作者:邢家树,高级工程师,目前就职于腾讯TEG基础架构部数据库团队。腾讯数据库技术团队维护MySQL内核分支TXSQL,100%兼容原生MySQL版本,对内支持微信红包,彩票等集团内部业务,对外为腾讯云CDB for MySQL提供内核版本。
导语:CDBTune是腾讯云自主研发的数据库智能性能调优工具。相比于现有业界通用方法,CDBTune无需细分负载类型和积累大量样本,通过智能学习参与参数调优,获得较好的参数调优效果。
数据库系统复杂,且负载多变,调优对DBA非常困难:
- 参数多,达到几百个
- 不同数据库没有统一标准,名字、作用和相互影响等差别较大
- 依靠人的经验调优,人力成本高,效率低下
- 工具调优,不具有普适性
总结起来就是三大问题:复杂,效率低,成本高。腾讯云的智能性能调优工具如何在不断实践中破解这些问题呢?
实践一:启发式搜索方法/Search-Based Algorithm
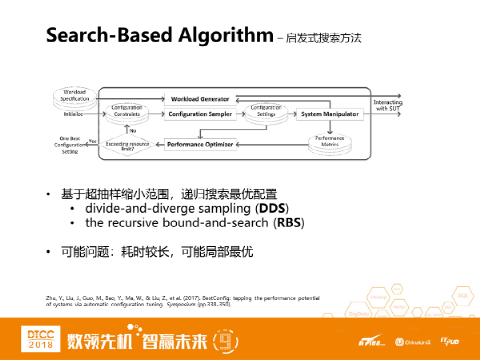
输入包括两部分:
- 参数约束:包括要调优的参数集合和参数的上下界;
- 资源的限制:调优过程在多少轮以后停止。
Configuration Sampler:会对输入参数进行取样,生成配置;配置会被设置到SUT(也就是待调优环境)。System Manipulator:它和SUT进行交互,设置参数,并且会获得SUT的性能数据。
Performance Optimizer:根据配置和性能数据找到最优的配置。PO算法主要包括两个方法:DDS和RBS。
lDivide-and-Diverge Sampling (DDS)
这里通过DDS来划分参数的子空间,降低问题的复杂度。首先把每个参数划分成k个区域,那么n个参数就有k^n个组合,从而降低复杂度。假设k和n如果比较大的话,空间可能还是很大。如何处理?此时可用超抽样的方法,只抽出k个样本解决。
lRecursive Bound-and-Search (RBS)
在一个性能平面上的某个点附近,总是能找到性能相近或者更好性能的点,也就是说可能找到更好的配置。在已有的样本里,找到性能最好的那个配置。然后在这个配置周围,运行多轮,递归寻找可能更好的配置。
基于搜索的方法可能的问题是,抽样和测试可能耗时很长,而且可能陷入局部最优。
实践二:机器学习方法/Machine Learning
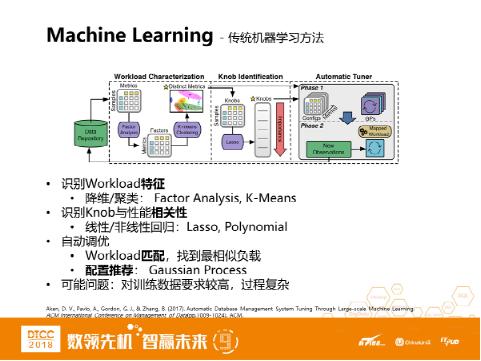
主要包括三个步骤:
l识别负载特征
对metric进行了降维,metric是指系统的内部状态指标,比如MySQL的innodb_metric。这里用了两个方法,一个是FA,一个是K均值聚类。
- 识别配置参数和性能的相关性
配置参数有几百个,先通过Lasso线性回归参数和性能的关系进行排序。优先考虑对性能影响较大的参数。
- 自动调优
匹配目标workload,也就是根据负载在不同配置下面运行,表现出来的metric特性,匹配到最相似的负载。然后,根据匹配到的负载,推荐最优的配置。这里用到高斯过程,同时加入exploration/ exploitation,即探索、利用的过程。
这种方法的问题是,调优过程非常依赖历史数据,要匹配到相似的workload才可以,对训练数据要求比较高。如果匹配不到,则找不到很好的配置。
实践三:深度学习方法/Deep Learning
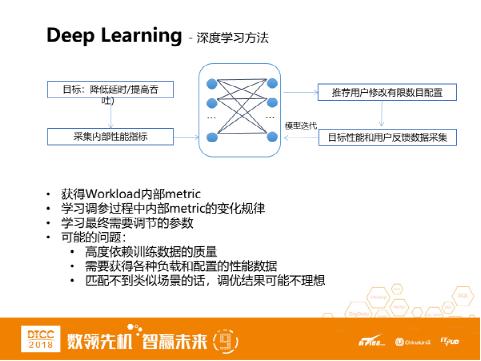
通过深度学习网络,推荐需要最终调节的参数:
- 获得Workload对应的内部metric
- 学习调参过程中内部metric的变化规律
- 学习最终需要调节的参数
这个模型高度依赖训练数据,需要获得各种负载在各种配置下的性能数据。而数据库的负载和配置的组合实在太多了,基本不可能覆盖到。假设匹配不到类似场景,调优结果可能不理想。
实践四:深度强化学习方法/Reinforcement Learning

在强化学习中,模拟人与环境交互的过程。Agent会根据观察到的状态state,做出相应的反应action。同时,Environment接受action,改变自己的状态。这个过程会根据一定规则,产生相应的reward,也就是对于action的评价。
最终通过实践比较,我们选取使用强化学习的模型,开发数据库参数调优工具CDBTune。它强调调参的动作,摆脱以数据为中心的做法。
强化学习与参数调优,我们定义如下规则:
- 规则:每间隔一定时间调参,获得性能数据
- 奖励:性能提高获得正奖励值,下降获得负奖励值
- 目标:调参时间/次数尽可能少,获得较高的期望奖励值
- 状态:系统内部metric指标
我们把系统的内部metric叫做内部指标;外部的性能数据,比如TPS/QPS/Latency叫做外部指标。在数据库参数调优场景中,具体做法是:Agent选择一个参数调整的action(也可能是多个参数)作用于数据库,根据执行action后的外部指标,计算应该获得的即时奖励。
在强化学习对应到参数调优这个场景。此场景的问题是:强化学习需要构造一张表,表明在某种状态下,执行某个操作,获得的收益后,我们才知道执行什么操作获得的收益是最大的。但是数据库的状态空间(性能指标)和动作空间(配置组合)特别大,组合这样一张表出来是不可能的任务。此时深度强化学习就派上用场了,我们要通过一个深度网络逼近这个Q-table的效果,也就是CDBTune的实现方法。
CDBTune实现

- S为当前数据库性能状态(内部指标),S'为下一状态数据库性能状态
- r为即时奖励,w为神经网络参数,a为采取的动作(配置参数的执行)
- Q为状态行为价值函数
此模型主要分成两部分。
l数据库环境:如图左边,参数会被设置到这个环境里,然后环境的内部指标和外部指标会被采集,反馈给右边的模型。
l深度强化学习网络:如图右边,实现算法类似DeepMind发布的Nature DQN,采用两个Q-Network。
另外,Replay Memory是我们的记忆池,历史数据会被记录下来。然后训练会不断进行,不断加入记忆池。深度学习网络会从记忆池中随机选取样本机型训练。
在估计一个action的reward的时候,基于一个假设:我们的回报取决于对未来每一步的结果影响;而影响最大的,是最近的回报。通过
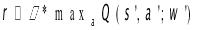
近似获得这个Q值。对于一个样本(s, a)而言,我们可以得到真正的回报r。这时候我们可以获得他们之前的Loss,调整左边的网络,使两边的Loss越来越小。这样我们的网络就会逐渐收敛,获得更好的推荐。
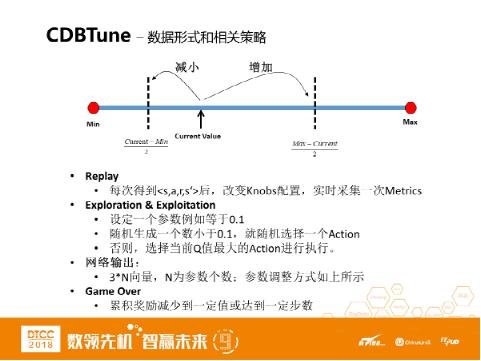
数据形式和相关策略

效果评估
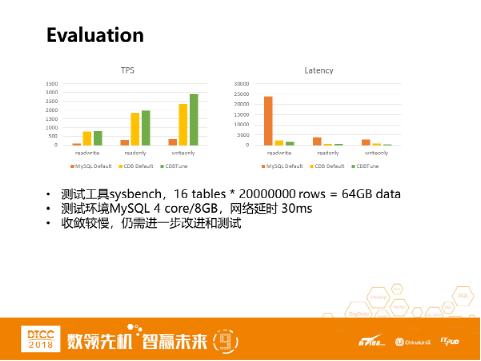
通过测试可以看到,在不需要任何前期数据收集的情况下,CDBTune通过自我学习参数调优过程,达到较优的参数调优效果,CDBTune调优获得的吞吐和延时性能均达到较为理解的水平。这也是深度强化学习方法相对于其他几种方法的优势所在。
总结:
基于DQN智能调参的优势
- 化繁为简,无需对负载进行精确分类
- 调参动作更符合实际调参时的情况
- 无需获取足够多的样本来,减少前期数据采集的工作量
- 利用探索-开发(Exploration & Exploitation)特点,降低对训练数据的依赖,减小陷入局部最优的可能性
在实践过程中,我们也遇到一些问题:
- 选择动作实际运行,训练效率不高,训练周期长
- 对连续配置离散化处理,可能导致推荐配置的精度不高,收敛较慢
- 使用动作的最大Q值,导致Q值的过高估计问题
针对这些问题,我们也在不断优化和改进我们的模型,优化参数。相信CDBTune可以在未来取得更好的效果。
更多前沿数据库技术和案例分享,请关注我们的微信号:腾讯云数据库CDB
