我们在之前的文章,《浅谈Elasticsearch Serverless设计与选择》 中提到过,云上许多数据存储和分析应用正在向 Serverless 模式进行转变。Serverless 是对专有的、需要自管理的集群模式的一种极大补充,特别是对于需要灵活应对需求和负载的变化又不希望预付服务器租赁费用,同时,又期望能够减少运维和管理成本的企业来说,Serverless 不仅便宜,而且更适合快速的构建业务和将产品推向市场,并提供更大的容错性和更低的试错成本。
但是选择使用 Serverless 和选择一个正确的 Serverless 服务则是两个不同的事情,前者是方向,后者是执行。在执行层面,我们有更多的东西需要去评估。对于 Elasticsearch 的 Serverless 服务来说,我们在选择时需要考虑可扩展性、可用性、灵活性、效率和安全性等基本因素,并且应该评估 Elasticsearch Serverless 是否具备缩放到零、按需计费、对现有集群模式进行抽象、屏蔽与隔离、保留核心API、明确主流使用场景、提供场景化方案和提供完整的Elastic Stack的Serverless等特性。
市场上给我们的选择不多,虽然大多数云厂商上也提供了号称兼容 Elasticsearch 的云搜索服务,但大多数都是7.10之前的版本,或者是直接使用 Opensearch,两者之间的性能差别可参阅《Elasticsearch 与 OpenSearch:详细对比性能差距》,而能够提供 Serverless 服务的厂商就更少。
而腾讯云在2023年8月1号发布了 Elasticsearch Service Serverless 服务,本文我们将在选择其中一些重要角度对其进行评估,以帮助用户对其有更深入的了解,以在技术选型时进行更全面的决策。
●缩放到零,按需计费 ●
Serverless 应用的核心优势在于用户只需在使用时付费,而不是预付服务器租赁费用。对于没有占用的资源,Serverless应该能够将其“释放”,并且不对用户收取费用。
●灵活场景下的费用对比 ●
为了更清楚的对比,我们选择自建ES集群与 Serverless 进行对比。对比中,Serverless 创建了多个索引,其中一个索引写入180GB数据,其余两个索引则是0数据。
从导出的费用清单上看,ES Serverless 是按量计费小时结,截止本文的时间8月15日12:00,有数据的Serverless 索引的存储费用在23.6元之内

图1
按照腾讯云 Elasticsearch Serverless 的计费项计算,即便算上流量费用,整个Serverless的花费在半个月间也仅在50元上下,而整月的费用则在75元左右。
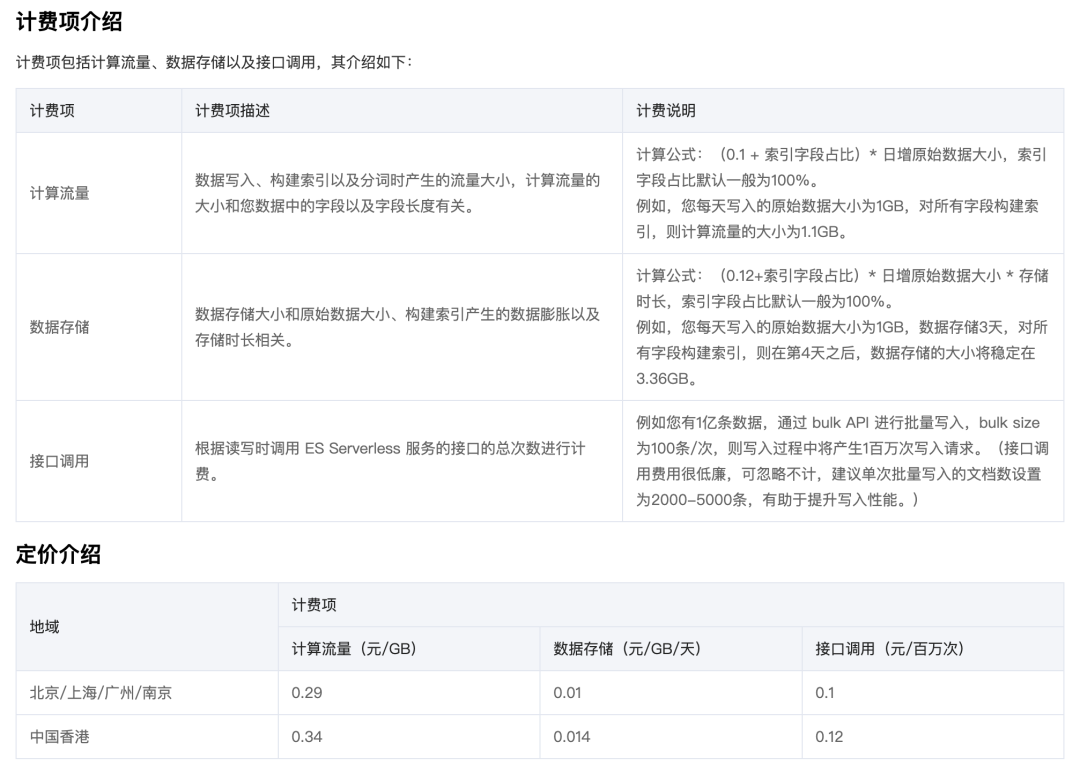
图2
而对于与没有数据的索引,则是完全将费用缩放到0元,同时,索引仍然处于随时可以访问和使用的状态!
而如果我们要自建一个承载对应数据的ES集群,即便是选择无高可用,无副本的单节点集群,参考Elastic官方的推荐配置,选择一个2C4GB的机器
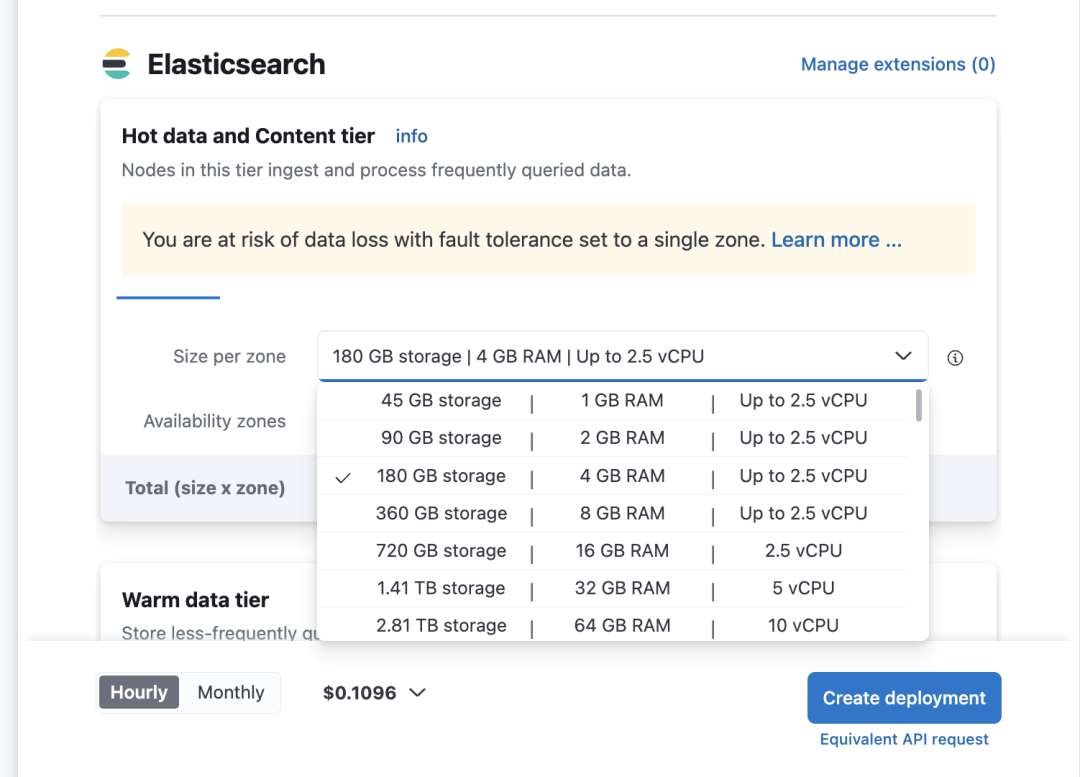
图3
而考虑到磁盘80%的水位控制,要存储180GB的数据,我们至少要220GB的磁盘,因此,自建集群在CVM上的费用大概为150元(在40%折扣下)

图4
因此,即便 Serverless 不打折(实际上会有和CVM类似的折扣),费用也仅仅是自建集群的50%。而一旦我们的业务有发生变化,无论是增加还是减少,Serverless 都能提供快速的灵活性,并且能够在一个小时内,体现在你的账单上。相对的,自建集群无论是扩容和缩容,都无法做到灵活和按需。
因此,对于大多数场景,Serverless 服务会表现出比自建集群更灵活和更低的成本。
●场景化的方案 ●
接下来,我们再看场景化的解决方案,Elasticsearch 作为一个通用搜索引擎和数据分析工具,广泛应用于搜索、企业搜索、日志分析、用户行为分析、全观测和安全分析等各种场景。但在不同场景下,Elasticsearch和整个Elastic Stack在部署拓扑结构、容量和资源大小配置、应用低级配置、数据类型与管理等方面都有所不同,需要有针对性的调整才能获得最高效的回报。因此,Elasticsearch Serverless 应该为用户提供对应的场景选择,并根据最佳实践配置场景对应所需的底层配置和管理。
而在腾讯云的 Elasticsearch Service Serverless 模式中,为用户提供了两个定制化的场景:
一、日志分析
二、实时搜索
目前,我们可以使用的是日志分析。而在日志分析场景中,我们从采集日志,到存储和分析日志,存在以下几个主要的工作:
1)日志采集:使用专门的工具或者框架,如Logstash、Beats、Flume等,从不同的数据源(如服务器、数据库、应用程序等)收集日志数据,并进行一定的过滤、转换和格式化,然后发送到Elasticsearch中。
2)日志存储:Elasticsearch是一个分布式的全文搜索和分析引擎,它可以接收日志数据,并将其存储在索引中。索引是一种数据结构,可以让Elasticsearch快速地对日志数据进行全文搜索和聚合分析 。Elasticsearch还提供了一些机制,如分片、副本、快照等,而日志存储的工作主要集中在,如何进行有效的数据治理来保证数据的可扩展性、高可用性和备份恢复能力 。
3)日志分析:Elasticsearch提供了丰富的查询语言和聚合功能,可以对日志数据进行多维度的检索和统计 。例如,可以根据关键字、时间范围、地理位置等条件进行过滤和排序,也可以根据字段值、数值范围、分布情况等进行分组和计算。在日志场景中,我们主要的工作在于日常的日志数据可视化分析,以及排障时的日志查询。
而在这几方面,腾讯云的 Elasticsearch Service Serverless 为用户提供的即插即用的能力包括:
日志采集:
1)支持无缝使用 ELK 中的采集框架,Logstash、Beats 等,可以从原有的 ELK 集群架构直接转到 Serverless 架构上。
# ============================== Filebeat inputs ===============================
filebeat.inputs:
- type: log
Change to true to enable this input configuration.
enabled: true
Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/*.log
============================== Filebeat modules ==============================
filebeat.config.modules:
Glob pattern for configuration loading
path: ${path.config}/modules.d/*.yml
Set to true to enable config reloading
reload.enabled: false
Period on which files under path should be checked for changes
#reload.period: 10s
======================= Elasticsearch template setting =======================
setup.template.enabled: false
setup.ilm.enabled: false
#template setting's value is set to false by default. If you set it to true, an error will be reported when the configuration is submitted
================================== General ===================================
The name of the shipper that publishes the network data. It can be used to group
all the transactions sent by a single shipper in the web interface.
#name:
The tags of the shipper are included in their own field with each
transaction published.
#tags: ["service-X", "web-tier"]
Optional fields that you can specify to add additional information to the
output.
#fields:
env: staging
================================= Processors =================================
processors:
- add_host_metadata:
when.not.contains.tags: forwarded
================================== Logging ===================================
Sets log level. The default log level is info.
Available log levels are: error, warning, info, debug
#logging.level: debug
At debug level, you can selectively enable logging only for some components.
To enable all selectors use ["*"]. Examples of other selectors are "beat",
"publisher", "service".
#logging.selectors: ["*"]
############################# output ######################################
output.elasticsearch:
Array of hosts to connect to.
allow_older_versions: true
protocol: "http"
hosts: ["索引内网访问地址"]
Authentication credentials - either API key or username/password.
username: "your index username"
password: "your index password"
indices:
index: The_index_name
when.equals:
fields.type: log
代码片段:可切换语言,无法单独设置文字格式
2)提供一键式的从不同的数据源(如CVM,TKE 等)收集日志数据,并进行一定的过滤、转换和格式化,然后发送到Elasticsearch中
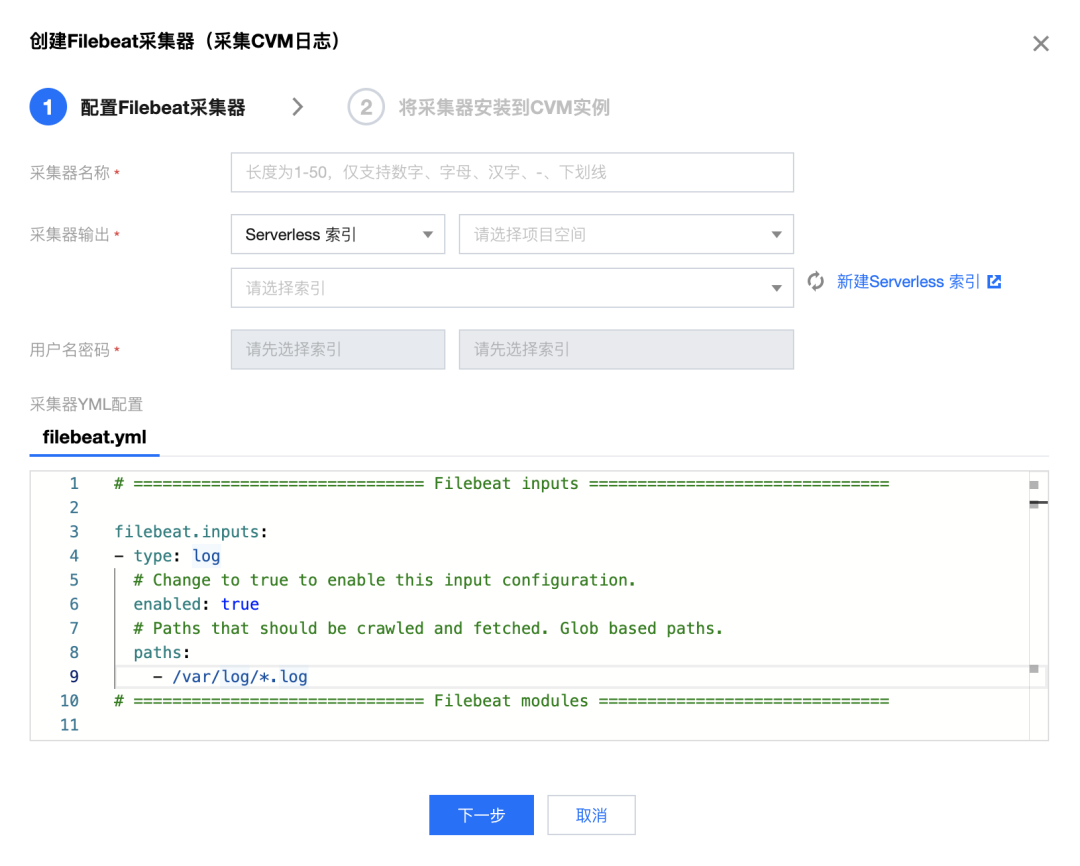
图5

图6
日志存储:
1)用户无需考虑底层的数据存储机制,如分片、副本、快照等,Elasticsearch Service Serverless 上创建的索引,自动使用腾讯云自研的自治索引功能,保证数据的可扩展性、高可用性和备份恢复能力 。无需考虑索引别名,索引生命周期管理,数据分层治理等复杂的运维工作。以上面的180GB的索引为例,我们可以看到,腾讯云 Elasticsearch Service Serverless 自动为我们根据数据大小创建自治索引,并自动的对背后的子索引进行滚动和切分:
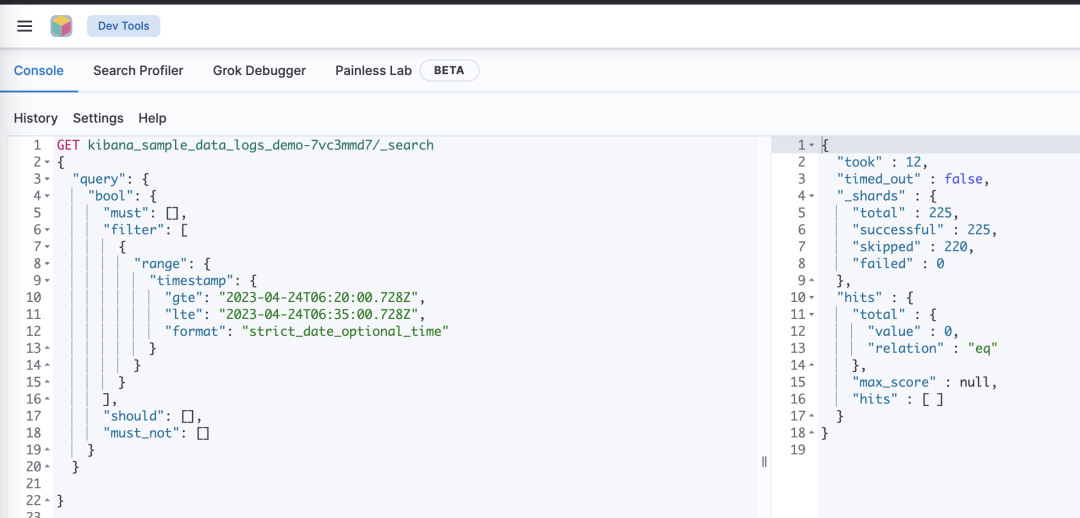
图7
2)同时,Serverless 会为我们屏蔽底层的物理细节,无需用户考虑应该使用什么计算资源和存储来适配不同使用生命周期的数据
日志分析:
腾讯云 Elasticsearch Service Serverless 为每个用户创建的所以提供了控制台上的索引查询界面。而如果有可视化的分析需求,也可以登录与其他索引隔离的 Kibana 用户界面,对数据进行深度检索和分析
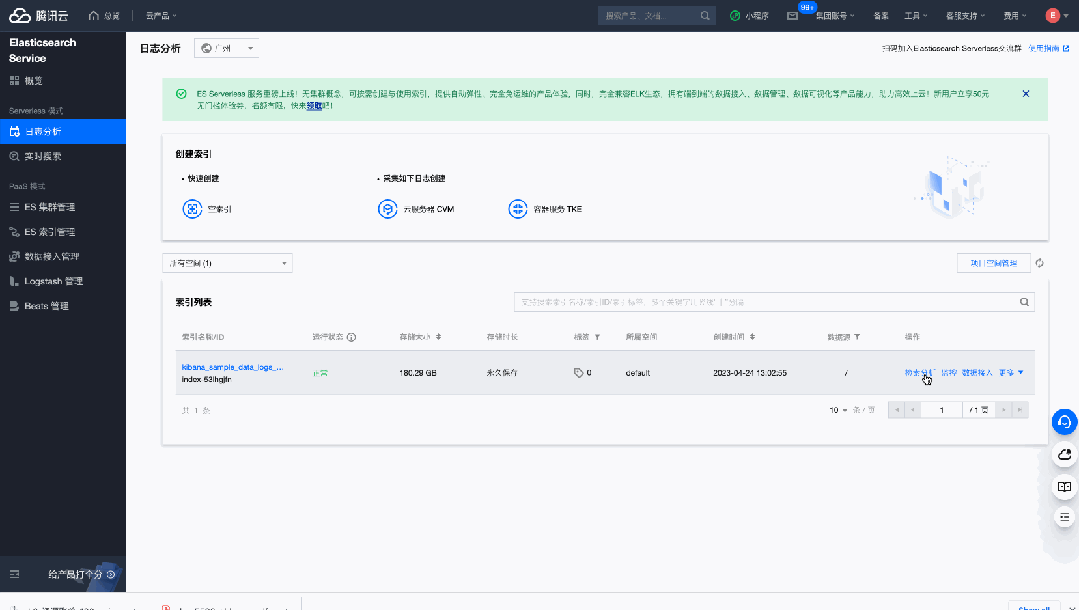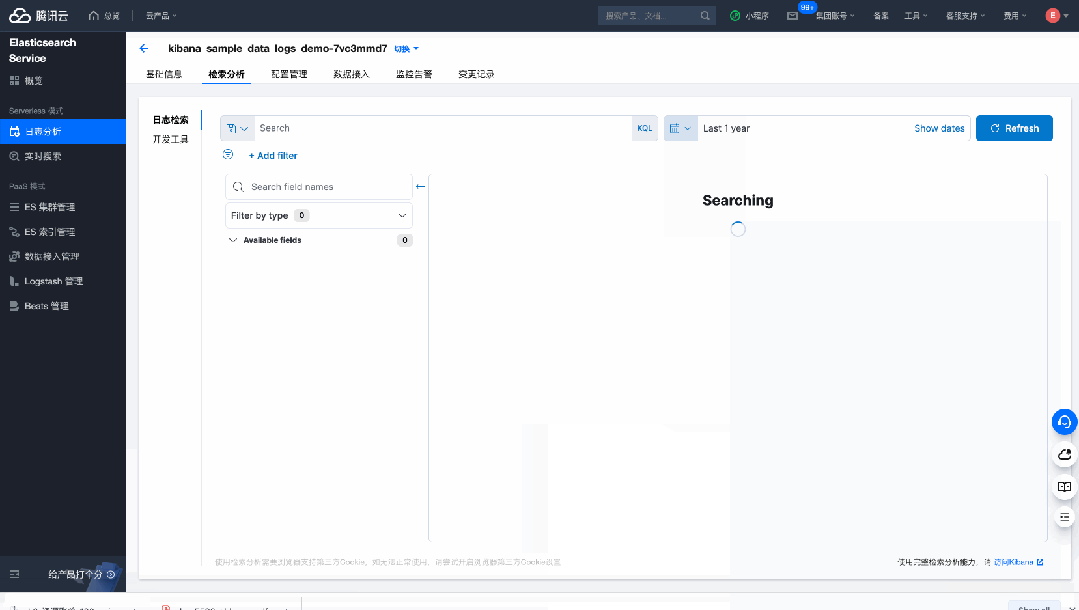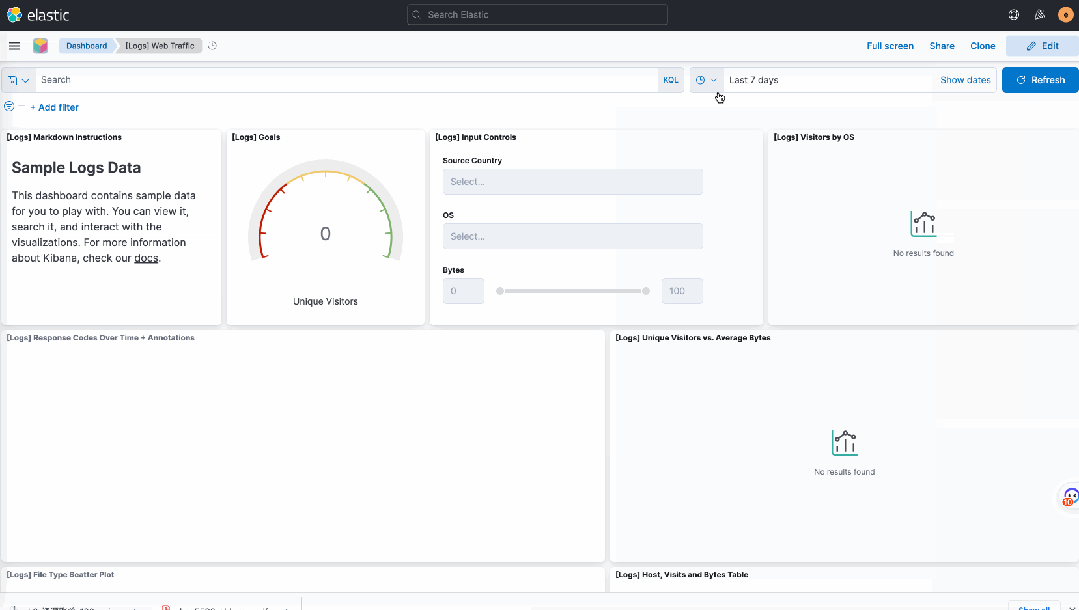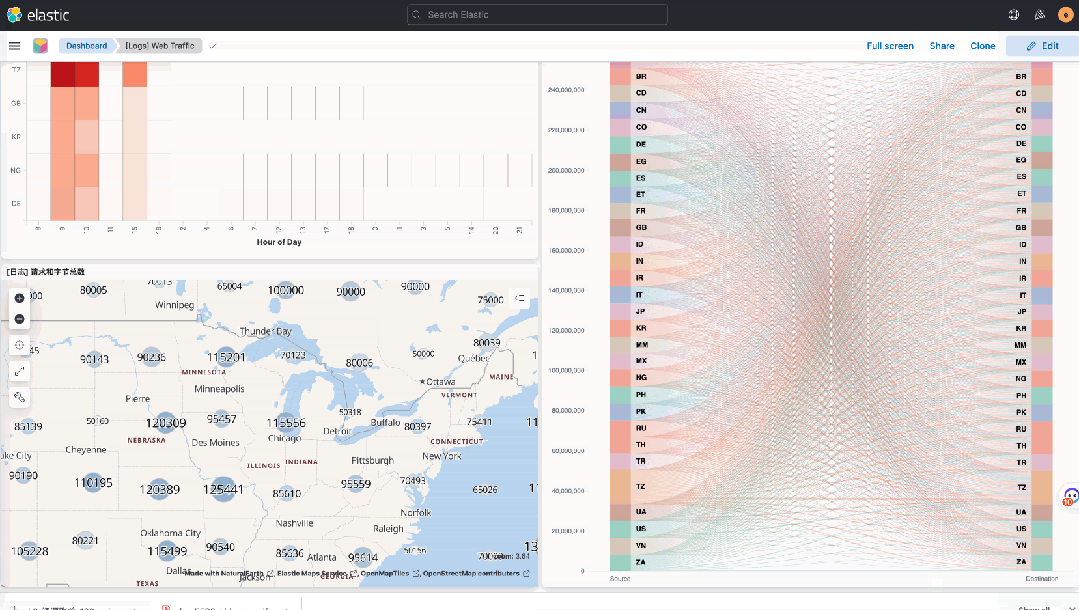
图8
●全托管的体验 ●
相对于需要自己管理的ES集群,越来越多的用户期望的是一个完全托管的体验,希望能从管理软件和操作系统版本、管理部署拓扑结构、管理容量和资源大小、应用低级配置(如某个线程池的大小)、管理高可用性、备份和持续的集群操作以及监测健康状况的负担中解放出来。
而在腾讯云 Elasticsearch Service Serverless 服务,则是从资源创建到运维,都在尽量减轻用户的负担,为全托管的方向进化。
在Serverless 模式下,只需要填写基础的名称、项目和网络信息即可快速创建一个可以用于写入和查询的索引:

图9
而在后期的使用和管理中,随着数据的增加,在自管理的环境中,我们即需要了解当前的资源是否能够应对数据与负载,还需要根据索引与分片的活动配置各种规则,
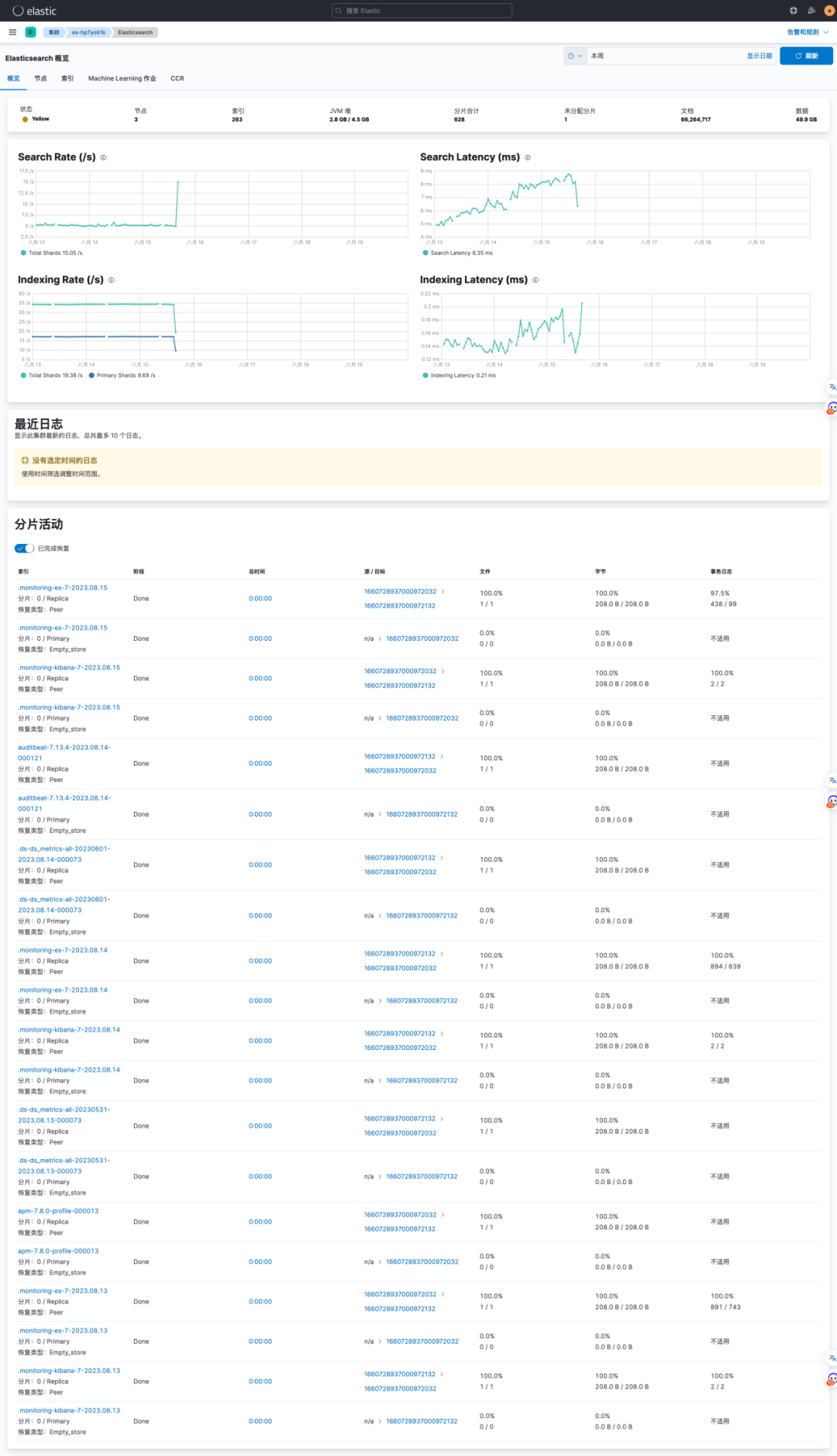
图10
而 Serverless 索引只需要知道索引的访问地址,背后的索引管理活动已经由 Serverless 服务代替我们执行,在整个控制台和Kibana界面都非常的简洁,后期需要人工介入和运维的地方几乎没有:
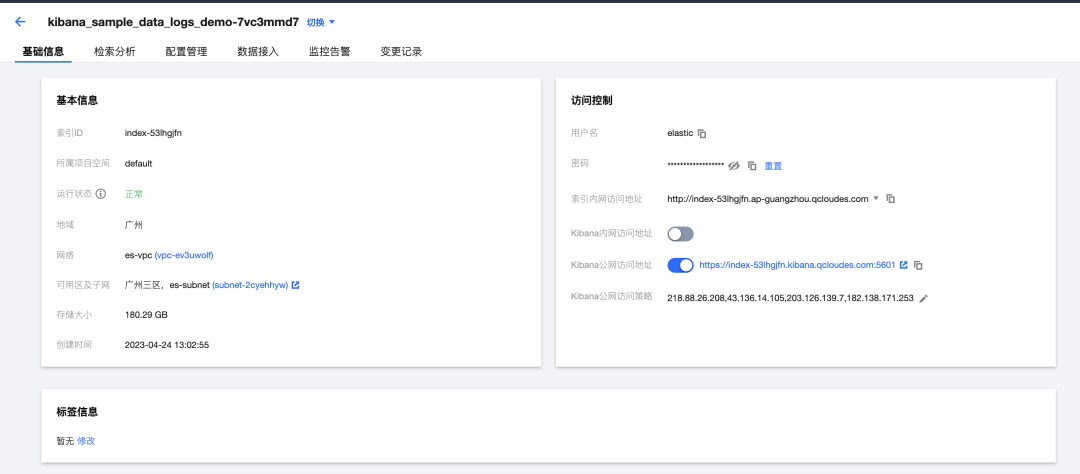
图11
●总结 ●
腾讯云 Elasticsearch Service Serverless是一款自动弹性、完全免运维、灵活易用、极致成本、开放集成以及稳定可靠的云端搜索引擎服务。它提供了一站式产品能力,可在分钟级实现业务落地,使得用户可以更加专注于业务开发,而无需关注基础设施的运维和管理。
除此之外,腾讯云Elasticsearch Service Serverless还兼容Elastic Stack生态,保留用户原有使用习惯,实现无缝迁移,助力业务快速上云。这意味着,用户可以将现有的Elasticsearch应用程序和工具集轻松地迁移到腾讯云上,而无需更改任何代码或配置。
而自2023年8月1日起,开通 ES Serverless 服务的新用户,可免费领取50元代金券,抵扣使用 Serverless 服务产生的费用,有效期自领取之日起持续90天,超出的费用,将按照对应计费项定价进行扣费。