1. 前言
TcaplusDB是专为游戏设计的分布式 NoSQL 数据库,作为腾讯云的数据库服务的一部分为广大客户提供极致的游戏数据体验。目前已为《王者荣耀》、《穿越火线》、《火影忍者》等千万级 DAU 大作提供了稳定的数据存储服务,依托腾讯云遍布全球五大洲(亚洲、欧洲、北美洲、南美洲、大洋洲)的基础设备服务节点,游戏开发商只需接入一次,便可方便全球游戏用户体验。具体产品详情请参考官网链接。
2. TcaplusDB架构
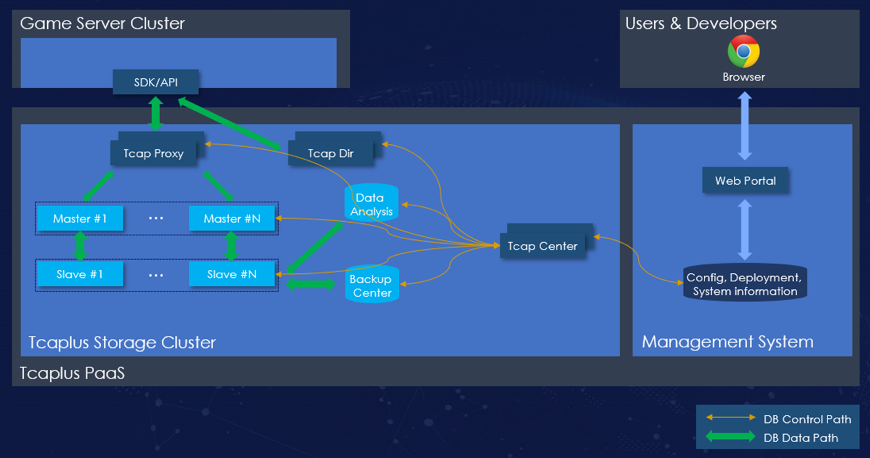
编号 | 组件名称 | 描述 |
|---|---|---|
1 | Tcapcenter | 处理来自Web页面的请求,作为zookeeper管理整个Tcaplus集群的各个节点。 |
2 | Tcaproxy | 接入层,接收来自SDK/API的请求,再与Master节点交互,获得Master节点的返回信息后,再返回至SDK/API请求方。 |
3 | Tcapdir | 目录服务器。存储和维护Tcaproxy集群的节点信息,响应来自SDK/API查询Tcaproxy节点信息(IP地址与服务端口)的请求。 |
4 | Tcapsvr-Master | 存储层的主节点,存储数据分片,负责响应Tcaproxy请求。 |
5 | Tcapsvr-Slave | 存储层的备份节点,存储备份数据,实时备份Master节点数据。当Master节点故障时,升级作为Master节点,作为备份节点时,不与Tcaproxy通讯。 |
6 | Backup Center | 跨城市/地域冷备中心,冷备中心部署在与Master节点异地的数据中心,每日定时从Slave节点进行存储层数据冷备,每15分钟从Slave节点进行Binlog流水日志备份。 |
7 | Data Analysis | 负责将TcaplusDB中的结构化数据导出,参见6.2。 |
3. TcaplusDB技术原理
3.1 存储原理
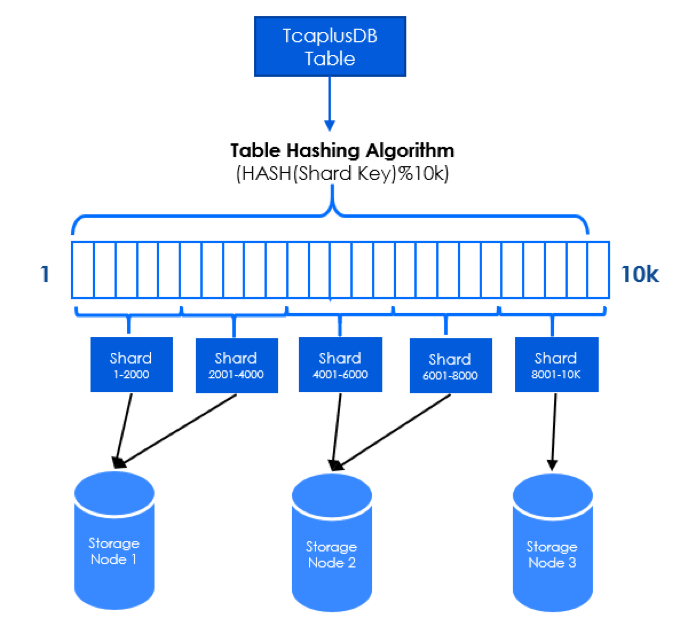
一个表通过HASH分表,按照路由数组长度(默认为10k)进行取模运算分片(Mod Sharding),所以每张表最多可以分成10k个分片(Shard)。以下图为例,1个TcaplusDB表被分为5个Shard文件分布到不同存储节点,每个结点分布有1个或多个分片的数据。
3.2 系统扩容
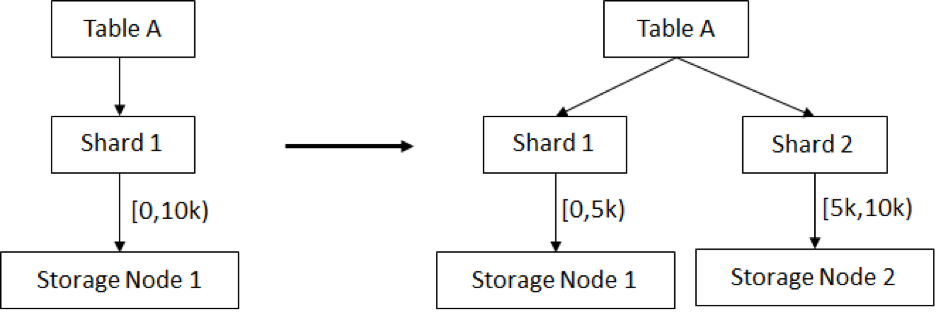
TcaplusDB扩容分别在存储层和接入层进行。从第2章节的架构图中,可以看到接入层即Tcap Proxy层,存储层即Tcapsvr层(主备节点)。对于接入层而言,采用的是无状态设计,所以可以灵活水平扩缩容,且不影响线上业务,对业务无感知 ; 对于存储层而言,由于表采用的是分片设计,在扩容时需要将原机器上的分片水平迁移到新机器上,达到扩容存储空间的目的。以图3.2为例,Table A在扩容前,只有一个分片Shard 1, 路由数组长度为10k。在扩容时,将该表分为两个分片,其中路由项0-5k放在Shard1 , 路由项5001-10k放在Shard2,2个shard分别存储到两个存储节点上。
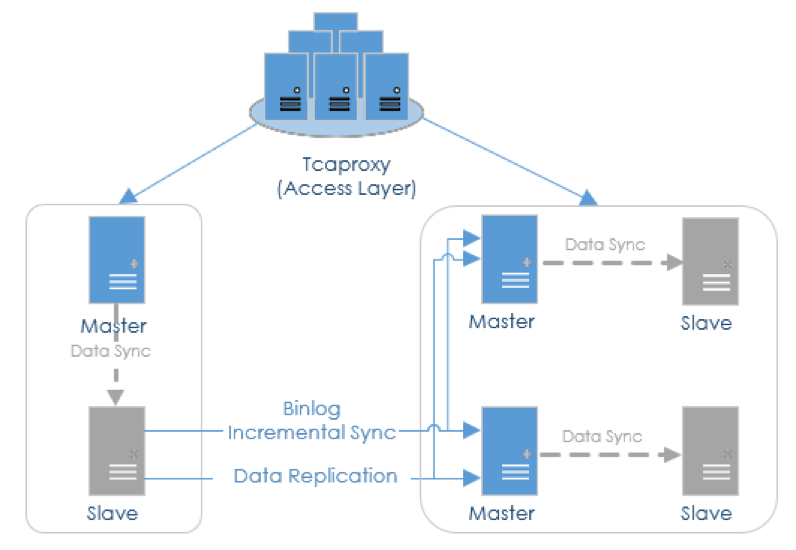
数据迁移过程见图3.3,原TcaplusDB Salve节点上数据会复制到新的TcaplusDB Master节点,通过binlog同步保持数据完整性,接入层tcapoxy的数据请求重定向到新的TcaplusDB集群。
接入层扩容,如图3.4所示,通过一致性哈希路由切换,将原来由4个tcaproxy负责转发的路由,平均分配给5个tcaproxy,路由切换过程不会造成消息丢失。

TcaplusDB的扩容基于存储节点的磁盘使用率和QPS (Queries per Second) 2个维度。当单台存储节点容量使用达到一定阈值后即触发扩容操作。
3.3 TcaplusDB可用性与一致性
3.3.1 高可用
TcaplusDB组件默认采用高可用部署:
- 管理节点tcapcenter采用Master/Slave模式部署,当Master故障时自动切换到Slave。
- 管理节点tcapdir会部署多个进程。
- 接入层tcaproxy采用冗余方式,单个接入层节点故障不会导致用户请求处理异常。
- 存储层tcapsvr,采用Master/Slave模式,主从切换无损。 存储层tcapsvr Master/Slave和接入层tcaproxy部署优先采用同城跨机房部署,也支持跨机架、跨交换机、跨楼层等部署方式。
3.3.2 灾难恢复
TcaplusDB API维护了一致性Hash环,当增加或者减少接入层节点时,TcaplusDB API会自动调整接入层tcaproxy的信息。
- 接入层异常:TcaplusDB每秒会向接入层tcaproxy发送心跳,若接入层节点在10s内没有返回响应,则TcaplusDB API会主动标注该节点不可用,使用其他节点。
- 存储层异常:tcapsvr Slave发生异常时会被一个新的Slave节点替换。如果tcapsvr master发生异常, Slave会切换成Master,切换过程中的用户请求失败,建议开发者增加重试逻辑代码。Master/Slave支持亚健康切换,读写错误率达到阈值时(默认80%)即进行主从切换,如下图:
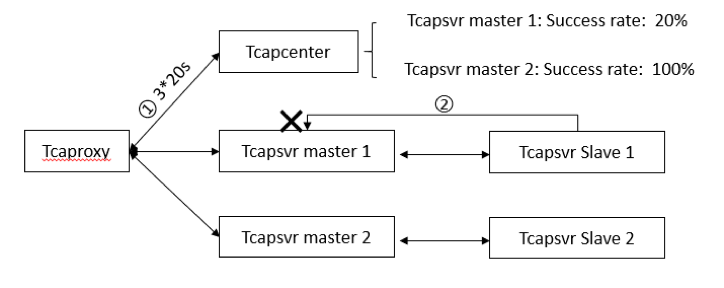
接入层tcaproxy和存储层tcapsvr均有过载保护功能,超过预留读写的请求会触发错误码返回。
3.3.3 数据一致性保障
对于TcaplusDB来说,有完善的数据一致性保障措施,具体如下所示:
- 正常读写场景:主备通过binlog来保证数据一致性,主备会按严格一致的时间顺序执行binlog;主备时间差约10ms; 业务读写请求均在主节点执行。
- 主备切换: 系统主动切换会先等待数据完全同步后,再进行切换。故障切换若因master进程已不存在, 可能丢失10ms左右数据,此时因老请求还连在原master上,TcaplusDB主备同步目前采用的是异步写的机制,当数据写主过程中故障,有可能数据还未来得及同步备机连接就断了,此时数据就可能会丢失,目前所使用的内外客户对这种损失程度还处于可接受范围,不会对业务造成太大影响。目前针对这个情况,项目组也在计划设计强同步机制,确保数据不会丢,不过带来的就是会牺牲一定的吞吐量。
- 周期性主备数据一致性全量对比: 根据用户需要,在低峰期对全量数据做一致性对比。对比过程因前端读写产品的不一致会根据记录修改时间自动判断并重复校验, 以发现系统潜在的不一致风险。 通常做法是抽查一些核心表的部分数据分片来进行全量比对,以保障比对效率。
- 冷备数据一致性保障: 备节点在做全量冷备时,冷备开始时间点全量数据文件处于完全静止状态,此时全量数据采用字节copy来进行备份, 完全无一致性问题。 且在冷备期间,前端读写完全不受影响,新请求会写入小的修改集,请求会合并全量数据和小修改集。
- 数据落地安全保障: 业务数据在存储节点落地时有CRC校验, 若因数据被篡改, CRC校验会失败, 不会因此返回给用户错误的数据。
3.4 备份与回档
3.4.1 冷备
目前TcaplusDB支持两种方式数据备分:全量数据文件冷备,每日定时进行,表创建好后,自动有脚本去备份存储数据文件,全量备份文件保存周期25天;另一种是增量备份,主要基于TcaplusDB的binlog进行,每15分钟进行一次, 增量流水保存周期15天。通过两种方式备份的结合,保障了系统异常期间通过备份快速恢复的能力。
3.4.2 回档
TcaplusDB的回档支持两种方式:
回档方式 | 描述 | 支持方式 |
|---|---|---|
冷备回档 | 使用备份文件回档到冷备的时间点,精确到毫秒。 | 暂时通过工单支持 |
精确回档 | 使用备份文件和binlog文件回档到任意指定的时间点,精确到毫秒。 | 腾讯云控制台支持(表,key) |
冷备回档和精确回档支持以下4种回档范围:
回档范围 | 描述 | 支持方式 |
|---|---|---|
全服回档 | 所有表均回档 | 暂时通过工单支持 |
单表回档 | 仅单个表回档 | 腾讯云控制台支持 |
记录回档 | 对单个记录回档, 回档时指定KEY即可 | 腾讯云控制台支持 |
条件回档 | 指定过滤条件回档, 如指定要回档的key | 暂时通过工单支持 |
3.5 性能调优
接入层tcaproxy响应与处理请求默认使用内存池(Memory Pool)技术,从而减少内存占用。
存储层tcapsvr采用谷歌snappy压缩算法,约节省30%存储空间,可按配置的过期时间和表名进行过期数据淘汰。
存储层tcapsvr每台服务器采用单进程运行,由36个线程组成,包括主线程、30个工作线程、LRU线程、主从同步线程、数据搬迁线程、缓写线程、刷Binlog流水线程。30个工作线程分为快慢线程,例如get(按主键查找)、replace(更新)等由快线程处理,getbypartkey(按索引查找)等由慢线程处理。通过不同线程的功能划分,提升了处理效率。
3.6 监控指标
TcaplusDB支持邮件、微信和电话告警,常见告警监控指标如下:
指标 | 描述 |
|---|---|
一般错误率 | 用户使用错误导致的请求数占总请求数比 |
系统错误率 | 存储层节点因为TcaplusDB错误导致错误请求数目占总的请求数目的比例 |
平均错误率 | 错误请求数(一般错误数与系统错误数之和)占总请求数比 |
实际读容量单位 | 读CU,1个读CU是1次4KB的读操作 |
实际写容量单位 | 写CU,1个写CU是1次4KB的写操作 |
平均读时延 | 60秒内所有读请求的平均时延 |
平均写时延 | 60秒内所有写请求的平均时延 |
存储容量 | 存储的数据大小(GB) |
3.7 系统安全
- 网络安全: TcaplusDB环境目前处于腾讯云VPC私有网络环境下,与外界进行充分的网络隔离保障用户数据安全。
- 访问安全: 主要体现在几个方面:
- CAM: TcaplusDB目前集成腾讯云用户权限管理体系CAM, 支持接口级权限访问控制,避免非相关人员访问到数据;
- 访问密码: TcaplusDB应用创建需设置访问密码,用于目录服务器tcapdir和接入层服务器tcaproxy鉴权使用;
- IP白名单: TcaplusDB后台支持基于IP白名单访问,即指定IP客户端读写TcaplusDB数据;
- 审计: 所有用户操作均有审计日志,做到所有访问有据可查。
- 数据安全: 数据读写压缩或解压缩后会采用序列化和反序列化操作,即使数据文件被劫持也无法解析数据内容
- 合规安全: 数据文件会采用aes-128-cbc加密,满足欧盟GDPR标准; 同时对于很多有出海需求的客户,腾讯云也提供了大量的国外安全认证体系,如韩国的KIMS等。
4. TcaplusDB操作
4.1 表定义
TcaplusDB支持2种类型的表,protobuf(Protocol Buffers)表TDR(Tencent Data Representation)表。Protobuf是Google开发的一种描述性语言,针对结构化数据进行序列化,同时强调简单性和性能; TDR是由腾讯开发的跨平台数据表示语言,结合了XML,二进制和ORM(对象关系映射)的优势,在腾讯游戏数据的序列化场景中广泛使用。
4.1.1 表定义约束
4.1.1.1 协议约束
目前支持Protobuf协议表版本建议用proto3。TDR协议建议用1.0。
4.1.1.2 主键索引约束
- 单表主键索引最多支持创建4个
- 主键索引必须基于主键字段创建
- 主键索引必须带有分表因子
示例:proto表有三个主键字段,分别为: fieldA, fieldB, fieldC。
合法的索引定义如下:
#如果以fieldA为分表因子,定义索引如下 option(tcaplusservice.tcaplus_index) = "index_1(fieldA)"; option(tcaplusservice.tcaplus_index) = "index_2(fieldA,fieldB)"; option(tcaplusservice.tcaplus_index) = "index_3(fieldA,fieldC)"; |
|---|
非法的索引定义如下:
#如果以fieldA为分表因子,非法的索引类型 option(tcaplusservice.tcaplus_index) = "index_1(fieldB)"; option(tcaplusservice.tcaplus_index) = "index_2(fieldC)"; option(tcaplusservice.tcaplus_index) = "index_3(fieldB, fieldC)"; |
|---|
如果以fieldB或fieldC为分表因子,定义规则类似上面。
4.1.2 Protobuf表
以下是protobuf表game_players.proto的示例,您可以将文件上传到腾讯云控制台并创建该表。
syntax = "proto3"; // 指定protobuf语言版本,proto3.// 导入TcaplusDB公共定义服务
import "tcaplusservice.optionv1.proto";message game_players { // 定义TcaplusDB表,包含message类型
// 基于选择项tcaplusservice.tcaplus_primary_key创建主键字段
// TcaplusDB单个表最多能指定4个主键字段
option(tcaplusservice.tcaplus_primary_key) = "player_id, player_name, player_email";// 基于选择项tcaplusservice.tcaplus_index创建主键索引 option(tcaplusservice.tcaplus_index) = "index_1(player_id, player_name)"; option(tcaplusservice.tcaplus_index) = "index_2(player_id, player_email)"; // TcaplusDB支持的数值类型: // int32, int64, uint32, uint64, sint32, sint64, bool, fixed64, sfixed64, double, fixed32, sfixed32, float, string, bytes // 嵌套类型: message // 主键字段 int64 player_id = 1; string player_name = 2; string player_email = 3; // 普通(非主键) 字段 int32 game_server_id = 4; repeated string login_timestamp = 5; repeated string logout_timestamp = 6; bool is_online = 7; payment pay = 8;}
message payment {
int64 pay_id = 1;
uint64 amount = 2;
int64 method = 3;
}
4.1.3 TDR表
TDR支持通用(generic)表和列表(list)表。 generic表是以表的形式表示元素属性的表,例如学生,雇主,游戏玩家。 list表是一系列记录,例如游戏排行榜,游戏中的邮件(通常是最近的100封邮件)。
推荐在一个XML文件中创建两种不同类型的表。
- 元素metalib是xml文件的根元素。另外,您可以使用union创建嵌套类型:
- 属性tagsetversion应该始终为1。
- 包含属性primarykey的struct元素定义一个表;否则,它只是一个普通的结构体。
- 每次修改表结构时,版本属性值需要相应地加1,初始版本始终为1。
- primarykey属性指定主键字段;对于generic表,您最多可以指定4个主键字段,对于list表,则可以指定3个。
- splittablekey属性等效于分片键(shard key),TcaplusDB表被拆分存储到多个存储节点。 splittablekey必须是主键字段之一,一个好的splittablekey应该具有高度分散性,这意味着值的范围很广,建议选用字符串类型。
- desc属性包含当前元素的描述。
- entry元素定义一个字段。支持的值类型包括int32,string,char,int64,double,short等。
- index元素定义一个索引,该索引必须包含splittablekey。由于可以使用主键查询表,因此索引不应与主键属性相同。
样例:users_mails.xml
<?xml version="1.0" encoding="utf-8" standalone="yes" ?><metalib name="tcaplus_tb" tagsetversion="1" version="1">
<!-- generic_table
users, store the user' information -->
<!-- an user may has many roles -->
<struct name="users" version="1" primarykey="user_id,username,role_id" splittablekey="user_id" desc="user table">
<entry name="user_id" type="uint64" desc="user id"/>
<entry name="username" type="string" size="64" desc="login username"/>
<entry name="role_id" type="int32" desc="a user can have multiple roles"/><entry name="level" type="int32" defaultvalue="1" desc="role's level"/> <entry name="role_name" type="string" size="1024" desc="role's name"/> <entry name="last_login_time" type="string" size="64" defaultvalue="" desc="user login timestamp"/> <entry name="last_logout_time" type="string" size="64" defaultvalue="" desc="user logout timestamp"/> <index name="index1" column="user_id"/></struct>
<!-- list_table
mails, store the role's mails -->
<struct name="mails" version="1" primarykey="user_id,role_id" desc="mail table">
<entry name="user_id" type="uint64" desc="user id"/>
<entry name="role_id" type="int32" desc="a user may has many roles"/><entry name="text" type="string" size="2048" desc="mail text"/> <entry name="send_time" type="string" size="64" defaultvalue="" desc="timestamp of the mail sent"/> <entry name="read_time" type="string" size="64" defaultvalue="" desc="timestamp of the mall read"/></struct>
</metalib>
- union元素包含原始类型的集合,例如整数和字符串,可以将Union也可以作为自定义类型来引用;
- Macro标签用于定义常量。
<macro name="DB_MAX_USER_MSG_LEN" value="301" desc="Max length of the message that user can define"/>
<union name="DBPlayerMsg" version="1" desc="DB Player message">
<entry name="SysMsgID" type="uint8" desc="Message ID" />
<entry name="UsrMsg" type="string" size="DB_MAX_USER_MSG_LEN" desc="player created message" />
</union>4.2 TcaplusDB客户端
下载最新的TcaplusDB C++ SDK 3.46程序包并解压缩该文件, 以PB SDK举例,下载地址:SDK下载。
注意:tcaplus_client要求在与TcaplusDB同一VPC中的CVM上执行所有操作。
# 解压TcaplusDB API包
tar -zxvf TcaplusPbApi3.46.0.199033.x86_64_release_20201210.tar.gz找到TcaplusDB客户端
cd TcaplusPbApi3.46.0.199033.x86_64_release_20201210.0/release/x86_64/bin
连接TcaplusDB应用
./tcaplus_client -a {APP ID} -z {ZONE ID} -s {TcaplusDB PASSWORD} -d {Tcapdir IP}:{Tcapdir PORT}
例子:
./tcaplus_client -a 21 -z 1 -s "Changeme12" -d 10.0.0.2:9999
上述TcaplusDB_client连接参数获取方式如下:
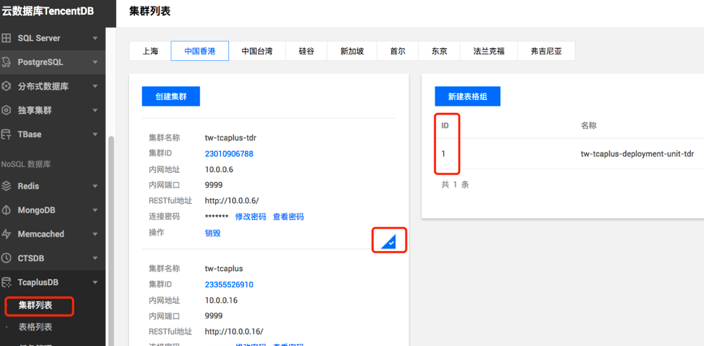
1) 打开表控制台,进入集群列表页面, 从页面获取Tcapdir IP(对应: Private Address/内网地址), Tcapdir PORT(对应:Private Port/内网端口),获取Zone ID (对应页面 : Table Group ID/表格组ID) 。
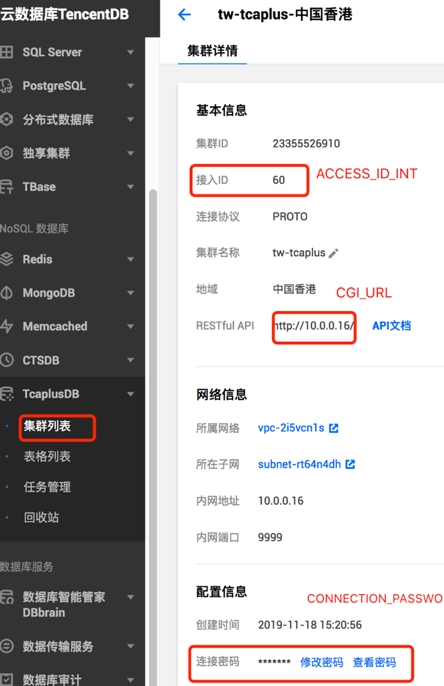
2) 点击上述截图的集群ID,进入应用详情页面, 获取 APP ID(对应: Access ID/接入ID), 以及TcaplusDB password(对应:Connection Password/连接密码)。 具体截图如下所示:
4.3 TcaplusDB客户端命令
TcaplusDB提供了一种类似SQL的查询语言,使您能像使用关系数据库一样操作TcaplusDB表。
命令 | 含义 | |
|---|---|---|
desc | 描述表字段 | |
count | 返回表记录数目 | |
clean | 清空(truncate)表, 此操作高度敏感,需要开白使用 | |
select | 查询表记录,示例: select * from BattleInfo where game_id = 100 and area_id=200 G; G标记符类似MySQL命令行格式化查询输出 | |
Insert | 插入记录,如记录存在,则报261错误 | |
update | 更新表记录,若该记录不存在,则报错,示例: update BattleInfo set player_number = 10 where game_id = 100 and area_id=200; | |
replace | 替换记录,如记录存在则更新类似update, 如不存在则插入新记录 | |
delete | 删除1条或多条记录,where语句需指定全部主键字段或索引字段。示例: delete from BattleInfo where game_id = 100 and area_id=200; | |
dump | 遍历表并将数据导出到文本文件,示例:dump * from BattleInfo into BattleInfo.csv; | |
load | 从文本文件导入数据到表,示例:load BattleInfo from BattleInfo.csv; |
注意: 使用tcaplus_client在操作PB类型(protobuf)的表时有一些限制,如下所示:
- load: 不支持, 预计Q2支持;
- select: 部分不支持,预计Q2支持,如下:
- 基于索引字段作为where查询条件暂不支持;
- select *不支持显示嵌套字段的值, 需要用点分模式指定嵌套字段才行如select pay.amount from ...;
- update: 部分不支持,对于repeated类型的字段无法用update 更新插入;
您可以通过运行help或help +命令获得更多的TcaplusDB语法。 请注意,上表中未列出的命令正在逐步淘汰或不建议使用。
tcaplus> help;help: show usage of commands, example: "help select;". show: get server status related information. executing "help show;" for details. exit/quit: exit the client. count: print record number in the database. desc: print table field name and type. select: query records from database. insert: insert a new record into database.replace: replace a record into the database.
update: update a record in the database.
delete: delete record(s) from database.dump: dump records from database. load: load records into the database.
--------------------------------------------------------------------------------
tcaplus> help select;example: select key1, key2, key3, value1, value2 [into result.csv] from table where key1 = 1 and key2 = "abc" [and -index = 1] [\P] [\G];
query records from database, you can specify part of the fields or whole fields (select *), and you can write the result to a file, which can be used by "insert" and "load"
for generic table, if the key in where clause is not complete, then it will send "GetByPartkey"
for list table, if "-index" is not specified in where clause, then it will send "ListGetAll", otherwise it will send "ListGet"
\P: print time usage in detail
\G: print fields in column
Note: "-index" only used for list tableexample: select * [into result.xml] from table where key1 = 1 and key2 = "abc" [and -index = 1] using tdr [\P];
if you specify "using tdr", then the records will be parsed by tdr file and print in xml format. you can write the result into a file, which can be used by "load"
it only support "select *" instead of select part of the fields when specify "using tdr"
Note: "-index" only used for list table
globle index query:
example: select * from table where key1 > 1 and value1 > 100;
example: select * from table where value1 like "test";
example: select field1, field2 from table where key1 > 1 or value1 > 100;
example: select * from table where value1 between 100 and 200;
example: select * from table where value1 > 100 limit 100 offset 0;
example: select sum(value2), max(value2), min(value2), avg(value2), count(*) from table where value1 > 100;
Note: globle index query is only support generic table;
Note: current support: =,!=,>,>=,<,<=, like, not like, betwwen, in, not in, and, or, limit offset;
Note: current support aggregation: count, sum, max, min, avg;
Note: for protobuf table, it support: "select field1.field2 from test where value1 > 100";
Note: limit must be used with offset, lack offset will query failed;
Note: the fields in where condition and in aggregation must had already created index;
Note: it not support: store the result to a file, such as "select * into file XXX" is not support;
Note: it not support: "select * from table"; which means to traverse table, you can used api traverse method to traverse table;
Note: it not support: order by, group by, having, join, union and so on;
Note: it not support: select a+b XXX; select * from table where a+b>0; select sum(XX),field1 from XXX; select *,field1 from XXX; ......;
--------------------------------------------------------------------------------
更详细的命令使用请参考:tcaplus_client使用指南。
5. Tcapluscli工具
上面提到的tcaplus_client是用于TcaplusDB数据层面的操作。Tcapluscli主要用于TcaplusDB资源层的操作,如腾讯云控制台(或TcaplusDB本地版)集群、表格组、表的增删查,支持批量操作,方便用户通过命令工具来完成资源的批量的操作。
具体工具使用手册参考:Tcapluscli使用手册。
6 TcaplusDB本地Docker版
Docker版主要方便用户本地开发调试TcaplusDB程序。Docker版本是TcaplusDB的最小化部署,只满足基本接口功能测试开发,不能用于性能压测。通过Docker版,用户可方便了解后台的动作模式,提供Web运维控制平台给用户基于UI界面进行TcaplusDB资源的管控。Docker版本部署文档参考:TcaplusDB-Docker部署指南。
7 全局二级索引使用
TcaplusDB推出全局二级索引功能,类似于MySQL的二级索引功能。二级索引功能需要在腾讯云控制台进表详情页面设置,在“表格配置”页,底部“索引信息”栏“全局索引”地方,点击“修改”,增加相关表字段作为二级索引字段。
7.1 约束
· 二级索引字段只能是一及字段,不支持嵌套字段作为二级索引字段;
· 不支持blob字段(byte)字段作为索引字段;
· 不支持数组类型字段作为索引字段。
7.2 索引相关语法
参考附录111.2。
8. TcaplusDB限制条件
编号 | 资源 | 上限 |
|---|---|---|
1 | 单表格组允许表格数 | 256 |
2 | 分标键(shard键) | 1 |
3 | 单表的Shard数 | 10,000 |
4 | 单shard大小 | 256GB |
5 | 单表大小 | 2.56PB |
6 | generic表主键字段 | 4 |
7 | generic表非主键字段 | 128 |
8 | list表组件字段 | 3 |
9 | list表非主键字段 | 127 |
10 | list表中的记录数 | 1024 |
11 | 表索引 | 8 |
12 | 字段长度(亦称属性长度) | 32B |
13 | 主键字段长度 | 1KB |
14 | 非主键字段长度 | 256KB |
15 | 单记录大小 | 1MB |
16 | 单索引关联记录数 | 无限制 |
17 | 单表允许分布的表格组数 (同一个表允许分布在一个表格组也可以分布在多个表格组) | 8 |
18 | 批量查询返回记录数 | 1024 |
9. API_Explorer使用
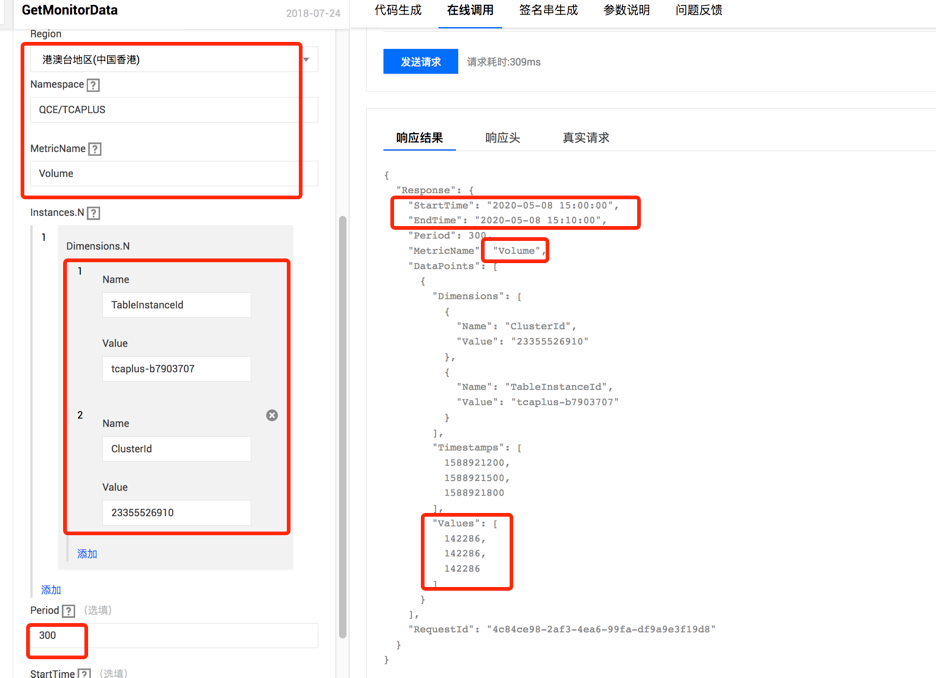
腾讯云提供了一个API在线使用的平台: API 3.0 Explorer。通过这个平台,用户可以方便在线测试对应产品的API接口调用逻辑。目前支持Java,Python, Node.js, PHP, Go和.Net等开发语言API ,只需在页面选择对应的API接口方法,填入对应方法参数后,定位到“在线调用”页面点击“发送请求”即可在线返回API的调用结果。API Explorer 支持两种方式API调用:一种是根据输入参数自动生成对应语言的调用代码,可以把这些代码放到自己的云环境机器中调用,方便更灵活的使用API; 另一种是根据输入参数自动生成Http调用代码,可直接在云环境机器用curl方式调用获取API返回结果。这里介绍下如何通过API Explorer来操作TcaplusDB及获取TcaplusDB表监控指标数据, 关于TcaplusDB表操作相关API请参考:TcaplusDB API, 关于监控数据获取API请参考: Monitor API。下面介绍下通过API Explorer 获取TcaplusDB表监控数据的例子。
调用代码生成如下:

调用返回结果如下:
10. 技术支持
10.1 问题升级
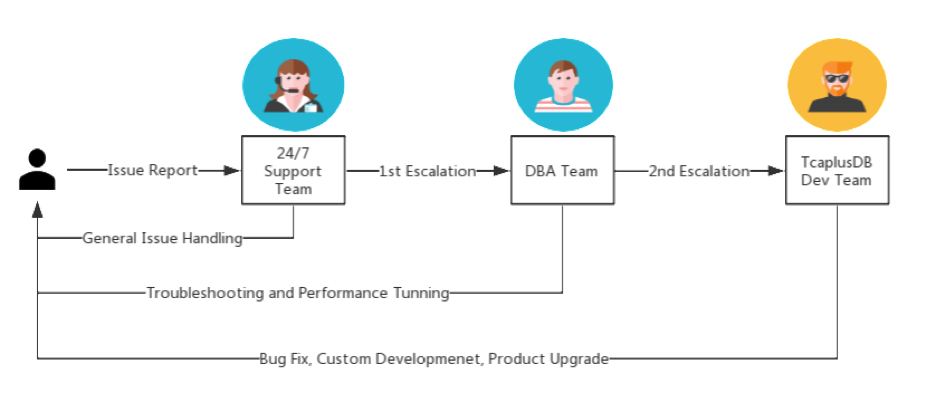
10.2 报表支持
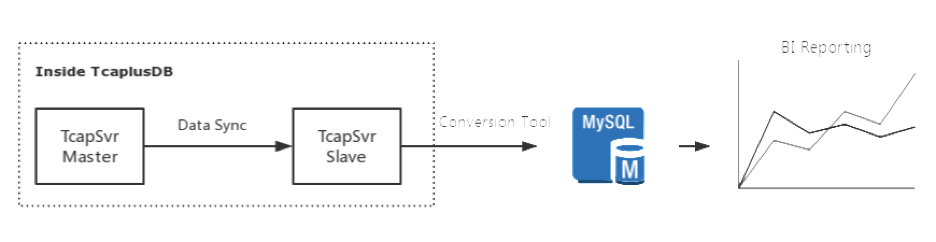
10.2.1 导出到关系型数据库
TcaplusDB支持用户选择部分Table的明文字段实时导入Mysql等关系型数据库,使用SQL语句查询和分析。
实现原理如下图所示:
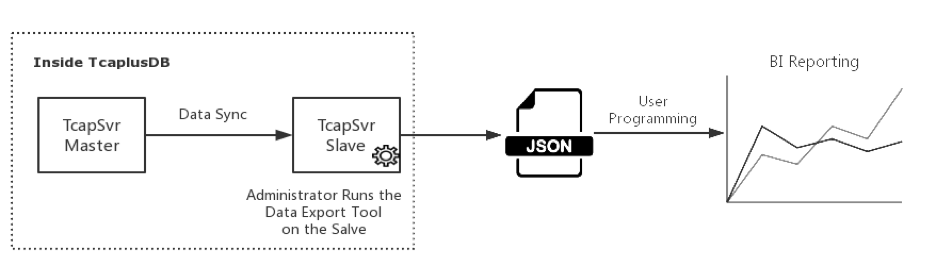
10.2.2 导出文本文件
TcaplusDB支持通过数据导出工具直接导出数据到JSON文件, 同上面用tcaplus_client导出csv文件类似。
10.2.3 导出到Kafka
TcaplusDB 数据支持导出到kafka, 通过在后台给每个表添加同步插件,实现数据流实时采集或定时采集至kafka. 插件支持指定字段数据采集,目前暂未开放到腾讯云控制台,在排期上线中。
11. 附录
11.1 TcaplusDB 新旧术语对比和使用场景
NO. | 旧术语 | 使用场景 | 新术语 | 使用场景 |
|---|---|---|---|---|
1 | Application | 仅适用TcaplusDB Client | Cluster | TcaplusDB云控制台 |
2 | Deployment Unit (Zone) | 仅适用TcaplusDB Client | Table Group | TcaplusDB 云控制台 |
3 | Application ID | 仅适用TcaplusDB Client | Cluster ID | TcaplusDB云控制台 |
4 | Deployment Unit ID (Zone ID) | 仅适用TcaplusDB Client | Table Group ID | TcaplusDB 云控制台 |
5 | app_id | 仅适用TcaplusDB Client | access_id | SDK中关于CRUD操作部分 |
6 | app_pwd | 仅适用TcaplusDB Client | access_passwd | SDK中关于CRUD操作部分 |
7 | zone_id | 仅适用TcaplusDB Client | table_group_id | SDK中关于CRUD操作部分 |
11.2 全局二级索引支持的 SQL 语法
11.2.1 条件查询
支持 =, >, >=, <, <=, !=, between, in, not in, like, not like, and, or , 比如:
select
select
select
select
|
|---|
注意:between 查询时,between a and b,对应的查询范围为[a, b],比如 between 1 and 100, 是会包含 1 和 100 这两个值的,即查询范围为[1,100]。
注意:like 查询是支持模糊匹配,其中"%"通配符,匹配 0 个或者多个字符; “_”通配符,匹配 1 个字符。
11.2.2 分页查询
支持 指定limit 和offset 属性进行分页查询。
select |
|---|
注意:当前 limit 必须与 offset 搭配使用,即不支持 limit 1 或者 limit 0,1 这种。
11.2.3 聚合查询
当前支持的聚合查询包括:sum, count, max, min, avg,比如:
select |
|---|
注意:聚合查询不支持 limit offset,即 limit offset 不生效。
注意:目前只有 count 支持 distinct,即 select count(distinct(a)) from table where a > 1000; 其他情况均不支持 distinct。
11.2.4 部分字段查询
指定部分字段查询,如下:
select |
|---|
对于PB表,还支持查询嵌套字段的值,用点分方式,类似:
select |
|---|
11.2.5 不支持的SQL查询
11.2.5.1 不支持聚合查询与非聚合查询混用
select select select |
|---|
11.2.5.2 不支持 order by 查询
select
|
|---|
11.2.5.3 不支持 group by 查询
select |
|---|
11.2.5.4 不支持having查询
select |
|---|
11.2.5.6 不支持多表联合查询
select |
|---|
11.2.5.7 不支持嵌套 select 查询
select 5000); |
|---|
11.2.5.8 不支持别名
select |
|---|
11.2.5.9其它不支持查询
· 不支持 join 查询;
· 不支持 union 查询;
· 不支持类似 select a+b from table where a > 1000 的查询;
· 不支持类似 select * from table where a+b > 1000 的查询;
· 不支持类似 select * from table where a >= b 的查询;
· 不支持其他未提到的查询。