说明
本文描述问题及解决方法同样适用于 腾讯云 Elasticsearch Service(ES)。
方案名称
ES多轮分批融合迁移方案(ES索引级别融合迁移方案)
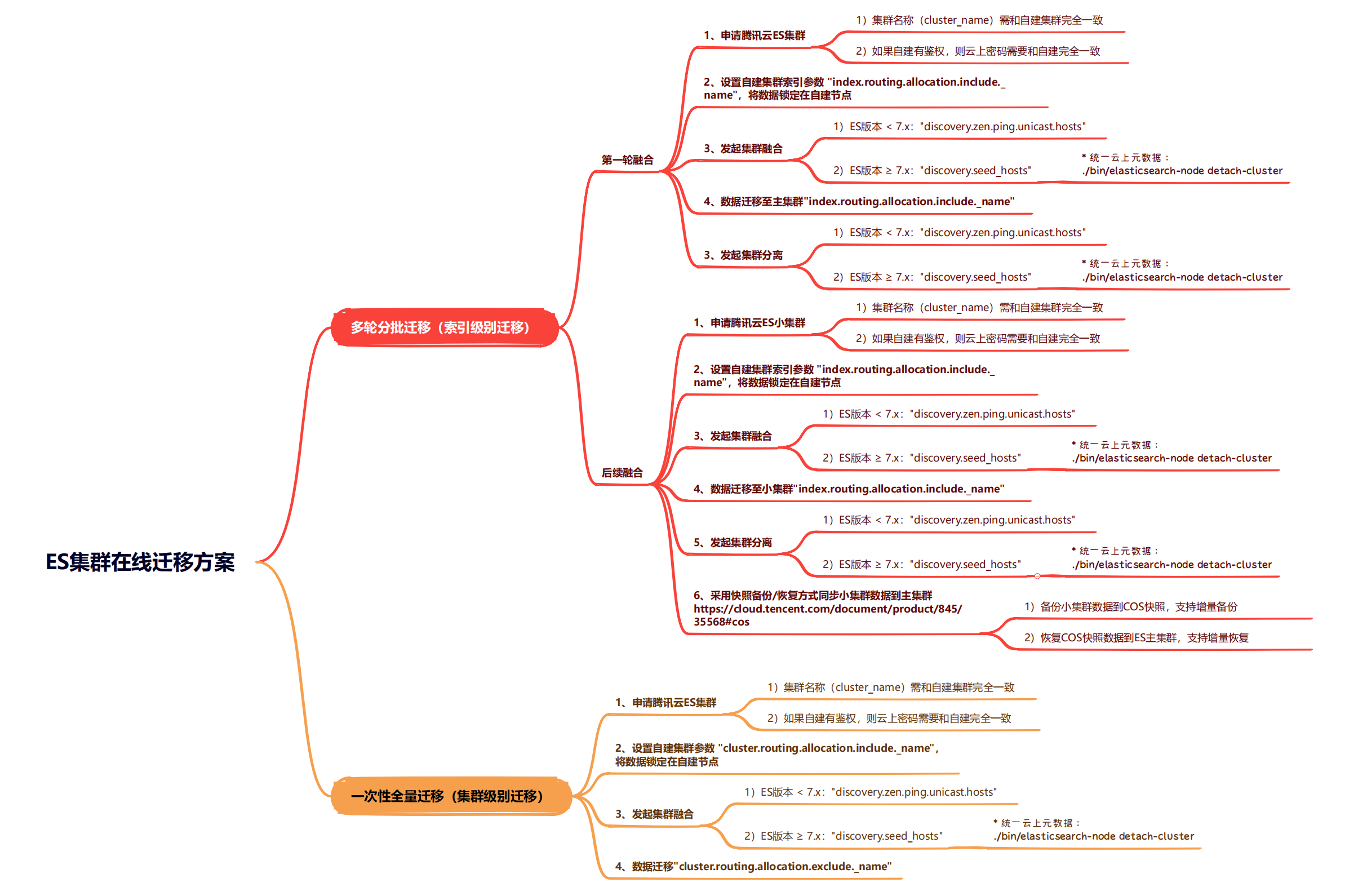
方案风险
- 集群融合期间,云上集群不可进行变更,比如升降配置、版本升级,否则会有集群不可用的风险;
- 集群融合期间,不可新建索引,否则分片会被分配到云上,将无法迁回到自建;
- 两个集群分离后,该云上集群不可再重新融合。如集群分离后有新的迁移需求,云上需要再新建集群进行融合操作,否则会有数据丢失的风险;
- 此方案除非是业务强需求,原则上不推荐。
环境配置
自建ES环境
● 版本
Elasticsearch版本:7.7.0
● 配置
节点数量:3
内存:4G
硬盘:高性能云盘 50G
CPU核心数:2
云上ES环境
● 版本
Elasticsearch版本:7.10.1(腾讯云 Elasticsearch Service 基础版)
● 配置
节点数量:3
内存:4G
硬盘:高性能云盘 20G
CPU核心数:2
1. 集群信息收集
集群名称 | 集群版本 | 节点信息 | 云上ID | 迁移方案 |
|---|---|---|---|---|
tencent-drill(自建) | 7.7.0 | 10.0.0.10 node-0110.0.0.29 node-0210.0.0.45 node-03 | / | / |
tencent-drill | 7.10.1 | 10.0.0.42 166791864200329513210.0.0.36 166791864200329493210.0.0.33 1667918642003295032 | es-7k9lokog | 首次融合迁移 |
tencent-drill-once | 7.10.1 | 10.0.0.41 166791956600329993210.0.0.35 166791956600329983210.0.0.32 1667919566003300032 | es-fqetcgvk | 二次融合迁移 |
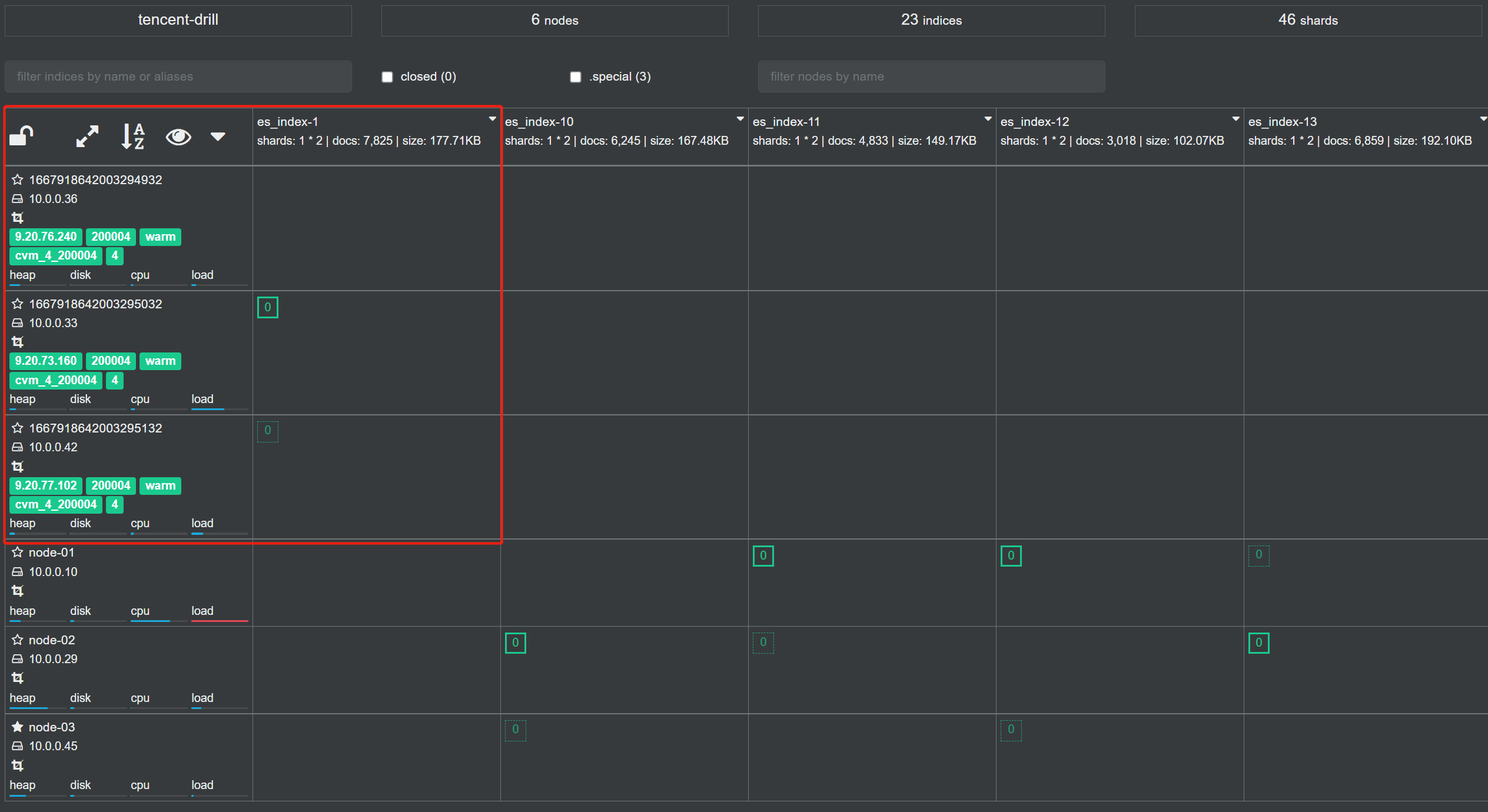
2. 自建集群情况
集群情况:
一共3个节点

索引情况:
一共20个索引,数据在持续写入

3. 首次融合迁移
1、锁定源端数据
对自建集群设置索引分片分配属性策略
curl -H "Content-Type: application/json" -XPUT 10.0.0.10:9200/_all/_settings?pretty -d '{
"index.routing.allocation.include._name" : "node-01, node-02, node-03"
}'
2、集群融合
集群融合,修改云上集群的配置文件,追加自建集群的节点ip
该操作执行完,集群不会正式融合,还需要统一集群元数据
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-7k9lokog",
"operator": "daemonyue",
"es_config": {
"discovery.seed_hosts": "[\"10.0.0.10:9300\", \"10.0.0.29:9300\", \"10.0.0.45:9300\", \"10.0.0.42:9300\", \"10.0.0.36:9300\", \"10.0.0.33:9300\"]"
},
"restart_type": "full_cluster_restart"
}'
3、初始化元数据
重启后,在腾讯云集群的cvm上执行
su - c_log
killall /data/c_log/repository/jdk/kona11.0.9.1.b1/bin/java
cd /data1/containers/*/es/
./bin/elasticsearch-node detach-cluster (选择y)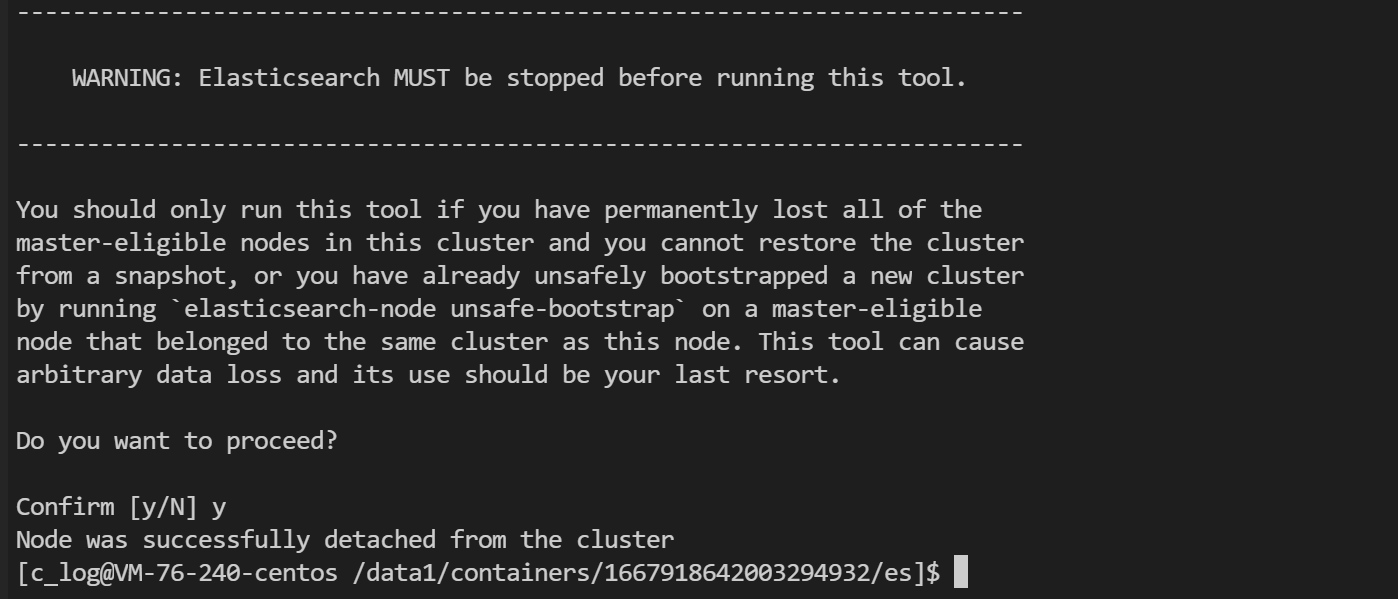
初始化完云上集群元数据之后,自建与云上集群融合成功

4、开始迁移数据
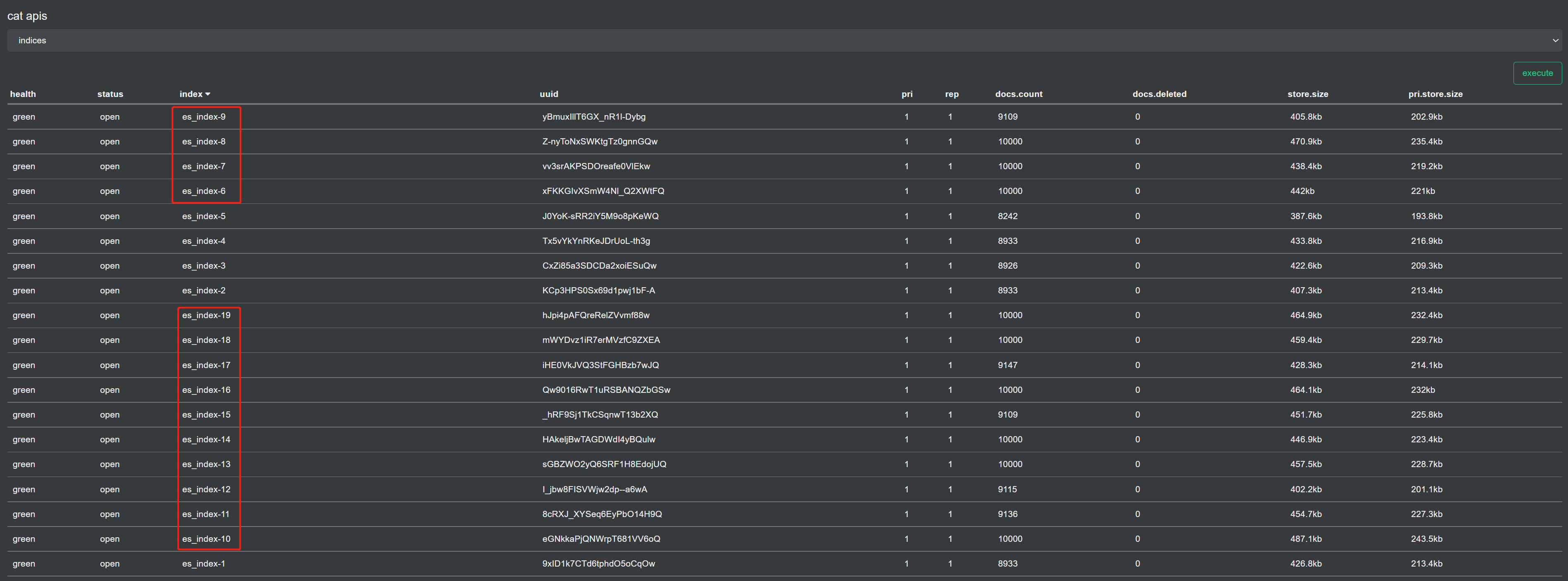
这里首次融合迁移我们只迁5个索引:
curl -H "Content-Type: application/json" -XPUT 10.0.0.10:9200/es_index-1,es_index-2,es_index-3,es_index-4,es_index-5/_settings?pretty -d '{
"index.routing.allocation.include._name" : "1667918642003295132, 1667918642003294932, 1667918642003295032"
}'
发起迁移之后,数据迁移到了云上。
5、分离集群
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-7k9lokog",
"operator": "daemonyue",
"es_config": {
"gateway.auto_import_dangling_indices": "true",
"discovery.seed_hosts": "null"
},
"restart_type": "full_cluster_restart"
}'6、初始化元数据
重启后,在腾讯云集群的cvm上执行
su - c_log
killall /data/c_log/repository/jdk/kona11.0.9.1.b1/bin/java
cd /data1/containers/*/es/
mkdir ~/_statebak
mv data/nodes/0/_state/* ~/_statebak成功分离后,索引正常,符合预期。

4. 二次融合迁移
1、锁定源端数据
对自建集群设置索引分片分配属性策略
curl -H "Content-Type: application/json" -XPUT 10.0.0.10:9200/_all/_settings?pretty -d '{
"index.routing.allocation.include._name" : "node-01, node-02, node-03"
}'
2、集群融合
修改云上集群的配置文件,追加自建集群的节点ip
该操作执行完,集群不会正式融合,还需要统一集群元数据
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-fqetcgvk",
"operator": "daemonyue",
"es_config": {
"discovery.seed_hosts": "[\"10.0.0.10:9300\", \"10.0.0.29:9300\", \"10.0.0.45:9300\", \"10.0.0.41:9300\", \"10.0.0.35:9300\", \"10.0.0.32:9300\"]"
},
"restart_type": "full_cluster_restart"
}'
3、初始化元数据
重启后,在腾讯云集群的cvm上执行
su - c_log
killall /data/c_log/repository/jdk/kona11.0.9.1.b1/bin/java
cd /data1/containers/*/es/
./bin/elasticsearch-node detach-cluster (选择y)
初始化完云上集群元数据之后,自建与云上集群融合成功
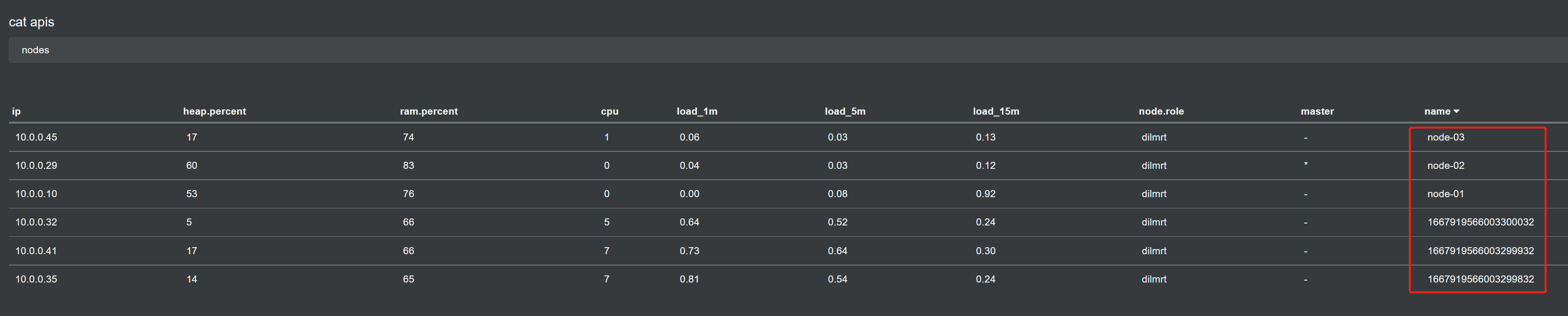
4、开始迁移数据
二次融合迁移我们迁7个索引:
curl -H "Content-Type: application/json" -XPUT 10.0.0.10:9200/es_index-6,es_index-7,es_index-8,es_index-9,es_index-10,es_index-11,es_index-12/_settings?pretty -d '{
"index.routing.allocation.include._name" : "1667919566003299932, 1667919566003299832, 1667919566003300032"
}'
发起迁移之后,数据迁移到了云上。

5、分离集群
curl localhost:5100/cluster/update -d '{
"cluster_name": "es-fqetcgvk",
"operator": "daemonyue",
"es_config": {
"gateway.auto_import_dangling_indices": "true",
"discovery.seed_hosts": "null"
},
"restart_type": "full_cluster_restart"
}'6、初始化元数据
重启后,在腾讯云集群的cvm上执行
su - c_log
killall /data/c_log/repository/jdk/kona11.0.9.1.b1/bin/java
cd /data1/containers/*/es/
mkdir ~/_statebak
mv data/nodes/0/_state/* ~/_statebak成功分离后,索引正常,符合预期。
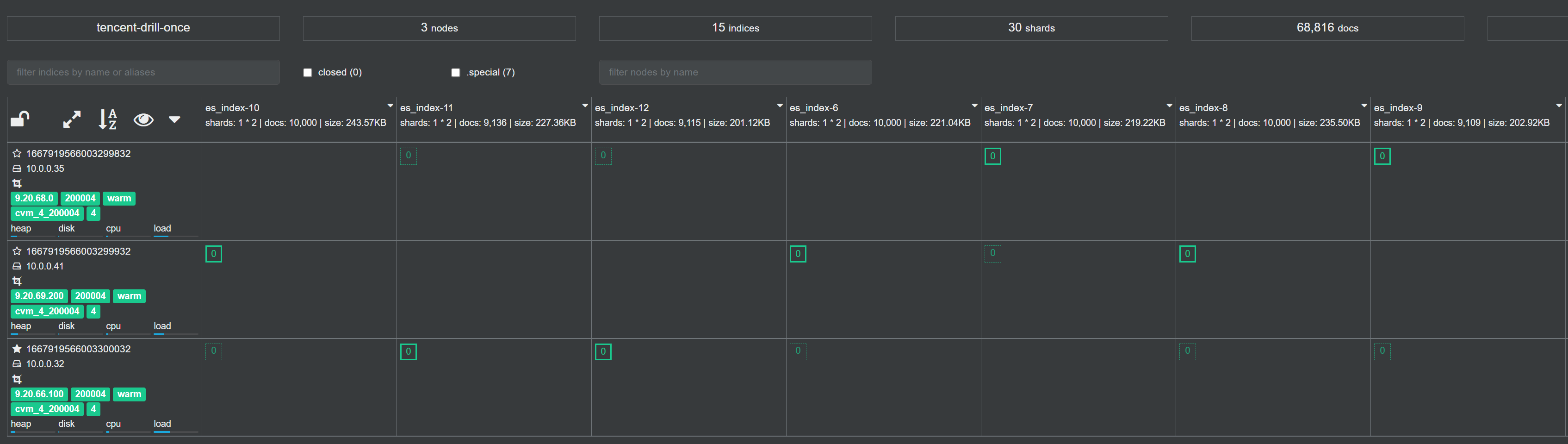
5. 通过快照迁移数据
二次融合迁移之后,数据迁移到了云上新建的小集群里,但由于数据还需要整合到云上主集群,所以还有一步快照迁移的操作。
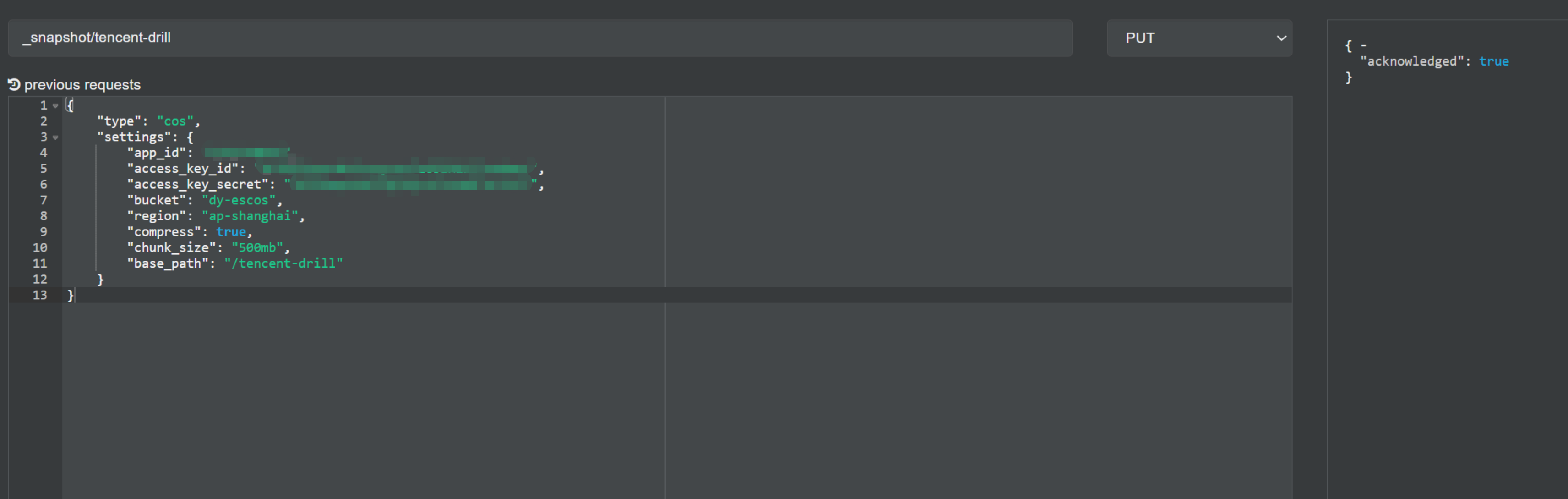
1、 在云上小集群创建快照仓库
PUT _snapshot/tencent-drill
{
"type": "cos",
"settings": {
"app_id": "xxxxxxxxxx",
"access_key_id": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"access_key_secret": "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",
"bucket": "dy-escos",
"region": "ap-shanghai",
"compress": true,
"chunk_size": "500mb",
"base_path": "/tencent-drill"
}
}
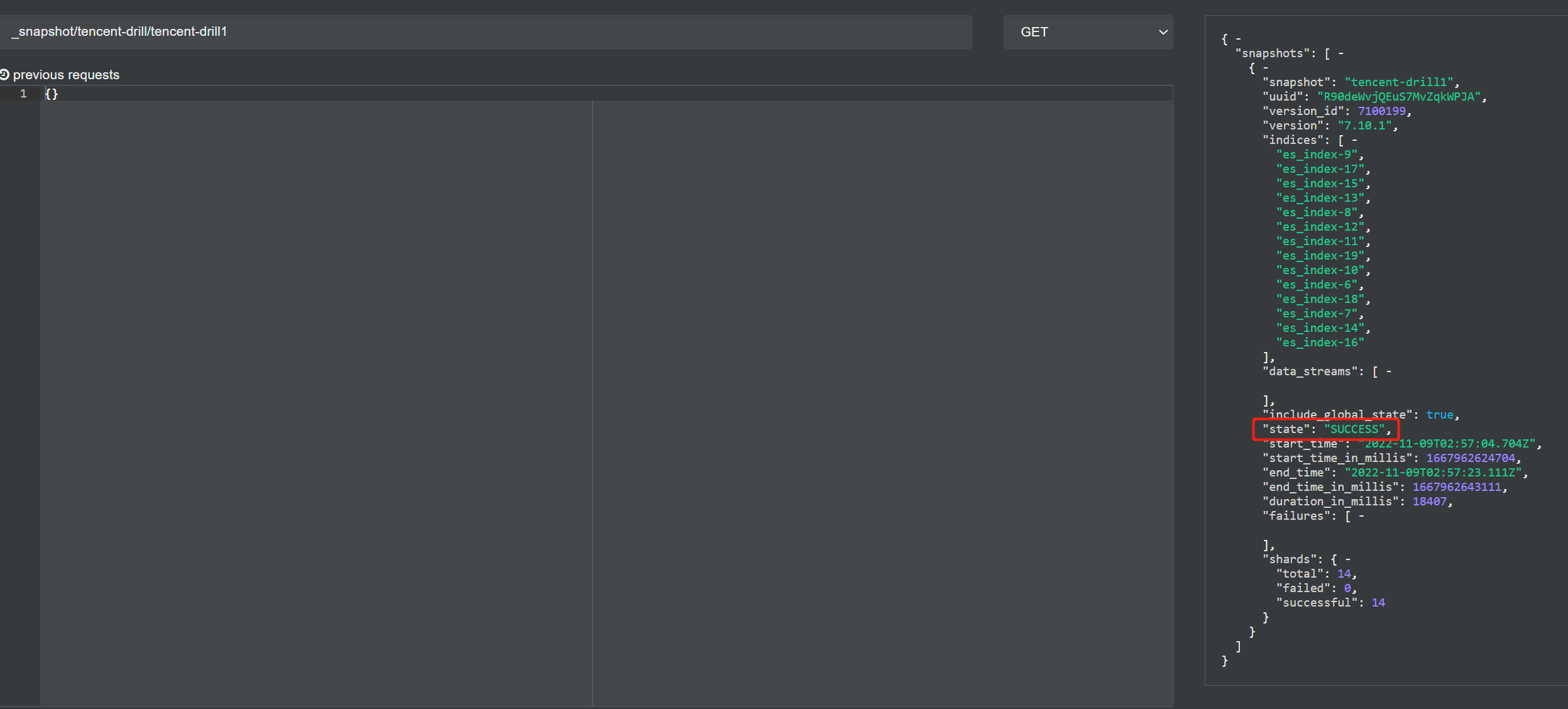
2、 发起快照备份
PUT _snapshot/tencent-drill/tencent-drill1
{
"indices": "es_index-6,es_index-7,es_index-8,es_index-9,es_index-10,es_index-11,es_index-12,es_index-13,es_index-14,es_index-15,es_index-16,es_index-17,es_index-18,es_index-19"
}
备份成功:
3、在云上主集群创建快照仓库
4、发起快照恢复
POST _snapshot/tencent-drill/tencent-drill1/_restore
{
"ignore_index_settings": [
"index.routing.allocation.include._name"
]
}
恢复完成,数据条数符合预期: