
导语
近几年,大型公有云故障引发的生产业务事故案例时有发生。由于很多开发者默认大型公有云的服务是一直可用的,在开发时没有针对公有云服务进行容错设计,在公有云故障时,就出现了业务的异常。可见,由于大型公有云实际上已经成为了全社会共同拥有的IT基础设施,其业务的高可用也已经成为了企业社会责任的一部分。腾讯云是如何通过完备的高可用设计,来保证云服务的业务连续性和数据持久性,从而承担大厂应有的社会责任的呢?
这篇来自腾讯专有云的架构师方天戟的万字长文为您揭开腾讯专有云高可用设计的内幕。
一. IT 业务高可用的需求与场景
1. 高可用相关的基础概念和指标
在运营级与企业级应用中,一个重要的概念是服务级别协议 SLA(Service Level Agreement)。SLA 的关键指标有可用性(Availability)、业务恢复时间 RTO(Recovery Time Objective)、数据恢复目标 RPO(Recovery Point Objective)。
衡量可用性的指标,一般为可用性百分比。以电信运营商(ISP) 提供的企业专线服务为例,如 ISP 向客户承诺,可用性指标为99.99%(一般称为4个9),每年计划外停止服务的时间在全年服务时间中的占比,就不应当高于0.01%,也就是365(天)×24(小时)×0.01%=0.876(小时),合52.56分钟。一些较为重要的业务有可能对可用性提出更高的要求,如99.999%(5个9)或99.9999%(6个9),对应的计划外停止服务时间就不应该多于5.256分钟或0.5256分钟(约合31.5秒)。
业务恢复时间 RTO 指的是从灾难状态恢复到可运行状态所需的时间,用来衡量系统的业务恢复能力,也就是所谓的业务连续性。通过对系统 RTO 的优化,可以使得灾难发生时,能够迅速恢复业务。
数据恢复目标 RPO 指的是在灾难过程中的数据丢失量,用来衡量系统的数据冗余备份能力,也就是所谓的数据可靠性,或数据持久性。通过对系统 RPO 的优化,可以使得在灾难发生时尽量少丢失数据。
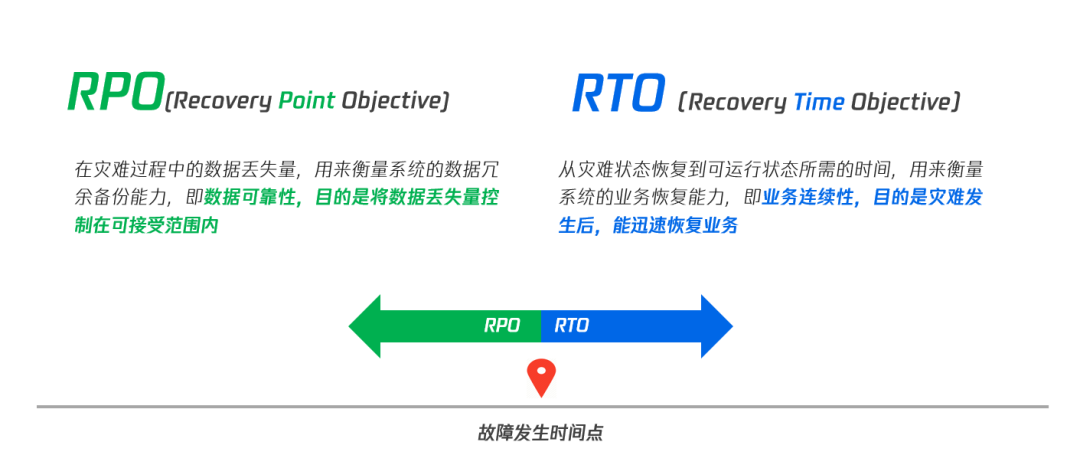
图1 高可用关键指标 RTO 与 RPO
让我们举一个例子:
某企业私有云平台的2台网络VPC服务节点中,有一台发生异常并重启,另一台在5秒内立即接管了业务,部分用户在这5秒内访问业务发生卡顿。这一故障的RTO为5秒,RPO为0。
2. 高可用建设目标
如1.1节中所述,高可用领域的建设目标可以从 RTO 和 RPO 两个维度进行衡量。我们将 RTO 作为 X 轴,RPO 作为 Y 轴,二者交叉可以得到四个象限,如下图所示:

图2 高可用建设目标四象限
在图2中,我们通过业务的 RTO 和 RPO 是否为0,将业务高可用建设的目标划分为四个象限。
右上象限是要求最高的场景,RTO 和 RPO 均为0。这代表着业务在两个或多个数据中心上,实现分布式双活或多活部署,任一节点/链路/机柜故障,甚至单数据中心整体故障,都不影响业务连续性,用户可以无感知地继续使用数据中心承载的的业务。实现这一象限的建设目标,不仅需要经过严格设计测试的技术架构,还需要极高的 IT 业务管理能力,是数据中心高可用的最高目标,相应地,成本也是最高的;
左上象限相对右上象限而言,是退而求其次的场景,RTO≠0,RPO=0。这代表业务在两个或多个数据中心上以同步容灾的方式运行,核心数据在两个或多个数据中心之间严格同步,也就是所谓的实现强一致性。当单一 AZ 整体故障时,业务可以切换到另一 AZ 运行。这种方式是最常见的业务高可用建设方式,需要实现核心数据库的强一致性同步,为此有可能在部分数据的写性能方面做一定的妥协;
右下象限是右上象限在另一方面的妥协。对于一些对状态与数据没有强一致性要求,对性能与扩展性有较高要求的业务,我们可以在一致性方面做一定的妥协,以最终一致性代替强一致性的方法,来实现系统性能更好的扩展性。业务可以依据一定的策略,被分发到两个或多个数据中心,而业务产生的数据并非实时强一致同步。这种建设方式的 RTO=0,RPO≠0,可以适用于音视频、社交平台及门户网站等非关键业务;
左下象限是高可用建设的一种兜底手段。当数据中心建设方在机房、网络线路及技术架构等方面不具备前三种建设方式的前置条件时,可以采用此种方式,使用较为节约的技术方案,建设温备或冷备数据中心,主数据中心的核心数据通过异步方式定期复制到备份数据中心。当主数据中心因故无法运行业务时,可以在备份数据中心拉起业务,并保证核心关键数据的丢失量在可控范围内。显然,这种建设方式的 RTO 和 RTO 均不为0;
在实践中,我们可以根据实际业务需求,结合成本考量,进行业务高可用方面的规划与建设。
3. 高可用需求与要素分解
一般地,业界认为,数据中心业务的高可用建设,可以总结为七个要素,如下图所示:

图3 数据中心高可用七要素
图3中的七个要素,可以分为两个大类:技术部分和非技术部分。前者包括基础设施高可用、网络连接高可用、数据存储高可用和应用高可用,而后者包括专业技术支持能力,运行维护管理能力和灾难恢复预案。
基础设施高可用,指的是数据中心的供配电系统、散热系统、综合布线和硬件设备的高可用冗余,如业界最高标准的 Tier-IV 级别数据中心,就要求供电是来自两家不同的电网企业,后备供电系统至少具备 2N UPS 系统以及 N+1柴油发电机,空调与机柜 PDU 均为双电源,以保证整数据中心基础设施的可用性达到99.995%,每年计划外停止服务的时间不应当高于0.4小时。各级别数据中心的标准可参见 ANSI-TIA-942-2005;
网络连接高可用,指的是数据中心内外部的网络节点和链路均具备高可用的基本条件,包括数据中心内部网络高可用,数据中心到互联网的连接高可用,数据中心到企业 Intranet 的高可用,以及数据中心之间互联链路的高可用。以利用裸光纤链路(Dark Optical Fibre Link)实现数据中心互联(DCI, Data Center Interconnection)为例,一般建议租用两家不同供应商的线路,并且两条线路在地理层面也经过不同的路径。由于运营商能够保证单链路的可用性达到4个9,采用冗余的运营商线路,可以将单数据中心的外联网络可用性提升到8个9;
数据存储高可用,指的是在数据中心内部,数据以一定的冗余方式存储,以保证一定数量范围内的磁盘或存储节点故障时,整系统的数据存储服务依然可用,数据无丢失;同时,将数据跨数据中心进行同步或异步复制,以保证在单一数据中心整体故障时,备份数据中心能够继续提供数据存储服务,且数据丢失量在可接受的范围(RTO)以内;
应用高可用,指的是通过在数据中心内部,以及跨数据中心之间,部署多个应用实例,并通过负载均衡/负载分担机制将用户请求分发到不同的应用实例。当数据中心内部分实例故障,甚至单个数据中心内实例全部故障时,用户仍然可以正常访问数据中心内的应用;
专业技术支持能力是指对灾难恢复过程提供技术与非技术各方面综合保障的能力,以使得灾备系统能够真正起到作用;
运行维护管理能力指的是运行环境管理、系统管理、安全管理和变更管理等内容,以保证对于数据中心所运行的业务相关的操作,都是在流程控制下执行的;
灾难恢复预案是保障关键业务功能在高可用数据中心的恢复,主系统的灾后重建和回退工作,以及突发事件应急响应的组织流程和预案,甚至进行沙盘推演及实际应急演练;
以上的七大要素是逐层叠加的,云服务的提供者至少应当实现其中技术层面的四大要素,并在运维运营流程层面补齐另外三大要素,才能够真正实现云服务支撑的应用的高可用。
二. 腾讯专有云高可用设计
如前文所述,对于业务的高可用而言,技术层面的决定因素是基础设施高可用,网络连接高可用,数据存储高可用和应用高可用这四点。腾讯专有云TCE 在基础设施高可用的前提下,通过充分考虑高可用的架构设计,融合网络连接高可用和数据存储高可用,实现了应用层面的高可用。
1. 高可用架构总体介绍
腾讯专有云TCE 的高可用部署,是一个具有完整体系的高可用方案,如下图所示:
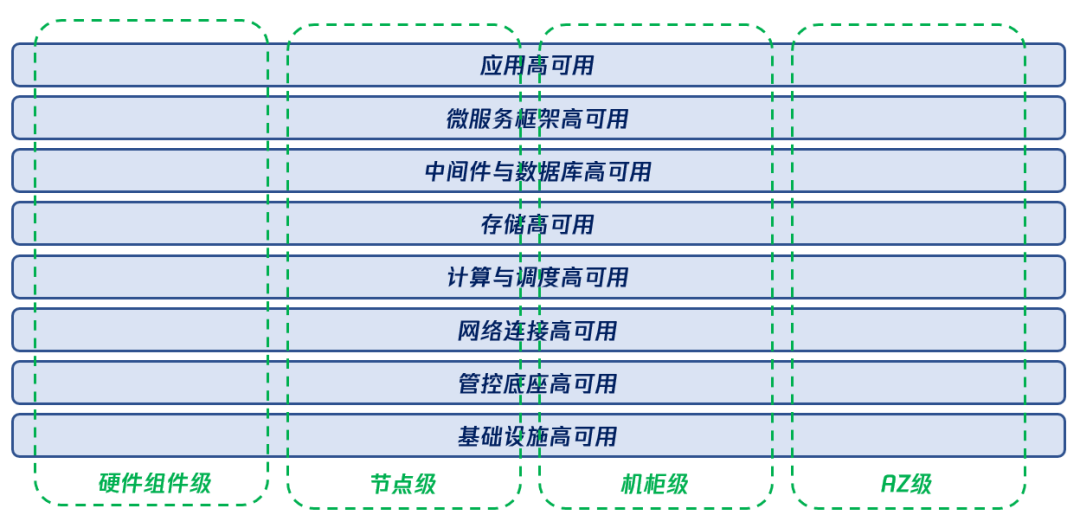
图4 腾讯专有云TCE 高可用体系架构
图4中展示了腾讯专有云TCE 具备的“八横四纵”的高可用体系,以支撑用户云上业务的高可用。
所谓的“四纵”指的是从故障容忍范围的维度对高可用能力的衡量,包括以下高可用特性:
- 硬件组件级高可用:任一硬件组件,如单块磁盘、单条网络线缆或单个电源模块等组件故障,均不影响业务的正常运行,也不会引起数据丢失;
- 节点级高可用:任一硬件节点,如管控支撑节点、计算节点、存储节点、网络节点、中间件节点或数据库节点故障,均不影响业务的正常运行,也不会引起数据丢失;
- 机柜级高可用:任一机柜发生整体故障,如 PDU 断电或其他物理设施故障造成机柜内部分或所有设备均掉线时,不影响业务的正常运行,也不会引起数据丢失;
- AZ级高可用:任一 AZ 整体故障,如整个机房的电力供应或网络连接中断等情况,使得整个 AZ 无法提供服务时,不影响业务的正常运行,也不会引起重要的数据丢失;
所谓的“八横”指的是从云上业务特性维度对高可用能力的描述,包括以下高可用特性:
- 基础设施高可用:通过将腾讯专有云TCE 部署在 Tier-IV 或 Tier-III+级别的数据中心中,单数据中心的可用性达到4个9;
- 管控底座高可用:在腾讯专有云TCE 的管控底座中,所有支撑组件及各个产品的控制平面,均运行多个实例,可以实现跨 AZ 级别的高可用。在全局负载均衡的辅助下可实现多 Region 高可用,也就是当任一 Region 中所有 AZ 全部故障时,仍然可以访问其他 Region 的云控制台,对云上资源和业务进行操作;
- 网络连接高可用:在腾讯专有云TCE 中,无论是每个 AZ 内的网络设计,AZ 间的网络互联,还是云边界的网络连接,均支持高可用设计,保证单一链路或单一节点的故障不影响整网的连通性;
- 计算与调度高可用:腾讯专有云TCE 中的计算资源,如云服务器和容器服务平台等,能够实现 AZ 内或跨 AZ 的算力调度;
- 存储高可用:腾讯专有云TCE 中的存储资源,如云硬盘、文件存储及对象存储等,能够实现 AZ 内或跨 AZ 的多副本冗余存储;
- 中间件与数据库高可用:腾讯专有云TCE 提供的中间件服务和数据库服务能够具备跨 AZ 的高可用性,无论是部分中间件服务节点故障,还是单 AZ 内所有中间件服务节点故障,云平台都能够保证中间件服务的可用,数据的丢失在可接受范围内,高可用部署对中间件和数据库服务的性能影响也在可接受范围内;
- 微服务框架高可用:腾讯专有云TCE 提供的微服务框架服务能够具备跨 AZ 的高可用性,且支撑应用的跨 AZ 高可用,无论是部分微服务数据平面节点故障,还是部分微服务控制平面节点故障,甚至整 AZ 故障,云平台能够保证微服务数据平面的业务始终可用,控制平面的服务注册发现,和监控平面链路追踪等微服务功能可用;
- 应用高可用:腾讯专有云TCE 为应用提供的微服务框架、键值缓存及分布式事务等底层机制,能够保证,只要应用开发者基于业界形成的一定规范进行应用开发,无论是部分应用实例故障,还是单 AZ 内的所有实例全部故障,都不影响应用对外提供服务;
为了实现以上“八横四纵”的高可用架构,专有云TCE 的部署应当按照一定的规范进行,TCE 主要高可用架构模式分为四种,如下图所示:

图5 腾讯专有云TCE 高可用架构模式
- 单 AZ 部署:低成本场景下,腾讯专有云TCE 使用单 AZ 部署,保证单 AZ3内部基础硬件节点、各个云组件、机柜间、外部网络以及基础电力的高可用;
- 双活 AZ 部署:本场景能够有效的防止单 AZ 整体故障后对业务产生的影响,在主 AZ 故障后可以切换到从 AZ 保证业务不中断,数据库在 AZ 间进行同步复制保证 RPO=0;
- 双活 AZ+仲裁部署:在仅有双活 AZ 的场景下,主 AZ 出现故障需要手工拉起部分 ZK 和 Etcd 节点,本场景加入仲裁 AZ,仲裁 AZ 中运行支持 ZK 和 Etcd 组件,在主 AZ 故障时,仲裁 AZ 与从 AZ 重组为多数派进行仲裁,理论上 RTO 可以趋近于0,保证业务的平稳运行。本场景也是腾讯专有云TCE 的推荐部署场景;
- 多中心部署:同城三中心部署,或在 “双活 AZ+仲裁”场景下加入异地灾备数据中心,核心数据进行异地异步备份,保障在主从 AZ 所在地发生故障时能够及时支撑业务运行;
2. 高可用标准模型
2.1 三 AZ 部署

图6 腾讯专有云TCE 的三 AZ 部署
图6中展示了三 AZ 部署方案,云平台中的各个组件除 CVM、CBS、CFS 单 AZ 部署外,其他均为三 AZ 部署保证高可用性。
三 AZ 是公有云部署的标准模型,每个地域在有三个或三个以上 AZ 的情况下,可以保证任一 AZ 故障,对业务 RPO 和 RTO 造成的影响在对客承诺的范围内。
2.2 双 AZ+仲裁部署
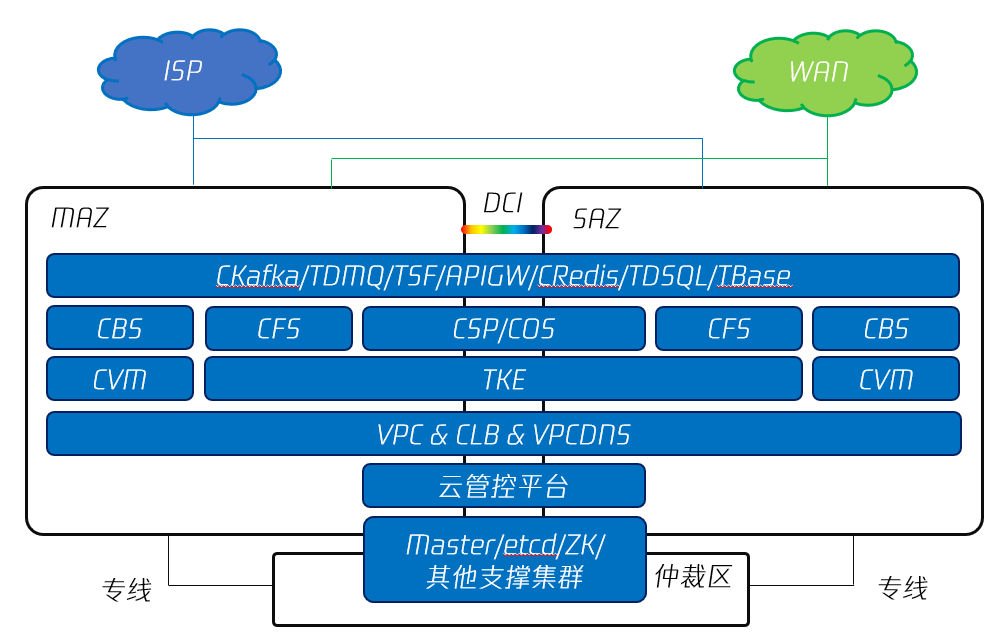
图7 腾讯专有云TCE 的双 Region+仲裁区部署
由于三 AZ 部署需要同一地域内至少有3个独立的机房,对于大部分用户而言条件要求过高,因此,TCE 也有针对成本方面的改善,在业务高可用方面进行部分妥协的部署方案,这就是将三 AZ 中的一个 AZ 中,所有云业务服务集群裁剪掉,仅保留控制平面,底座容器平台 Master、ZK 以及 Etcd 等元数据存储服务集群;由于仲裁区所需要的资源非常少,几台服务器就可以部署,因此,用户可以很容易地找到适合部署仲裁区的环境。
2.3 双 AZ 部署
对于部分不具备部署仲裁区条件的用户,也可以仅部署双 AZ 来实现业务的高可用,也就是俗称的“同城双活”。“同城双活”指的是在一定的地理距离范围内部署两个数据中心(MAZ 和 SAZ),这两个数据中心中运行的业务采用互备(A-B)或负载分担(A-A)的方式部署,当任一数据中心发生故障时,另一数据中心能够接管故障数据中心中的业务,实现业务的高可用,也就是使得 RTO 符合用户的需求;同时,两个数据中心中运行的业务所产生的数据,可以按照一定的要求,在两个数据中心之间实现一致性同步,从而将 RPO 控制在一定范围内。
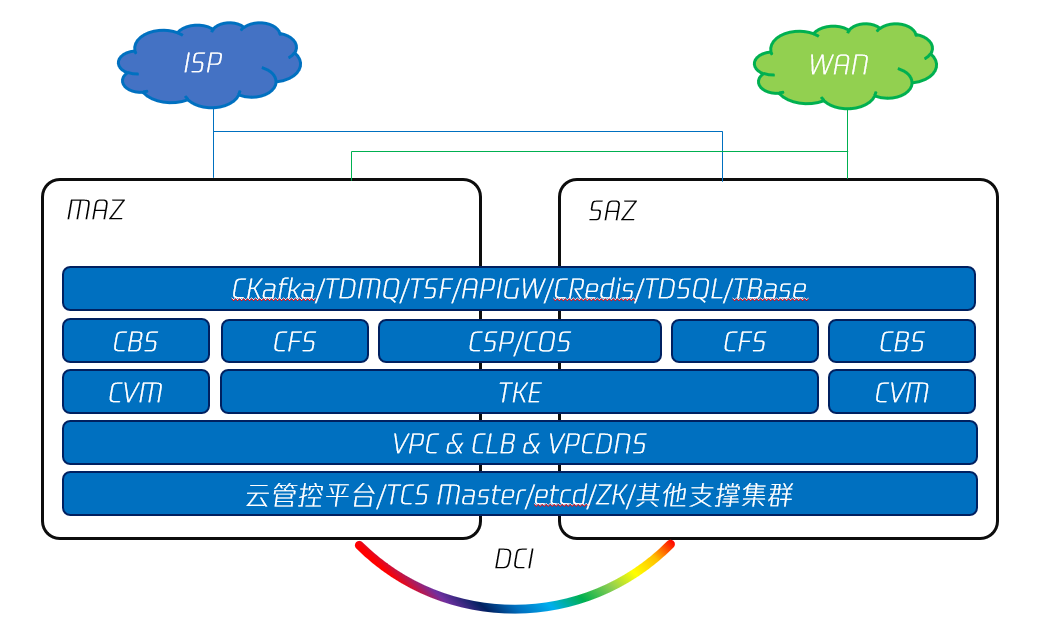
图8 腾讯专有云TCE 的双 AZ 部署
如图8所示,腾讯专有云TCE 可以在经过 DCI 线路互联互通的两个同城数据中心中部署双AZ,以实现 “同城双活”。特别地,在具备条件时,可以利用 DWDM(Dense Wavelength Division Multiplex,密集波分复用)来实现 DCI,可以支撑更多的业务双活及数据强一致同步。
2.4 多 Region 部署
多 Region 部署方案是另一种高可用部署方式。如图9所示,用户通过在异地建立灾备数据中心,实现核心数据的异地异步备份,保障在主 Region 所在地发生故障时从 Region 能够及时支撑业务运行。双 Region 间使用 DCI 互联互通。两个 Region 都具备连接外网的链路。
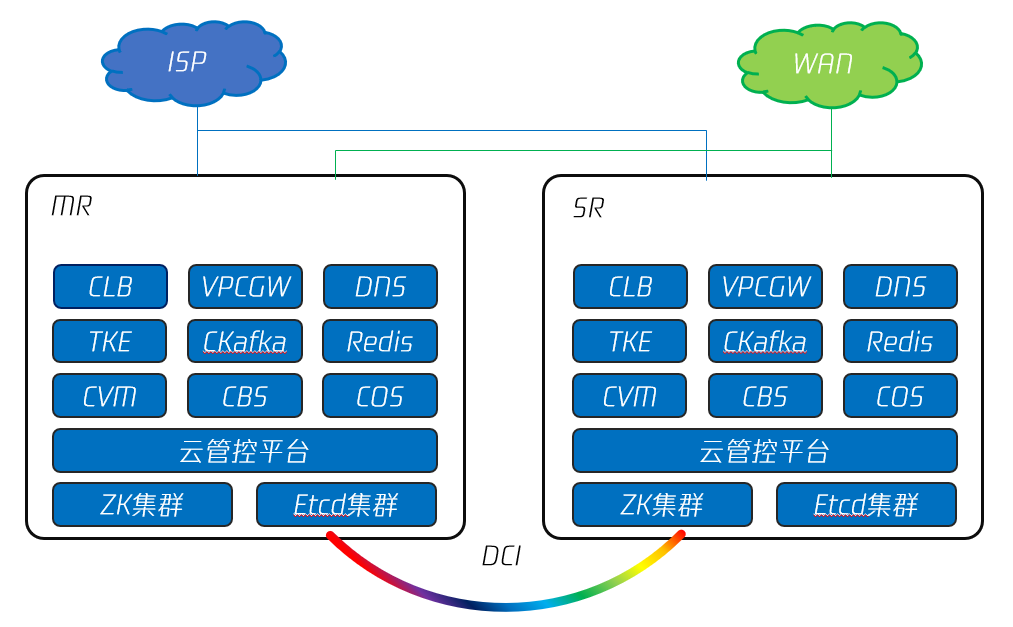
图9 腾讯专有云TCE 的双 Region 部署
3. 高可用实现设计
腾讯专有云TCE 的高可用部署,实际上是保障应用高可用(RTO 尽量趋近于0)和数据高可用(RPO 尽量趋近于0)的手段,也就是说,用户最终感知到的,是云上业务的高可用。
下图中简要展示了部署在腾讯专有云TCE 上的应用,实现高可用所依赖的各要素的部署方式:

图10 基于腾讯专有云TCE 实现的应用高可用
如图10所示,腾讯专有云TCE 上运行的应用,其高可用实际上依赖于图中的各要素。其中,属于云产品服务本身的有负载均衡 CLB、Web 前端云服务器 CVM、存储(包括块存储 CBS 和对象存储 CSP/COS)、中间件(包括 API 网关、消息队列 TDMQ、流式数据引擎 CKafka 及缓存 CRedis 等)以及数据库的高可用;同时,还需要网络、计算调度、管控平台、支撑组件与仲裁组件等支撑云平台运行的基础设施及控制平面的高可用。
3.1 IaaS 高可用设计
IaaS 高可用是应用级别高可用的最基本的前置条件。IaaS 高可用包括基础网络高可用、网络外连高可用、负载均衡&VPCGW 高可用、计算高可用和存储高可用。
云平台基础网络支持物理设备与链路的冗余备份,同时,双 AZ 或多 AZ 之间的 DCI 也采用冗余线路的高可用设计。特别地,在建设互联网出口、专线和 DCI 线路时,也应当尽量利用异构 ISP 提供的专线线路。这样,当单线路或某 ISP 出现整体故障时,不会对用户访问云上的业务造成影响。
负载均衡与 VPCGW 为云内的应用服务与 PaaS 服务提供了服务发现和服务路由机制。腾讯专有云TCE 的负载均衡和 VPCGW 实现了跨 AZ 的高可用,负载均衡 CLB 能够实现跨 AZ 集群,也就是在跨 AZ 的至少四个节点上实现用户会话的同步。这样一来,配合对外的路由发布,即使单一 AZ 的两个 CLB 节点故障,另一 AZ 的 CLB 节点也可以接管用户会话。而 VPCGW 以主备模式部署在小集群中,使用 VIP 对外提供服务。AZ 内部可以部署多个 VPCGW 的小集群,当其中一个集群发生故障时,可以在 AZ 内进行切换。当主 AZ 的 VPC 网关整体故障时,可以进行跨 AZ 切换。
计算资源的高可用包括应用前端的高可用和后台的高可用。目前,云上部署的绝大部分应用为 B/S 架构,其前端通过 Web 服务器实现,而后端一般为 Tomcat 等 Java 服务器,近年来也开始出现其他编程语言实现的后端服务。
Web 前端一般运行在云服务器 CVM 或容器平台 TKE 提供的容器 Pod 上。无论是 CVM 还是 TKE 的容器 Pod,都可以支持跨 AZ 的 Web 高可用。
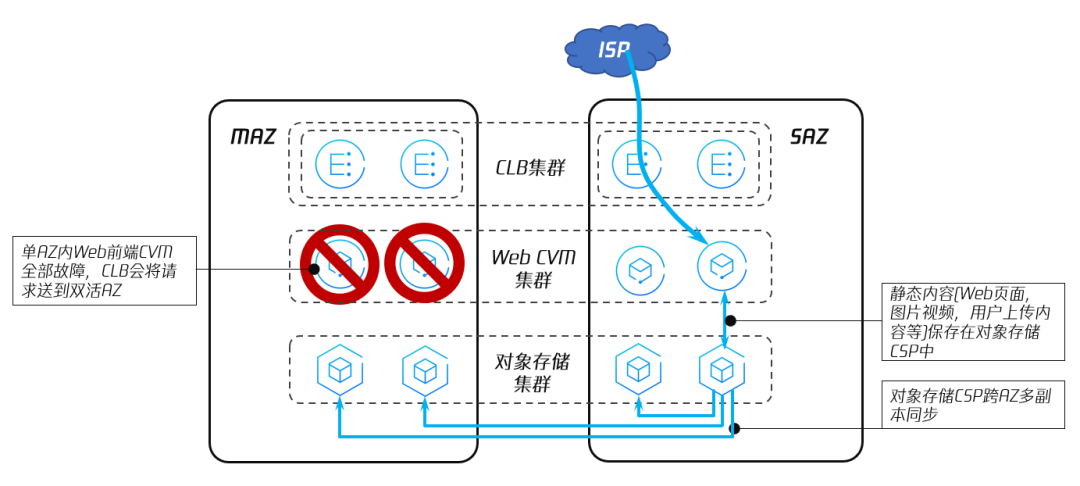
图11 基于腾讯专有云TCE 实现的应用前端高可用
腾讯专有云TCE 的存储分为块存储、文件存储和对象存储三种形态,其架构设计均为分布式存储。分布式存储的特点是,整个存储集群中,任意一个节点故障都不影响集群对外提供服务,也不会引起数据丢失,也就是实现 RTO 和 RPO 均为0。
块存储 CBS 采用三副本机制,集群的管理平面定期检查每个物理硬盘和每个节点的在线状态。如果有某块物理硬盘或某个节点状态异常,所有对该硬盘/该节点的写入请求将被暂缓执行,其故障恢复不需要人工干预,对业务完全透明。
对象存储 CSP/COS 常用于海量数据和前端静态资源的存储。TCE 无论是三 AZ 高可用部署,还是双 AZ 高可用部署,都可以实现对象存储的跨 AZ 高可用,其架构如下图所示:
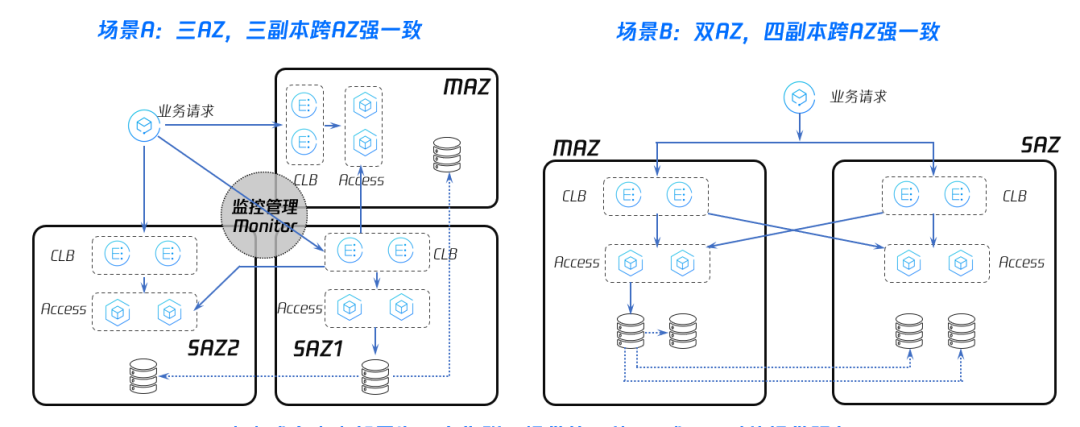
图12 专有云TCE 中对象存储高可用-跨 AZ 多副本
如图12中所示,场景 A 中对象存储跨三个 AZ 进行了部署,对象存储可以实现在数据落盘时,为其在三个 AZ 各创建一个副本,共计三个副本。当单 AZ 整体故障时,另两个 AZ 仍然有两个副本可用。场景 B 中展示了对象存储 CSP 跨 AZ 的四副本数据同步能力。CSP 可以实现在数据落盘时,为其在 MAZ 和 SAZ 各创建两个副本。当单 AZ 整体故障时,另一 AZ 仍然有两个副本可用。对象存储在双 AZ 或多 AZ 部署为一套集群,提供统一的 VIP 或 URL 对外提供服务,数据实时写入,满足 RPO=0核心指标。
3.2 PaaS 高可用设计
APP 后端与 Web 前端的区别是,APP 后端是有状态的。如果用户期望专有云TCE 上的 APP 层实现跨 AZ 的高可用,除通过负载均衡 CLB、云服务器 CVM 和其他 IaaS 产品的配合来降低 RTO,另一方面,还需要在 APP 开发的时候,使用专有云可支持跨 AZ 高可用的 PaaS 产品,使得在 RTO 无限趋近于0的同时,RPO 也控制在可接受的范围内。
腾讯专有云TCE 中,支撑应用高可用的 PaaS 产品主要有消息队列 TDMQ、流式数据引擎 CKafka、关系型数据库 TDSQL、缓存数据库 CRedis 以及微服务框架 TSF。
消息队列 TDMQ 产品采用了存算分离的架构,前端的 Broker 节点负责消息的收发,而后端的 Bookie 节点负责堆积消息的持久化存储。TDMQ 跨 AZ 高可用部署时,可以将 Broker 集群和 Bookie 集群都跨 AZ 部署,并且配置在持久化存储消息的时候,三个副本分配到位于两个或多个 AZ 上的 Bookie 节点,就可以实现跨 AZ 的高可用。
另一种常见的消息中间件 CKafka 的跨 AZ 高可用部署与 TDMQ 类似,CKafka 的 Broker 在生产消息和消费消息时,其 Leader 节点会同步到 AZ 内和其他 AZ 的 Follower。由于 CKafka 的原型 Kafka 在设计时,在数据可靠性与吞吐性能之间倾向于较高的性能,没有引入类似 Binlog 的 Double Check 机制,在极端情况下,有可能出现丢失消息的情况,因此,CKafka 无论是在 AZ 内,还是跨 AZ 高可用部署,都无法做到严格的 RPO=0。在对消息有严格要求的情况下,建议使用 TDMQ。TDMQ 的数据为强一致性同步,单 AZ 故障时,RTO 和 RPO 均可以为0。
PaaS 层中另一种常用的产品为缓存中间件,如腾讯专有云TCE 上的 CRedis。它是一个分布式的缓存键值(Key-Value)数据库,设计时采用了性能优先的策略,如默认将数据存在 RAM 中,按业务需要定期持久化到磁盘。因此,CRedis 跨 AZ 的高可用部署也需要考虑到这一点,在性能和一致性这两个要素发生冲突时,更多地向性能方面倾斜。CRedis 的高可用部署方式,是在两个 AZ 各部署相等的物理节点,在物理节点上混部 Redis Proxy 和 Redis Cache 节点。Redis Cache 节点在 Key 写入的同时,Redis Cache 主节点会将写入的数据向其他节点发起复制请求。出于性能优先考虑,CRedis 的跨 AZ 数据同步采用了最终一致性模型,也就是其他从节点有一个追赶主节点的过程,在单 AZ 故障时,其 RTO≈0,RPO≠0。
在腾讯专有云TCE 中,APP 产生的持久化数据,一般都在数据库中存储,并利用数据库本身的功能实现新增、检索、更新和删除。因而,APP 的高可用,特别是 RPO 指标,所依赖的一个要素是数据库的高可用。在应用开发中,用于记录交易信息、账户信息及认证鉴权信息等核心数据,最常用的是分布式关系型数据库 TDSQL。
TDSQL 在跨 AZ 高可用部署时,至少需要在每个 AZ 中部署2个数据库 Proxy 节点和2个数据库引擎节点,双 AZ 一共有四个数据库 Proxy 节点和四个引擎节点。在数据库服务实例的主引擎节点接收到写交易请求后,会将 SQL 写语句涉及的数据变更在本地落盘,另一方面会通过 Binlog 同步到位于各 AZ 的从节点,所有从节点返回数据落盘成功以后,主节点才返回写成功。可见,这种同步机制是所谓的强一致,可以实现在单 AZ 故障时,其 RTO≈0,RPO=0。
对于同城多活+异地灾备的场景,TDSQL 也可以实现在同城多 AZ 内数据强一致多活,而异地灾备 Region 的数据异步复制,牺牲一致性实现数据远端备份。对于特殊场景,也可以在同城多 AZ 内设定异步备份节点。
在云原生时代,应用的运行除依赖于前文所述的 PaaS 组件外,往往还需要微服务框架和容器平台的支持。腾讯专有云TCE 的微服务框架 TSF 实现了控制平面的高可用和数据平面的高可用。前者主要实现了服务注册发现的高可用,而后者主要包括 TSF 微服务网关的高可用和实际微服务节点的高可用。即使任一 AZ 全部故障,TSF 的控制平面也可以继续运行。同时,利用 TKE 容器平台的跨 AZ 高可用能力,实现数据平面的高可用。
TKE 容器平台高可用的核心是 Master 和 Etcd 节点的高可用。在双 AZ 和三 AZ 场景下,Master 和 Etcd 节点都可以通过跨 AZ 高可用部署,来实现单 AZ 整体故障不影响业务。
PaaS 层的高可用能力,赋予了业务应用真正的跨 AZ 高可用能力,无论是单 AZ 整体故障,还是其他单点/单链路故障,都不会影响业务的连续性,也不会造成业务数据的丢失。
3.3 管控平台与支撑组件高可用设计
专有云TCE 控制平面的总入口是云控制台 TCenter。在 TCenter 上,用户可以通过云 API,对 TCE 各产品运行在底座中的控制平面 OSS 组件下达命令,进行产品元数据的 CRUD 操作,从而分配、管理或释放云上的资源实例。
专有云TCE 的 TCenter 是一个全局性质的服务,无论专有云TCE 中部署了多少个 Region 和多少个 AZ,每个 Region 的每个 AZ 上,都运行了 TCenter 的前端实例,用户可以通过 GSLB 提供的智能 DNS 功能,将专有云TCE 的域名解析得到最合适的 IP 地址。这样,只要专有云TCE 有一个 AZ 处于可用状态,用户都可以访问 TCenter,实现管控平面入口的高可用,如下图所示:
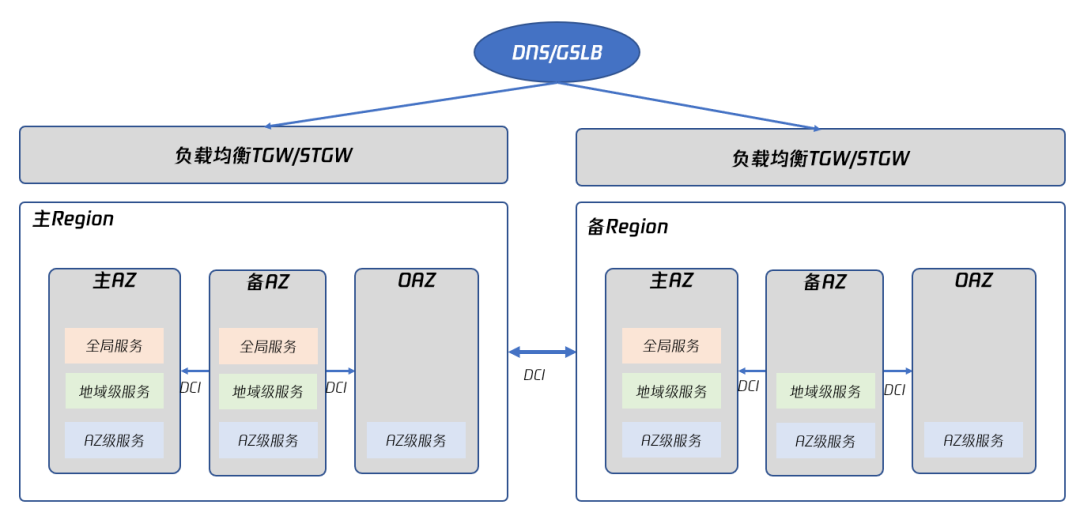
图13 云控制台 TCenter 的高可用部署
如图13所示,TCenter 属于全局服务,在不同 Region 中均有实例在运行,即使某一 Region 的全部 AZ 故障,用户也可以访问到其他 AZ 的 TCenter 实例,保证在最坏的情况下,只要有任意一个 AZ 存活,用户仍然可以登录云控制台并恢复业务。
在腾讯专有云TCE 中,底座支撑组件有底座 CSP,底座容器平台(包括 Master、Apiserver 和 Etcd),底座 ZK 等组件。所有云产品均依赖底座的容器平台作为控制平面,同时从底座 ZK 中存储和读取运行时所需要的元数据。
当专有云TCE 跨 AZ 部署时,各组件所依赖的 ZK 实例和 Etcd 集群,会组成跨 AZ 集群,以支撑各组件的跨 AZ 高可用。由于 ZK 和 Etcd 集群均使用了类似 PAXOS 算法的多数派选举机制,只有在集群中存活节点大于集群总节点数时,整个集群才能正常工作,如下表所示:
表1 分布式集群规模与最少工作节点数
ZK 或 Etcd集群规模 | 最少工作节点数 |
|---|---|
3 | 2 |
4 | 3 |
5 | 3 |
6 | 4 |
7 | 4 |
8 | 5 |
…… | …… |
从表1中可以看出,当 ZK/Etcd 集群节点总数为 2K+1(K 为自然数)时,需要集群中存活节点数大于等于 K+1。如集群节点总数为2K 时,也需要集群中存活节点数大于 K+1。
基于以上原理,专有云TCE 在双 AZ 高可用部署时,会在主 AZ(以下称为 MAZ)部署3个 ZK 节点和3个 Etcd 节点,双活 AZ(以下称为 SAZ)部署2个 ZK 节点和2个 Etcd 节点,构成5节点的 ZK 集群和5节点的 Etcd 集群。此外,SAZ 中还有冷备的 ZK 节点和 Etcd 节点,暂时不加入跨 AZ 的 ZK 集群和 Etcd 集群,如下图所示:

图14 ZK 和 Etcd 的3+2+1部署方式
图14中,MAZ 中有3个 ZK 节点和3个 Etcd 节点,均加入跨 AZ 集群,而 SAZ 中有2个活跃的 ZK 节点和2个 Etcd 节点,各自加入所属的跨 AZ 集群,ZK 集群和 Etcd 集群中,总共有5个 ZK 节点和 Etcd 节点。此外,SAZ 中还有1个 ZK 节点和1个 Etcd 节点处于冷备状态。这种部署方式被称为3+2+1部署方式。
在3+2+1部署方式中,当 SAZ 故障时,MAZ 中还有3个 ZK 节点和3个 Etcd 节点,可以形成多数派,业务不会受到影响。而 MAZ 故障时,由于 SAZ 中只有2个 ZK 节点和2个 Etcd 节点在集群中,还需要运维人员手工将备用节点加入集群,以形成3个节点的多数派,才能让业务从 MAZ 切换到 SAZ。这种方案又称为双 AZ 准双活方案。
双 AZ 准双活方案的 RTO 取决于备用节点加入集群的操作时间,因此 RTO≠0。可以通过 PAXOS 一致性原理很容易地推导出,所有的双活数据中心部署方案,如不依赖第三站点,都难以实现真正的 RTO≈0。
基于双 AZ 准双活方案,腾讯专有云TCE 为实现双 AZ 切换的 RTO≈0,增加了一个位于第三处机房(如办公区增加一个机柜)的仲裁区,在仲裁区中部署 ZK 热备节点和 Etcd 热备节点,代替手工拉起 ZK 和 Etcd 冷备节点的工作,加快业务切换,如下图所示:
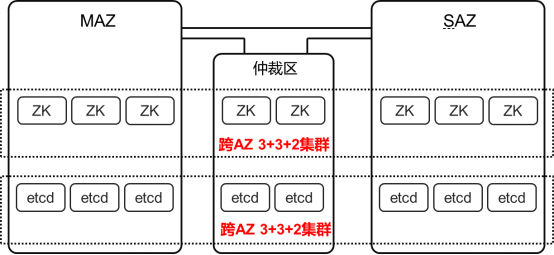
图15 ZK 和 Etcd 的3+3+2部署方式
在图15中,ZK 和 Etcd 采用3+3+2部署方式,也就是在 MAZ 和 SAZ 各部署3个 ZK 节点和 Etcd 节点,在仲裁区部署2个 ZK 节点和2个 Etcd 节点,构成8节点的 ZK 集群和8节点的 Etcd 集群。无论是 MAZ 还是 SAZ 整体故障,存活的 ZK 节点数和 Etcd 节点数均为5个,可以保证 ZK 集群和 Etcd 集群仍然有多数派实例保持运行,能够正常为专有云TCE 中的各产品与服务提供支撑,从而保证 TCE 具备 RTO≈0的基本条件。
必须注意的是,如果将仲裁区与任意一个 AZ 合并部署到同一机房,当该机房整体故障时,另一 AZ 不满足 ZK 和 Etcd 集群构成多数派的要求,将无法提供正常的支撑服务。
三. 腾讯专有云高可用切换场景
如前文所述,用户往往期望上云业务的可用性达到6个9,但根据腾讯云在大规模公有云运营实践中的统计,服务器单节点、网络设备单节点、外连线路或数据中心其他基础设施,其可用性一般在3个9或4个9之间。因而,我们需要考虑单节点故障、单机柜故障、单线路故障以及整 AZ 故障等不同情况下,腾讯专有云TCE 上应用及其依赖的各类服务或组件的高可用切换。
1. 单 AZ 互联网出口故障
单 AZ 的业务可用性,与 AZ 所在机房的互联网线路有强相关性。当专有云 TCE 某一 AZ 的互联网线路出现故障时,可以通过下图所示的机制,使得该 AZ 内部的云服务器等承载业务的资源,依然可以对外提供服务:
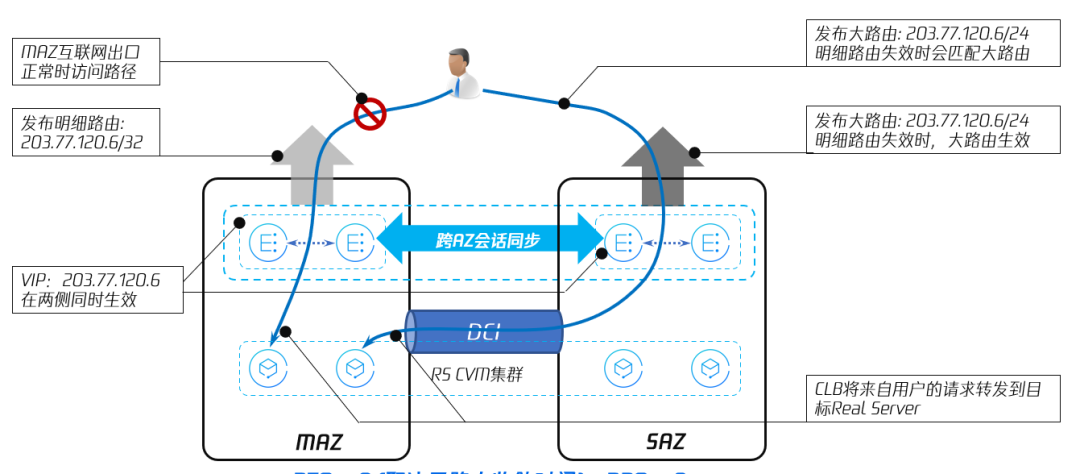
图16 单 AZ 互联网出口故障场景
图16中,专有云TCE 的 MAZ 与 SAZ 各自有运营商线路连接到互联网,同时,MAZ 和 SAZ 之间通过 DCI 线路互联。
当 MAZ 与互联网之间的线路发生故障,MAZ 发布的路由失效,来自用户的访问请求会被运营商的路由器匹配到 SAZ 对外发布的路由,从而将流量牵引到 SAZ 的 CLB 节点。由于 CLB 是跨 AZ 的集群,可以通过 DCI 将用户访问请求分发到另一 AZ,MAZ 内部的 CVM 依然可以通过 DCI,挂载到 CLB 集群上,通过 SAZ 的互联网线路对外提供服务。
需要注意的是,这种情况下的 RTO 取决于路由收敛时间,因此做不到 RTO≈0。
2. 整机柜故障
腾讯专有云TCE 的服务器需要置放于机柜中,而机柜本身的可用性取决于机柜本身的设计规范性,机柜制冷与通风系统的可靠性,以及供电的冗余与连续性。下图中展示了单个机柜整体故障时,对专有云TCE 中各组件的影响:
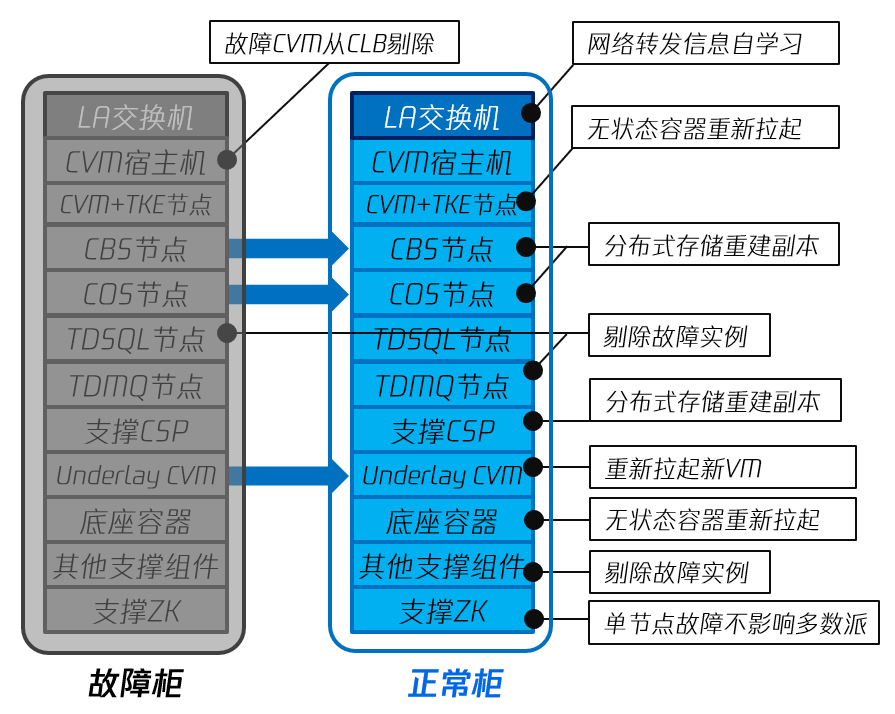
图17 单机柜故障场景
图17中,灰色部分代表故障机柜,蓝色部分代表正常机柜。
在大多数情况下,每2-3个机柜中的服务器,会连接到一组 TOR(Top of Rack, 柜顶交换机)。每组 TOR 由2台盒式交换机组成,彼此之间通过堆叠,MC-LAG(Multi-Chassis Link Aggregate)等高可用机制组成双机集群,从而做到在某机柜故障导致单台 TOR 故障的时候,在同一组的另一台 TOR 能够无缝接管业务的转发,可以认为 RTO≈0。
机柜故障导致的 CVM 宿主机故障,会触发 CLB 上剔除所涉及的宿主机,同时,云平台会在其他宿主机上重新拉起 CVM 顶替,其具体流程如前一小节所述,对于大部分用户而言,RTO≈0,实际上一般在1s 以内,少部分用户的 RTO 可能达到分钟级别。
与 CVM 宿主机类似地,容器平台 TKE 的 Worker Node 如果位于故障机柜中,也会使得该Worker Node 上的容器 Pod 全部停止运行。由于 TKE 继承了 Kubernetes 的高可用特性,无论对应的 Pod 是使用何种方式编排生成的,TKE 都可以在其他健康的 Worker Node 上重新拉起容器 Pod,并将其加入到负载均衡上,以实现容器化部署的应用的高可用。由于容器的启动与调度效率显著高于 CVM,容器化部署的应用 RTO 一般为秒级。
对于机柜故障引起的机柜中,云存储节点的故障,无论是块存储 CBS,还是对象存储 COS/CSP,只要不在一个机柜中部署两个属于同一个存储资源池的存储节点,就不会引起分布式存储的服务中断和数据丢失。当机柜故障引发节点离线时,块存储 CBS 和对象存储 COS 都会在其他健康的硬件节点上重建副本,同时其他健康节点也可以对外提供服务,从而做到 RTO≈0,RPO=0;
如果在故障机柜中,还有分布式消息中间件和分布式数据库等 PaaS 组件节点,由于 TDMQ、CKafka、CRedis、TDSQL 和 MongoDB 等 PaaS 组件都是多节点多副本部署,各副本节点之间通过内建的同步机制,实现分布式数据一致性。其高可用能力如下表所示:
表2 腾讯专有云TCE PaaS 节点级高可用能力
产品名称 | 部署方式 | 一致性 | RTO | RPO |
|---|---|---|---|---|
流式数据引擎 CKafka | 3节点,每 Topic 3副本 | 最终一致性 | ≈0 | ≠0 |
消息队列 TDMQ | 3节点,每 Topic 3副本 | 强一致性 | ≈0 | =0 |
关系型数据库 TDSQL | 3节点,每实例1主2从 | 强一致性 | ≈0 | =0 |
缓存数据库 CRedis | 5节点,每实例1主2从 | 强一致性 | ≈0 | =0 |
微服务框架 TSF | Consul 共3节点 | 最终一致性 | ≈0 | ≠0 |
如上表所示,所有的中间件和数据库,在单节点故障时,均可以实现 RTO≈0,其中,TDMQ,TDSQL 和 CRedis 在 AZ 内可以做到数据的强一致性,也就是 RPO=0。TSF 是最终一致性,存在着从副本或从节点“追赶”主副本或主节点的过程,因此,其 RPO≠0。CKafka 虽然使用了接近强一致性的设计,但其底层机制并非完全保证数据的强一致,因此 RPO 不严格为0。
除 IaaS 和 PaaS 产品外,腾讯专有云TCE 的底座还包括支撑云管控平台 TCenter、运维平台、运营平台及其他产品组件的控制平面运行的分布式存储、容器平台、ZK 及其他支撑组件等。由于这些支撑组件都是以多副本的方式部署,并将每个副本分散到不同的节点上,这样,单节点的故障只会影响一个副本,可以认为单节点故障的 RTO≈0,RPO=0。
总之,当单个计算/存储机柜发生故障时,对专有云TCE 上应用的影响在可控范围内,实际上总的 RTO 和 RPO 可以控制在分钟级别,如对应用的 RTO 和 RPO 有较高要求,在应用开发遵循一定规范的前提下,能实现 RTO≈0,RPO=0。
3. 双 AZ 部署时单 AZ 整体故障
当电力故障或其他灾难性不可抗力导致整个 AZ 全部故障时,此时,需要另一 AZ 接管全部业务,如下图所示:
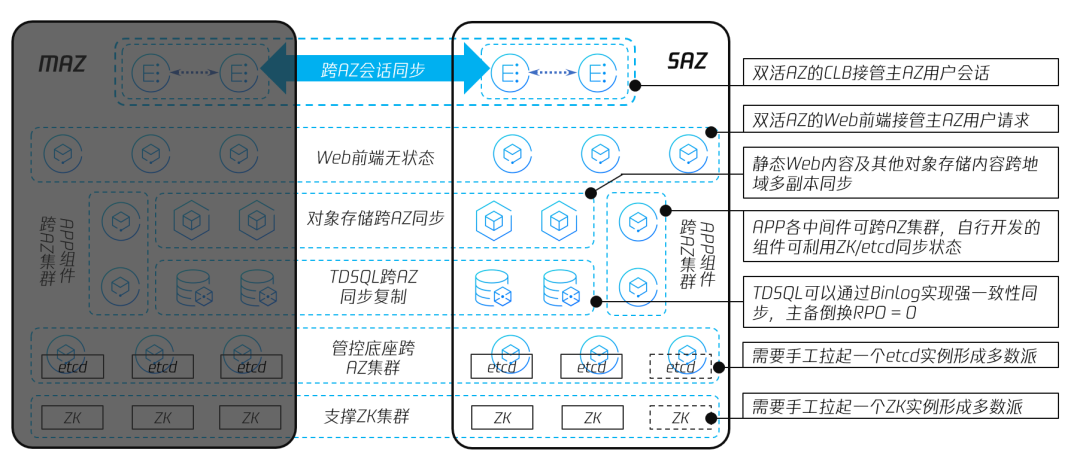
图18 腾讯专有云TCE 单 AZ 故障引起业务切换
图18中,展示了腾讯专有云TCE 的 MAZ 故障下,某一应用整体切换到 SAZ 的场景。假设该应用使用 CVM 作为前端 Web 服务器,Web 前端中所需的静态资源放置于对象存储中,后端 APP 在 CVM 或 TKE 的容器 Pod 上运行,利用 TCE 提供的中间件和数据库服务,实现组件之间消息的投递和数据的持久化存储。
当 MAZ 整体故障时,首先会触发 MAZ 侧 CLB 对外发布的路由失效,用户访问请求会被动态路由牵引到 SAZ 侧的 CLB 上。由于 CLB 是跨 AZ 高可用的,SAZ 的 CLB 可以接管来自用户的会话并转发请求,实现 RTO≈0。
CLB 把来自用户请求转发到 RS(Real Server)的依据是 RS 的健康度。由于 MAZ 整体故障,位于 MAZ 的所有 CVM 的健康度为0,CLB 集群不会将任何请求转发到 MAZ,而是让 SAZ 的 CVM 承担请求。类似地,从 Web 前端到 APP 后端的请求也会由 SAZ 内的所有运行 APP 的 CVM 或容器 Pod 承担,其 RTO≈0。
运行 Web 前端的 CVM 会挂载一个 CBS 云硬盘实例,作为系统盘使用,其他 Web 所需的静态内容,如文本、图片、代码或视频等,可以放置在对象存储中,便于 Http 访问的同时,也可以利用对象存储的跨 AZ 同步等功能,实现双 AZ 内容的一致,做到 RTO≈0,RPO=0。
云上应用的 APP 后端,无论是运行在 CVM 上,还是运行在容器 Pod 上,只要在开发时使用了跨 AZ 高可用的中间件和数据库,并利用专有云TCE 的 Zookeeper 存储一些关键状态数据和元数据,可以做到 RTO≈0,RPO=0。
如2.2.2小节中所述,腾讯专有云TCE 双 AZ 高可用部署时,支撑专有云TCE 各组件运行的 ZK和 Etcd 集群为3+2+1模式,在 MAZ 故障时,SAZ 内仅剩2个节点运行,需要通过手工拉起 ZK 冷备节点和 Etcd 冷备节点,来恢复 SAZ 的业务。手工拉起冷备节点的时间决定了故障倒换的 RTO。
在最坏的情况下,当单 AZ 出现故障,RTO 为分钟级别,而利用数据库存储的核心数据的 RPO=0。
4. 双 AZ+仲裁区部署时单 AZ 整体故障
由于前文所述的原因,腾讯专有云TCE 在双 AZ 部署时,MAZ 整体故障的业务切换需要人工介入,RTO 为分钟级别,如云上的应用的可用性需要6个9,双 AZ 部署难以满足 RTO 的要求。
为提升故障倒换效率,缩短 RTO,腾讯专有云TCE 支持双 AZ+仲裁区部署,也就是在双 AZ 以外的第三个地点,增加一个仲裁区,仲裁区中运行1-2个 ZK 节点和 Etcd 节点,如下图所示:
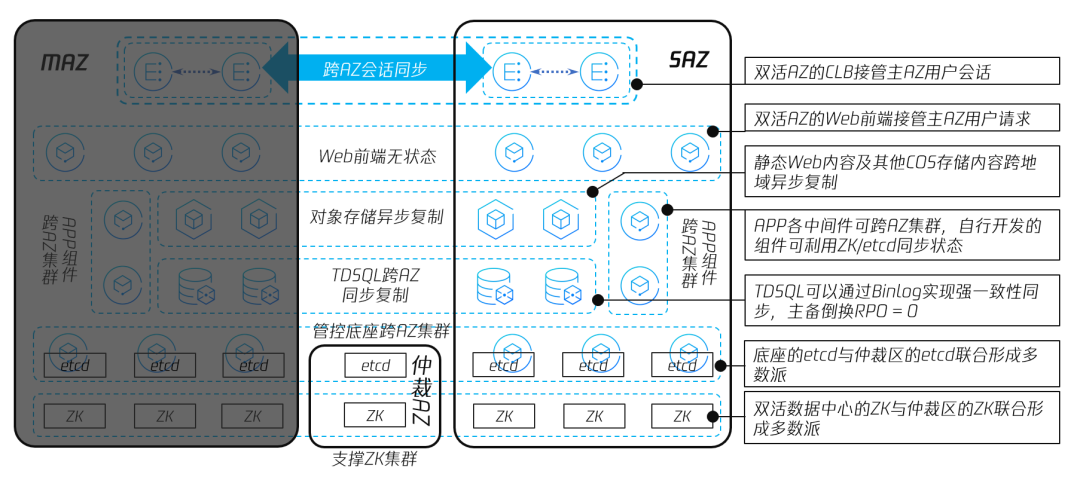
图19 腾讯专有云TCE 引入仲裁区加速故障倒换
相对于双 AZ 部署方式,图19引入了仲裁区,在仲裁区中运行了2个 ZK 节点和 Etcd 节点,而 SAZ 中运行的 ZK 节点和 Etcd 节点数量均为3个,MAZ+SAZ+仲裁区共有8个 ZK 节点和 Etcd 节点,也就是在2.2.2小节中提到的3+3+2部署方式。
在为专有云TCE 的双 AZ 增加仲裁区后,单 AZ 故障触发业务切换的机制与流程,与传统双 AZ 部署大同小异,其区别主要是,当单 AZ 故障,AZ 内的三个 ZK 实例和三个 Etcd 节点离开集群,ZK 集群和 Master/Etcd 集群内还有5个节点在运行,无需手工拉起冷备节点,也就是实现了 ZK 集群和 Master/Etcd 集群的 RTO≈0,消除了双 AZ 部署时故障倒换的卡点。
在引入仲裁区后,技术上能够实现单 AZ 整体故障时,业务倒换的 RTO≈0,RPO=0。
5. 地域级故障,跨地域切换接管
当灾难性不可抗力导致整个 Region 机房全部故障时,此时,需要另一 Region 接管全部业务,快速完成业务面及云平台管控面的切换接管能力,如下图所示:
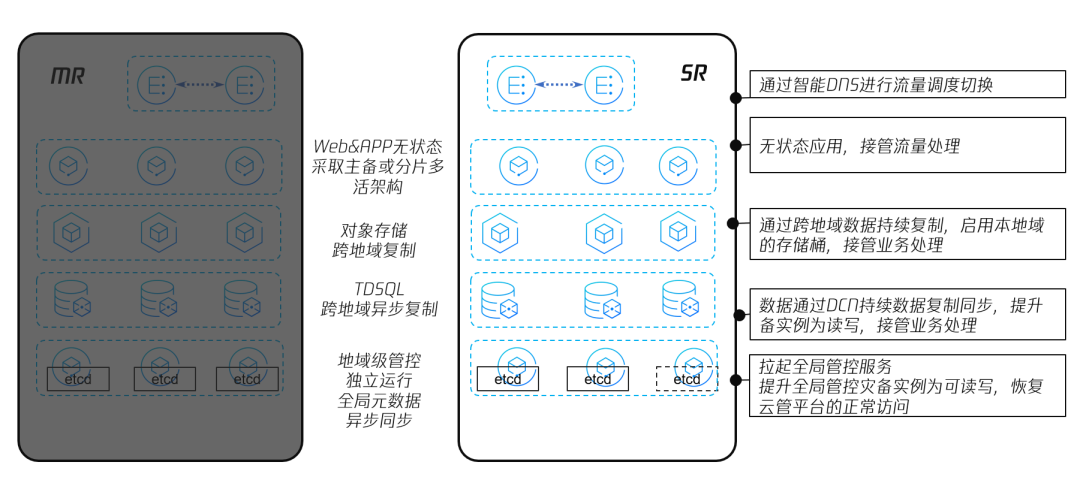
图20 腾讯专有云TCE 地域级故障,跨地域切换接管
当 MR 整体故障时,通过外部智能 DNS(GSLB)进行流量的调度切换到 SR,SR 上 WEB&APP 等无状态的应用直接接管流量进行处理;对象存储在正常情况下始终保持跨地域的异步复制,故障后启动本地域的存储桶,接管业务进行处理;关系型数据库正常情况下跨地域异步复制,发生故障后提升 SR 中数据库实例为读写,接管业务处理;Region 级管控组件正常情况下独立运行,全局的元数据异步同步到 SR,故障时 SR 的全局管控服务会被拉起,并提升全局管控实例为可读写,从而恢复云管平台的正常访问。
四. 小结
无论是公有云,还是私有化部署的专有云平台,作为关键信息基础设施,其对应用高可用的支撑能力,决定了云平台上应用的 RTO 和 RPO。腾讯专有云TCE 继承了腾讯公有云在高可用方面完备的设计,能够帮助客户建设基于多地多中心的分布式云平台,从而使得任何故障发生时,业务的 RTO 和 RPO 在可控范围内。