如何设计可靠云业务架构?个人认为应该从业务容错、高可用和灾备三个方面入手。
什么是容错?
容错(fault tolerance)指的是, 单个组件发生故障时,业务还能继续运行。

容错的目的是,发生故障时,业务系统的整体性能有所下降,但是依然可以访问。
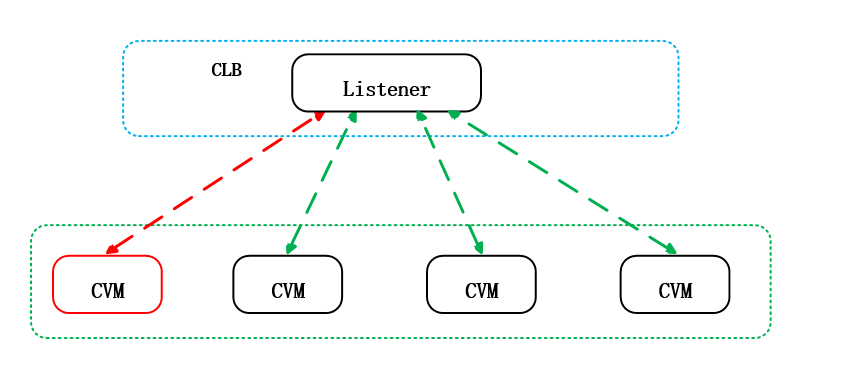
云架构中典型的容错设计就是CLB(负载均衡)后端绑定多个RS(虚拟机或者容器),同一个业务的一组RS中出现某个RS误操作或软件故障,不会影响整体业务的继续运行。如下图:
什么是高可用?
高可用(high availability)通常来描述一个架构经过专门的设计,从而减少业务中断时间,最终实现保障其服务的高度可用性。

汽车的备胎就是一个高可用的例子。当轮胎坏了没有备胎,纵使老司机也只能等着新轮胎到了才能正常替换修复,相反如果有备胎那么就会大大缩短修复汽车的耗时。
注意,高可用不是指业务不中断(那是容错能力),指的是能以最短时间恢复正常访问业务的能力,无论这个故障是业务流程、物理设施、网络或者服务器软/硬件的故障。如果需要很长时间才能恢复可用性,就不叫高可用了。上面例子中,更换备胎就必须停车,但只要装上去,就能恢复行驶状态。
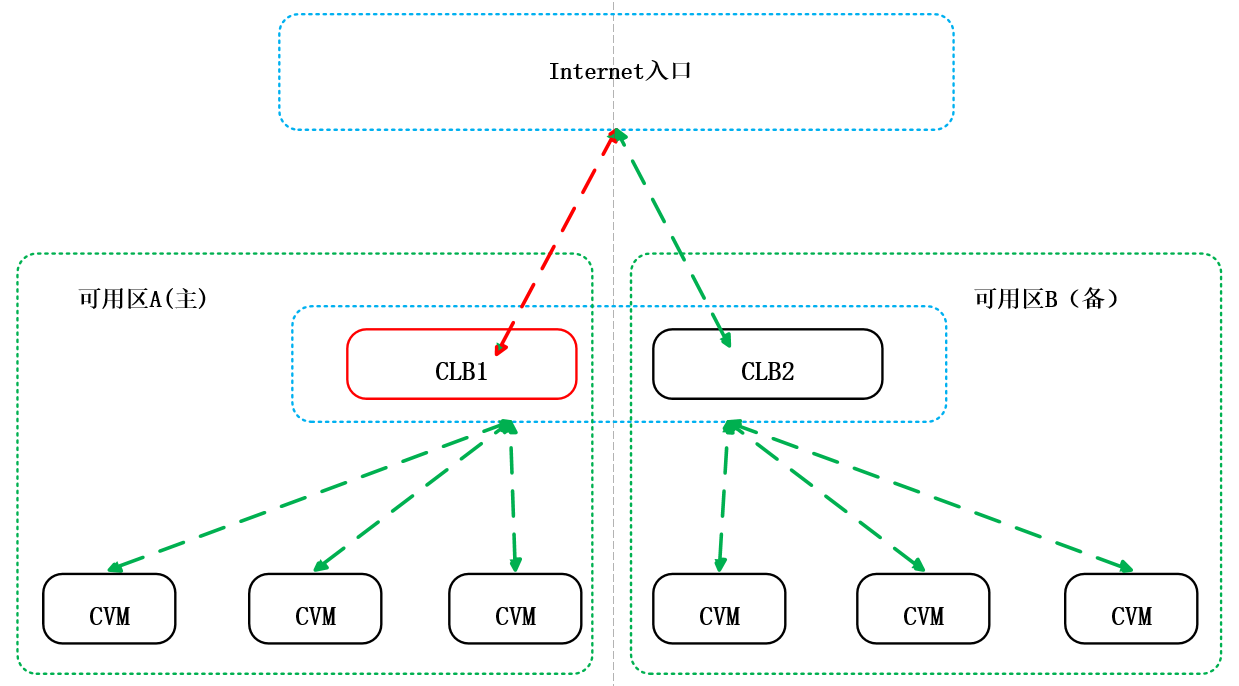
云架构中典型的高可用设计就是在支持主备可用区(简称AZ一般代表一个机房或园区)的地域创建CLB实例,就是在购买CLB的时候尽量选择多可用区的类型。
当您选择CLB的主备可用区时,可以根据CVM实例的可用区分布进行选择。大部分CVM实例位于哪个可用区,就将哪个可用区选择为CLB的主可用区,以获取最小的访问延迟。但是并不建议您将所有CVM实例都部署在一个可用区内,您也需要在CLB的备可用区部署少量ECS实例,以便在极端情况下(主可用区整体不可用时),切换到备可用区后依然可以正常处理CLB转发的请求。如下图:
什么是灾备?
灾备(又称灾难恢复,disaster recovery)是指当灾难破坏生产中心时在不同地点的数据中心内恢复数据、应用或者业务的能力。

上图中,飞机是你的 IT 基础设施,飞行员是你的业务,飞行员弹射装置就是灾备措施。一旦飞机故障坠毁,你原来的基础设施就没了,灾备可以让你的业务幸存下来。
灾备的目的就是保存云上业务的核心部分。一个好的灾备方案,就是从故障的基础设施中保存企业最宝贵的数据,然后在新的基础设施上恢复业务。注意,灾备不是为了挽救基础设施,而是为了挽救业务。
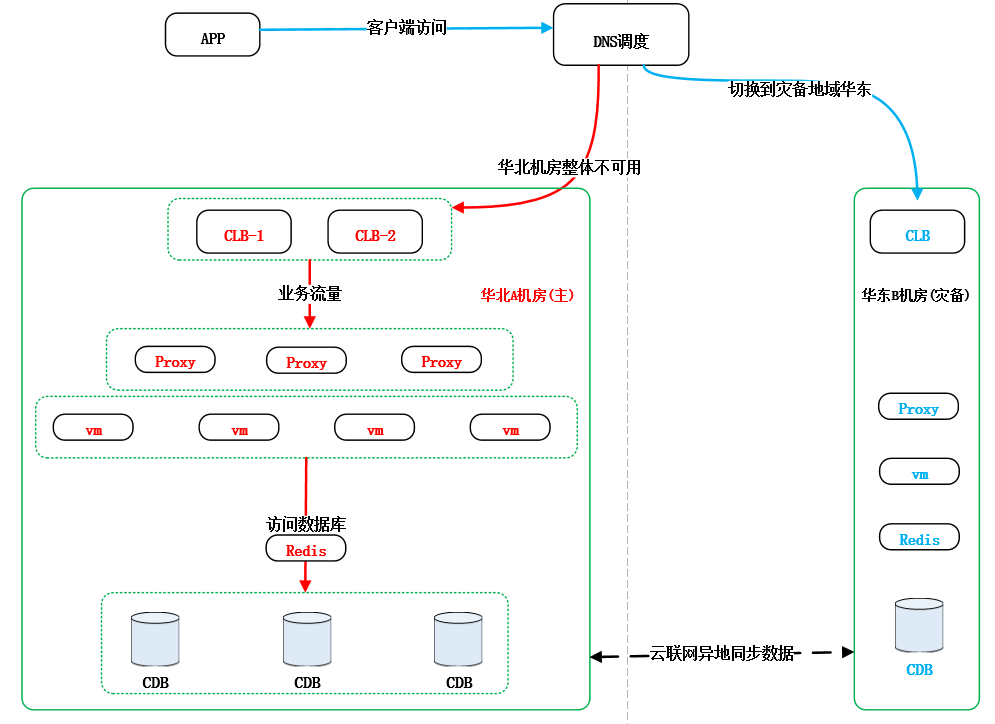
云架构中典型的灾备设计就是不同Region(北京是一个region,上海是另外一个region)机房创建一套备份业务系统实现异地灾备,在不同地域、不同可用区中均对原有业务架构做一套完整的备份。不同地域之间可以采用腾讯云的云联网实现异地VPC之间通信,通过云联网(底层是通过不同地域的专线做保障)保障数据库之间的数据实时同步,将数据传输延迟降到最低。这种容灾架构方式既可以解决单机房故障也可以应对像地震,海啸等灾难性故障。如下图:
公有云异地容灾优势:
1)云DNS以及云网络提供快速切换业务入口功能;
2)异地VPC之间的云联网,提供统一发布、部署、配置变更功能;
3)对象存储提供异地数据复制功能;
4)通过数据传输服务(DTS)提供不同区域间数据库同步功能;
衡量容灾系统有两个主要指标:RPO(Recovery Point Objective)和 RTO(Recovery Time Object),其中 RPO代表 了当灾难发生时允许丢失的数据量,而 RTO 则代表了从业务系统中断到恢复消耗的时间。RPO 与 RTO 越小,代表业务系统的可用性就越高,当然用户投入的TCO(Total Cost of Ownership,总体拥有成本)也越大。
设计一个高可靠的云业务架构,至少需要考虑以下三点:
容错:单个组件误操作或异常时,保证业务继续稳定运行。
高可用:业务访问出现故障中断时,保证快速恢复。
灾备:基础设施毁灭时,保证尽快恢复业务。
本文主要概括性介绍了设计高可靠云业务架构的主要考量,具体容错、高可用、灾备如何运用还要看每个公司业务的具体情况来定。
友情提示:如果码这么多字对您有一些帮助,请帮忙点赞或分享帮助更多人!