在业务场景中,经常会有监听数据库数据变更的诉求,如数据同步、数据推送等场景。对于Mysql,可以监听其binlog日志,并输出到消息队列完成订阅,而腾讯云上有各种各样数据库,还有一些自研的数据库,都让用户来自研对接的方式显然成本太高,所以腾讯云推出了数据订阅任务,满足用户实时处理数据库数据变更的诉求。
在实现上数据订阅任务就是将各种数据库的binlog日志,转换成统一的Protobuf格式,写入到Kafka中,从而屏蔽了底层数据变更生产的细节。
笔者在对接使用过程中,发现还是有一些难点的,并且有时还需要了解背后数据库的一些原理,因此在这里分享下经验。
一、数据订阅任务配置
本文介绍的是Kafka版本的数据订阅,具体的任务配置方式可以参考[1],其中有一些比较重要的说明:
- Kafka分区策略:分区策略主要影响数据顺序和消费性能的取舍,比如选择“表名+主键分区”,那么只能保证同一张表、同一行数据的多次变更写入同一分区、在消费时能保证顺序处理,顺序保证要求较低,并发消费能力较高;选择“表名分区”,那同一张表的所有变更都会写入Kafka的同一分区,消费时就能保证所有该表的数据更新都被顺序的处理,顺序保证要求较高,并发消费的能力就弱。
- TDSQL数据订阅:TDSQL是一个分布式数据库,多个Shard是互相独立运行,因此在数据变更生产的时候也是互相独立的生产,因此Kafka中的消息是多个Shard并发生产的结果,在分包的场景下,同一条数据的多个包在Kafka中并不一定是连续的。因此在处理时需要根据Kafka 中的每条消息的消息头中都带有分片信息进行划分处理。
- 消费数据订阅:由于数据订阅涉及到数据权限,因此消费组需要在数据订阅任务界面上创建,并设置用户名密码,在消费时要使用正确的用户名密码才能消费。
二、DTS数据写入Kafka的模型
从腾讯云官方文档的介绍[2]中可以看到,Kafka中消息内容为Envelope序列化后的二进制数据,其中data为Entries序列化之后的二进制结构,每一个Entry就是binlog数据(包括binlog对应的库表,行变更前后的数据等)。
message Envelope {
int32 version = 1; //protocol version, 决定了 data 内容如何解码
uint32 total = 2;
uint32 index = 3;
bytes data = 4; //当前 version 为1, 表示 data 中数据为 Entries 被 PB 序列化之后的结果, 通过 PB 反序列化可以得到一个 Entries 对象
repeated KVPair properties = 15;
}从Envelope的数据结构可以看出,它明显是用来分包的,那这个分包的作用是什么呢?
Kafka每条消息的长度是有限制的(默认1MB),而数据库中每行数据的大小却可以远远超过这个限制(比如Mysql中一个longtext字段的长度就可以超过1MB),因此很可能出现单行数据变更无法转换成一条消息写入Kafka。这个分包的逻辑就是为了处理这种单行变更消息很大的场景。数据订阅任务会将binlog数据先转化为Entries并将其序列化,再对序列化后的数据进行分包处理,因此在消费端,需要将多个分包的消息全部收到,才能解析成Entries处理。
在单行数据比较小的情况下,数据订阅任务也会将每行变更作为一个Entry,将多行变更一起放入一个Envelope中写入Kafka,提升写消息的效率。
在单机数据库的场景下,数据库的binlog产生是顺序的,数据订阅任务也是顺序处理binlog的,所以如果产生分包的情况,分包的多条Kafka消息,在Kafka的同一个分区里一定是连续的。但对于分布式数据库TDSQL来说,多个Shard产生binlog是互相独立的,那么数据分包生产到Kafka中的顺序就互相独立了。
下图一所示为TDSQL数据订阅任务配置按表名分区的数据生产模型,即同一个表binlog都会生产到Kafka的同一个分区中。当执行一个SQL更新Table A的多行数据时,若Shard1和Shard2都有单行很大的数据更新,那么Kafka分区1中的分包数据就有可能按图二所示的顺序排列,其中蓝色代表Shard1产生的一条binlog,被拆分为3条Kafka消息,橙色代表Shard2产生的一条binlog,被拆分为3条Kafka消息。
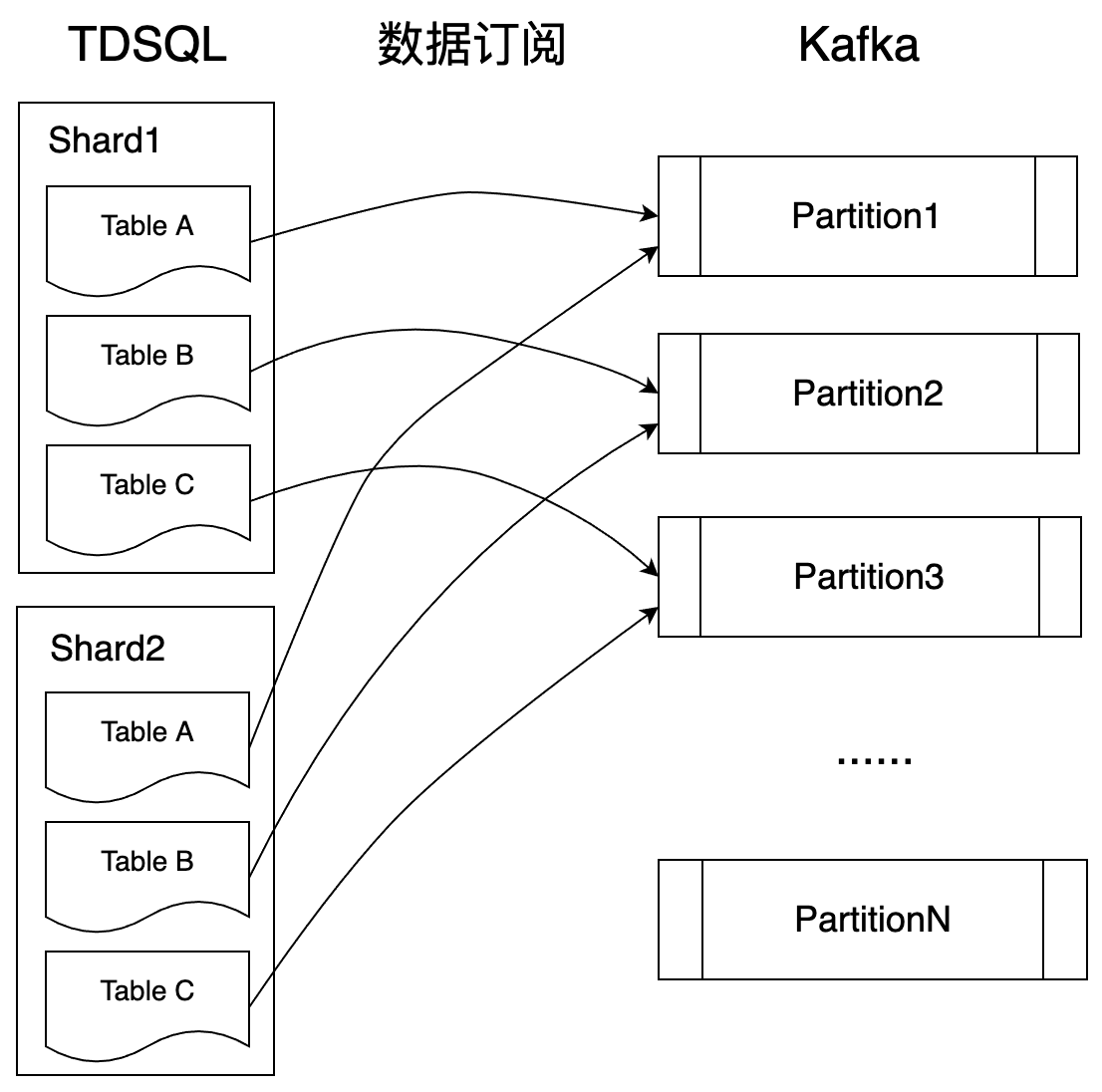
对于图二所示的情况,需要在数据顺序消费出来后,按照消息的“颜色”进行划分,同一个“颜色”的包顺序拼接起来,才能正确解析。这个“颜色”信息以 key/value 的形式存在Kafka消息头中,key 是 ShardId,value 是 SQL 透传 ID,可根据 SQL 透传 ID 区分该消息来自哪个分片。

三、Flink消费任务实现及并发优化
前面介绍了数据订阅任务的生产模型,本节介绍如何用Flink实现消费逻辑。
如下图三所示为任务的Execution Graph,Source端是FlinkKafkaConsumer,这里通常不是任务的瓶颈,且为了简化整体任务执行,将Source端的并发设置为1。在Source中会解析Kafka的消息头,生成哈希Key,用于处理顺序拼包的逻辑。Keyby之后的Parser实现拼包逻辑以及binlog消息的解析。
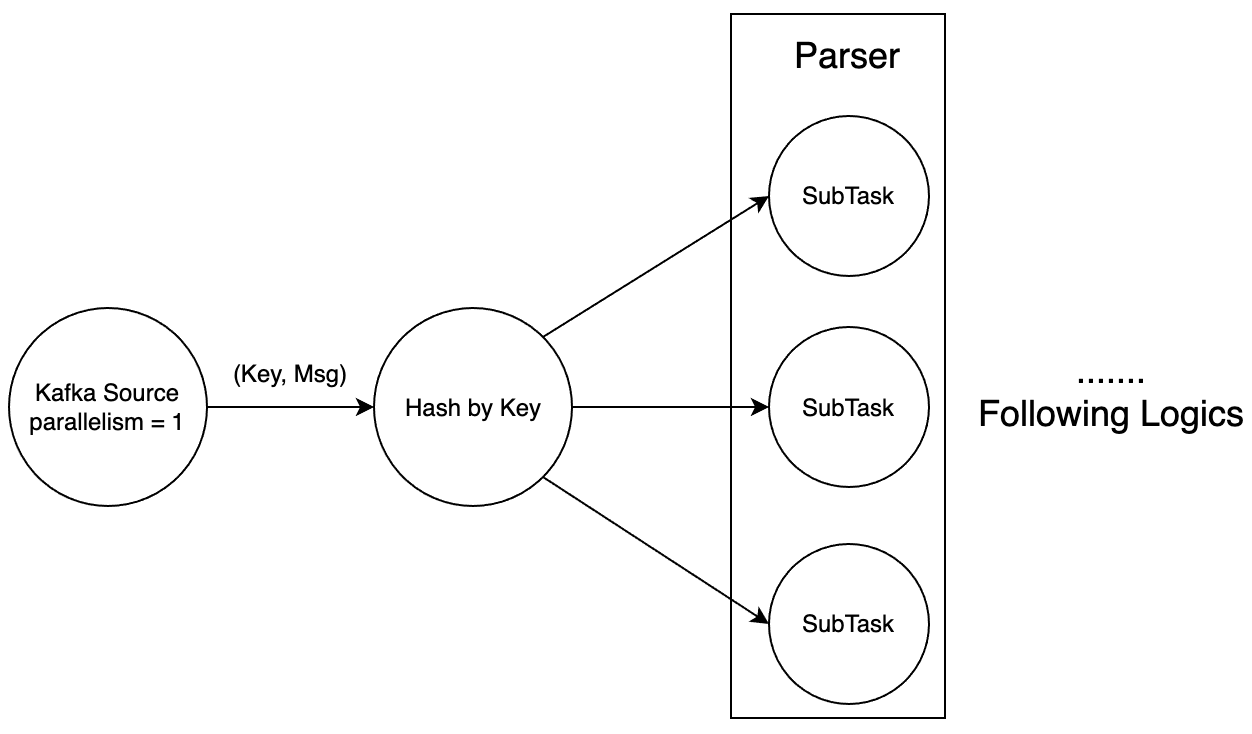
下面对照着部分代码说明下逻辑实现中的重点。首先是Source端的逻辑,其中自定义实现了一个KafkaDeserializationSchema,在deserialize()方法中解析了Kafka的消息头。可以看到生成的Key为ShardId+Partition,其中选取ShardId的原因在第二节已有说明,加上Partition是由于我们将Source端的并发设置为1,Source从Kafka的多个分区拉取的数据会合并在一起,影响拼包的逻辑。
env.addSource(new FlinkKafkaConsumer<>( topic, new KafkaDeserializationSchema<Tuple2<String, byte[]>>() {@Override public TypeInformation getProducedType() { return TypeInformation.of(new TypeHint<Tuple2<String, byte[]>>() {}); } @Override public boolean isEndOfStream(Tuple2<String, byte[]> msg) { return false;} @Override public Tuple2<String, byte[]> deserialize(ConsumerRecord<byte[], byte[]> msg) { String key = "default"; Iterator<Header> it = msg.headers().headers("ShardId").iterator(); if (it.hasNext()) { key = new String(it.next().value()); } key = key + "_" + msg.partition(); LOG.debug("Receive msg, partition:{}, offset:{}, key: {}", msg.partition(), msg.offset(), key); return Tuple2.of(key, msg.value()); } }, properties
)).setParallelism(1).name(topic).keyBy(tuple -> tuple.f0);
如图四所示,Source端持有Kafka的分区1和分区2,Shard1的Table A有两次数据更新,产生了2个独立的Kafka消息(绿色)到分区1,Shard1的Table B有一行比较大的更新,被拆分为2条消息(黄色),生产到了分区2。这个场景下,如果只按ShardId划分,由于这几条消息的ShardId相同,实际处理的顺序很可能如图四右侧所示,就会导致无法正确拼包。
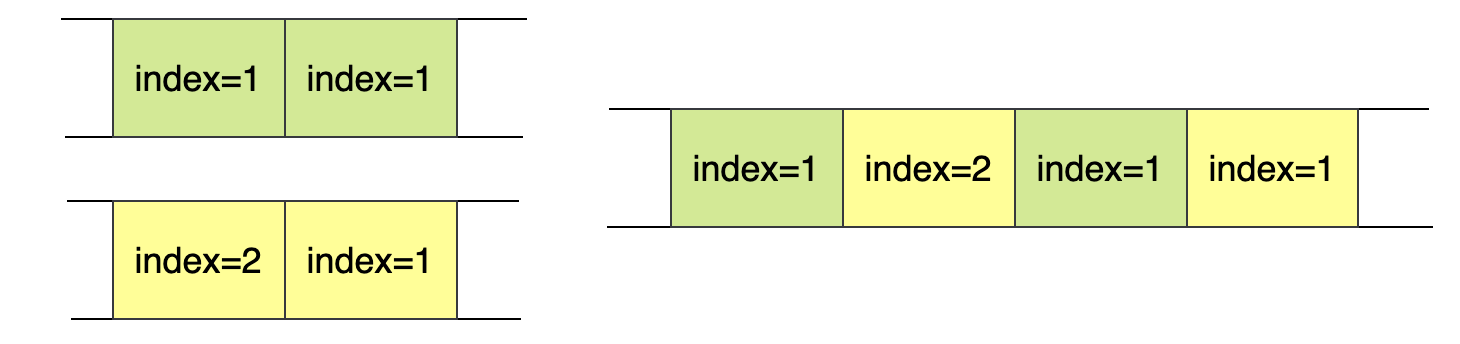
Parser的实现是一个RichFlatMapFunction,其作用是将Kafka中的二进制消息转化为Flink内部的Row。在Parser中使用Keyed State保存已消费但还未处理的不完整的Envelope data(即每一个<ShardId, Partition>都有一份对应的状态)。若当前消费到的Envelope不是分包的最后一个,就只将这个包追加到状态中;若消费到最后一个包,则处理完整的状态中的数据,并将状态清空。这里使用状态处理拼包逻辑保证了在任务异常重启时,也可以正确拼包,而不会丢数据。
Parser中其他的逻辑就是解析Protobuf的格式,完成用户自定义的逻辑,这里就不再赘述了。
public class DTSBinlogFormatParser extends RichFlatMapFunction<Tuple2<String, byte[]>, Row> {private transient ValueState<byte[]> entriesState; @Override public void open(Configuration parameters) throws Exception { entriesState = getRuntimeContext().getState( new ValueStateDescriptor<>("entries", TypeInformation.of(byte[].class), new byte[0]) ); } @Override public void flatMap(Tuple2<String, byte[]> input, Collector<Row> output) { try { SubscribeDataProto.Envelope envelope = SubscribeDataProto.Envelope.parseFrom(input.f1); ByteArrayOutputStream entriesBuffer = new ByteArrayOutputStream(); if (envelope.getTotal() != 1) { entriesBuffer.write(entriesState.value()); } envelope.getData().writeTo(entriesBuffer); LOG.debug("ShardId and partition:{}, buffer size:{}, index:{}, total:{}", input.f0, entriesBuffer.size(), envelope.getIndex(), envelope.getTotal()); if (envelope.getIndex() < envelope.getTotal() - 1) { // 不是最后一个包 entriesState.update(entriesBuffer.toByteArray()); return; } if (envelope.getTotal() != 1) { entriesState.clear(); } SubscribeDataProto.Entries entries = SubscribeDataProto.Entries.parseFrom(entriesBuffer.toByteArray()); for (SubscribeDataProto.Entry entry : entries.getItemsList()) { // Process Entry } } catch (InvalidProtocolBufferException pbException) { LOG.error("parse from entriesBuffer failed!", pbException); } catch (Exception e) { LOG.error("invalid binlog message!", e); } }
}
在数据同步的任务场景中,处理数据源产生的binlog消息是一定要保证顺序的(不一定是全局顺序),例如对同一条数据的2次更新在处理时乱序的话,可能会导致最终更新目标表的结果不正确。在这个前提下,这里Flink消费数据订阅任务的最大并发数对于TDSQL就是shard数乘Kafka分区数,而对于Mysql就是Kafka分区数,且要配合数据订阅任务配置的分区策略使用。而对于整个数据同步任务来说,在并发数有限的情况下,写入下游数据库的Sink节点往往会成为性能的瓶颈。因此如果想提升整体的处理性能,就需要在解析出binlog的内容后,根据一定的规则去扩大并发数:例如写入下游数据库时,数据中每行有唯一ID标识,那么只需要保证相同ID的多次变更被顺序执行,这种场景下就可以在任务下游对ID字段做keyby,来提升Sink节点的并发。
参考文献
[1] 《数据订阅(Kafka 版)》。https://cloud.tencent.com/document/product/571/52376
[2] 《使用 Kafka 客户端消费订阅数据》。https://cloud.tencent.com/document/product/571/523812