本文作者:孙旭,腾讯数据库开发工程师,9年数据库内核开发经验;熟悉数据库查询处理,并发控制,日志以及存储系统;熟悉PostgreSQL(Greenplum,PGXC等)、Teradata等数据库内核实现机制。
CynosDB 是腾讯数据库研发团队推出的自研数据库,有PostgreSQL和MySQL两个版本。本文以兼容PostgreSQL版CynosDB为例,介绍我们的架构设计和优化思路。
1、概述
PostgreSQL是世界上最先进的开源数据库,始于1986年,有30多年的社区演进历史。其先进的架构、可靠性以及丰富的功能已经获得业界高度认可。同时,PostgreSQL能够在多种操作系统上运行,支持多种索引类型和扩展,特别是对PostGIS扩展的支持,可以让PostgreSQL轻松的处理地理信息数据。
兼容PostgreSQL版CynosDB作为PostgreSQL在NewSQL领域的一个产品,也具有良好的扩展性。由其架构特点带来的资源池化,可以让用户付出更少的成本而获得同等的性能,并且不损失PostgreSQL数据库原有的功能特性。
2、基础架构
现有共有云上的数据库存在一些不足:
1.网络IO重。传统云上的主备架构下,会有大量数据需要写到磁盘,主要包括:WAL LOG、脏页数据、防止页部分写的Double Write或者Full Page Write。
2.主从实例不共享数据。一方面浪费了大量存储,另一方面进一步加重了网络IO。这样会导致磁盘利用率低、CPU闲置等问题。
而CynosDB可以通过日志下沉、共享存储来解决上述问题,以实现共有云数据库的高性价比、高可用性以及弹性扩展。其基础架构如下:

架构中的组件:
1. master是数据库的主实例,负责接收应用的读写事务请求。
2. slave是数据库的只读实例,负责处理应用的读请求,可以支持多个slave实例。
3. CynosStore Client提供访问分布式存储(CynosStore)的接口。DB引擎通过这些接口访问存储,完成数据文件的读写等操作。
4. CynosStore是一个分布式存储系统,存放数据库的数据和日志,并负责日志到数据页面的转换。
4. 集群管理服务负责整个系统的管理,例如:存储扩容,实例创建等。
5. 冷备存储用来存储系统的日志。
master实例将数据的变更以日志方式发送到存储系统(CynosStore)中,同时CynosStore会定期将日志合并到数据页面上。因此,CynosDB无需将脏页写入到存储中,这点与传统数据库是不同的。slave数据库实例没有写事务,不会向存储发送日志,但是会从存储中读取页面,也会接收master实例的日志来刷新内存中的数据页面;如果收到的日志所对应的页面没有在slave的内存中,则会丢弃这些日志。
从架构上看,CynosDB实现了存储和计算分离,并把资源进行池化,因此适合云上部署。而且计算和存储传输数据的仅有日志流,无需写脏页面,因此也减少了系统中的网络量。总的来说,CynosDB具有如下优势:
1.计算能力弹性扩展。可以快速增加slave节点来扩展读能力,而不必进行全量的数据拷贝。
2. 存储能力弹性扩展。不像传统数据库那样受单机存储能力的限制。
3. 充分利用硬件资源。缓解传统主备架构中的CPU闲置、磁盘利用率不高等问题。
4. 备份容易。备份完全由后台持续进行,用户无需干预。
3、兼容PostgreSQL版CynosDB的计算层架构
CynosDB实现了计算与存储分离,系统也因此被分成两大块:计算层和存储层。计算层负责SQL解析、日志生成等;存储层负责数据存储、日志归档以及日志合并等。本节以CynosDB的PostgreSQL兼容版本为例来介绍计算层架构。其计算层架构如下图所示。为了实现这种NewSQL架构,我们对PostgreSQL内核做了新设计:

灰色部分是PostgreSQL内核原生模块:
1. SQL:PostgreSQL的SQL引擎,包括词法/语法分析、语义分析、查询重写/优化和查询执行。CynosDB的设计不涉及SQL层改动,因此它兼容PostgreSQL原来的SQL语法和语义。
2. Access:数据库的访问层,定义了对象的组织方式和访问方法。其中包括:
lHeap:表实现以及访问方法,包括扫描、更新、插入、删除等。
lbtree/gin/gist/spgist/hash/brin:索引实现,包括各种索引的实现和操作方式,如索引扫描、插入等。
lCLOG/MultiXACT:与事务提交状态以及并发等。
Access是设计和优化的重点模块。当表和索引等数据库对象被修改时,原生的PostgreSQL会生成XLog,并写入到日志文件中。在CynosDB中,这些对象修改时也会生成日志,但是这些日志不会写本地的日志文件,而是发送到CynosStore中。
3. storage/buffer:buffer pool和存储管理,调用文件接口对数据文件进行读写。在CynosDB中使用CynosStore Client对CynosStore中的文件进行操作。
5. CynosStore Client提供访问CynosStore的接口,以完成数据库对数据文件的操作。包括数据页面读取接口、日志发送接口等。
6. 分布式存储CynosStore是一个基于日志的分布式的块存储,在本文中不做重点介绍。
CynosDB的计算层把数据文件修改所生成的日志,通过CynosStore Client发送到分布式存储CynosStore中,而CynosStore会将日志定时合并到数据页面上。这里比较重要的一点是,计算层写出日志并不是PostgreSQL原生的XLog,而是我们自己重新设计的日志系统和日志格式。因此CynosDB不依赖于PostgreSQL的原生日志系统,这种设计也可以让我们有机会在CynosDB上做更多的性能优化。具体可以参见下节。
4、架构优化
CynosDB计算层的架构设计遵循了如下思路:
1.“极简IO”。即,降低网络/磁盘IO
2. 高效的系统设计。异步的日志设计、降低计算层CPU负载
通过这些设计,使CynosDB的性能比云上的同等配置性能要高。本节主要介绍计算层所做的优化手段。
4.1 日志系统
兼容PostgreSQL版CynosDB的底层存储CynosStore是一个支持日志写的、可以提供多版本读的、分布式的块设备,DB引擎对存储中文件的修改,都是以日志的方式发送到存储中。其日志格式是:<页面号,页面偏移,修改内容,修改长度>,含义是:在页面的哪个偏移做了什么内容的修改。这样设计的日志是幂等的。
以表插入元组为例,PostgreSQL原来的XLog日志格式可能是:
<relfilenode, pageno, offsetnum,informask2,infomask,hoff,tuple_data>:代表在页面(由relfilenode和pageno来确定一个页面)的offsetnum位置插入一条元组,插入的元组是在恢复时由informask2, infomask, hoff, tuple_data等信息进行重构。
同样的操作,在CynosDB中生成的日志可能如下。假设在页面号为n的页面上插入元组tuple:
<n,10,(char *) &pd_flag,2> -- 保存页面头pd_flag到日志
<n,12,(char *) &pd_lower,2> -- 保存页面头pd_lower到日志
<n,14,(char *) &pd_upper,2> -- 保存页面头pd_upper到日志
<n,36,(char *) &ItemIdData,4> -- 保存ItemIdData数组的第3个元素到日志
<n,7488,(char *) tuple,172> -- 保存tuple到日志
这些条目记录了页面在插入元组时的所有修改,它们最终会在CynosStore Client中形成一个MTR(mini-transaction record:多条日志的集合,代表对数据库存储结构的一次原子修改,例如:btree结构、页面结构的修改;在日志重放的时候需要将一个MTR的所有日志都应用完毕,否则会导致数据库存储结构的破坏),并放到日志流中发送到存储。当存储需要将这个MTR合并到页面时,要保证MTR中的所有日志应用完毕,任何不完全的应用都会导致页面结构不正确。
利用日志特点,我们对PostgreSQL 的内核进行了优化,而优化之后的日志大小开销与PostgreSQL的原生XLOG差不多。这些优化和设计包括:
1. 移除原本PostgreSQL中full page write(FPW)特性。为了保证系统crash再重启之后,那些部分写的页面(torn page)可以被正确恢复,PostgreSQL在Checkpoint之后,对页面执行第一次被修改时,会将整个页面记录到日志中,这种特性就是FPW,类似MySQL的double write。当crash recovery时,系统会以这个全页作为基页面进行日志回放,并将恢复好的页面写到存储,而不必关心存储页面中的页面是否是半页。由于CynosDB日志的幂等性,当出现半页写时,系统直接重新在此页面上直接进行日志回放,即可将页面修复到一致状态。因此CynosDB中无需原生的FPW,从而减少了日志量。
2. 移除系统中脏页面刷盘操作。CynosDB通过日志保存页面的修改,并且可以通过在基页上合并日志而得到最新页面,因此无需原本系统的刷脏操作,仅仅刷日志就足够。
通过如上优化,可以很大程度上减少网络IO和日志量。
3. 除了以上对PostgreSQL内核的优化,CynosDB对日志的记录方式也进行了精简和压缩。CynosDB的日志都有日志头(LogHeader),如果修改同一个页面的多条日志共享一个日志头,则可以省去多个日志头的开销,如下图所示:
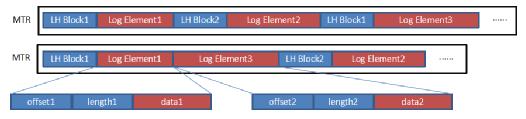
LH代表LogHeader,Log Element代表对页面的页一次修改。如上图,有两条对Block1的修改日志,并且每个修改都有一个日志头(LH),经过日志头合并优化后,形成新的MTR中,修改Block1的那些日志共享了同一个日志头。
如果修改同一个页面的两条日志是相邻的,那么可以将两条日志进一步合并成一条日志。这种方式减少了日志条目,从而可以提高日志合并和页面生成速度。
4.2 页面CRC
在PostgreSQL中,页面在刷盘前会计算并填充页面的CRC属性,而在CynosDB中,如果为CRC也生成了一条日志写入到存储中的话,会增加计算节点的CPU负担和日志条数。为了解决这个问题,我们将CRC的计算任务下放到存储中,从而减轻了计算层的CPU负担,以及日志条数。
4.3 异步表扩展
原生的PostgreSQL数据库使用的是本地文件系统存储数据,其文件扩展操作同步并实时的反映到磁盘文件上。但是CynosDB的扩展操作是通过日志实现,如果每次扩展都对日志做一次flush操作,让扩展实时的反应到存储上,势必会影响系统的性能。因此,我们实现了文件的异步扩展,即文件扩展的日志先保留在系统的日志buffer中,而不是每次扩展都实时的刷新到存储中,当事务提交的时候再把这些日志刷到存储上,对数据批量导入的性能提升很明显。另外,扩展操作可以一次性在文件中扩展出多个页面,减少调用扩展操作的次数。
后续
后续我们会在新硬件、多Master架构等领域作更多探索,为云上的数据库产品形态带来更多惊喜和亮点。
云数据库MySQL年终特惠,新用户1元购买,新老用户热卖款型2.5折起,更有代金券免费领,立即围观:https://cloud.tencent.com/act/pro/mysql
更多数据库前沿技术可关注 公众号:TencentDB
