分享一个轻量的小工具,10MB 左右,能够帮助你直观的了解大模型 Token 的计算方法。
希望能够帮助到想了解或者正在规划模型 API 使用成本的你。
写在前面
之所以折腾这个小工具,是因为有朋友和我提问,大模型 API 的 Token 到底是怎么计算的。
好像是中文字符占 Token 占的多,英文占的少,有没有直观一些的工具,或者更详细一些的资料。
所以,我将 OpenAI 官方的 “tokenizer” 页面进行了汉化,并封装成了可独立运行的小工具(~10MB),让你可以更快速、方便的使用这个工具来“计算 Token”。
虽然主要是计算 GPT 3.5/4 以及之前的古老模型的,但是在 OpenAI 产品成为事实标准的现在,差不多是通用计算方案了。
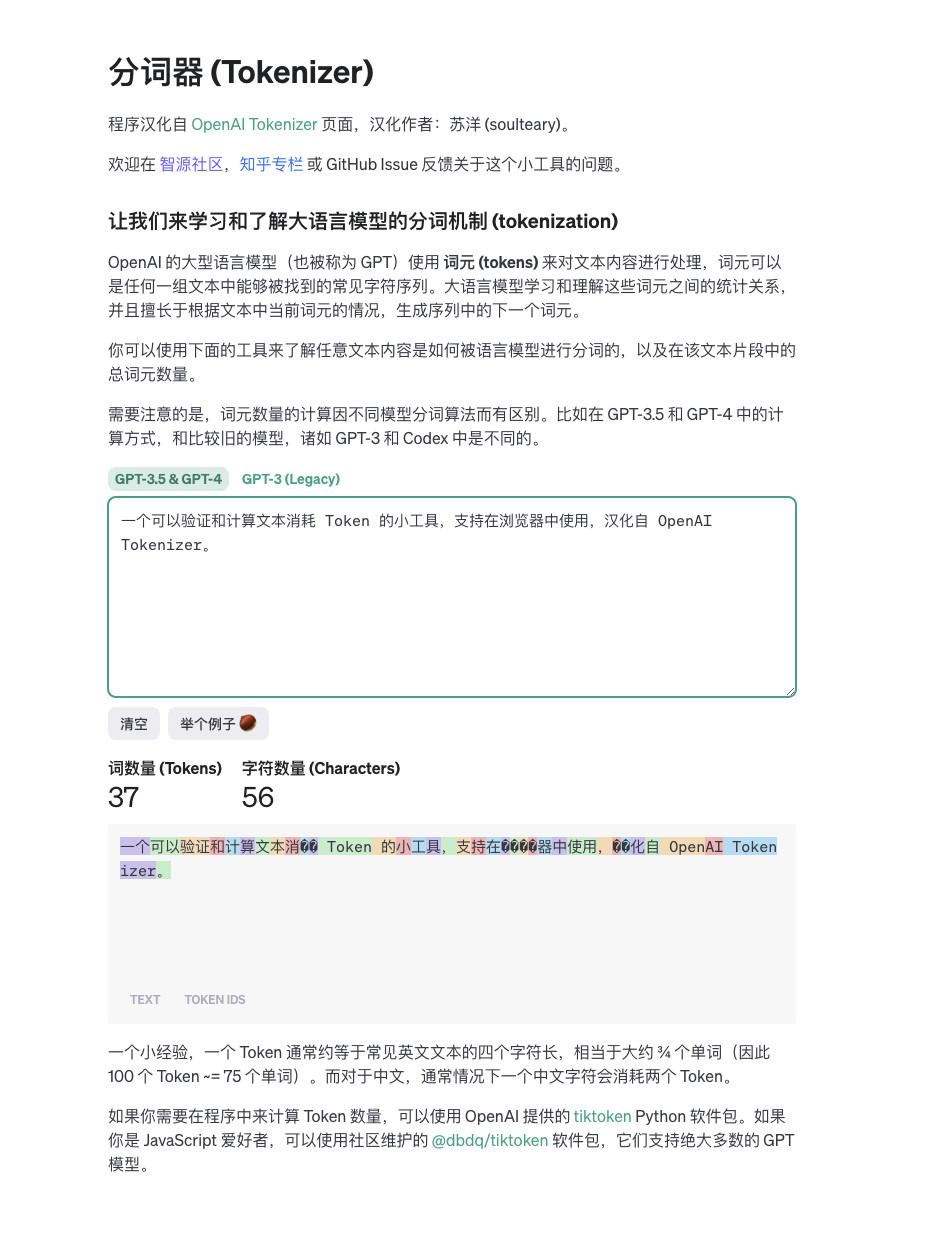
我将项目开源在了 GitHub,有需要可以自取:
https://github.com/soulteary/ai-token-calculator
如果你觉得项目不错,别忘记一键三连 🌟。
工具使用
这里介绍两种使用方式,先来聊聊常规使用。
直接执行可执行文件
第一种使用方法,是从 GitHub 的发布页面 下载适合你操作系统的可执行文件,然后解压缩执行。
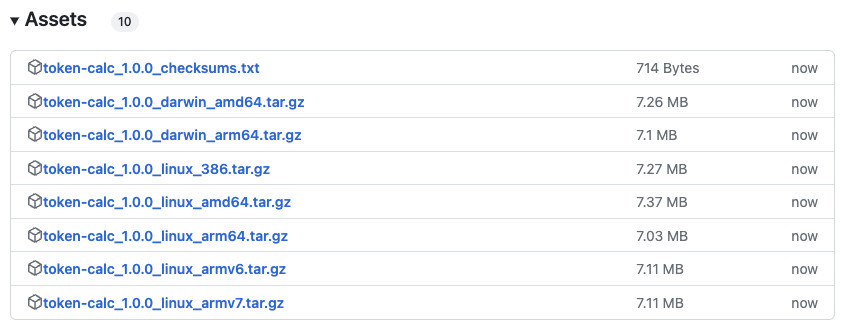
当我们解压缩压缩包之后,会得到 token-calc 文件。我们执行它就行 ./token-calc,默认情况下,程序会输出类似下面的日志:
2023/12/28 11:22:15 The PORT environment variable is empty, using the default port: 8080
2023/12/28 11:22:15 github.com/soulteary/ai-token-calculator has started 🚀当看到类似上面的日志输出时,我们打开浏览器,访问 http://localhost:8080 ,就能够直接看到结果啦。
如果你本地的 8080 端口被占用,我们可以启动的时候在 PORT 环境变量中指定一个新的端口,比如 PORT=8090 ./token-calc。
然后,再次执行程序,程序的端口就切换成了 8090 啦,将浏览器中的访问地址修改为 http://localhost:8090 即可。
使用 Docker 运行程序
我们也可以通过 Docker 来运行这个程序,相比较直接下载程序,镜像只比原始之心程序最多大 3MB,镜像整体在 10MB 尺寸。
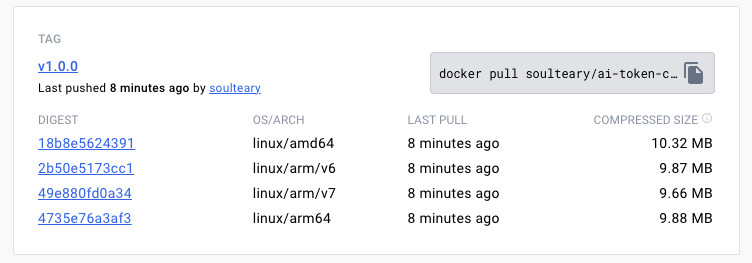
我们可以使用下面的方式,来快速下载程序镜像:
docker pull soulteary/ai-token-calculator:v1.0.0接着,执行下面的命令,就能够临时性的启动一个监听 8080 端口的服务啦:
docker run -p 8080:8080 soulteary/ai-token-calculator:v1.0.0如果你想调整端口,可以修改命令中的端口,比如还是将本地的端口改为 8090:
docker run -p 8090:8080 soulteary/ai-token-calculator:v1.0.0如果你想持久的在系统后台运行这个服务,可以运行下面的命令:
docker run -d -p 8090:8080 --restart=always --name=token-calc soulteary/ai-token-calculator:v1.0.0当你想关闭这个服务,也只需执行下面的命令就好啦:
docker stop token-calcDocker Compose
相比使用命令,如果你更喜欢使用配置,可以使用下面的 docker-compose.yml 配置文件:
version: "3"
services:
web:
image: soulteary/ai-token-calculator:v1.0.0
ports:
- "8080:8080"
将上面的内容保存为 docker-compose.yml,然后执行 docker compose up,不出意外,你也将看到下面的输出内容:
# docker compose up
[+] Building 0.0s (0/0) docker:desktop-linux
[+] Running 1/0
✔ Container ai-token-calculator-web-1 Recreated 0.0s
Attaching to ai-token-calculator-web-1
ai-token-calculator-web-1 | 2023/12/28 11:55:12 The PORT environment variable is empty, using the default port: 8080
ai-token-calculator-web-1 | 2023/12/28 11:55:12 github.com/soulteary/ai-token-calculator has started 🚀接着,访问浏览器中的地址就可以使用啦。
关于模型 Token 的计算方式
关于 Token,虽然不同的模型有不同的计算(计费)方式,但常见的终归是这么四种:gpt2、p50k_base、p50k_edit、r50k_base、cl100k_base。
在 OpenAI 官方的项目 openai/tiktoken 中,我们能够找到官方是如何使用 Rust 来快速计算文本包含 Token 数量的。不过,如果你想了解具体哪些模型用上述的具体算法来进行计算,我更推荐阅读社区项目 dqbd/tiktoken的代码(dqbd/tiktoken/js/src/core.ts)
export function getEncodingNameForModel(model: TiktokenModel) {
switch (model) {
case "gpt2": {
return "gpt2";
}
case "code-cushman-001":
case "code-cushman-002":
case "code-davinci-001":
case "code-davinci-002":
case "cushman-codex":
case "davinci-codex":
case "davinci-002":
case "text-davinci-002":
case "text-davinci-003": {
return "p50k_base";
}
case "code-davinci-edit-001":
case "text-davinci-edit-001": {
return "p50k_edit";
}
case "ada":
case "babbage":
case "babbage-002":
case "code-search-ada-code-001":
case "code-search-babbage-code-001":
case "curie":
case "davinci":
case "text-ada-001":
case "text-babbage-001":
case "text-curie-001":
case "text-davinci-001":
case "text-search-ada-doc-001":
case "text-search-babbage-doc-001":
case "text-search-curie-doc-001":
case "text-search-davinci-doc-001":
case "text-similarity-ada-001":
case "text-similarity-babbage-001":
case "text-similarity-curie-001":
case "text-similarity-davinci-001": {
return "r50k_base";
}
case "gpt-3.5-turbo-16k-0613":
case "gpt-3.5-turbo-16k":
case "gpt-3.5-turbo-0613":
case "gpt-3.5-turbo-0301":
case "gpt-3.5-turbo":
case "gpt-4-32k-0613":
case "gpt-4-32k-0314":
case "gpt-4-32k":
case "gpt-4-0613":
case "gpt-4-0314":
case "gpt-4":
case "gpt-3.5-turbo-1106":
case "gpt-35-turbo":
case "gpt-4-1106-preview":
case "gpt-4-vision-preview":
case "text-embedding-ada-002": {
return "cl100k_base";
}
default:
never(model);
throw new Error("Unknown model");
}
}上面的配置就是实际我们在使用各种模型时候,Token 的计算方式了,某种程度上来看,也是我们的模型 API 使用成本的计算方式。
当然,实际使用的时候,各种程序或多或少还会按照自己的习惯添加几个字符,所以如果我们的模型有一个具体的字符限制,建议稍微留有 10~20 字符的余量,避免程序出错。
最后
这篇文章,就先写到这里吧。
--EOF
本文使用「署名 4.0 国际 (CC BY 4.0)」许可协议,欢迎转载、或重新修改使用,但需要注明来源。 署名 4.0 国际 (CC BY 4.0)
本文作者: 苏洋
创建时间: 2023年12月28日
统计字数: 4418字
阅读时间: 9分钟阅读
本文链接: https://soulteary.com/2023/12/28/chinese-version-of-large-model-token-cost-calculator.html