
1 背景
数据平面开发套件(DPDK 1 ,Data Plane Development Kit)是由6WIND,Intel等多家公司开发,主要基于Linux系统运行,用于快速数据包处理的函数库与驱动集合,可以极大提高数据处理性能和吞吐量,提高数据平面应用程序的工作效率。
1.1 高性能网络技术
传统的网络设备(交换机、路由器等)为了快速处理数据包而嵌入了NP处理器(Network Process),内置硬件电路实现高速转发数据包。随着云计算的发展以CPU为核心、操作系统是linux,网络设备都是虚拟化,没有NP处理器。传统的网络架构处理流程如下:

传统网络框架处理流程
随着云计算产业的异军突起,网络技术的不断创新,越来越多的网络设备基础架构逐步向基于通用处理器平台的架构方向融合,从传统的物理网络到虚拟网络,从扁平化的网络结构到基于 SDN 分层的网络结构,无不体现出这种创新与融合。
这在使得网络变得更加可控制和成本更低的同时,也能够支持大规模用户或应用程序的性能需求,以及海量数据的处理。究其原因,其实是高性能网络编程技术随着网络架构的演进不断突破的一种必然结果。
1.2 C10K 到 C10M 问题的演进
如今,关注的更多是 C10M 问题(即单机 1 千万个并发连接问题)。很多计算机领域的大佬们从硬件上和软件上都提出了多种解决方案。从硬件上,比如说,现在的类似很多 40Gpbs、32-cores、256G RAM 这样配置的 X86 服务器完全可以处理 1 千万个以上的并发连接。
但是从硬件上解决问题就没多大意思了,首先它成本高,其次不通用,最后也没什么挑战,无非就是堆砌硬件而已。所以,抛开硬件不谈,我们看看从软件上该如何解决这个世界难题呢?
这里不得不提一个人,就是 Errata Security 公司的 CEO Robert Graham,他在 Shmoocon 2013 大会上很巧妙地解释了这个问题。有兴趣可以查看其 YouTube 的演进视频: C10M Defending The Internet At Scale。
他提到了 UNIX 的设计初衷其实为电话网络的控制系统而设计的,而不是一般的服务器操作系统,所以,它仅仅是一个数据负责数据传送的系统,没有所谓的控制层面和数据层面的说法,不适合处理大规模的网络数据包。最后他得出的结论是:
OS 的内核不是解决 C10M 问题的办法,恰恰相反 OS 的内核正式导致 C10M 问题的关键所在。
1.3 基于 OS 内核的数据传输有什么弊端?
1、中断处理。当网络中大量数据包到来时,会产生频繁的硬件中断请求,这些硬件中断可以打断之前较低优先级的软中断或者系统调用的执行过程,如果这种打断频繁的话,将会产生较高的性能开销。
2、内存拷贝。正常情况下,一个网络数据包从网卡到应用程序需要经过如下的过程:数据从网卡通过 DMA 等方式传到内核开辟的缓冲区,然后从内核空间拷贝到用户态空间,在 Linux 内核协议栈中,这个耗时操作甚至占到了数据包整个处理流程的 57.1%。
3、上下文切换。频繁到达的硬件中断和软中断都可能随时抢占系统调用的运行,这会产生大量的上下文切换开销。另外,在基于多线程的服务器设计框架中,线程间的调度也会产生频繁的上下文切换开销,同样,锁竞争的耗能也是一个非常严重的问题。
4、局部性失效。如今主流的处理器都是多个核心的,这意味着一个数据包的处理可能跨多个 CPU 核心,比如一个数据包可能中断在 cpu0,内核态处理在 cpu1,用户态处理在 cpu2,这样跨多个核心,容易造成 CPU 缓存失效,造成局部性失效。如果是 NUMA 架构,更会造成跨 NUMA 访问内存,性能受到很大影响。
5、内存管理。传统服务器内存页为 4K,为了提高内存的访问速度,避免 cache miss,可以增加 cache 中映射表的条目,但这又会影响 CPU 的检索效率。
6、协议栈的低效性。Linix诞生之初就是为电话电报控制而设计的,它的控制平面和数据转发平面没有分离,不适合处理大规模网络数据包。并且为了全面的支持用户空间的各个功能,协议栈中嵌入了大量用于对接的接口,如果能让应用程序直接接管网络数据包处理、内存管理以及CPU调度,那么性能可以得到一个质的提升。为了达到这个目标,第一个要解决的问题就是绕过Linux内核协议栈,因为Linux内核协议栈性能并不是很优秀,如果让每一个数据包都经过Linux协议栈来处理,那将会非常的慢。像Wind River和6 Wind Gate等公司自研的内核协议栈宣称比Linux UDP/TCP协议栈性能至少提高500%以上,因此能不用Linux协议栈就不用。 不用协议栈的话当然就需要自己写驱动了,应用程序直接使用驱动的接口来收发报文。PF_RING,Netmap和intelDPDK等可以帮助你完成这些工作,并不需要我们自己去花费太多时间。 Intel官方测试文档给出了一个性能测试数据,在1S Sandbridge-EP 8*2.0GHz cores服务器上进行性能测试,不用内核协议栈在用户态下吞吐量可高达80Mpps(每个包处理消耗大约200 cpu clocks),相比之下,使用Linux内核协议栈性能连1Mpps都无法达到。
7、多核协同问题。多核的可扩展性对性能提升也是非常重要的,因为服务器中CPU频率提升越来越慢,纳米级工艺改进已经是非常困难的事情了,但可以做的是让服务器拥有更多的CPU和核心,像国家超级计算中心的天河二号使用了超过3w颗Xeon E5来提高性能。在程序设计过程中,即使在多核环境下也很快会碰到瓶颈,单纯的增加了处理器个数并不能线性提升程序性能,反而会使整体性能越来越低。一是因为编写代码的质量问题,没有充分利用多核的并行性,二是服务器软件和硬件本身的一些特性成为新的瓶颈,像总线竞争、存储体公用等诸多影响性能平行扩展的因素。那么,我们怎样才能让程序能在多个CPU核心上平行扩展:尽量让每个核维护独立数据结构;使用原子操作来避免冲突;使用无锁数据结构避免线程间相互等待;设置CPU亲缘性,将操作系统和应用进程绑定到特定的内核上,避免CPU资源竞争;在NUMA架构下尽量避免远端内存访问
综合以上问题,可以看出内核本身就是一个非常大的瓶颈所在。那很明显解决方案就是想办法绕过内核。
1.4 解决方案探讨
针对以上弊端,分别提出以下技术点进行探讨。
- 控制层和数据层分离。将数据包处理、内存管理、处理器调度等任务转移到用户空间去完成,而内核仅仅负责部分控制指令的处理。这样就不存在上述所说的系统中断、上下文切换、系统调用、系统调度等等问题。
- 使用多核编程技术代替多线程技术,并设置 CPU 的亲和性,将线程和 CPU 核进行一比一绑定,减少彼此之间调度切换。
- 针对 NUMA 系统,尽量使 CPU 核使用所在 NUMA 节点的内存,避免跨内存访问。
- 使用大页内存代替普通的内存,减少 cache-miss。
- 采用无锁技术解决资源竞争问题。
经很多前辈先驱的研究,目前业内已经出现了很多优秀的集成了上述技术方案的高性能网络数据处理框架,如wind、windriver、netmap、dpdk 等,其中,Intel 的 dpdk 在众多方案脱颖而出,一骑绝尘。DPDK目前支持的CPU体系架构包括x86、ARM、PowerPC(PPC),支持的网卡列表:
https://core.dpdk.org/supported/,包括主流使用Intel 82599(光口)、Intel x540(电口)

dpdk 全称data plane development kit(数据平面转发工具),为 Intel 处理器架构下用户空间高效的数据包处理提供了库函数和驱动的支持,数据包的控制层和数据层分开,dpdk绕过linux内核协议栈将数据包的接受处理放到应用层。
也就是 dpdk 绕过了 Linux 内核协议栈对数据包的处理过程,在用户空间实现了一套数据平面来进行数据包的收发与处理。在内核看来,dpdk 就是一个普通的用户态进程,它的编译、连接和加载方式和普通程序没有什么两样。
1.5 dpdk 应用场景
dpdk 作为优秀的用户空间高性能数据包加速套件,现在已经作为一个“胶水”模块被用在多个网络数据处理方案中,用来提高性能。如下是众多的应用。
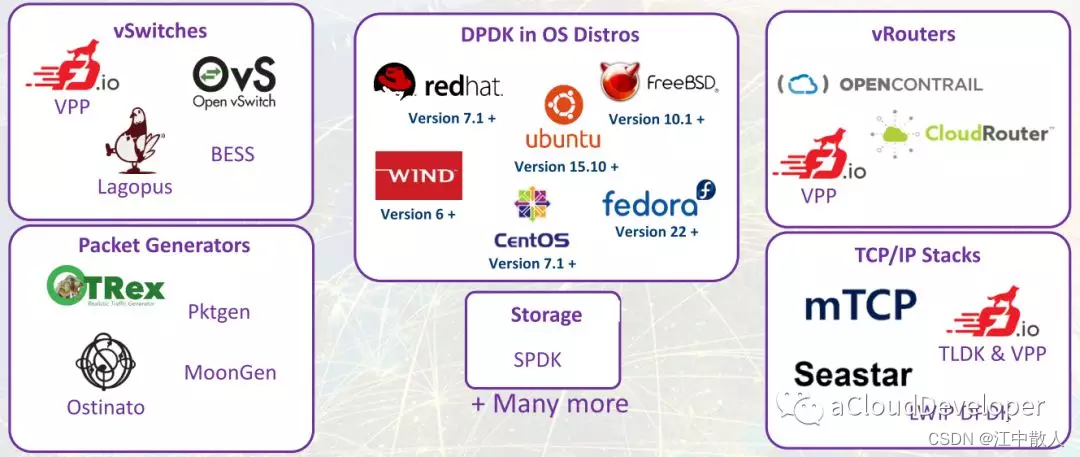
1.5.1 数据面(虚拟交换机)
1.5.1.1 OVS
Open vSwitch 是一个多核虚拟交换机平台,支持标准的管理接口和开放可扩展的可编程接口,支持第三方的控制接入。
https://github.com/openvswitch/ovs
1.5.1.2 VPP
VPP 是 cisco 开源的一个高性能的包处理框架,提供了交换/路由功能,在虚拟化环境中,使它可以当做一个虚拟交换机来使用。在一个类 SDN 的处理框架中,它往往充当数据面的角色。经研究表明,VPP 性能要好于 ovs+dpdk 的组合,但它更适用于NFV,适合做特定功能的网络模块。
VPP - fd.io
1.5.1.3 Lagopus
Lagopus 是另一个多核虚拟交换的实现,功能和 OVS 差不多,支持多种网络协议,如 Ethernet,VLAN,QinQ,MAC-in-MAC,MPLS 和 PBB,以及隧道协议,如 GRE,VxLan 和 GTP。
https://github.com/lagopus/lagopus/blob/master/QUICKSTART.md
1.5.1.4 Snabb
Snabb 是一个简单且快速的数据包处理工具箱。
https://github.com/SnabbCo/snabbswitch/blob/master/README.md
1.5.2 数据面(虚拟路由器)
1.5.2.1 OPENCONTRAIL
一个集成了 SDN 控制器的虚拟路由器,现在多用在 OpenStack 中,结合 Neutron 为 OpenStack 提供一站式的网络支持。
http://www.opencontrail.org/
1.5.2.2 CloudRouter
一个分布式的路由器。
https://cloudrouter.org/
1.5.3 用户空间协议栈
1.5.3.1 mTCP
mTCP 是一个针对多核系统的高可扩展性的用户空间 TCP/IP 协议栈。
https://github.com/eunyoung14/mtcp/blob/master/README
1.5.3.2 IwIP
IwIP 针对 RAM 平台的精简版的 TCP/IP 协议栈实现。
README - lwip.git - lwIP - A Lightweight TCPIP stack
1.5.3.3 Seastar
Seastar 是一个开源的,基于 C++ 11/14 feature,支持高并发和低延迟的异步编程高性能库。
Seastar - Seastar
1.5.3.4 f-stack
腾讯开源的用户空间协议栈,移植于 FreeBSD协议栈,粘合了 POSIX API,上层应用(协程框架,Nginx,Redis),纯 C 编写,易上手。
https://github.com/f-stack/f-stack
总结
dpdk 绕过了 Linux 内核协议栈,加速数据的处理,用户可以在用户空间定制协议栈,满足自己的应用需求,目前出现了很多基于 dpdk 的高性能网络框架,OVS 和 VPP 是常用的数据面框架,mTCP 和 f-stack 是常用的用户态协议栈。很多大公司都在使用 dpdk 来优化网络性能。
参考链接
DPDK_百度百科
DPDK技术简介 - 简书
DPDK 全面分析 - bakari - 博客园
DPDK技术的原理是怎样的,它的作用是什么 - 今日头条 - 电子发烧友网
DPDK框架核心介绍 - 知乎
DPDK解析 - 知乎
DPDK加速技术深度剖析(一)—— 综述篇 | SDNLAB | 专注网络创新技术
DPDK 分析,原理以及学习路线 - 知乎
阿里云用DPDK如何解决千万级流量并发_哔哩哔哩_bilibili
阿里云用到的DPDK(分析原理)以及学习路线 - 知乎
DPDK系列之十二:基于virtio、vhost和OVS-DPDK的容器数据通道_cloudvtech的博客-CSDN博客_dpdk 容器
DPDK系列之六:qemu-kvm网络后端的加速技术_cloudvtech的博客-CSDN博客_kvm加速
DPDK系列之十五:Virtio技术分析之一,virtio基础架构_cloudvtech的博客-CSDN博客_virtio
从dpdk1811看virtio1.1 的实现—packed ring-lvyilong316-ChinaUnix博客
qemu-kvm中的virtio浅析 - 骑着蜗牛追太阳 - 博客园
Qemu模拟IO和半虚拟化Virtio的区别以及I/O半虚拟化驱动介绍_weixin_34051201的博客-CSDN博客
virtio blk原理 - 简书
DPDK系列之十一:容器云的数据通道加速方案概览_cloudvtech的博客-CSDN博客
DPDK系列之十二:基于virtio、vhost和OVS-DPDK的容器数据通道_cloudvtech的博客-CSDN博客_dpdk 容器
《重识云原生系列》专题索引:
- 第一章——不谋全局不足以谋一域
- 第二章计算第1节——计算虚拟化技术总述
- 第三章云存储第1节——分布式云存储总述
- 第四章云网络第一节——云网络技术发展简述
- 第四章云网络4.2节——相关基础知识准备
- 第四章云网络4.3节——重要网络协议
- 第四章云网络4.3.1节——路由技术简述
- 第四章云网络4.3.2节——VLAN技术
- 第四章云网络4.3.3节——RIP协议
- 第四章云网络4.3.4节——OSPF协议
- 第四章云网络4.3.5节——EIGRP协议
- 第四章云网络4.3.6节——IS-IS协议
- 第四章云网络4.3.7节——BGP协议
- 第四章云网络4.3.7.2节——BGP协议概述
- 第四章云网络4.3.7.3节——BGP协议实现原理
- 第四章云网络4.3.7.4节——高级特性
- 第四章云网络4.3.7.5节——实操
- 第四章云网络4.3.7.6节——MP-BGP协议
- 第四章云网络4.3.8节——策略路由
- 第四章云网络4.3.9节——Graceful Restart(平滑重启)技术
- 第四章云网络4.3.10节——VXLAN技术
- 第四章云网络4.3.10.2节——VXLAN Overlay网络方案设计
- 第四章云网络4.3.10.3节——VXLAN隧道机制
- 第四章云网络4.3.10.4节——VXLAN报文转发过程
- 第四章云网络4.3.10.5节——VXlan组网架构
- 第四章云网络4.3.10.6节——VXLAN应用部署方案
- 第四章云网络4.4节——Spine-Leaf网络架构
- 第四章云网络4.5节——大二层网络
- 第四章云网络4.6节——Underlay 和 Overlay概念
- 第四章云网络4.7.1节——网络虚拟化与卸载加速技术的演进简述
- 第四章云网络4.7.2节——virtio网络半虚拟化简介
- 第四章云网络4.7.3节——Vhost-net方案
- 第四章云网络4.7.4节vhost-user方案——virtio的DPDK卸载方案
- 第四章云网络4.7.5节vDPA方案——virtio的半硬件虚拟化实现
- 第四章云网络4.7.6节——virtio-blk存储虚拟化方案
- 第四章云网络4.7.8节——SR-IOV方案
- 第四章云网络4.7.9节——NFV
- 第四章云网络4.8.1节——SDN总述
- 第四章云网络4.8.2.1节——OpenFlow概述
- 第四章云网络4.8.2.2节——OpenFlow协议详解
- 第四章云网络4.8.2.3节——OpenFlow运行机制
- 第四章云网络4.8.3.1节——Open vSwitch简介
- 第四章云网络4.8.3.2节——Open vSwitch工作原理详解
- 第四章云网络4.8.4节——OpenStack与SDN的集成
- 第四章云网络4.8.5节——OpenDayLight
- 第四章云网络4.8.6节——Dragonflow
- 第四章云网络4.9.1节——网络卸载加速技术综述
- 第四章云网络4.9.2节——传统网络卸载技术
- 第四章云网络4.9.3.1节——DPDK技术综述
- 第四章云网络4.9.3.2节——DPDK原理详解
- 第四章云网络4.9.4.1节——智能网卡SmartNIC方案综述
- 第四章云网络4.9.4.2节——智能网卡实现