❝本节来介绍如何通过R来批量做相关性分析,将通过两个小例子来进行介绍,1个
for循环与另一个tidyverse体系;
加载R包
代码语言:javascript
复制
library(tidyverse)
library(magrittr)
library(ggstatsplot)
案例一
导入数据
代码语言:javascript
复制
Bats <- read.csv(file = "Bats_data.csv", header = T, stringsAsFactors = F)
Bats_subset <- select(Bats, Activity, Area.thinned:Distance.creek.water)
构建容器
代码语言:javascript
复制
rows <- ncol(Bats_subset) - 1
Correlations <- data.frame(
variable = character(length = rows),
correlation = numeric(length = rows),
stringsAsFactors = F
)
循环计算相关性
代码语言:javascript
复制
for (i in 1:rows) {
temp1 <- colnames(Bats_subset[i + 1])
temp2 <- cor(Bats_subset[, 1], Bats_subset[, i + 1], method = "pearson")
Correlations[i, 1] <- temp1
Correlations[i, 2] <- temp2
}
代码语言:javascript
复制
variable correlation
1 Area.thinned -0.40890389
2 Time.since.thinned -0.02135752
3 Exclusion.thinned 0.17562438
4 Distance.murray.water -0.18071570
5 Distance.creek.water -0.09130258
案例二
❝此处计算单个基因与其余全部基因的相关性,小编在此介绍如何不使用循环用
tidyverse体系函数来进行计算
❞
代码语言:javascript
复制
read_tsv("data.xls") %>% column_to_rownames(var="TCGA_id") %>%
pivot_longer(-B2M) %>%
pivot_longer(names_to = "name_2", values_to = "value_2",B2M) %>%
group_by(name_2,name) %>%
summarise(cor= cor.test(value_2,value,method="spearman")$estimate,
p.value = cor.test(value_2,value,method="spearman")$p.value) %>% as.data.frame() %>%
set_colnames(c("gene_1","gene_2","cor","pvalue")) %>%
filter(pvalue < 0.05) %>%
arrange(desc(abs(cor)))%>%
dplyr::slice(1:500)
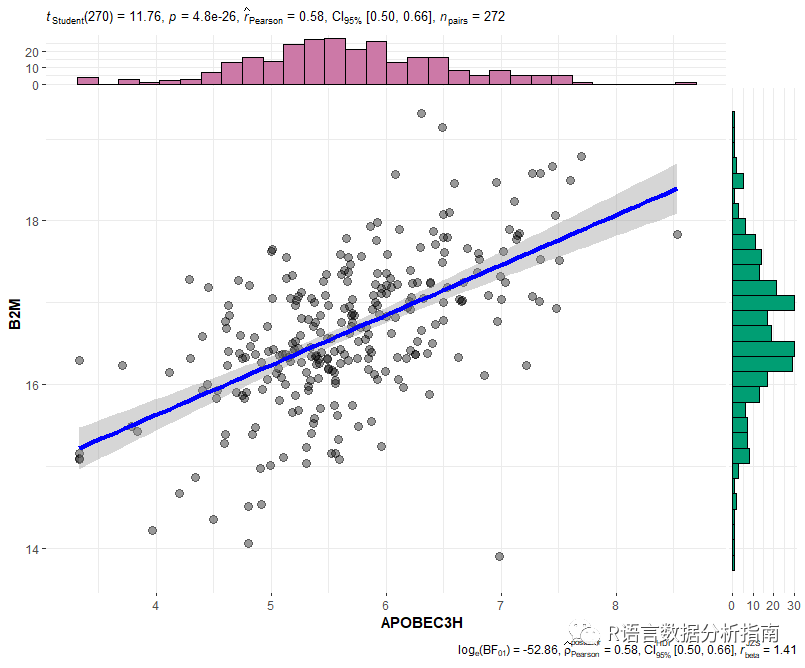
❝可以看到与
B2M相关性最高的为APOBEC3H基因
❞
代码语言:javascript
复制
gene_1 gene_2 cor pvalue
<chr> <chr> <dbl> <dbl>
1 B2M APOBEC3H 0.577 1.48e-25
2 B2M XCL2 0.577 1.51e-25
3 B2M KIR2DL4 0.565 2.31e-24
4 B2M TIFAB 0.565 2.63e-24
5 B2M XCL1 0.561 5.92e-24
6 B2M FUT7 0.558 1.21e-23
7 B2M ZBED2 0.557 1.57e-23
8 B2M IFNG 0.526 8.71e-21
9 B2M NCR3 0.524 1.39e-20
10 B2M SSTR3 0.506 4.22e-19
数据可视化
❝此处用ggstatsplot包来进行结果的展示真是方便至极
❞
代码语言:javascript
复制
df2 <- read_tsv("data.xls")
ggscatterstats(data = df2,y = B2M,x=APOBEC3H,
centrality.para = "mean",
margins = "both",
xfill = "#CC79A7",
yfill = "#009E73",
marginal.type = "histogram")