点击观看大咖分享
评判一个地方好坏的致命原则---体验感。同样,体验感也是网络游戏中不可或缺的元素。生活中我们通过旅行来放松身心缓解压力,换个城市最大的不同在于什么?在于人类对多元化场景的新奇体验带来的满足感。网络里多变的场景对我们视觉的冲击和吸引力更是被无限放大。极致场景体验感的背后一定站着一个支撑它的更伟大的GME。
GME游戏多媒体引擎,是腾讯音视频能力对游戏场景的对外输出的载体产品。具有稳定性的GME就像三角形的稳定性一样,两条边分别是面向终端的Pass服务,只接入一个客户端SDK就可以实现三角形的稳定性。GME的场景非常多,主要包括对战场景,语音游戏场景,国战指挥场景,音乐直播场景等。「腾讯云大学」邀请腾讯云高级工程师 曾维亿 介绍GME如何定制网络和编解码策略,去支持各种应用场景。
在之前的大咖分享直播课中,我们介绍了GME的基础技术方案,包括GME的核心功能和整体架构等,此次我们将让大家了解到GME内置的网络和编解码策略,以及当你要接入GME的时候如何正确使用。
1.2 GME功能介绍
以下为GME整体功能全景图,我们可以看到GME里包罗万象,涵盖了常见的所有音频能力。本次课程主要介绍网络部分,包括语音上行过程中的编码和下行过程中的解码及网络上行过程中的各种抗丢包,抗抖动策略。

1.3 网络与场景

因为网络传输受限最严重,客户要求可能很高,为了在实际有限能力范围内尽可能满足客户要求,需要平衡好时延和抗性,消耗和音质。比方游戏开黑场景,音质越高就越好么?其实不是,对于游戏策划来说,实时音频交流,是锦上添花的功能,他天然拥有那种“有当然更好,但是不能影响游戏本身的”的这种属性。所以低时延低消耗是最key的属性,但音质不是。所以我们会在保证沟通无障碍的前提下,会尽可能的把时延和消耗做低。又比如另一个极端场景直播场景,音质需要很高,但对时延和消耗,并不是那么在意
因此我们定制策略的首要准则,就是按照需求来提供能力。我们需要首先分析对场景最重要的因素然后针对性的制定策略,为达成最优场景。
场景分类:
一、是否支持传输音乐,这决定了网络编码的编码格式,码率和采样率
二、对于这个场景来说,时延更重要还是音质更重要,就可以决定这个网络的基本策略
此外还有一些细分策略比如是否需要支持互动等。主要为了预防大丢包场景还是高抖动场景。
2.1 网络传输,从信源编码开始
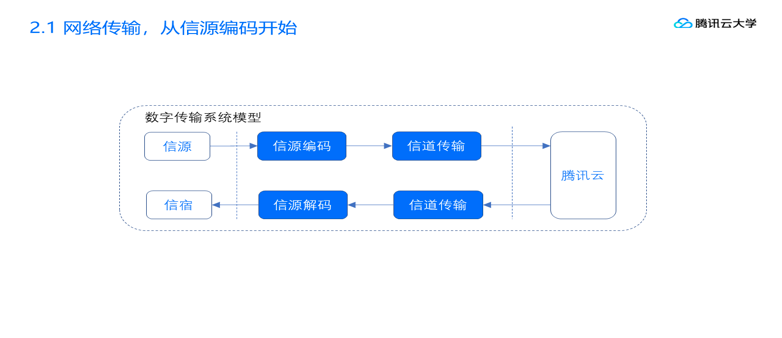
众所周知,数字音频信号如果不加压缩地直接进行传送,将会占用极大的带宽,所以需要信源编码器,在编码的过程中对冗余信号丢弃和信号压缩,可以大大减少需要传输的数据量。例如,语音数据一般是16k采样率单声道的,pcm裸流就是每秒16k个大B,转成小B乘以8就是 256kbps,还挺大的。但如果我们经过opus编码成20kbps,就减少到原有的十分之一。
2.1.1编码格式
历史上出现过很多编码格式,因为模型设计的不同,可细分为两类:人声编码和音乐编码
两者针对的分别是对应人类的发音模型与听觉模型进行编码设计,两者最好不要混用。所以,我们评估要用编码器在不同场景下的使用,第一个要看的就是我们要传输的内容是纯人声还是音乐。如果是纯人声的话,一般选用SpeechCodec,带音乐的话,选用AudioCodec
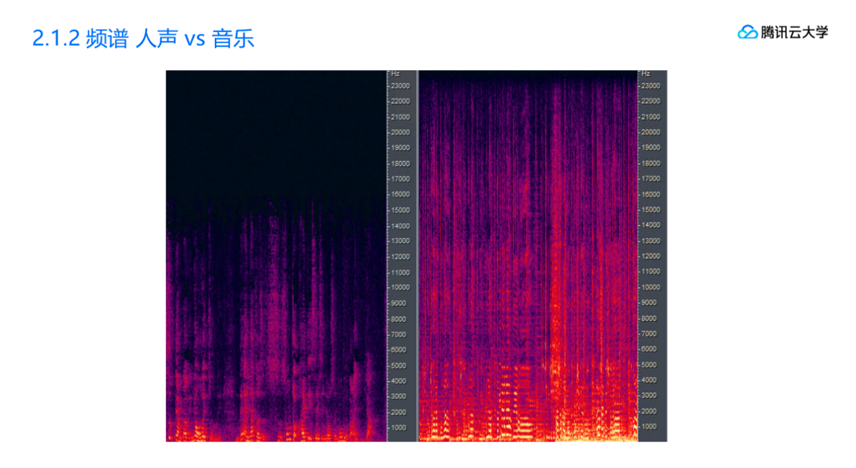
我们用两幅频谱图,来进一步展示人声和音乐的不同。
左边的是正常说话,右边是一首从QQ音乐下载的正常歌曲。可以看到人声的频谱较低,大部分在8k以下,而且信号是离散不连续的。而音乐的频谱覆盖到全频带,且信号连续,强度较大。
按照采样定律,需要完整还原信号的话,编码的采样率应该是频谱的两倍。
所以,业界称8k频谱对应的16khz采样率为宽带,用于纯人声场景。
24k频谱对应的采样率48khz为全频带,用于音乐场景。
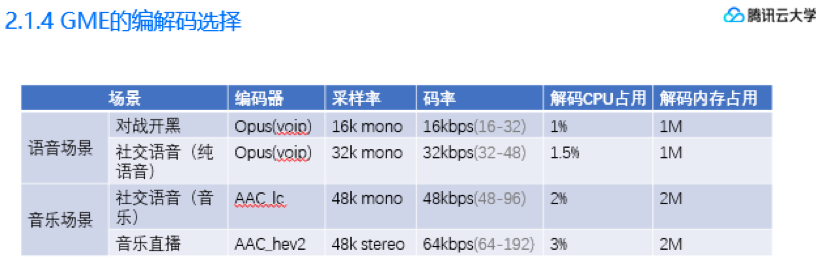
最终我们根据场景,为满足场景需求,选择的编解码策略表如下
在对战开黑场景(比方说打王者),我们以最低能耗为准则,将对游戏本身的影响降到最低;
当然如果用户对消耗不那么看重,或者说像狼人杀这种语音就是游戏本身,我们也支持超宽带编码,可以完美的还原人声。在国战指挥场景下,因为很多玩家都喜欢播一点战歌,如果场景带音乐我们选择使用AAC_lc进行音乐编码,码率也同步提升到48k,但同时编解码消耗也将上升。最后是音乐纯直播的高音质场景,我们使用音乐效果最好的AAC_hev2,码率上限也大大提升。
2.2 网络策略
下面开始讲述GME的网络对抗策略。音频信号,对稳定性的要求非常高,比视频高很多。
视频过程中,假设每秒25帧丢个10帧都不一定能看出来。但是在音频中,每秒50帧,哪怕只丢了一帧,听上去都非常明显传输过程中,我们面对的是一个不稳定的网络。主要的两个不稳定因素:
1、丢包。可能突然间10%的包就丢了。
2、抖动。可能突然间下一个包就延迟了100ms才来。
常见可以采用的网络抗丢包抗抖动策略包括,PLC FEC ARQ ARC UDT。我们后面将一一叙述。
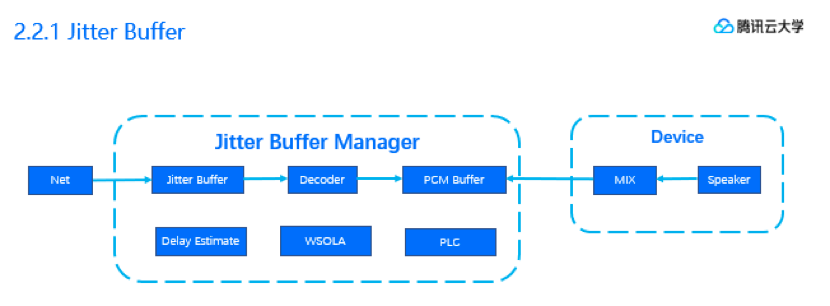
我们第一个要讲述的是音频传输接收端最重要的模块——Jitter Buffer。Jitter Buffer是完全后端的抗抖动机制。Jitter Buffer所在的位置如图所示。左边的是网络来数据,推进jitter buffer右边的是播放信号要数据走。这一推一拉,中间形成的这个Buffer,形成了整个链路中最重要的模块。
这个模块主要负责的是一个队列平衡。既不能让队列满(这样会形成丢包/跳帧),又不能让队列空(这样会形成播放静音帧)。
主要手段有:
1、网络抖动和播放延迟估计
通过一定的算法去预测Buffer内的可播放缓存是正在增加还是减少。
2、变时不变调处理;
通过预测,在收包量不够播放的时候,拉伸减速播放,在收包量过多的时候,压缩加速播放。
3、音频丢包补偿;
主要技术有前后帧差值、基于混响滤波器等来实现数据包的填充,比填充静音效果好很多,但是分数一定会有所下降,另外可抗的丢包率比较有限大概为5%左右。
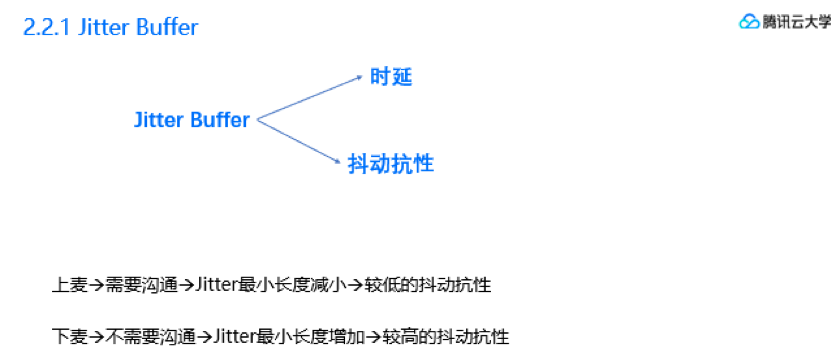
做音频传输的,最头疼就是怎么去定Jitter Buffer的最小长度。长度大,时延就大;长度短了,抗性就低。例如:如果当前Buffer的长度是200ms,但是突然抖动有1000ms(就意味着有1秒钟的没有音频数据来),中间这800ms的空档不管是拉长还是补帧都是补不过来的。所以我们的解决办法,还是回到场景,针对场景制定不同的Buffer长度。
在场景上,差一点主要在于,是否存在双向沟通。如果本地只收听,不上行,那么时延并不是很重要,就像平时家里收看电视节目一样,给个10秒的延时也发现不了。
但如果需要上行,即存在沟通互动,那必须保证延时在500ms以内,否则会出现沟通障碍。
所以后面我会介绍到,GME在下麦时设置的Jitter最小长度要远大于上麦时,以提供更好的网络抖动抗性。比方说直播场景,上麦的时候Jitter设置为400ms,保证沟通,下麦的时候Jitter就直接去到1000ms,保证有很好的抖动抗性。
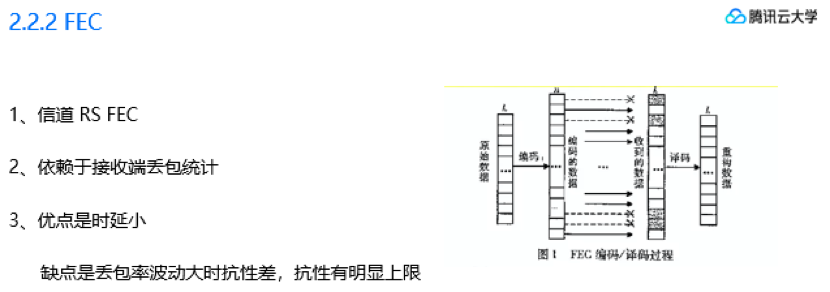
FEC是前后端配合的抗丢包机制。分为信源FEC和信道FEC两种。GME目前只使用了信道FEC原理,就是如果网络上有一定比例的丢包,那我就每X个包通过算法生成Y个纠错包,然后把X+Y个包一起发出去,如果丢包率满足这X+Y个包中,有任意X个包到达,就可以通过算法还原出原来的X个包。比方说,我们要发4个包,如果接收端检测到丢包率是25%,那我们给他额外的编1个包,5个包一起发出,5个包中只要有4个到达,就可以还原出来原来的4个包。
FEC的最大优点是时延小,因为所有的数据都不涉及重传或者确认,一直发就可以了。
缺点:
一是需要接收端反馈丢包率,所以对突发抗性较差。
二是他的抗性是有上限的。比方说现在是4+1,就是5个包里能到4个,就相当于扛25%丢包,但4+4只能扛50%丢包,如果要到75%,就需要4+12,这种冗余包量对网络来说是不可接受的。
另外,4+4就真能顶50%么?肯定不是,因为:
1、整个过程是依赖于丢包统计的,丢包率统计也可能丢失;
2、丢包率是统计意义上的,丢包率25%并不意味着5个包就一定能到达其中4个;
3、丢包率突变,很难及时响应。
所以,这里我们的策略是,快响应,慢恢复。简单说就是一旦检测到丢包率上升,马上给他加到4+4,然后在一个相对长的时间段内,如果丢包率都平稳,再慢慢降到合理的水平。
GME目前使用FEC的上限是4+4,可以扛30%丢包。
2.2.3 ARQ
ARQ也是前后端配合的抗丢包策略。
我们目前使用的是基于NACK的选择性重传ARQ。
选择性重传的ARQ对比FAC省流量做到有条件的选择重传。这个条件依赖于RTT和Jitter Buffer的严密配合。
第一个事就是如何发起重传条件,我们在接收端有一个收包统计,定时去检查未到达的包。如果收包缓冲里还可以播放的音频帧长度大于一个RTT,那么重传是可能成功的,这个时候通过NACK发起一个重传请求。
第二个事就是重传间隔,我们需要保证两次重传的间隔至少在一个RTT以上;
第三个事就是重传反哺Jitter Buffer的调整,举个例子,如果重传两次都没能传过来,而当前收包缓冲里留存的已经不够两个RTT了,那么在产生丢包PLC的同时,也需要增大Jitter Buffer。
自动重传最大毛病就在于,RTT过大的场景下可用性会极度的降低,因为很多丢包都会因为重传时间超过了播放缓存,而无法触发重传。另一个缺点是缺乏拥塞机制,在拥塞丢包时会让拥塞更加严重。

下面我们介绍UDT。
UDT是一种基于UDP协议来实现的可靠传输。
整体流程跟TCP协议类似,对比TCP只为两个字:公平。传统的TCP在高BDP网络下,没法做到公平。而UDT相当于是TCP的优化版,他可以更充分的利用当前网络的资源。
UDT是基于ACK实现的,所以不存在在RTT过大的场景下的不适用性。
但问题是在于,发端的发包频率,是受制于ACK的到达的。所以时延没有办法压到很低,即使在无损网络下,网络耗时也不会低于两个RTT。所以UDT比较适合天然就不介意大延时的场景,比方说我们刚才提到的音乐直播。尤其是1vN单向的音乐直播
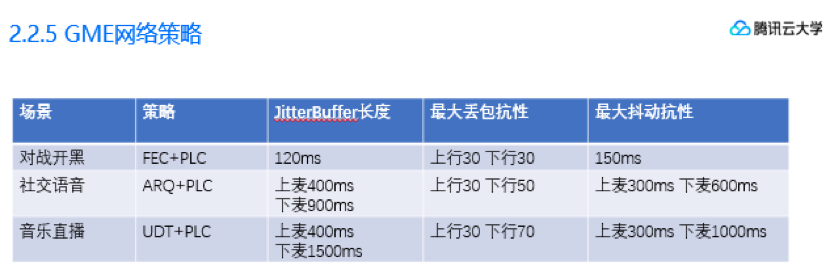
最终我们根据场景,选择的网络策略表如下:
在对战开黑场景(比方说打王者),我们以最低时延为准则,选用FEC+PLC的纠错方式,并且基于玩家玩对战游戏时网络情况一般不会过差,给FEC冗余数据量加了一个4+4的上限,相应的,抗丢包能力也就最多到30%;
然后在社交语音类的场景,我们选用了ARQ+PLC的网络策略,有较好的网络抗性和省流量兼顾了音质和沟通需求。
最后,纯直播的高音质场景,我们使用音乐效果最好的AAC_hev2,配合稳定性最好的UDT,提供的是最好的直播效果。
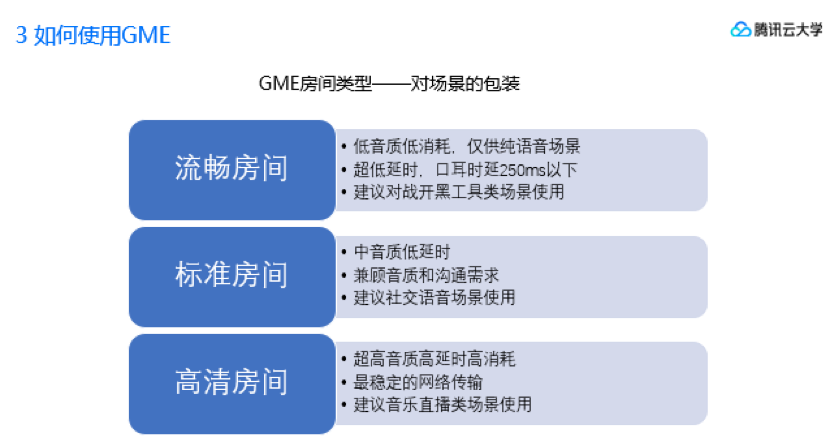
为了简化开发者使用,GME提供了房间类型供开发者调用时选择,具体对应功能如下表:
简单的建议如下:
1、如果是游戏开黑场景,或者明确不带音乐元素(包括清唱元素或者放战歌),建议用流畅房间;
2、如果项目是社交游戏,或带点音乐甚至语音就是游戏本身,建议用标准房间;
3、如果项目主要内容就是语音直播,那么建议用高清房间。
另外可以看到,GME默认提供的房间类型是内置能力的一个子集。本课程中所有的内容GME都是后台可控的,感谢观看。
问卷
为了给广大开发者提供最实用、最热门前沿、最干货的视频教程,请让我们听到你的需要,感谢您的时间!点击填写 问卷

腾讯云大学是腾讯云旗下面向云生态用户的一站式学习成长平台。腾讯云大学大咖分享邀请行业技术大咖,为你提供免费、专业、行业最新技术动态分享。