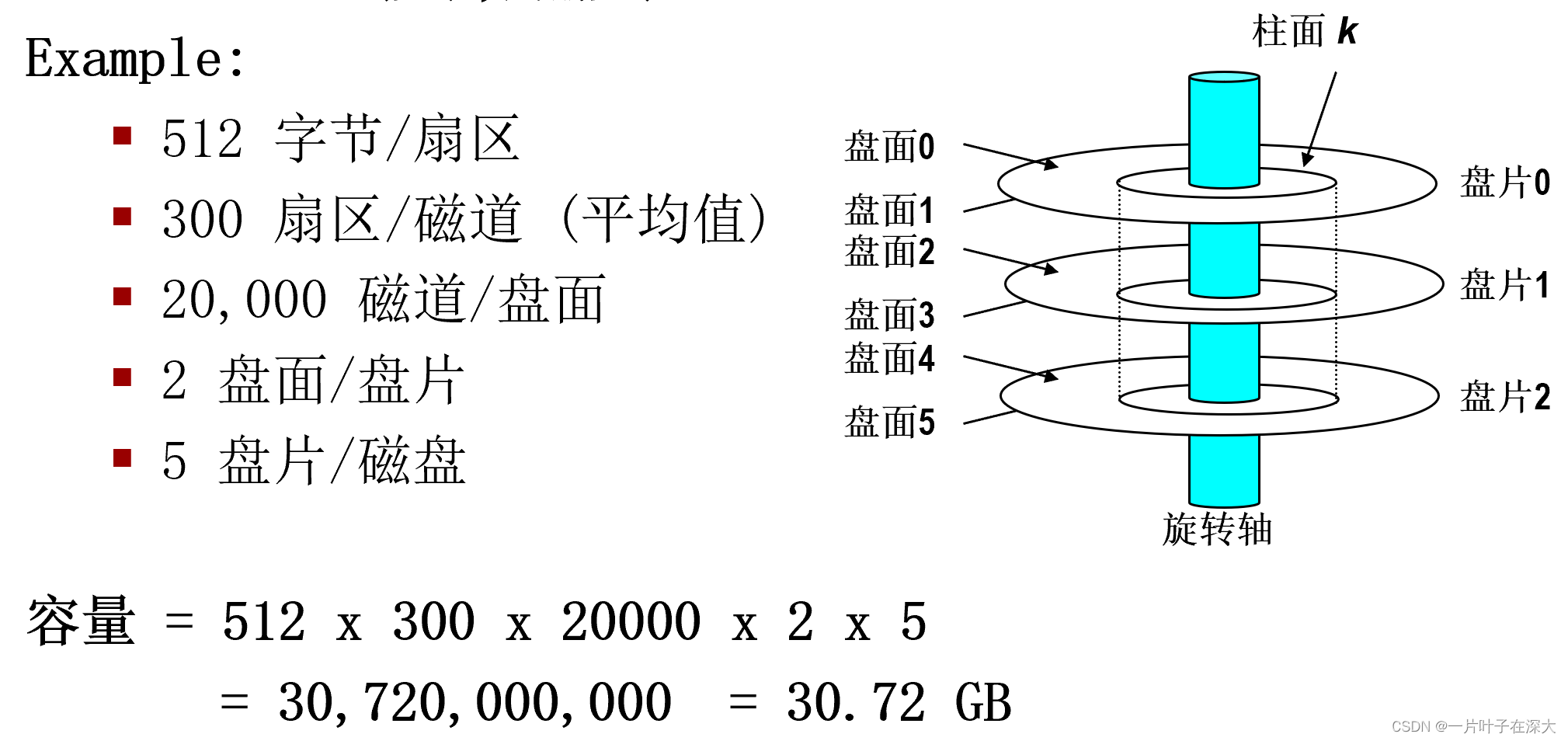
磁盘容量
- 容量: 可存储的最多比特数
- 销售商以10进制度量存储大小,即1 GB = 109 Bytes
- 容量参数
- 记录密度(位/英寸):
- 一英寸磁道可存储的比特数
- 磁道密度 (道/英寸):
- 一英寸半径可排布的磁道数
- 面密度 (位/平方英寸):
- 记录密度与磁道密度的乘积
- 记录密度(位/英寸):
容量 =(字节数/扇区)×(平均扇区数/磁道)×(磁道数/盘面)×(盘面数/盘片)×(盘片/磁盘)
磁盘访问
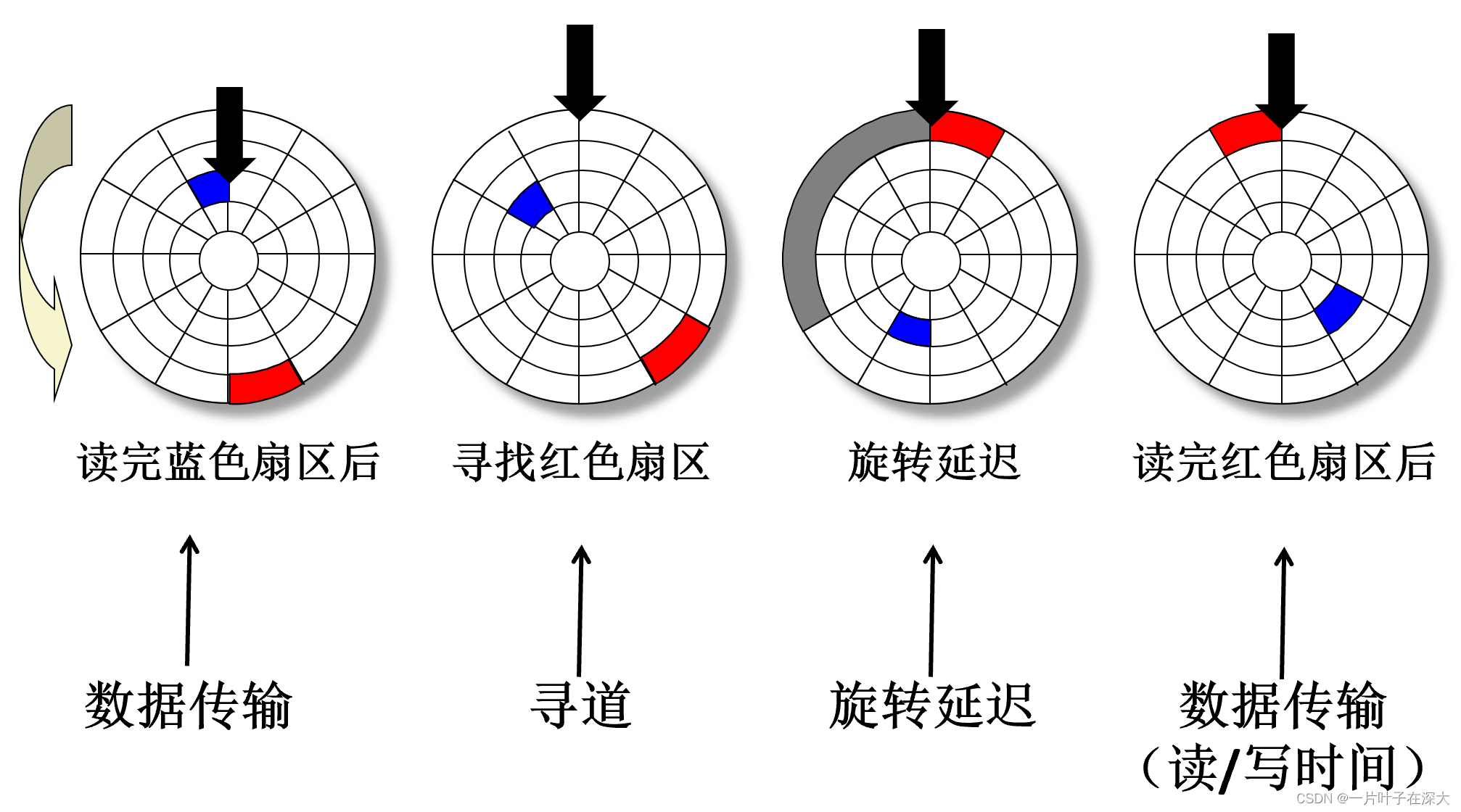
- 访问某个扇区的平均时间为 :
- 访问时间 = 寻道时间 + 旋转时间 + 数据传输时间
- 寻道时间
- 磁头由一个柱面移动到另一个柱面的时间
- 通常寻道时间为: 3—9 ms
- 旋转时间
- 经过磁盘旋转,目标扇区到达磁头下的时间
- 最大旋转延迟 = 1/RPMs x 60 sec/1 min
- 平均旋转延迟 = 0.5 x 最大旋转延迟
- 通常旋转时间 = 7200 RPMs
- 数据传输时间
- 传输每个扇区所需时间
- 数据传输时间 = 1/RPM x 1/(平均扇区数/磁道) x 60 秒/1 分钟.
磁盘访问时间示例
- 给定条件:
- 旋转速度 = 7,200 RPM
- 平均寻道时间 = 9 ms.
- 平均扇区数/磁道 = 400.
- 计算结果:
- 平均旋转时间 = 1/2 x (60 secs/7200 RPM) x 1000 ms/sec ≈ 4 ms.
- 数据传输时间 = 60/7200 RPM x 1/400 secs/track x 1000 ms/sec ≈ 0.02 ms
- 服务总时间 = 9 ms + 4 ms + 0.02 ms = 13.02 ms
- 重点:
- 访问时间主要由寻道时间和旋转时间组成.
- 访问扇区的第一个bit比较消耗时间,剩余bit较快.
- SRAM 访问时间为 4 ns/双字, DRAM 为 60 ns/双字
- 磁盘比SRAM慢4,0000倍,
- 磁盘比 DRAM慢2500倍.
局部性
局部性原理:
程序倾向于使用最近一段时间,距离其较近地址的数据和指令。
时间局部性:
最近被访问的数据或指令在未来可能还会被访问。
空间局部性:
当前访问地址附近的区域在不久还有可能被访问。
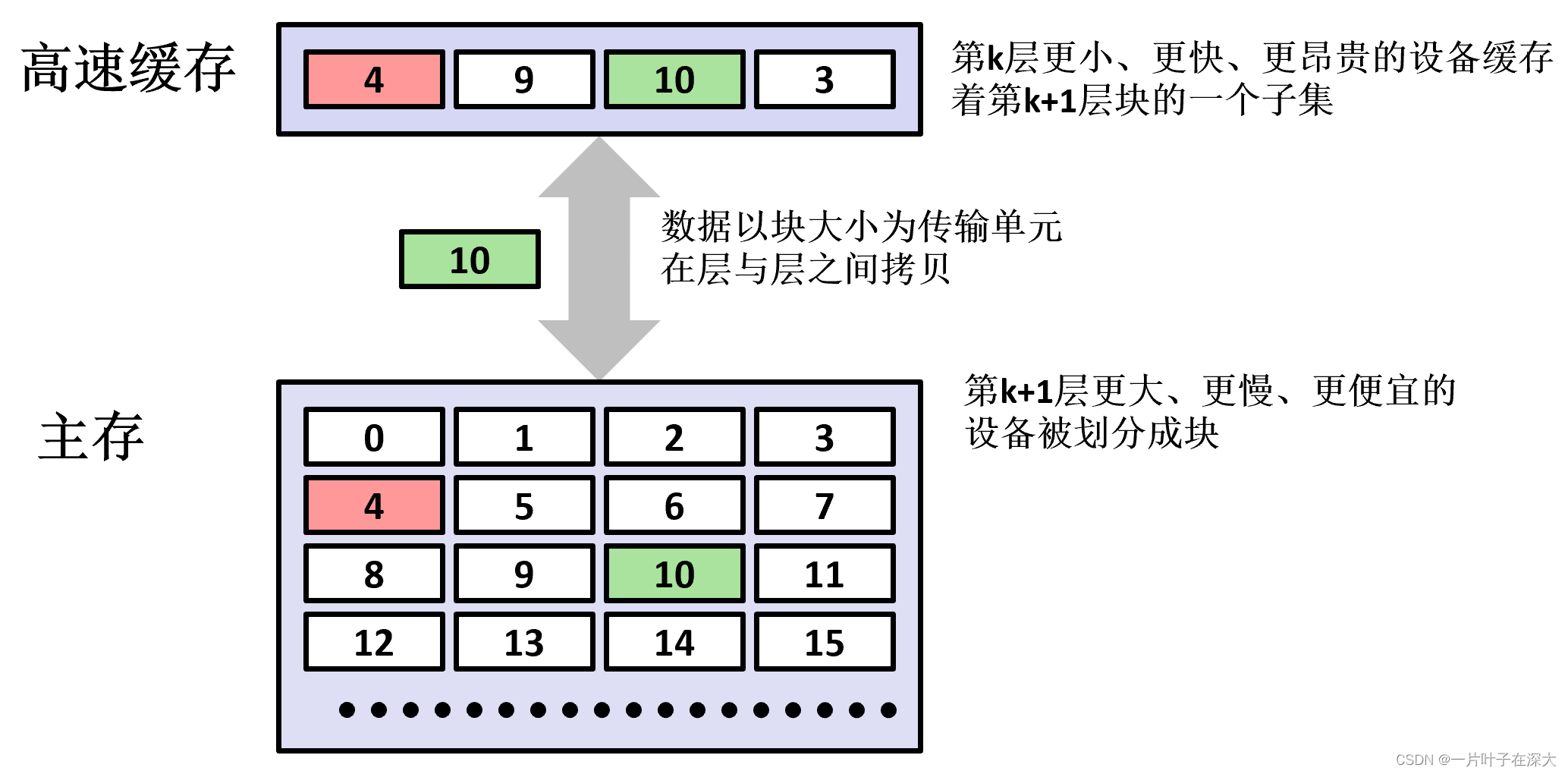
存储器层次结构

高速缓存
缓存不命中
- 冷不命中(或强制性不命中)
- 由于高速缓存开始为空并且这是对块的第一次引用,所以发生冷不命中。
- 容量不命中
- 当一组活动缓存块(工作集)大于缓存时发生
- 冲突不命中
- 大多数高速缓存将第k+1层的某个块限制放置在第k层块的一个小的子集中(有时只是一个块)
- 例如,第k+1层的块i必须放置在第k层的块(i mod 4)中
- 当第k层的缓存足够大,但多个数据对象映射到同一个缓存块中时发生冲突不命中
- 例如,每次引用块0, 8, 0, 8, 0, 8, ... 都会错过
- 大多数高速缓存将第k+1层的某个块限制放置在第k层块的一个小的子集中(有时只是一个块)
Cache的命中率:在一个程序执行期间,设Nc表示cache完成存取的总次数,Nm表示主存完成存取的总次数,h定义为命中率。
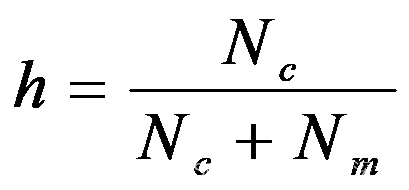
平均访问时间:若tc表示命中时的Cache访问时间,tm表示未命中时的主存访问时间,1-h表示未命中率,则Cache/主存系统的平均访问时间ta为 ta= h tc + (1 - h) tm
- 某计算机系统的内存储器由cache和主存构成,cache的存取周期为45ns,主存的存取周期为200ns。已知在一段给定的时间内,CPU共访问内存4500次,其中340次访问主存。问:
- Cache的命中率是多少?
- Cpu访问内存的平均时间是多少纳秒?
- Cache-主存系统的效率是多少?
解:
1、cache的命中率
- h=Nc/(Nc+Nm)=(4500-340)/4500=0.92
2、cpu访存的平均时间
- ta=htc+(1-h)tm=0.92 ×45+(1-0.92) ×200=57.4[ns]
3、cache-主存系统的效率
- e=tc/ ta=45/57.4=0.78=78%
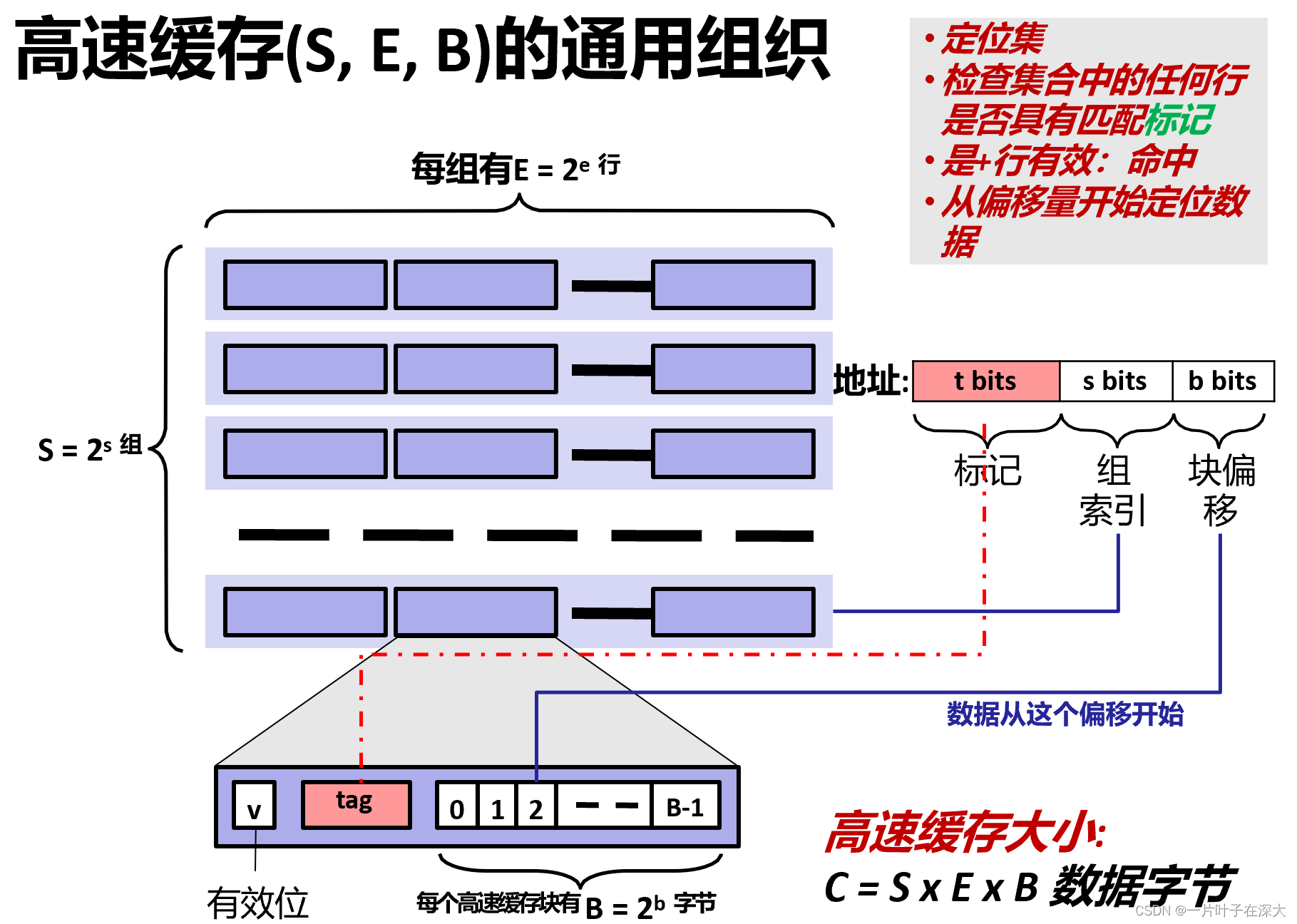
Cache映射
把主存空间划分成大小相等的主存块(Block)。
Cache中存放一个主存块的对应单位称为槽(Slot)或行(line),有书中也称之为块(Block),有书称之为页(page)(不妥!)。
将主存块和Cache行按照以下三种方式进行映射
直接相联(Direct):每个主存块映射到Cache的固定行。
全相联(Full Associate):每个主存块映射到Cache的任一行。
组相联(Set Associate):每个主存块映射到Cache固定组中任一行。
链接
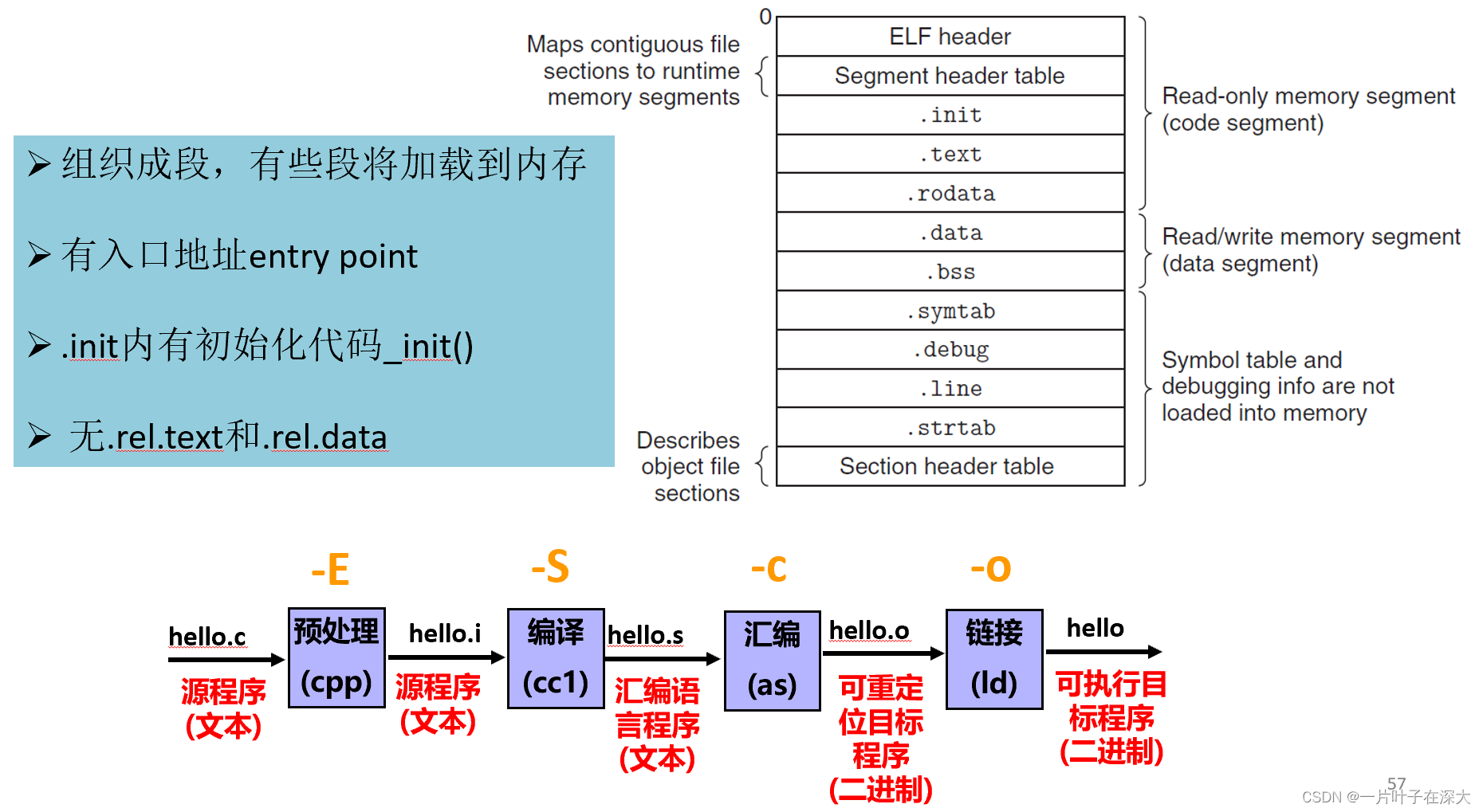
编译器驱动程序
编译过程
预处理
预处理是在编译之前的一个阶段,它主要负责处理源代码中的预处理指令。预处理器会根据预处理指令进行相应的处理,最常见的预处理指令是以"#"开头的指令,如包含文件指令(#include)、宏定义指令(#define)等。预处理器会根据这些指令将相应的代码插入到源代码中,生成被处理过的新的源代码文件。
编译
编译是将预处理过后的源代码翻译成汇编语言的过程。编译器会对源代码进行词法分析、语法分析和语义分析等操作,然后将源代码转换成中间代码或者汇编代码。中间代码是一种机器无关的代码表示形式,而汇编代码则是与特定的硬件平台相关联的低级代码。
汇编
汇编是将汇编代码转化为机器码的过程。汇编器将汇编代码逐行翻译成与特定处理器相关的二进制指令,这些指令可以被计算机直接执行。每个汇编语句通常对应着一条机器指令,包括操作码和操作数等。
链接
链接是将多个目标文件与库文件链接在一起,形成最终的可执行文件。在编写复杂程序时,往往会将不同的源代码文件分别编译成目标文件,然后通过链接器将这些目标文件以及所需的库文件链接在一起。链接器会解析目标文件之间的引用关系,将它们合并成一个完整的可执行文件。在链接过程中,还会进行地址分配、重定位和符号解析等操作。
静态链接与动态链接
完成两个任务:符号解析与重定位。
符号解析:
建立符号引用和定义之间的联系。
重定位:
为每一个引用确定地址。
链接时间:编译时、加载时、运行时。
目标文件
可重定位目标文件 (.o)
其代码和数据可和其他可重定位文件合并为可执行文件,每个.o 文件由对应的.c文件生成,每个.o文件代码和数据地址都从0开始。
可执行目标文件 (默认为a.out)
包含的代码和数据可以被直接复制到内存并被执行,代码和数据地址为虚拟地址空间中的地址。
共享的目标文件 (.so)
特殊的可重定位目标文件,能在装入或运行时被装入到内存并自动被链接,称为共享库文件,Windows 中称其为 Dynamic Link Libraries (DLLs)。
可执行可链接格式
Executable and linkable format,ELF。
可重定位目标文件

.text:已编译程序的机器代码。
.rodata:只读数据。
.data:已初始化的全局和静态C变量。
.bss:未初始化的全局和静态C变量,以及所有被初始化为0的全局或静态变量。
.symtab:符号表,存放函数和全局变量的信息。
.rel.text:文本部分的重新定位信息,修改指令的地址。
.rel.data:数据段的重新定位信息,修改指针数据的地址。
符号和符号表
全局符号
由本模块定义并且能被其他模块引用的,对应于非静态的函数和全局变量。
外部符号
由其他模块定义并且能被本模块引用的,对应于在其他模块定义的非静态函数和全局变量。
局部符号
只能被本模块定义和引用的局部符号,对应于静态函数和全局变量。
符号解析
作用
将每个符号引用与它输入的可重定位目标文件的符号表中的一个确定的符号定义关联起来。
强符号
函数和已经初始化的全局变量。
弱符号
未初始化的全局变量。
规则
- 不允许存在同名强符号。
- 如果强符号和弱符号同名,选择强符号。
- 如果弱符号同名,任意选择一个弱符号。
静态库链接
静态库
定义
将相关可重定位目标模块打包成一个单独的文件。
数据结构:
维护三个动态变化的集合E、U和D
E:可重定位目标文件集合,被引用的目标文件将被拷贝到可执行文件中;
U:随着链接的展开而发现的未解析的符号集合,成功链接后最终该集合为空;
D:所有输入文件中已解析的符号集合;
算法要点:
1)初始化E/U/D为空;
2)逐个扫描命令行给出的文件f;
a)f是目标文件: E = E U {f},D = D U {f中的已定义符号},
重定位表项对应的符号与D进行匹配,未匹配的加入到U;
b)f是静态库,将U中的符号与f定义的符号相匹配,存在匹配模块m上的符号,E = E U {m},否则丢弃该库。
3)扫描结束
U非空:链接失败,将U未能解析的符号输出给用户。
U为空,链接成功,布局E中模块拼接成可执行文件,完成符号解释和重定位。
重定位
重定位由两步组成:重定位节和符号定义,重定位节中的符号引用。
重定位节和符号定义
赋予指令和全局变量唯一的运行时内存地址。
重定位节中的符号引用
修改代码节和数据节中符号的引用,使其指向正确的运行地址。
可执行目标文件
加载可执行目标文件
了解LINUX运行时存储器映像。

动态链接共享库
静态库的不足
- 库函数被复制到每个运行进程的代码段,对于并发运行上百个进程的系统,造成内存空间的极大浪费。
- 库函数被合并到可执行目标文件中,磁盘上存放着数千个可执行文件,造成磁盘空间的极大浪费。
- 程序员需关注是否有函数库的新版本出现,并须定期下载、重新编译和链接,使用不便且编译耗时。
动态链接共享库(shared library,又称共享库或动态链接库)
- 目标文件,包含有代码和数据。
- 从程序中分离出来,磁盘和内存中都只有一个备份。
- 可在装入时或运行时被动态加载并链接。
- Window称其为动态链接库(Dynamic Link Libraries,.dll文件)。
- Linux称其为动态共享对象( Dynamic Shared Objects, .so文件)。