注意力机制(Attention)是深度学习中常用的tricks,可以在模型原有的基础上直接插入,进一步增强你模型的性能。本文记录常用 Attention 方法与 Pytorch 实现。
概述
注意力机制起初是作为自然语言处理中的工作Attention Is All You Need被大家所熟知,从而也引发了一系列的XX is All You Need的论文命题,SENET-Squeeze-and-Excitation Networks是注意力机制在计算机视觉中应用的早期工作之一,并获得了2017年imagenet, 同时也是最后一届Imagenet比赛的冠军,后面就又出现了各种各样的注意力机制,应用在计算机视觉的任务中。
论文 arxiv 镜像
如果大家遇到论文下载比较慢, 推荐使用中科院的 arxiv 镜像: http://xxx.itp.ac.cn, 国内网络能流畅访问 简单直接的方法是, 把要访问 arxiv 链接中的域名从 https://arxiv.org 换成 http://xxx.itp.ac.cn
比如: 从 https://arxiv.org/abs/1901.07249 改为 http://xxx.itp.ac.cn/abs/1901.07249
注意力
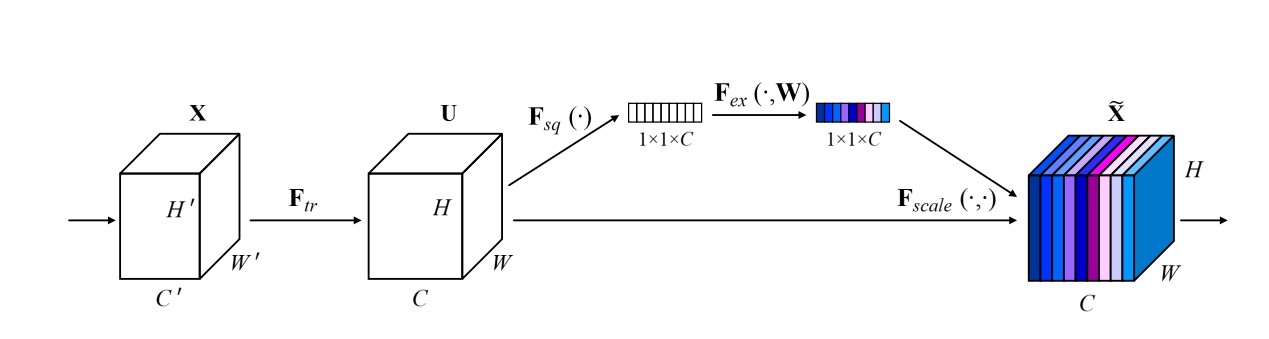
SeNet: Squeeze-and-Excitation Attention
- 论文地址:https://arxiv.org/abs/1709.01507
- 核心思想:对通道做注意力机制,通过全连接层对每个通道进行加权。
- 网络结构:

- Pytorch代码
import numpy as np import torch from torch import nn from torch.nn import initclass SEAttention(nn.Module):
def __init__(self, channel=512, reduction=16): super().__init__() self.avg_pool = nn.AdaptiveAvgPool2d(1) self.fc = nn.Sequential( nn.Linear(channel, channel // reduction, bias=False), nn.ReLU(inplace=True), nn.Linear(channel // reduction, channel, bias=False), nn.Sigmoid() ) def init_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): init.kaiming_normal_(m.weight, mode='fan_out') if m.bias is not None: init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): init.constant_(m.weight, 1) init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): init.normal_(m.weight, std=0.001) if m.bias is not None: init.constant_(m.bias, 0) def forward(self, x): b, c, _, _ = x.size() y = self.avg_pool(x).view(b, c) y = self.fc(y).view(b, c, 1, 1) return x * y.expand_as(x)
if name == 'main':
input = torch.randn(50, 512, 7, 7)
se = SEAttention(channel=512, reduction=8)
output = se(input)
print(output.shape)
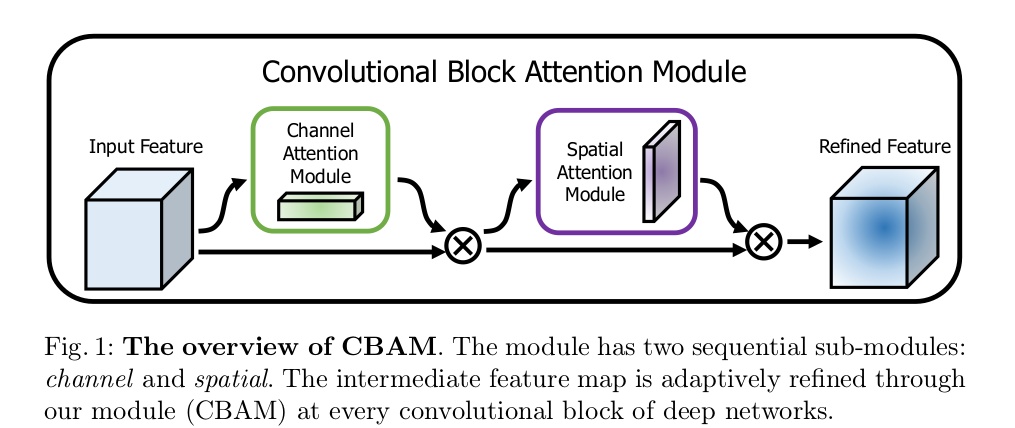
CBAM: Convolutional Block Attention Module
- 论文地址:CBAM: Convolutional Block Attention Module
- 核心思想:对通道方向上做注意力机制之后再对空间方向上做注意力机制
- 网络结构
- Pytorch代码
import numpy as np
import torch
from torch import nn
from torch.nn import initclass ChannelAttention(nn.Module):
def init(self, channel, reduction=16):
super().init()
self.maxpool = nn.AdaptiveMaxPool2d(1)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.se = nn.Sequential(
nn.Conv2d(channel, channel // reduction, 1, bias=False),
nn.ReLU(),
nn.Conv2d(channel // reduction, channel, 1, bias=False)
)
self.sigmoid = nn.Sigmoid()def forward(self, x): max_result = self.maxpool(x) avg_result = self.avgpool(x) max_out = self.se(max_result) avg_out = self.se(avg_result) output = self.sigmoid(max_out + avg_out) return outputclass SpatialAttention(nn.Module):
def init(self, kernel_size=7):
super().init()
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2)
self.sigmoid = nn.Sigmoid()def forward(self, x): max_result, _ = torch.max(x, dim=1, keepdim=True) avg_result = torch.mean(x, dim=1, keepdim=True) result = torch.cat([max_result, avg_result], 1) output = self.conv(result) output = self.sigmoid(output) return outputclass CBAMBlock(nn.Module):
def __init__(self, channel=512, reduction=16, kernel_size=49): super().__init__() self.ca = ChannelAttention(channel=channel, reduction=reduction) self.sa = SpatialAttention(kernel_size=kernel_size) def init_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): init.kaiming_normal_(m.weight, mode='fan_out') if m.bias is not None: init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): init.constant_(m.weight, 1) init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): init.normal_(m.weight, std=0.001) if m.bias is not None: init.constant_(m.bias, 0) def forward(self, x): b, c, _, _ = x.size() residual = x out = x * self.ca(x) out = out * self.sa(out) return out + residualif name == 'main':
input = torch.randn(50, 512, 7, 7)
kernel_size = input.shape[2]
cbam = CBAMBlock(channel=512, reduction=16, kernel_size=kernel_size)
output = cbam(input)
print(output.shape)
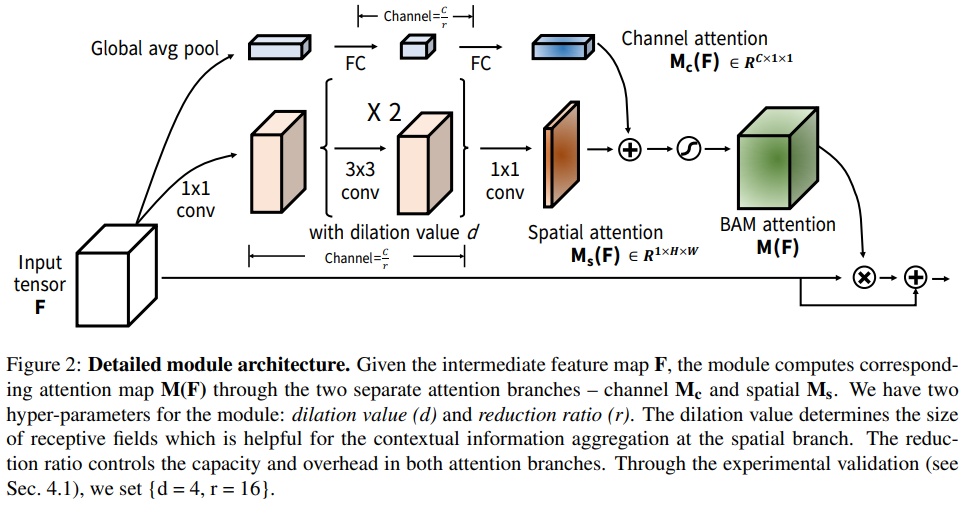
BAM: Bottleneck Attention Module
- 论文地址:https://arxiv.org/pdf/1807.06514.pdf
- 网络结构:
- Pytorch代码
import numpy as np
import torch
from torch import nn
from torch.nn import initclass Flatten(nn.Module):
def forward(self, x):
return x.view(x.shape[0], -1)class ChannelAttention(nn.Module):
def init(self, channel, reduction=16, num_layers=3):
super().__init__()
self.avgpool = nn.AdaptiveAvgPool2d(1)
gate_channels = [channel]
gate_channels += [channel // reduction] * num_layers
gate_channels += [channel]self.ca = nn.Sequential() self.ca.add_module('flatten', Flatten()) for i in range(len(gate_channels) - 2): self.ca.add_module('fc%d' % i, nn.Linear(gate_channels[i], gate_channels[i + 1])) self.ca.add_module('bn%d' % i, nn.BatchNorm1d(gate_channels[i + 1])) self.ca.add_module('relu%d' % i, nn.ReLU()) self.ca.add_module('last_fc', nn.Linear(gate_channels[-2], gate_channels[-1])) def forward(self, x): res = self.avgpool(x) res = self.ca(res) res = res.unsqueeze(-1).unsqueeze(-1).expand_as(x) return resclass SpatialAttention(nn.Module):
def init(self, channel, reduction=16, num_layers=3, dia_val=2):
super().__init__()
self.sa = nn.Sequential()
self.sa.add_module('conv_reduce1',
nn.Conv2d(kernel_size=1, in_channels=channel, out_channels=channel // reduction))
self.sa.add_module('bn_reduce1', nn.BatchNorm2d(channel // reduction))
self.sa.add_module('relu_reduce1', nn.ReLU())
for i in range(num_layers):
self.sa.add_module('conv_%d' % i, nn.Conv2d(kernel_size=3, in_channels=channel // reduction,
out_channels=channel // reduction, padding=1, dilation=dia_val))
self.sa.add_module('bn_%d' % i, nn.BatchNorm2d(channel // reduction))
self.sa.add_module('relu_%d' % i, nn.ReLU())
self.sa.add_module('last_conv', nn.Conv2d(channel // reduction, 1, kernel_size=1))def forward(self, x): res = self.sa(x) res = res.expand_as(x) return resclass BAMBlock(nn.Module):
def __init__(self, channel=512, reduction=16, dia_val=2): super().__init__() self.ca = ChannelAttention(channel=channel, reduction=reduction) self.sa = SpatialAttention(channel=channel, reduction=reduction, dia_val=dia_val) self.sigmoid = nn.Sigmoid() def init_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): init.kaiming_normal_(m.weight, mode='fan_out') if m.bias is not None: init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): init.constant_(m.weight, 1) init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): init.normal_(m.weight, std=0.001) if m.bias is not None: init.constant_(m.bias, 0) def forward(self, x): b, c, _, _ = x.size() sa_out = self.sa(x) ca_out = self.ca(x) weight = self.sigmoid(sa_out + ca_out) out = (1 + weight) * x return out
if name == 'main':
input = torch.randn(50, 512, 7, 7)
bam = BAMBlock(channel=512, reduction=16, dia_val=2)
output = bam(input)
print(output.shape)
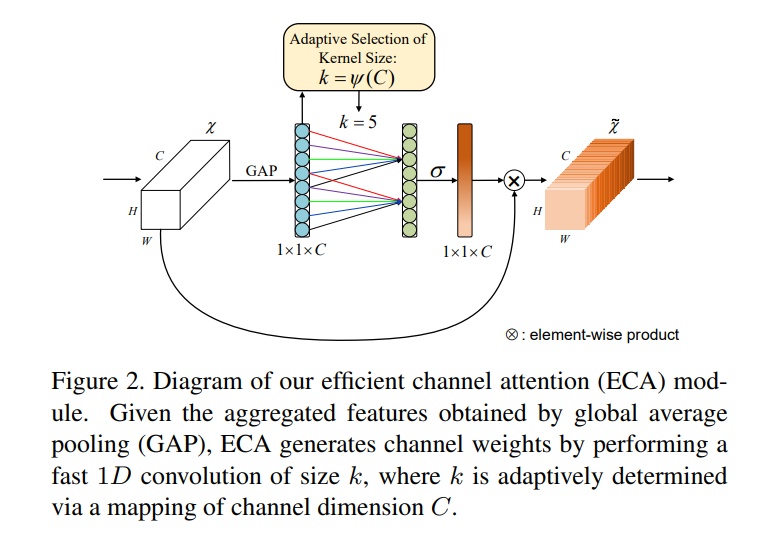
ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
- 论文地址:https://arxiv.org/pdf/1910.03151.pdf
- 网络结构:
- Pytorch代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
from collections import OrderedDictclass ECAAttention(nn.Module):
def __init__(self, kernel_size=3): super().__init__() self.gap = nn.AdaptiveAvgPool2d(1) self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2) self.sigmoid = nn.Sigmoid() def init_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): init.kaiming_normal_(m.weight, mode='fan_out') if m.bias is not None: init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): init.constant_(m.weight, 1) init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): init.normal_(m.weight, std=0.001) if m.bias is not None: init.constant_(m.bias, 0) def forward(self, x): y = self.gap(x) # bs,c,1,1 y = y.squeeze(-1).permute(0, 2, 1) # bs,1,c y = self.conv(y) # bs,1,c y = self.sigmoid(y) # bs,1,c y = y.permute(0, 2, 1).unsqueeze(-1) # bs,c,1,1 return x * y.expand_as(x)
if name == 'main':
input = torch.randn(50, 512, 7, 7)
eca = ECAAttention(kernel_size=3)
output = eca(input)
print(output.shape)
SA-NET: SHUFFLE ATTENTION FOR DEEP CONVOLUTIONAL NEURAL NETWORKS
- 论文地址:https://arxiv.org/pdf/2102.00240.pdf
- 网络结构:

- Pytorch代码
import numpy as np
import torch
from torch import nn
from torch.nn import init
from torch.nn.parameter import Parameterclass ShuffleAttention(nn.Module):
def __init__(self, channel=512, reduction=16, G=8): super().__init__() self.G = G self.channel = channel self.avg_pool = nn.AdaptiveAvgPool2d(1) self.gn = nn.GroupNorm(channel // (2 * G), channel // (2 * G)) self.cweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1)) self.cbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1)) self.sweight = Parameter(torch.zeros(1, channel // (2 * G), 1, 1)) self.sbias = Parameter(torch.ones(1, channel // (2 * G), 1, 1)) self.sigmoid = nn.Sigmoid() def init_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): init.kaiming_normal_(m.weight, mode='fan_out') if m.bias is not None: init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): init.constant_(m.weight, 1) init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): init.normal_(m.weight, std=0.001) if m.bias is not None: init.constant_(m.bias, 0) @staticmethod def channel_shuffle(x, groups): b, c, h, w = x.shape x = x.reshape(b, groups, -1, h, w) x = x.permute(0, 2, 1, 3, 4) # flatten x = x.reshape(b, -1, h, w) return x def forward(self, x): b, c, h, w = x.size() # group into subfeatures x = x.view(b * self.G, -1, h, w) # bs*G,c//G,h,w # channel_split x_0, x_1 = x.chunk(2, dim=1) # bs*G,c//(2*G),h,w # channel attention x_channel = self.avg_pool(x_0) # bs*G,c//(2*G),1,1 x_channel = self.cweight * x_channel + self.cbias # bs*G,c//(2*G),1,1 x_channel = x_0 * self.sigmoid(x_channel) # spatial attention x_spatial = self.gn(x_1) # bs*G,c//(2*G),h,w x_spatial = self.sweight * x_spatial + self.sbias # bs*G,c//(2*G),h,w x_spatial = x_1 * self.sigmoid(x_spatial) # bs*G,c//(2*G),h,w # concatenate along channel axis out = torch.cat([x_channel, x_spatial], dim=1) # bs*G,c//G,h,w out = out.contiguous().view(b, -1, h, w) # channel shuffle out = self.channel_shuffle(out, 2) return outif name == 'main':
input = torch.randn(50, 512, 7, 7)
se = ShuffleAttention(channel=512, G=8)
output = se(input)
print(output.shape)
Polarized Self-Attention: Towards High-quality Pixel-wise Regression
- 论文地址:https://arxiv.org/abs/2107.00782
- 网络结构:
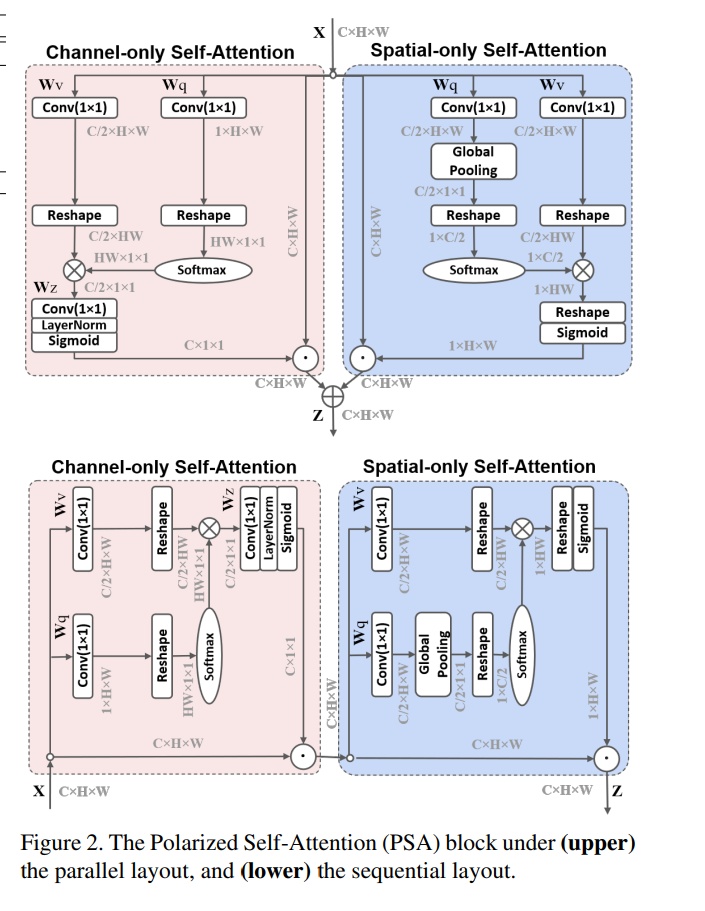
- Pytorch代码
import numpy as np
import torch
from torch import nn
from torch.nn import initclass ParallelPolarizedSelfAttention(nn.Module):
def __init__(self, channel=512): super().__init__() self.ch_wv = nn.Conv2d(channel, channel // 2, kernel_size=(1, 1)) self.ch_wq = nn.Conv2d(channel, 1, kernel_size=(1, 1)) self.softmax_channel = nn.Softmax(1) self.softmax_spatial = nn.Softmax(-1) self.ch_wz = nn.Conv2d(channel // 2, channel, kernel_size=(1, 1)) self.ln = nn.LayerNorm(channel) self.sigmoid = nn.Sigmoid() self.sp_wv = nn.Conv2d(channel, channel // 2, kernel_size=(1, 1)) self.sp_wq = nn.Conv2d(channel, channel // 2, kernel_size=(1, 1)) self.agp = nn.AdaptiveAvgPool2d((1, 1)) def forward(self, x): b, c, h, w = x.size() # Channel-only Self-Attention channel_wv = self.ch_wv(x) # bs,c//2,h,w channel_wq = self.ch_wq(x) # bs,1,h,w channel_wv = channel_wv.reshape(b, c // 2, -1) # bs,c//2,h*w channel_wq = channel_wq.reshape(b, -1, 1) # bs,h*w,1 channel_wq = self.softmax_channel(channel_wq) channel_wz = torch.matmul(channel_wv, channel_wq).unsqueeze(-1) # bs,c//2,1,1 channel_weight = self.sigmoid(self.ln(self.ch_wz(channel_wz).reshape(b, c, 1).permute(0, 2, 1))).permute(0, 2, 1).reshape( b, c, 1, 1) # bs,c,1,1 channel_out = channel_weight * x # Spatial-only Self-Attention spatial_wv = self.sp_wv(x) # bs,c//2,h,w spatial_wq = self.sp_wq(x) # bs,c//2,h,w spatial_wq = self.agp(spatial_wq) # bs,c//2,1,1 spatial_wv = spatial_wv.reshape(b, c // 2, -1) # bs,c//2,h*w spatial_wq = spatial_wq.permute(0, 2, 3, 1).reshape(b, 1, c // 2) # bs,1,c//2 spatial_wq = self.softmax_spatial(spatial_wq) spatial_wz = torch.matmul(spatial_wq, spatial_wv) # bs,1,h*w spatial_weight = self.sigmoid(spatial_wz.reshape(b, 1, h, w)) # bs,1,h,w spatial_out = spatial_weight * x out = spatial_out + channel_out return outclass SequentialPolarizedSelfAttention(nn.Module):
def __init__(self, channel=512): super().__init__() self.ch_wv = nn.Conv2d(channel, channel // 2, kernel_size=(1, 1)) self.ch_wq = nn.Conv2d(channel, 1, kernel_size=(1, 1)) self.softmax_channel = nn.Softmax(1) self.softmax_spatial = nn.Softmax(-1) self.ch_wz = nn.Conv2d(channel // 2, channel, kernel_size=(1, 1)) self.ln = nn.LayerNorm(channel) self.sigmoid = nn.Sigmoid() self.sp_wv = nn.Conv2d(channel, channel // 2, kernel_size=(1, 1)) self.sp_wq = nn.Conv2d(channel, channel // 2, kernel_size=(1, 1)) self.agp = nn.AdaptiveAvgPool2d((1, 1)) def forward(self, x): b, c, h, w = x.size() # Channel-only Self-Attention channel_wv = self.ch_wv(x) # bs,c//2,h,w channel_wq = self.ch_wq(x) # bs,1,h,w channel_wv = channel_wv.reshape(b, c // 2, -1) # bs,c//2,h*w channel_wq = channel_wq.reshape(b, -1, 1) # bs,h*w,1 channel_wq = self.softmax_channel(channel_wq) channel_wz = torch.matmul(channel_wv, channel_wq).unsqueeze(-1) # bs,c//2,1,1 channel_weight = self.sigmoid(self.ln(self.ch_wz(channel_wz).reshape(b, c, 1).permute(0, 2, 1))).permute(0, 2, 1).reshape( b, c, 1, 1) # bs,c,1,1 channel_out = channel_weight * x # Spatial-only Self-Attention spatial_wv = self.sp_wv(channel_out) # bs,c//2,h,w spatial_wq = self.sp_wq(channel_out) # bs,c//2,h,w spatial_wq = self.agp(spatial_wq) # bs,c//2,1,1 spatial_wv = spatial_wv.reshape(b, c // 2, -1) # bs,c//2,h*w spatial_wq = spatial_wq.permute(0, 2, 3, 1).reshape(b, 1, c // 2) # bs,1,c//2 spatial_wq = self.softmax_spatial(spatial_wq) spatial_wz = torch.matmul(spatial_wq, spatial_wv) # bs,1,h*w spatial_weight = self.sigmoid(spatial_wz.reshape(b, 1, h, w)) # bs,1,h,w spatial_out = spatial_weight * channel_out return spatial_outif name == 'main':
input = torch.randn(1, 512, 7, 7)
psa = SequentialPolarizedSelfAttention(channel=512)
output = psa(input)
print(output.shape)
Spatial Group-wise Enhance: Improving Semantic Feature Learning in Convolutional Networks
- 论文地址:https://arxiv.org/pdf/1905.09646.pdf
- 网络结构:

- Pytorch代码
import numpy as np
import torch
from torch import nn
from torch.nn import initclass SpatialGroupEnhance(nn.Module):
def __init__(self, groups): super().__init__() self.groups = groups self.avg_pool = nn.AdaptiveAvgPool2d(1) self.weight = nn.Parameter(torch.zeros(1, groups, 1, 1)) self.bias = nn.Parameter(torch.zeros(1, groups, 1, 1)) self.sig = nn.Sigmoid() self.init_weights() def init_weights(self): for m in self.modules(): if isinstance(m, nn.Conv2d): init.kaiming_normal_(m.weight, mode='fan_out') if m.bias is not None: init.constant_(m.bias, 0) elif isinstance(m, nn.BatchNorm2d): init.constant_(m.weight, 1) init.constant_(m.bias, 0) elif isinstance(m, nn.Linear): init.normal_(m.weight, std=0.001) if m.bias is not None: init.constant_(m.bias, 0) def forward(self, x): b, c, h, w = x.shape x = x.view(b * self.groups, -1, h, w) # bs*g,dim//g,h,w xn = x * self.avg_pool(x) # bs*g,dim//g,h,w xn = xn.sum(dim=1, keepdim=True) # bs*g,1,h,w t = xn.view(b * self.groups, -1) # bs*g,h*w t = t - t.mean(dim=1, keepdim=True) # bs*g,h*w std = t.std(dim=1, keepdim=True) + 1e-5 t = t / std # bs*g,h*w t = t.view(b, self.groups, h, w) # bs,g,h*w t = t * self.weight + self.bias # bs,g,h*w t = t.view(b * self.groups, 1, h, w) # bs*g,1,h*w x = x * self.sig(t) x = x.view(b, c, h, w) return x
if name == 'main':
input = torch.randn(50, 512, 7, 7)
sge = SpatialGroupEnhance(groups=8)
output = sge(input)
print(output.shape)
Coordinate Attention for Efficient Mobile Network Design
主要应用在轻量级网络上,在resnet系列上效果不好。
- 论文地址:https://arxiv.org/abs/2103.02907
- 网络结构
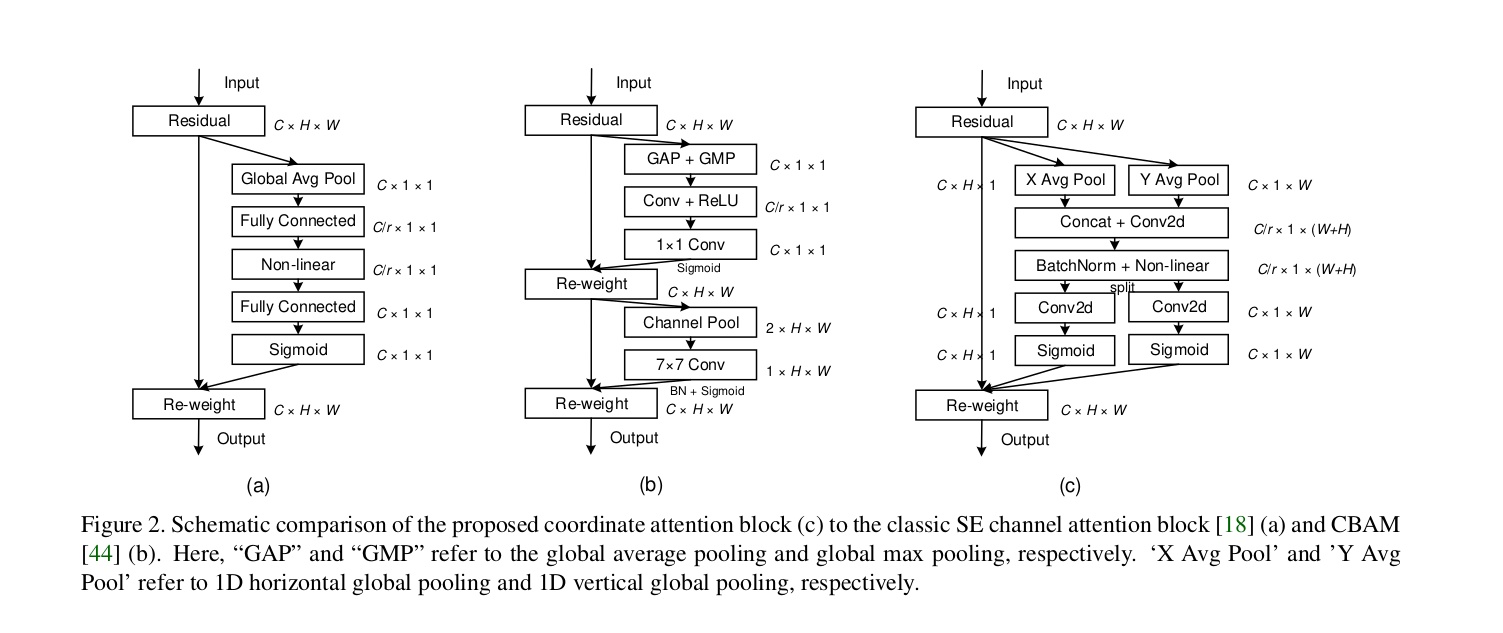
- Pytorch代码
import torch import torch.nn as nn import torch.nn.functional as Fclass h_sigmoid(nn.Module):
def init(self, inplace=True):
super(h_sigmoid, self).init()
self.relu = nn.ReLU6(inplace=inplace)def forward(self, x): return self.relu(x + 3) / 6class h_swish(nn.Module):
def init(self, inplace=True):
super(h_swish, self).init()
self.sigmoid = h_sigmoid(inplace=inplace)def forward(self, x): return x * self.sigmoid(x)class CoordAtt(nn.Module):
def init(self, inp, oup, reduction=32):
super(CoordAtt, self).init()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))mip = max(8, inp // reduction) self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0) self.bn1 = nn.BatchNorm2d(mip) self.act = h_swish() self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0) def forward(self, x): identity = x n, c, h, w = x.size() x_h = self.pool_h(x) x_w = self.pool_w(x).permute(0, 1, 3, 2) y = torch.cat([x_h, x_w], dim=2) y = self.conv1(y) y = self.bn1(y) y = self.act(y) x_h, x_w = torch.split(y, [h, w], dim=2) x_w = x_w.permute(0, 1, 3, 2) a_h = self.conv_h(x_h).sigmoid() a_w = self.conv_w(x_w).sigmoid() out = identity * a_w * a_h return out
Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
计算量特别大,效果一般
- 论文地址: https://arxiv.org/abs/2112.05561
- Pytorch 代码
class GAM_Attention(nn.Module): def __init__(self, in_channels, out_channels, rate=4): super(GAM_Attention, self).__init__()self.channel_attention = nn.Sequential( nn.Linear(in_channels, int(in_channels / rate)), nn.ReLU(inplace=True), nn.Linear(int(in_channels / rate), in_channels) ) self.spatial_attention = nn.Sequential( nn.Conv2d(in_channels, int(in_channels / rate), kernel_size=7, padding=3), nn.BatchNorm2d(int(in_channels / rate)), nn.ReLU(inplace=True), nn.Conv2d(int(in_channels / rate), out_channels, kernel_size=7, padding=3), nn.BatchNorm2d(out_channels) ) def forward(self, x): # print(x) b, c, h, w = x.shape x_permute = x.permute(0, 2, 3, 1).view(b, -1, c) x_att_permute = self.channel_attention(x_permute).view(b, h, w, c) x_channel_att = x_att_permute.permute(0, 3, 1, 2) x = x * x_channel_att x_spatial_att = self.spatial_attention(x).sigmoid() out = x * x_spatial_att # print(out) return out
更多注意力
双路注意力机制-DANET
- 论文标题:Fu_Dual_Attention_Network_for_Scene_Segmentation
- 论文地址:https://openaccess.thecvf.com/content_CVPR_2019/papers/Fu_Dual_Attention_Network_for_Scene_Segmentation_CVPR_2019_paper.pdf
- 时间:2019
- 网络结构
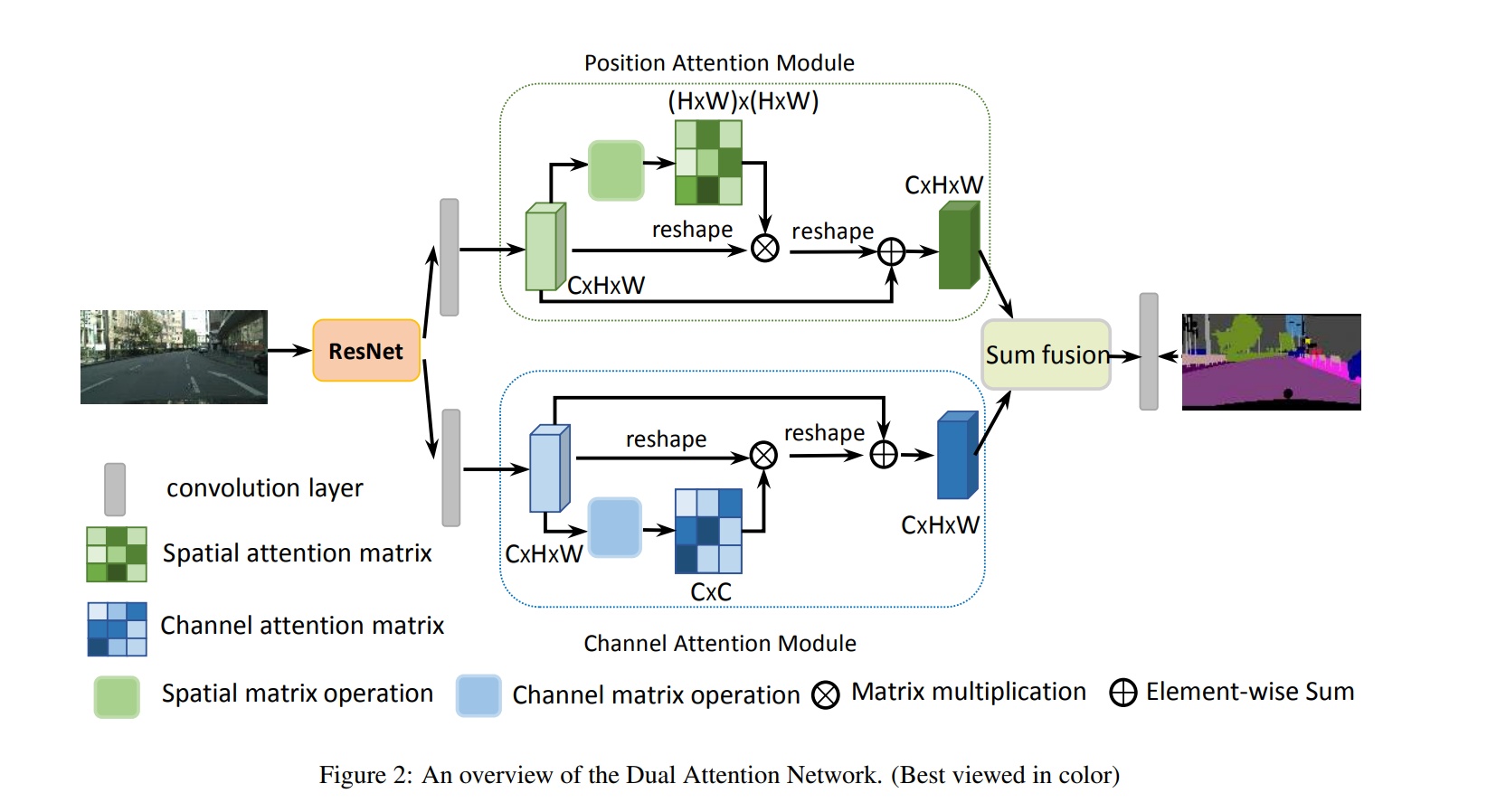
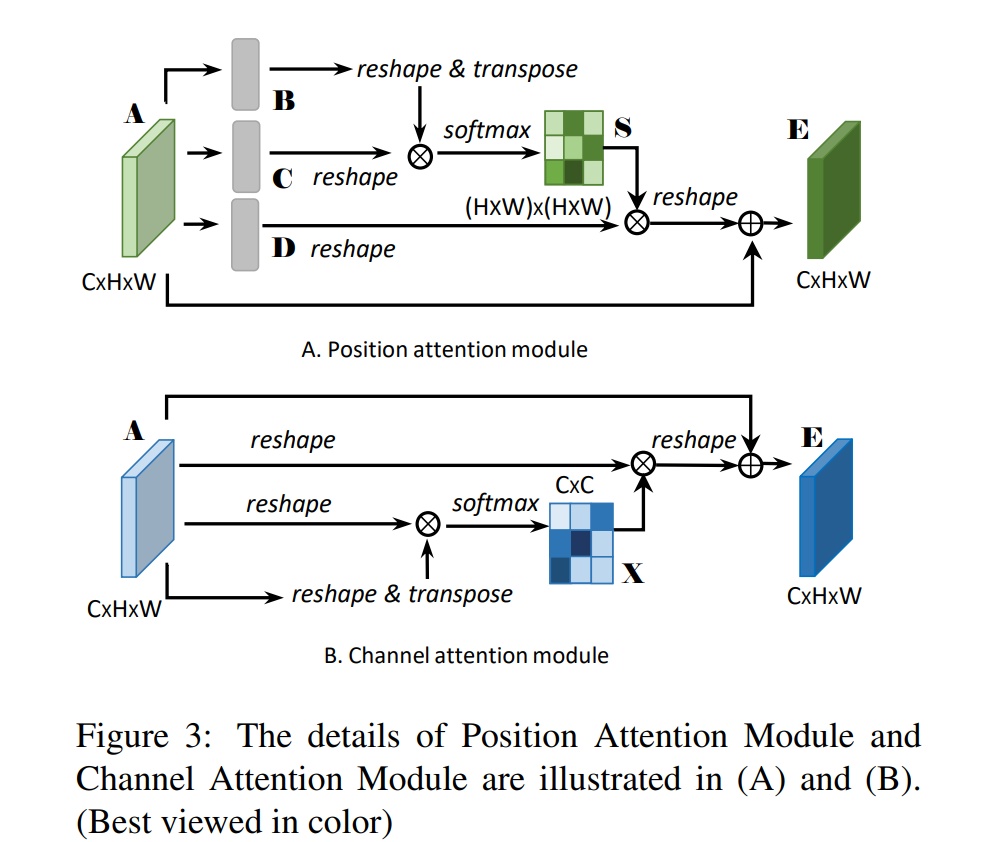
位置注意力-CCNET
在上面的danet上改的,主要是解决计算量的问题, 通过十字交叉的结构来解决
- 论文标题:CCNet: Criss-Cross Attention for Semantic Segmentation
- 论文地址:https://openaccess.thecvf.com/content_ICCV_2019/papers/Huang_CCNet_Criss-Cross_Attention_for_Semantic_Segmentation_ICCV_2019_paper.pdf
- 时间:2019

参考资料
- https://blog.csdn.net/ECHOSON/article/details/121993573
- https://github.com/xmu-xiaoma666/External-Attention-pytorch