原文链接:https://developers.google.com/web/updates/2019/08/get-started-with-gpu-compute-on-the-webundefined作者:François Beaufort
本文是关于我使用实验性的WebGPU API并与有兴趣使用GPU进行数据并行计算的Web开发人员分享我的旅程。
背景
众所周知,图形处理单元(GPU)是计算机中最初专用于处理图形的一个电子子系统。但是,在获取的10年里,GPU利用其独特的架构已经发展成为一种不仅能渲染3D图形,也允许开发人员实现多种类型算法的更加灵活的架构。这些功能称为GPU计算,将GPU用作通用科学计算的协处理器称为通用GPU(GPGPU)编程。
GPU计算为最近的机器学习热潮做出了重要贡献,因为卷积神经网络和其他模型可以利用该架构在GPU上更高效地运行。由于当前的Web平台缺乏GPU计算功能,W3C的“ Web上的GPU”社区小组正在设计一种API,为当前大多数设备上提供可用的现代GPU API。该API称为WebGPU。
WebGPU是一个低级API,例如WebGL。如你所见,其非常强大且冗长。但是没关系我们更在乎的是性能。
在本文中,我将重点介绍WebGPU的GPU计算部分,老实说,我讲的会比较浅,让你可以自己开始玩就可以了。下一篇文章中我将更深入地探讨WebGPU渲染(画布,纹理等)。
PS: 目前,WebGPU已在Chrome 78实验性功能提供了。你可以在
chrome://flags/#enable-unsafe-webgpu来开启它。它还处在实验阶段,API可能会不断变化,目前使用很不安全。由于尚未为WebGPU API实现GPU沙箱,因此可以读取其他进程的GPU数据!故不要在启用网络的情况下浏览网络。
访问GPU
在WebGPU中访问GPU很容易。调用navigator.gpu.requestAdapter(),该方法将会返回一个在解决时返回一个GPU adaptor的JavaScript promise。可以把返回的adaptor看做GPU。它既可以是集成GPU(与CPU在同一芯片上),也可以是独立GPU(通常是性能更高但功耗更高的PCIe卡)。
有了GPU适配器后,调用adapter.requestDevice()来获得一个promise,通过该promise可以得到一个能够用于执行一些GPU计算的GPU device。
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();如果你想的话,这两个方法都可以通过传入参数,来具体确定所需的适配器类型(电源偏好)和设备(扩展,限制)。为了简单起见,我们将在本文中使用默认选项。
写入缓冲存储器
让我们看看如何使用JavaScript将数据写入GPU的内存。由于现代网络浏览器中使用的沙箱模型,因此此过程并不简单。
下面的示例展示了如何将四个字节写入可从GPU访问的缓冲存储器。调用device.createBufferMappedAsync()来获取缓冲区的大小及其用法。即使此特定调用不需要指定标识GPUBufferUsage.MAP_WRITE,这里也要明确要数据将写入此缓冲区。最后通过promise来返回GPU缓冲区对象和它的原始二进制数据缓冲区。
如果您已经使用过ArrayBuffer,写入字节应该会很容易;使用TypedArray并将值复制过来。
// Get a GPU buffer and an arrayBuffer for writing. // Upon success the GPU buffer is put in the mapped state. const [gpuBuffer, arrayBuffer] = await device.createBufferMappedAsync({ size: 4, usage: GPUBufferUsage.MAP_WRITE });
// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);
此时,GPU缓冲区映射到了CPU中,并且可以通过JavaScript进行读取/写入。为了使GPU能够访问它,必须调用gpuBuffer.unmap()将其取消映射。
使用映射/未映射的概念可以防止GPU和CPU同时访问内存的竞争情况。
读取缓冲存储器
现在,让我们看看如何将一个GPU缓冲区复制到另一个GPU缓冲区并读取出来。
由于我们正在写入第一个GPU缓冲区,并且希望将其复制到第二个GPU缓冲区,因此需要一个新的使用标志GPUBufferUsage.COPY_SRC。device.createBuffer()可以同步地创建出处于未映射状态的第二个GPU缓冲区。这里使用标志是GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ,因为它将用作第一个GPU缓冲区的目标,并在执行了GPU复制命令后就读入JavaScript。
// Get a GPU buffer and an arrayBuffer for writing.
// Upon success the GPU buffer is returned in the mapped state.
const [gpuWriteBuffer, arrayBuffer] = await device.createBufferMappedAsync({
size: 4,
usage: GPUBufferUsage.MAP_WRITE | GPUBufferUsage.COPY_SRC
});// Write bytes to buffer.
new Uint8Array(arrayBuffer).set([0, 1, 2, 3]);// Unmap buffer so that it can be used later for copy.
gpuWriteBuffer.unmap();
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: 4,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});
由于GPU是独立的协处理器,所有GPU命令都是异步执行的。这就是为什么需要构建并批量发送GPU命令的列表的原因。在WebGPU中,由device.createCommandEncoder()方法返回的GPU命令编码是构建一批“缓冲”命令的JavaScript对象,这些命令将在某个时候发送到GPU。另一方面,GPUBuffer上的方法是“未缓冲的”,这意味着它们在被调用时会自动执行。
有了GPU命令编码器后,如下所示调用copyEncoder.copyBufferToBuffer()将此命令添加到命令队列中以供以后执行。最后,通过调用copyEncoder.finish()完成编码命令,将其提交到GPU设备命令队列。该队列负责处理通过device.getQueue().submit()完成提交的,改方法以GPU命令作为参数。队列中的命令将按照顺序执行。
// Encode commands for copying buffer to buffer.
const copyEncoder = device.createCommandEncoder();
copyEncoder.copyBufferToBuffer(
gpuWriteBuffer /* source buffer /,
0 / source offset /,
gpuReadBuffer / destination buffer /,
0 / destination offset /,
4 / size */
);
// Submit copy commands.
const copyCommands = copyEncoder.finish();
device.getQueue().submit([copyCommands]);
需要注意,已发送的GPU队列命令,不一定会执行。通过调用gpuReadBuffer.mapReadAsync()可以读取第二个GPU缓冲区。它返回一个promise,一旦所有排队的GPU命令都已执行,它将使用包含与第一个GPU缓冲区相同的值的ArrayBuffer进行解析。
// Read buffer.
const copyArrayBuffer = await gpuReadBuffer.mapReadAsync();
console.log(new Uint8Array(copyArrayBuffer));你可以试试这个简单的例子。
简而言之,下面是关于缓冲存储器的操作你需要记住的:
- 必须取消映射GPU缓冲区才能在设备队列提交中使用。
- 映射后,可以使用JavaScript读写GPU缓冲区。
- 调用
mapReadAsync()、mapWriteAsync()、createBufferMappedAsync()和createBufferMapped()可以映射GPU缓冲区。
着色器编程
在GPU上运行的仅执行计算(而不绘制三角形)的程序称为计算着色器。它们由数百个GPU内核(小于CPU内核)并行执行,这些GPU内核共同操作以处理数据。它们输入、输出到WebGPU中的缓冲区。
为了说明计算着色器在WebGPU中的使用,我们将尝试下矩阵乘法,这是机器学习中的一种常见算法,如下所示。
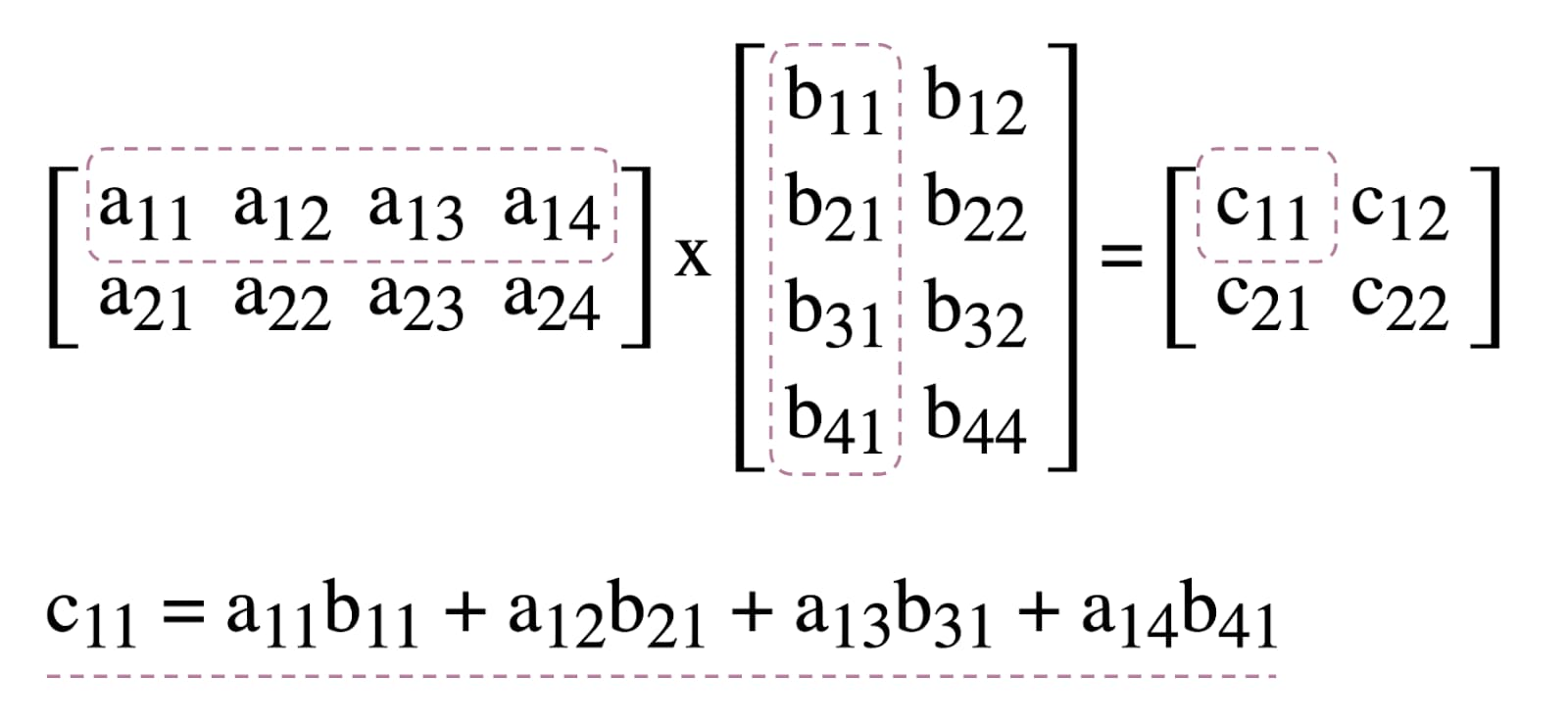
Figure 1. Matrix multiplication diagram
简而言之,我们要做的如下:
- 创建三个GPU缓冲区(两个用于矩阵相乘,一个用于结果矩阵)
- 描述计算着色器的输入和输出
- 编译计算着色器代码
- 设置计算管道
- 批量提交编码后的命令到GPU
- 读取结果矩阵GPU缓冲区
创建GPU缓冲区
为了简单起见,矩阵将表示为浮点数列表。第一个元素是行数,第二个元素是列数,其余是矩阵的元素。

Figure 2. Simple representation of a matrix in JavaScript and it's equivalent in mathematical notation
这三个GPU缓冲区是存储缓冲区,因为我们需要在计算着色器中存储和检索数据。这就是为什么我们使用GPUBufferUsage.STORAGE标志位来创建GPU缓冲区。结果矩阵使用标志GPUBufferUsage.COPY_SRC,因为一旦所有GPU队列命令全部执行完毕,它将被复制到另一个缓冲区以进行读取。
const adapter = await navigator.gpu.requestAdapter();
const device = await adapter.requestDevice();// First Matrix
const firstMatrix = new Float32Array([
2 /* rows /, 4 / columns */,
1, 2, 3, 4,
5, 6, 7, 8
]);const [gpuBufferFirstMatrix, arrayBufferFirstMatrix] = await device.createBufferMappedAsync({
size: firstMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
new Float32Array(arrayBufferFirstMatrix).set(firstMatrix);
gpuBufferFirstMatrix.unmap();// Second Matrix
const secondMatrix = new Float32Array([
4 /* rows /, 2 / columns */,
1, 2,
3, 4,
5, 6,
7, 8
]);const [gpuBufferSecondMatrix, arrayBufferSecondMatrix] = await device.createBufferMappedAsync({
size: secondMatrix.byteLength,
usage: GPUBufferUsage.STORAGE,
});
new Float32Array(arrayBufferSecondMatrix).set(secondMatrix);
gpuBufferSecondMatrix.unmap();// Result Matrix
const resultMatrixBufferSize = Float32Array.BYTES_PER_ELEMENT * (2 + firstMatrix[0] * secondMatrix[1]);
const resultMatrixBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.STORAGE | GPUBufferUsage.COPY_SRC
});
绑定组布局和绑定组
绑定组布局和绑定组的概念特定于WebGPU。绑定组布局定义了着色器所需的输入/输出接口,而绑定组表示着色器的实际输入/输出数据。
在下面的示例中,绑定组布局期望计算着色器的编号绑定0、1和2处有一些存储缓冲区。另一方面,为此绑定组布局定义的绑定组将GPU缓冲区与绑定关联:gpuBufferFirstMatrix绑定到绑定0,gpuBufferSecondMatrix绑定到绑定1,resultMatrixBuffer绑定到绑定2。
const bindGroupLayout = device.createBindGroupLayout({
bindings: [
{
binding: 0,
visibility: GPUShaderStage.COMPUTE,
type: "storage-buffer"
},
{
binding: 1,
visibility: GPUShaderStage.COMPUTE,
type: "storage-buffer"
},
{
binding: 2,
visibility: GPUShaderStage.COMPUTE,
type: "storage-buffer"
}
]
});
const bindGroup = device.createBindGroup({
layout: bindGroupLayout,
bindings: [
{
binding: 0,
resource: {
buffer: gpuBufferFirstMatrix
}
},
{
binding: 1,
resource: {
buffer: gpuBufferSecondMatrix
}
},
{
binding: 2,
resource: {
buffer: resultMatrixBuffer
}
}
]
});
计算着色器代码
用于乘法矩阵的计算着色器代码用GLSL编写,GLSL是WebGL中使用的高级着色语言,其语法基于C编程语言。无需赘述,你应该能在下面找到三个用关键字buffer标记的存储缓冲区。该程序使用firstMatrix和secondMatrix作为输入,并使用resultMatrix作为其输出。
请注意,每个存储缓冲区都有一个binding限定符,该限定符与在上面声明的绑定组布局和绑定组中定义的相同索引相对应。
const computeShaderCode = `#version 450layout(std430, set = 0, binding = 0) readonly buffer FirstMatrix {
vec2 size;
float numbers[];
} firstMatrix;layout(std430, set = 0, binding = 1) readonly buffer SecondMatrix {
vec2 size;
float numbers[];
} secondMatrix;layout(std430, set = 0, binding = 2) buffer ResultMatrix {
vec2 size;
float numbers[];
} resultMatrix;void main() {
resultMatrix.size = vec2(firstMatrix.size.x, secondMatrix.size.y);ivec2 resultCell = ivec2(gl_GlobalInvocationID.x, gl_GlobalInvocationID.y); float result = 0.0; for (int i = 0; i < firstMatrix.size.y; i++) { int a = i + resultCell.x * int(firstMatrix.size.y); int b = resultCell.y + i * int(secondMatrix.size.y); result += firstMatrix.numbers[a] * secondMatrix.numbers[b]; } int index = resultCell.y + resultCell.x * int(secondMatrix.size.y); resultMatrix.numbers[index] = result;
}
`;
设置管道
Chrome中的WebGPU当前使用字节码代替原始的GLSL代码。这意味着我们必须在运行计算着色器之前编译computeShaderCode。幸运的是,@webgpu/glslang包使我们能够以Chrome中的WebGPU接受的格式编译computeShaderCode。该字节码是格式基于SPIR-V的安全子集。
注意,“WebGPU” W3C社区组仍未决定编写WebGPU的着色语言。
import glslangModule from 'https://unpkg.com/@webgpu/glslang@0.0.8/dist/web-devel/glslang.js';计算管道是实际描述我们将要执行的计算操作的对象。通过调用device.createComputePipeline()创建。该方法包含两个参数:我们之前创建的绑定组布局,以及一个计算阶段,该阶段定义了我们的计算着色器(主要GLSL函数)和使用glslang.compileGLSL()编译的实际计算着色器模块的入口点。
const glslang = await glslangModule();
const computePipeline = device.createComputePipeline({
layout: device.createPipelineLayout({
bindGroupLayouts: [bindGroupLayout]
}),
computeStage: {
module: device.createShaderModule({
code: glslang.compileGLSL(computeShaderCode, "compute")
}),
entryPoint: "main"
}
});
提交命令
在使用我们的三个GPU缓冲区和具有绑定组布局的计算管道实例化绑定组之后,就该使用它们了。
让我们使用commandEncoder.beginComputePass()启动一个可编程计算过程编码器。我们将使用它来编码将执行矩阵乘法的GPU命令。通过passEncoder.setPipeline(computePipeline)设置其管道,并通过passEncoder.setBindGroup(0, bindGroup)在索引0处设置其绑定组。索引0对应于GLSL代码中的set = 0限定符。
现在,让我们讨论一下此计算着色器将如何在GPU上运行。我们的目标是逐步针对结果矩阵的每个单元并行执行此程序。例如,对于2乘4大小的结果矩阵,我们将调用passEncoder.dispatch(2,4)来编码执行命令。第一个参数“ x”是第一个维度,第二个参数“ y”是第二个维度,最后一个参数“ z”是第三个维度,默认情况下为1,因为我们在这里不需要它。在GPU中,对在一组数据上执行内核功能的命令进行编码称为调度。
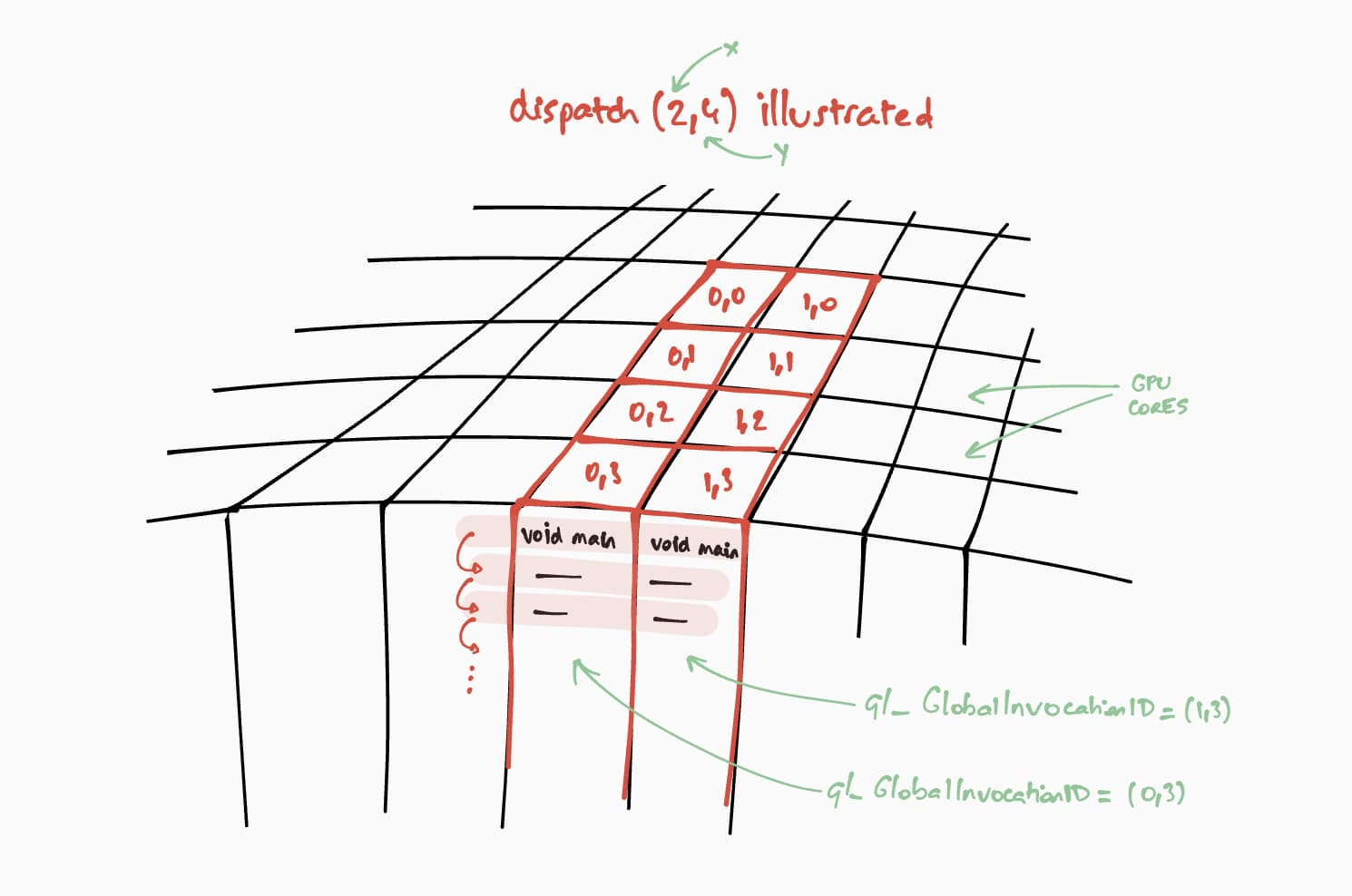
Figure 3. Execution in parallel for each result matrix cell
在我们的代码中,“ x”和“ y”将分别是第一个矩阵的行数和第二个矩阵的列数。这样,我们现在可以使用passEncoder.dispatch(firstMatrix [0],secondMatrix [1])调度计算调用。
如上图所示,每个着色器都可以访问唯一的gl_GlobalInvocationID对象,该对象将用于得到要计算的结果矩阵像元。
const commandEncoder = device.createCommandEncoder();
const passEncoder = commandEncoder.beginComputePass();
passEncoder.setPipeline(computePipeline);
passEncoder.setBindGroup(0, bindGroup);
passEncoder.dispatch(firstMatrix[0] /* x /, secondMatrix[1] / y */);
passEncoder.endPass();
可以通过调用passEncoder.endPass()来结束计算过程编码器。然后,创建一个GPU缓冲区用作目的地,以使用copyBufferToBuffer复制结果矩阵缓冲区。最后,使用copyEncoder.finish()完成编码命令,并通过使用GPU命令调用device.getQueue()。submit()将它们提交到GPU设备队列。
// Get a GPU buffer for reading in an unmapped state.
const gpuReadBuffer = device.createBuffer({
size: resultMatrixBufferSize,
usage: GPUBufferUsage.COPY_DST | GPUBufferUsage.MAP_READ
});// Encode commands for copying buffer to buffer.
commandEncoder.copyBufferToBuffer(
resultMatrixBuffer /* source buffer /,
0 / source offset /,
gpuReadBuffer / destination buffer /,
0 / destination offset /,
resultMatrixBufferSize / size */
);
// Submit GPU commands.
const gpuCommands = commandEncoder.finish();
device.getQueue().submit([gpuCommands]);
读取结果矩阵
读取结果矩阵就像调用gpuReadBuffer.mapReadAsync()并记录由结果promise返回的ArrayBuffer一样容易。
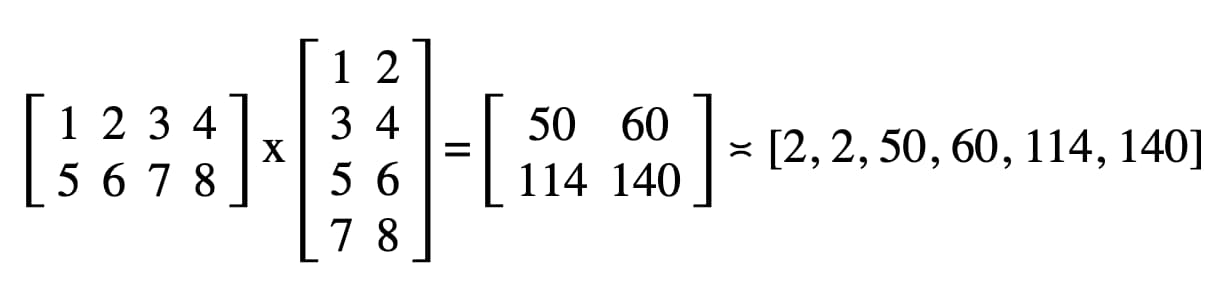
Figure 4. Matrix multiplication result
我们的代码在控制台中记录的结果是“ 2、2、50、60、114、140”。
// Read buffer.
const arrayBuffer = await gpuReadBuffer.mapReadAsync();
console.log(new Float32Array(arrayBuffer));恭喜你做到了。你可以看看这个示例。
性能
那么在GPU上运行矩阵乘法与在CPU上运行矩阵乘法相比又如何呢?为了找出答案,我编写了刚刚针对CPU编写的程序。如下图所示,当矩阵的大小大于256 x 256时,使用GPU是一个显而易见的选择。
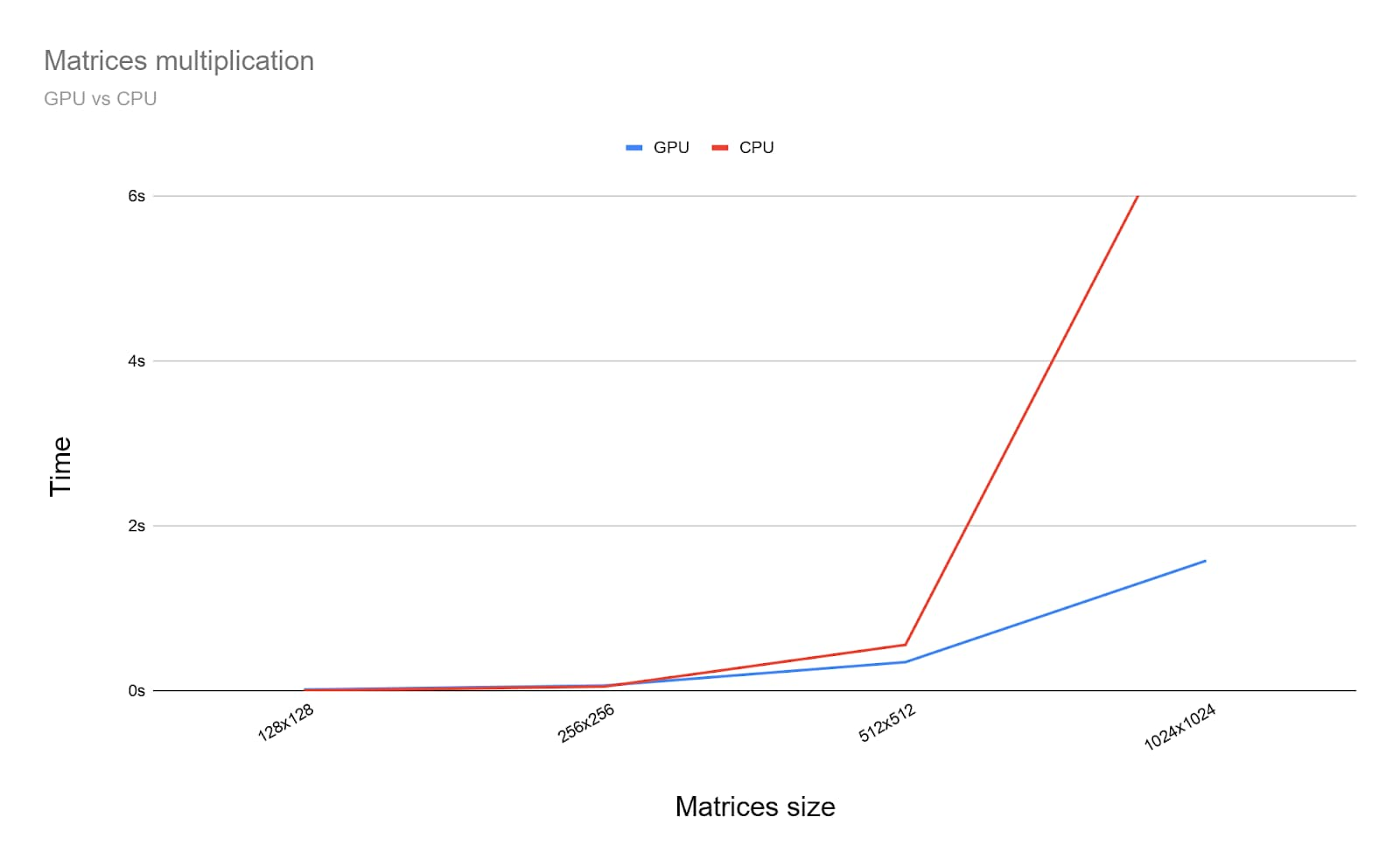
Figure 5. GPU vs CPU benchmark
本文只是我探索WebGPU的旅程的开始。很快就会有更多文章发表,它们将更深入地介绍GPU Compute,以及有关WebGPU中渲染(画布,纹理,采样器)的工作方式。