
关注腾讯云大学,了解行业最新技术动态

戳阅读原文观看完整直播回顾
讲 师 介 绍

正现负责腾讯“神盾-联邦计算”平台的底层安全与隐私保护系统的设计与搭建,分别于2019年与2015年获得澳大利亚国立大学和清华大学的工学博士和工学学士学位,申请和拥有隐私保护相关专利十余篇,在Automatica, IEEE/ACM Transactions on Networking等国际学术期刊与会议上发表论文十余篇,研究兴趣包括联邦学习、面向隐私保护的分布式计算、多智能体网络系统等。
| 导语 在过去的几年中,我们见证了大数据及人工智能技术的飞速发展,许多机构却依旧苦于数据数量少、质量低等难题而无法将前沿理论商业化落地。助力像石油般宝贵的数据突破隐私保护的条框限制并实现其价值的流通,对相关产业的发展起着至关重要的作用。在上一篇文章中,我们简要介绍了腾讯“神盾-联邦计算”平台的诞生背景和数据安全与隐私保护技术亮点。这次,我们着重选取本产品首推的“非对称联邦学习” (Asymmetrical Federated Learning, AFL) 范式进行介绍。该范式旨在全面保护数据集的样本ID、特征和标签的隐私安全,彻底解除在不平衡的 (unbalanced) 联邦计算系统中,中小企业对敏感用户ID泄露问题的担忧。
一、研究背景
在风控、营销、推荐、AI等主流业务中,腾讯“神盾-联邦计算”平台以底层强有力的隐私保护技术为支撑,以上层先进高效的信息分享、数据挖掘、人工智能算法为出口,向包括企业、学校、医院和政府等在内的各类独立机构提供联邦计算系统的无门槛搭建、计算、建模和推理等服务。腾讯“神盾-联邦计算”平台旨在撮合有数据需求的业务方和有价值变现需求的数据方之间展开合作。在合作过程中,神盾秉承始终保持各机构原始数据安全的原则,令各机构公平地享受联邦计算成果。
为了达成以上目标,腾讯“神盾-联邦计算”平台在数年来的孵化和成长中,逐渐吸纳了数据安全与隐私保护领域的两大核心技术:
- 以不经意传输 (Oblivious Transfer, OT)、秘密分享 (Secret Sharing, SS) 和同态加密 (Homomorphic Encryption, HE) 为代表的安全多方计算 (Secure Multiparty Computation, MPC) 技术。该类技术通常以在分布式隐私数据之上的一般函数求值为目标,在半个多个世纪发展中渐渐形成了严格的精度、效率和安全性度量。
- 以联邦学习 (Federated Learning, FL) 为代表的面向隐私保护的分布式机器学习 (Privacy-Preserving Distributed Machine Learning, PPDML) 技术。该类技术通常以将现有的隐私保护技术巧妙地集成到经典的数据挖掘和统计学习算法中为目标。由于许多模型训练所基于的最优化及贪心算法计算量庞大,所以该类技术对高计算效率和低通信复杂度有着狂热的追求。
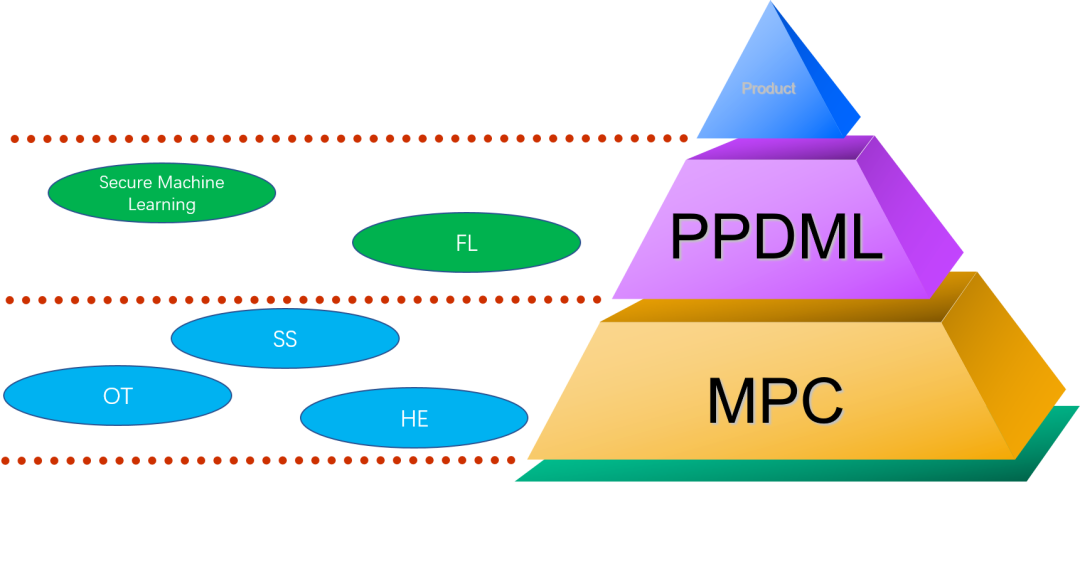
从上图可以看出,在腾讯“神盾-联邦计算”平台的底层技术栈中,PPDML与MPC并不仅仅是单纯的并列关系。正如以上第 (2) 条中提到,PPDML通常结合了MPC的诸多经典安全技术,对学业界常见的机器学习算法做隐私保护形式的改造。实际上,在许多实际业务场景中,尤其是现如今的金融风控和精准营销场景等中,相关大型企业已经无比擅长利用成型的机器学习系统,对自己掌握的用户的高维特征和历史行为标签做数据挖掘,最后基于挖掘得到的机器学习模型对新用户做业务预测,达到降低信用风险、打压黑灰产、扩大市场份额和减少获客成本等目的。因此,相对于MPC本身,与现行机器学习系统更贴近的PPDML技术拥有更强的实际业务场景诉求,并且,这种诉求更多来自于缺乏大规模、高质量数据集的中小企业。
以腾讯“神盾-联邦计算”平台频繁使用的PPDML下的FL技术为例。在纵向FL的标准范式 [1] 中,参与方依次执行以下步骤:
- 加密实体对齐 (encrypted entity alignment):参与方采用MPC技术获取所有参与方掌握的样本ID交集,而不暴露ID非交集内容。这里通常采用为MPC中的隐私集合求交 (Private Set Intersection, PSI) 技术。
- 加密模型训练 (encrypted model training):每一个参与方遵从预设的联邦协议,基于自己掌握的原始数据计算获得中间变量,将加密或混淆后的中间变量与其他参与方交互,以期合作训练获得高质量的机器学习模型。在联邦协议的执行过程中,各参与方的隐私数据集的特征和标签隐私被重点关注和保护。
以两方FL为例,上述的FL标准范式可以被下图表示:
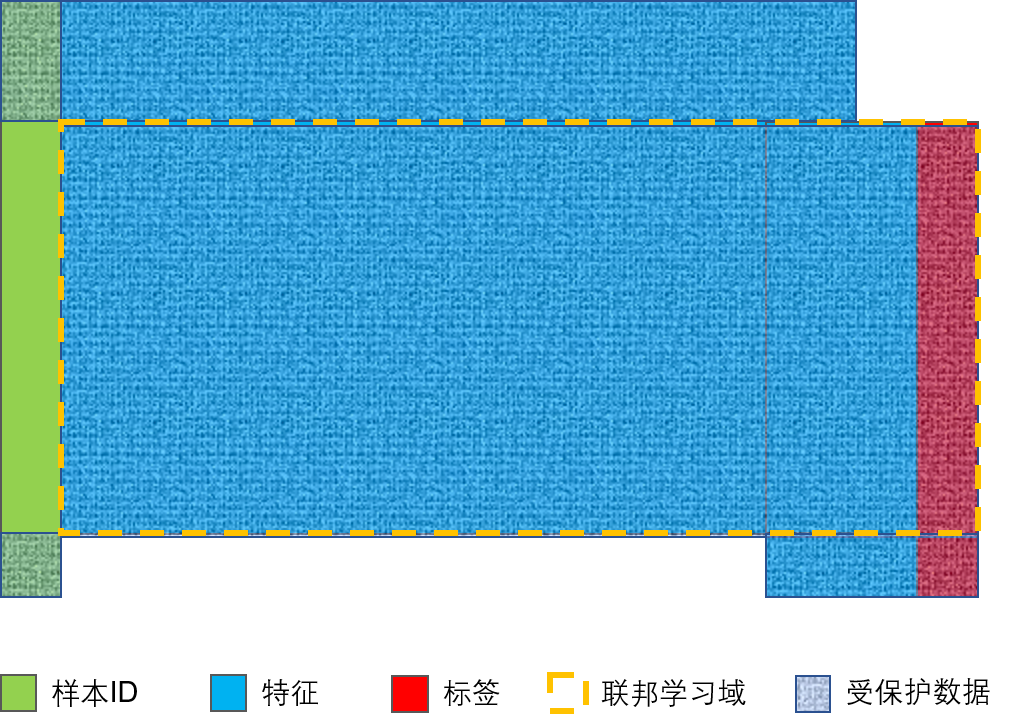
可以看出,两方的ID量级相当,被默认成一种强强联手形态的平衡的 (balanced) 多方知识分布。的确,FL标准范式通过第 (1) 步保证了样本ID非交集内容的隐私安全,通过第 (2) 步保证了两数据集的特征与标签隐私安全。然而,它却允许样本ID交集内容成为必向各方公开的信息。以下数值实验量化了FL标准范式的这种缺陷造成的样本ID隐私泄露程度。
假设样本ID全集为全国人手机号,共14亿个,而两参与方Alice和Bob各掌握8亿个手机号,分别是bc + cd和bc + ab。进一步地,我们假设双方有6亿手机号的交集bc。另有4亿手机号de不被双方所掌握。这种ID分布可以由下图表示:

那么,在接入FL标准范式前,若Alice在手机号全集中均匀随机的抽取一个ID,那么此ID在Bob所掌握的ID中的概率为
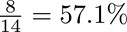
在接入FL标准范式后,同样的做法将使Alice基于观察给出三种不同推断:
Alice观察ID落在哪个区域 | 区域占比 | Alice猜测ID属于Bob掌握的概率 | 备注 |
|---|---|---|---|
(a, b) 或 (d, e) | 6 / 14 | 2 / 6 = ab / (ab + de) | Alice无法完全确认该ID的所属区间 |
(b, c) | 6 / 14 | 1 | Alice完全确认该ID属于交集,即属于Bob掌握 |
(c, d) | 2 / 14 | 1 | Alice完全确认该ID既不属于交集又被自己掌握,即Bob不掌握 |
综上,用条件概率方式计算得到此ID被Bob掌握的概率为
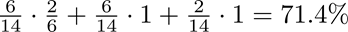
因此,接入FL标准范式使得Alice对Bob样本ID的知识增益为
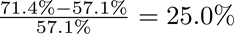
这25%也可视为Bob对Alice的隐私泄露量。该隐私泄露量并不高,貌似可接受。然而,在联邦计算的实际业务场景中,更多的是不平衡的多方知识分布,即强弱联邦系统。这时,该风险变得更为严重。通常,其中的强势方为社交媒体公司、大型国企和大型银行等大型机构,掌握较大的ID空间;而弱势方则为小型的游戏公司、借贷公司、保险公司和互联网平台,它们的ID空间较小,对于这些弱势方来说,掌握的样本ID可能是高额违约用户、高理赔客户、黑灰产账户等,每一条样本ID的获取都意味着高昂成本的付出,这些ID本身应当被视为最高等级的隐私信息之一。
在不平衡的联邦计算系统中,Bob的隐私泄露量会怎样变化?我们重新回到刚才的数值实验,令Bob为弱势的中小企业,其掌握有60万ID,其中与Alice的交集为50万。这种知识分布可以由下图表示:
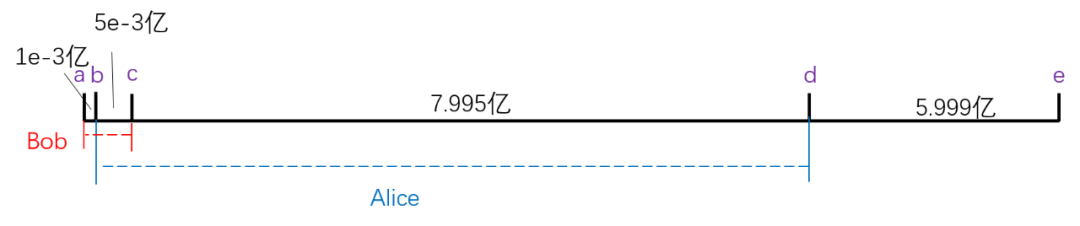
在这种情况下,接入联邦前,若Alice在手机号全集中均匀随机的抽取一个ID,那么此ID在Bob所掌握的ID中的概率仅为
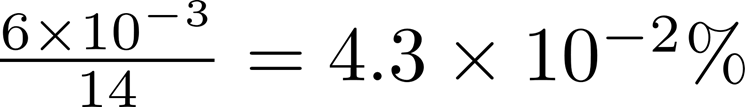
接入联邦后,Alice同样的猜测行为将形成以下条件概率分布
Alice观察ID落在哪个区域 | 区域占比 | Alice猜测ID属于Bob掌握的概率 | 备注 |
|---|---|---|---|
(a, b) 或 (d, e) | 6 / 14 | 0.001 / 6 | Alice无法完全确认该ID的所属区间 |
(b, c) | 0.005 / 14 | 1 | Alice完全确认该ID属于交集,即属于Bob掌握 |
(c, d) | 7.995 / 14 | 1 | Alice完全确认该ID既不属于交集又被自己掌握,即Bob不掌握 |
根据条件概率计算,此ID被Bob所掌握的概率变成
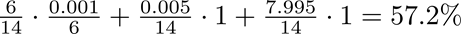
此时,Bob对Alice的隐私泄露量高达
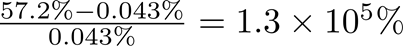
综上,当多方知识分布由平衡切换至不平衡时,Bob对Alice的隐私泄露量由可接受的25.0%提升至惊人的130000%。可见,在不平衡的联邦计算系统中,弱势方的隐私泄露量大大高于平衡态,增加了中小企业对接入联邦计算平台的安全顾虑。
为了解决实用联邦计算系统中的隐私保护缺陷,神盾率先提出非对称联邦学习范式,全方位保护弱势中小企业的隐私数据。
二、非对称联邦学习范式
与标准联邦学习范式相比,腾讯“神盾-联邦计算”平台独创的非对称联邦学习范式通过对原有的两个环节——加密实体对齐和加密模型训练——做针对性的非对称协议改造[2],实现对弱势方隐私数据的全面保护。接下来,我们依次介绍两环节的改造内容。
2.1 非对称加密实体对齐
在数据输入到非对称联邦计算系统后,首先要做的就是非对称版本的加密实体对齐环节。分别从两个参与方的角度去看:
- 在弱势方侧,由于精确交集的获知并不会对强势方隐私ID构成较大威胁,所以非对称范式允许精确交集的内容直接被弱势方拿到。我们称精确交集的元素为Genuine样本。
- 在强势方侧,根据数值实验,精确交集的获知将对弱势方造成严重的ID隐私泄露。作为折衷,非对称范式仅允许强势方拿到精确交集+混淆集合的内容。我们称混淆集合的元素为Dummy样本。
这种非对称加密实体对齐的输出分布可以从下图看出。

这种输出分布具备以下两个特点:
- 强势方无法从非对称加密实体对齐的输出集合中分辨哪些为Genuine样本,哪些为Dummy样本;
- 精确交集与混淆集合的大小比例,即Genuine与Dummy样本的数量比例,直接影响非对称范式对弱势方样本ID的隐私保护力度:当比例非常小时,精确交集远远小于混淆集合,强势方难以从输出分辨哪些为Genuine样本,弱势方的样本ID安全性极高;当比例升高时,这种分辨行为变得容易,弱势方样本ID的安全性持续降低;当比例为无穷时,非对称加密实体对齐退化为标准版本,不再具备保护弱势方的样本ID隐私的能力。
为了量化 (2) 中提到的精确与混淆比例,我们引入非对称指数λ,令其落在[0, 1],满足
(强势方ID数量 / 精确交集ID数量)^λ = (混淆集合ID数量 + 精确交集ID数量) / 精确交集ID数量
可见,当λ=0时,混淆集合为空,此时非对称对齐退化为标准对齐,安全性最低;λ越大,混淆集合越大,安全性越高;当λ=1时,混淆集合达到最大,安全性最高。
以下表格反映了数值实验中,λ=1的非对称联邦对Bob隐私泄露量的降低效果。
标准联邦学习范式 | 非对称联邦学习范式 | |
|---|---|---|
平衡联邦计算系统 | 25.0% | 25.0% |
不平衡联邦计算系统 | 130000% | 25.0% |
从以上表格可以看出,在不平衡的联邦计算系统中,神盾独创的非对称联邦学习范式将弱势方的隐私泄露量从130000%大幅降低至平衡联邦的水平25.0%,安全性大幅提升,彻底解除中小企业对接入联邦计算平台的安全顾虑。
值得一提的是,非对称加密实体对齐的具体实现可以由多种经典隐私保护技术完成,如1978年Pohlig Hellman提出的交换加密方法[3],或神盾独创的交换仿射密码。本篇文章中,我们不赘述相关实现原理。
2.2 非对称加密模型训练
从已介绍的非对称加密实体对齐环节可以看出,非对称改造使原有对齐方式失去了部分对齐功能,即强势方没有获得精确交集。这使得在后续的联邦加密模型训练环节中,每轮信息交互之后,强势方无法直接将逐样本的中间变量与对应样本精确匹配。为了能够继续保护精确交集信息不被强势方获知,又能准确执行后续加密模型训练环节,得到正确结果,腾讯“神盾-联邦计算”平台首次提出Genuine-with-Dummy方法,非对称化已有的加密模型训练环节。该方法的思想简述如下,在逐样本的中间变量的计算和交互时,满足:
- 在弱势方侧,对精确交集中的Genuine样本,遵从标准联邦协议执行计算,得到中间变量v;对混淆集合中的Dummy样本,根据计算机制捏造对应的不变元 (identity) e,例如加法群的0,乘法群的1和函数复合群的f(x)=x等。将v和e混合在一起发送给强势方。
- 在强势方侧,遵从标准联邦协议执行计算。
以下图为例。

在联邦协议的某个子程序subroutine()执行过程中,弱势方对每个Genuine样本计算标准中间变量v,并对每个Dummy样本捏造不变元e。将v和e混合在一起加密发送给强势方。在这个过程中,我们强调
- 由于不变元e具备不改变相应算子运算结果的性质,Genuine-with-Dummy方法保证了subroutine()的计算结果在有无e输入的情况下结果相同,进一步保证了非对称加密模型训练产生的模型效果与标准版本相同。
- 在现有的联邦协议中,e和v通常在发送前使用包括语义安全的同态密码系统在内的成熟隐私保护工具加密,如Paillier密码[4]和神盾独创的随机化迭代型仿射密码 (Randomized Iterative Affine Cipher)。在这种情况下,即便是对大量Dummy样本捏造相同的不变元e,加密得到的密文也各异,强势方无法从密文语义判断哪些样本为Dummy,持续保证Genuine样本的隐私安全。
以加密逻辑回归模型训练为例,我们知道,与其他广义线性模型相同,逻辑回归似然函数的梯度是标量向量乘积之和的形式,即
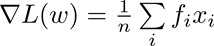
一种业界通用的联邦逻辑回归算法核心在于由标签持有方Bob计算、加密和发送逐样本的中间变量f给Alice,由Alice在密文空间计算局部梯度。为了实现非对称加密模型训练,在Genuine-with-Dummy方法的指导下,Bob对每个Dummy样本捏造f=e,其中e是加法不变元零。如下算法

这样,在无感知哪些样本为Dummy的前提下,Alice以非对称形式计算得到与标准范式相同的局部梯度结果。
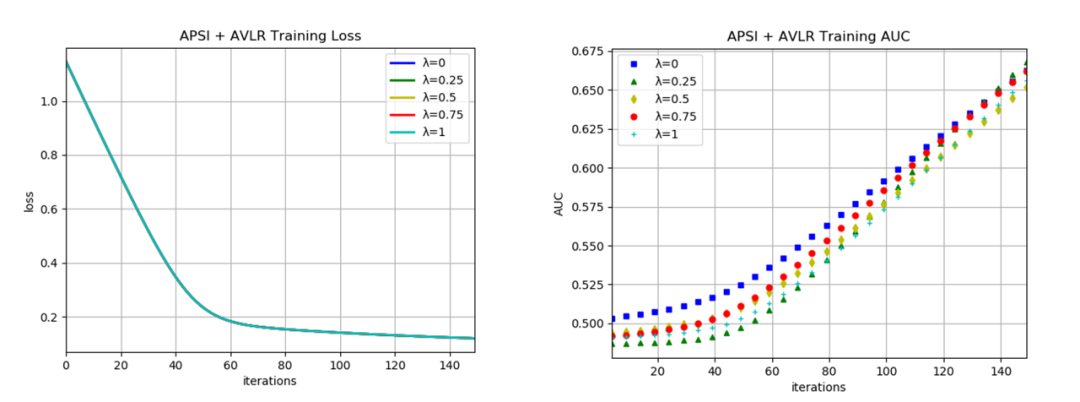
以下数值实验以MNIST数据集之上的逻辑回归为例,其中用到的底层联邦协议基于腾讯大数据团队研发的PowerFL联邦学习框架。所有实验均在500分钟内完成。这些实验反映了非对称联邦学习范式相对于标准范式具备保持计算结果精度的优点。
三、总结
这篇文章简介了腾讯“神盾-联邦计算”平台团队用新颖的角度定位到了业界通用的标准联邦学习范式中弱势方数据集隐私泄露问题,针对该问题,神盾首创非对称联邦学习范式,能够在保护弱势方数据样本ID隐私的前提下完成常见的联邦计算任务,并通过创新的Genuine-with-Dummy方法,保障非对称范式的计算成果逼近标准范式。
参考文献
- Yang, Qiang, et al. "Federated machine learning: Concept and applications." ACM Transactions on Intelligent Systems and Technology (TIST) 10.2 (2019): 1-19.
- Liu, Yang, Xiong Zhang, and Libin Wang. "Asymmetrically Vertical Federated Learning." arXiv preprint arXiv:2004.07427(2020).
- Pohlig, Stephen, and Martin Hellman. "An improved algorithm for computing logarithms over GF (p) and its cryptographic significance (Corresp.)." IEEE Transactions on Information Theory 24.1 (1978): 106-110.
- Paillier, Pascal. "Public-key cryptosystems based on composite degree residuosity classes." International conference on the theory and applications of cryptographic techniques. Springer, Berlin, Heidelberg, 1999.
