联邦语言模型是一个利用了两种人工智能趋势的想法:小型语言模型 (SLM) 和大型语言模型 (LLM) 能力的提升。
译自 Federated Language Models: SLMs at the Edge + Cloud LLMs,作者 Janakiram MSV。
生成式 AI 领域出现了两个重大发展:可以在设备上运行的 小型语言模型 (SLM) 的兴起;以及大型语言模型 (LLM) 在上下文长度、工具集成、多模态 和云端运行的复杂推理方面能力的提升。“联邦语言模型”是一个利用这两个趋势的想法,同时使企业能够遵守机密性、隐私和安全。
在联邦 LLM 中,我们处理两个语言模型——一个在边缘运行,另一个在云端运行。在边缘运行的 SLM 主要用于生成,而云端的 LLM 用于将提示映射到一组工具和相关参数。下图描述了联邦 LLM 的架构和流程:
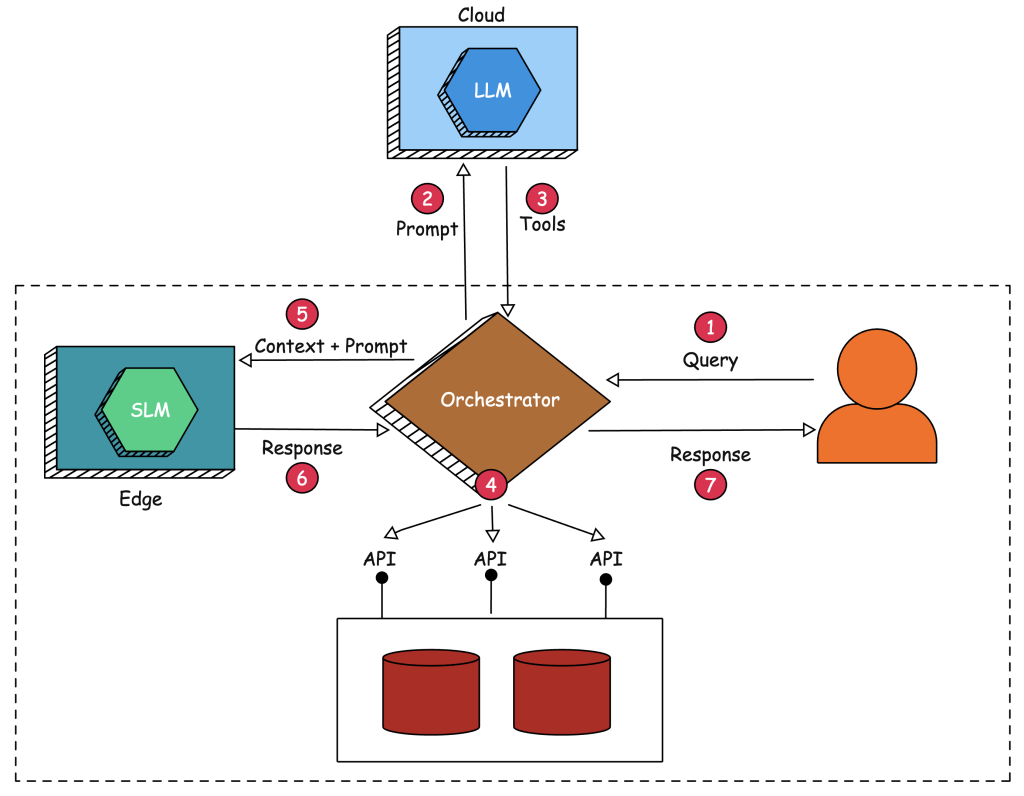
目标是在无需将敏感上下文发送到公共领域运行的强大 LLM 的情况下实现 检索增强生成 (RAG) 代理。强大的 LLM 用于将提示映射到具有访问敏感内部数据和应用程序的适当工具。协调对语言模型调用应用程序执行由 LLM 识别的工具以提取上下文,该上下文被发送到本地运行在廉价边缘设备上的能力较弱的 SLM。这种架构通过将实际生成委托给 SLM 来将敏感数据隐藏在 LLM 之外。
在我们仔细研究这种架构的实现之前,让我们重点介绍语言模型不断变化的格局中的一些最新趋势。
LLM 趋势
1. 小型语言模型变得越来越强大和成熟
SLM 变得越来越强大和成熟,在性能和效率方面取得了重大进步。Gemini Nano 和 Microsoft Phi-3 等最新发展体现了这一趋势。
由 Google DeepMind 开发的 Gemini Nano 旨在高效地在边缘设备上运行,提供强大的语言处理能力,而无需大量的计算资源。同样,Microsoft Phi-3 利用创新的架构和训练技术,以紧凑的形式提供高精度和上下文理解。这些模型以及 SLM 类别的其他模型展示了在自然语言理解、生成和翻译方面的增强功能,使其适用于从移动设备到企业解决方案的各种应用。
SLM 的进步表明正在向更易获得和更通用的 AI 解决方案转变,反映了更广泛的趋势,即优化 AI 模型以提高效率并在各种平台上进行实际部署。
2. 函数调用和工具仍然仅限于大型语言模型
函数调用 和工具仍然主要局限于 LLM,因为 SLM 缺乏执行这些高级任务所需的必要功能。
LLM,例如 OpenAI 的 GPT-4o、Anthropic Claude 3.5 Sonnet 和 Google 的 Gemini 1.5 Pro,拥有广泛的上下文理解和推理能力,使它们能够处理复杂的函数调用并与各种工具无缝集成。相比之下,SLM 尽管越来越复杂,但仍然受到其较小的参数大小和减少的计算能力的限制。这种限制阻碍了它们有效地处理复杂指令和与外部系统交互的能力。
虽然 Gemini Nano 和 Microsoft Phi-3 等模型在提高 SLM 的效率和准确性方面取得了进展,但它们在执行高级功能和工具集成方面仍然不足,这需要 LLM 的强大性能和广泛的训练数据。因此,函数调用和复杂工具交互的使用仍然是 LLM 擅长和主导的领域。
3. 大型语言模型无法部署在像 Nvidia Jetson 这样的边缘设备上
由于计算资源的固有局限性和量化带来的挑战,语言模型无法有效地部署在边缘设备(如 Nvidia Jetson)上。虽然将 LLM 量化以减小其大小和计算需求是一种常见方法,但它通常会导致精度和能力的显著下降。这些量化模型难以保持与全精度模型相同的准确性和语境理解水平,导致在需要细致语言理解的任务中性能下降。
此外,像 Nvidia Jetson 这样的边缘设备的内存和处理能力不足以处理 LLM 的复杂性,即使是量化形式。因此,在这些设备上部署 LLM 仍然不切实际,因为性能和精度的权衡大于其带来的益处。这种局限性突出了持续开发更有效模型和算法的必要性,这些模型和算法可以平衡高级语言处理的需求与边缘计算环境的限制。
4. RAG 所需的大部分敏感数据都位于数据中心内
用于 RAG 的大部分敏感数据都驻留在安全的数据中心内,突出了将这些数据发送到公共领域运行的 LLM 所带来的重大合规性和安全问题。
将私人数据传输到外部 LLM 可能违反严格的合规法规,例如 GDPR 和 HIPAA,这些法规要求对数据访问和处理进行严格控制。此外,存在将这些敏感信息在 LLM 的预训练和微调阶段无意中使用的风险,从而导致潜在的数据泄露或未经授权的使用。此外,将本地数据传输到基于云的 LLM 所涉及的延迟会严重影响性能和响应能力,使实时应用程序变得不切实际。
这些问题加剧了数据一旦离开数据中心的受保护环境,就无法控制其固有的缺乏,从而增加了网络威胁和滥用的脆弱性。因此,组织必须优先将敏感数据保留在其安全基础设施内,利用内部部署或私有云解决方案来实现 RAG,以确保合规性并降低与数据隐私和安全相关的风险。
5. 代理工作流依赖于多个语言模型
代理工作流,涉及 自主代理 通过一系列相互依赖的步骤执行复杂任务,依赖于多个语言模型才能获得最佳结果。
代理工作流旨在模仿人类的解决问题的方式,通过将任务分解成更小、更易于管理的组件,并按顺序或并行执行它们。这通常需要使用多个专门的语言模型,每个模型都针对工作流的特定方面进行定制。例如,一个模型可能擅长自然语言理解,另一个模型擅长生成详细的响应,而另一个模型则擅长处理特定领域的知识。
此外,代理可能依赖于边缘的 SLM 进行实时、低延迟处理,以及云中的更强大的 LLM 来处理复杂、资源密集型任务。通过利用各种模型的独特优势,代理工作流可以确保其操作的更高准确性、效率和上下文相关性。与多个模型进行通信的需要使工作流能够集成不同的功能,确保复杂的任务得到全面有效地解决,而不是依赖于单个模型的有限范围。这种多模型方法对于在现实世界应用中实现代理工作流所期望的细致入微和复杂的结果至关重要。
实施联邦语言模型
步骤 1: 用户向代理发送一个需要访问作为 API 公开的本地数据库的提示。
步骤 2: 由于在边缘运行的 SLM 无法将提示映射到函数和参数,因此代理(充当协调器和粘合剂)将提示以及可用工具发送到云中运行的 LLM。
步骤 3: 强大的 LLM 向协调器返回一组工具——函数和参数。在公共领域运行的此模型的唯一工作是将提示分解为函数列表。
步骤 4: 代理枚举由 LLM 识别的工具,并并行执行它们。这实际上涉及调用与本地数据库和数据源(敏感和机密)交互的 API。代理聚合来自调用函数的响应,并构建上下文。
步骤 5: 然后,代理将用户提交的原始查询以及从工具中收集的聚合上下文发送到边缘运行的 SLM。
步骤 6: SLM 使用从协调器/代理发送的上下文中得出的事实信息进行响应。 这显然受限于 SLM 的上下文长度。
步骤 7: 代理将最终响应发送到用户发送的原始查询。
FLM 挑战
虽然这种方法很有前景,但它可能会面临实施挑战:
- 需要仔细管理边缘 SLM 和云 LLM 之间的协调。
- SLM 在生成任务方面的性能可能无法与 LLM 相匹配,这可能会限制整个系统的功能。
- 这种方法可能会由于边缘和云之间的来回通信而引入延迟。
本文的目的是介绍联邦语言模型,这是一种将基于边缘的小型语言模型 (SLM) 与基于云的 LLM 相结合的创新方法。 这种方法利用 LLM 进行复杂的任务规划,并利用 SLM 进行本地数据生成,从而解决企业 AI 应用中的隐私问题。 虽然很有前景,但该系统在模型之间的协调、SLM 的潜在性能限制和延迟问题方面面临挑战。 尽管存在这些障碍,但它提供了一种新颖的解决方案,平衡了先进的 AI 功能和数据安全,但成功的关键在于仔细的实施。
我基于在 Jetson Orin 上本地运行的 Microsoft Phi-3、作为 API 公开的 MongoDB 数据库以及来自 OpenAI 的 GPT-4o,实现了这种方法的概念验证。 在本系列的下一部分中,我将带您逐步了解代码和在您自己的环境中运行此代码的步骤。
相关文章:
- 使用AI改进组织的元数据
- 增强ChatGPT处理模糊问题能力
- Gemini:我们最大最强的AI模型
- 2023年开源大语言模型一览
- 2024年开发者人工智能技术思考指南