图神经网络是人工智能的一个热点方向,从图的视角解读大数据,可以灵活建模复杂的信息交互关系,吸引大量学者的关注并在多个工业领域得到广泛应用。
《图深度学习从理论到实践》由浅入深,全面介绍图神经网络的基础知识、典型模型方法和应用实践。《图深度学习从理论到实践》不仅包括一般的深度学习基础和图基础知识,还涵盖了图表示学习、图卷积、图注意力、图序列等典型图网络模型,以京东自研的Galileo平台为代表的图学习框架,以及图神经网络在电商推荐和流量风控方面的两个典型工业应用。
《图深度学习从理论到实践》既适合对数据挖掘、机器学习方向以及图建模交叉方向感兴趣的高年级本科生和研究生作为教材使用,也适合互联网电商、金融风控、社交网络分析、药物研发等企业的从业者参考学习。
以下内容节选自《图深度学习从理论到实践》。

广告反作弊中的传统图算法
网络广告作弊是由某些团伙和个人借由计算机和手机等智能设备在一定的网络环境下实施的。考虑到作弊成本,作弊团伙的人力资源和设备资源相对有限和固定,一般而言,在网络行径中会呈现出孤立性和集聚性等特点。同时,设备、账户、网络IP地址等信息可以很好的用图数据刻画,是图算法应用的合适场景,图算法在反作弊的团伙挖掘领域有广泛应用。
欺诈用户往往会把自己的欺诈行为伪装成正常的用户行为,以逃避风险监控平台的识别。为了尽量贴近真实用户的购买习惯,作弊平台会对刷手提出一系列要求,比如要求货比三家、最低浏览时长、浏览停留时间以及要求对于正常热销商品做一定购买等,这些行为都会导致已有风控经验指标的部分失效。
典型的传统图算法包括Louvain,Fraudar,D-cube等无监督算法,这类算法的共同点是通过定义稠密度量指标,采用搜索策略进行度量指标优化,从而来检测大图中的稠密子图结构,最终达到识别出欺诈用户群体的目的。这些算法主要适用于检测是否存在团伙、群体欺诈的风控场景(例如,群控设备攻击、群控模拟器欺诈、人工分布式群体欺诈等)。下面对这三种图算法展开简单介绍:
1.1 Louvain算法
2008年,Vincent 等提出的Louvain算法,是基于模块度(Modularity)的社区发现算法,采用模块的度来计算社区的稠密程度,其优化目标是最大化整个社区网络模块的度。该算法的计算模式是当一个节点被添加到一个社区中使得该社区的模块度增加,则认为该节点应该属于该社区,否则留在原属社区内。模块度的定义如下:
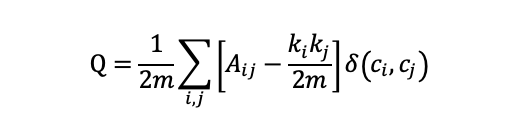
其中,m 为图中边的总数, 表示节点对 之间的权重, 分别表示指向节点 i 和节点 j 的边的权重之和, 表示节点 i 当前所在社区。具体来说,模块度的优化目标是想让社区内部点之间的连接相对稠密,而不同社区的点之间的连接相对稀疏。所以模块度也可以理解为社区内部边的权重减去所有与社区节点相连的边的权重和,在无向图上更加容易理解,就是社区内部的度数减去社区内节点的总度数。
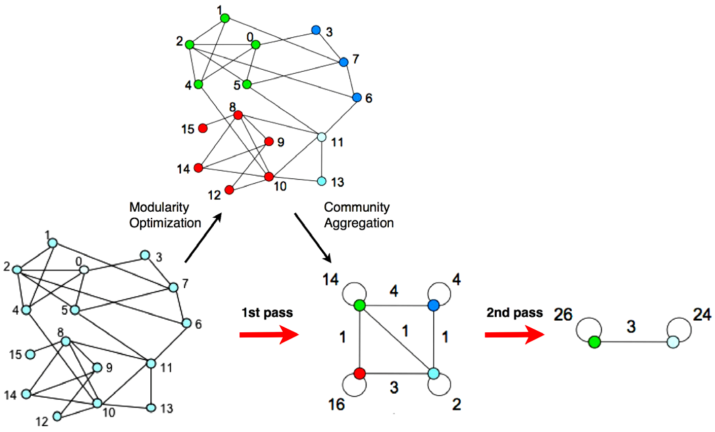
▲ Louvain算法示意图
开始每个节点均被视作独立社区,边的权重均被初始化为0,后续迭代更新可分为两个步骤:
(a) 针对数据集合中的某一个节点,遍历该节点的所有邻居,并计算当该节点加入到邻居节点所在社区后,模块度的变化,并将该节点加入模块度增大最大的社区,依次逻辑遍历数据集合中所有节点,重复执行,直到社区归属不再发生变化;
(b) 将步骤(a)形成的社区,视作一个单点,计算“社区点”之间的连接边的权重,以及社区内所有边的权重之和。
1.2 Fraudar 算法
Fraudar算法来自2016年度KDD会议最佳论文,是一种针对二部图中的稠密子图检测算法,旨在找出平台上的伪装虚假团体。虚假账户通过构建与正常用户的联系进行伪装,而这些伪装往往会形成一个稠密的子图。如下图所示,构建用户与目标的二部图。
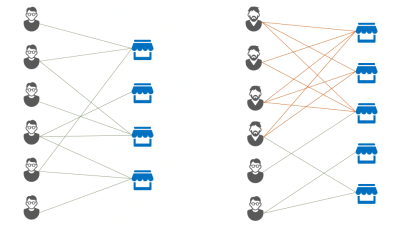
▲ 二部图下的正常连接模式 (左) 和Lockstep欺诈模式 (右)
这里定义三种可疑度,边的可疑度定义为目标入度的衰减函数 ,x 表示边的数目,c 为常数,原文中取 c=5,即当目标节点的入度越大,与之相关联的边权重值越小;节点可疑度定义为该节点关联的所有边的可疑度之和;子图平均可疑度定义为该子图边的可疑度之和除以子图所包含的节点总数。
Fraudar对边可疑度的含义是,与目标类结点连接的边越多,其可疑程度越小,即根据连接数降权,即交易量越大的店铺,其交易可疑程度越小,因为大概率是真热门店铺。下图展示了客户与热门店铺和刷单店铺的交易网络中,初始各边及结点的可疑度计算,计算过程为:
1)确定目标与
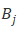
相连的边数
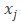
;
2)计算边的可疑度
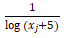
,结点B1有3条边连接,则其边可疑度为1/log(3+5)=0.48,结点B2有2条边连接,则其边可疑度为1/log(2+5)=0.51
3) 节点
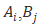
,可疑度计算,结点可疑度定义为 F() =
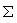
(边可疑度),即F(B1)= 0.48*3 = 1.44,F(B2) = 0.51*2 = 1.02, F(A1) = 0.48 + 0.51 = 0.99, F(A2) = 0.0.48+0.51 = 0.99, F(A3) = 0.48。
4)全体结点可疑度:
F(S) = F(A) + F(B) = F(B1) + F(B2) + F(A1) + F(A2) + F(A3) = 4.92
5)全局可疑度:
G(s) = F(s) / |s| = 4.92 / 5 = 0.98
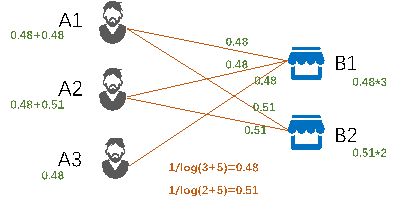
▲ 二部图初始边和结点可疑度计算示意图
初始可疑度确定完毕后在模型迭代过程中,Fraudar贪心的逐步移除图所有二类结点中可疑度最低的结点。因为网络规模通常较大,所有结点构建了用于快速搜索的二叉树,以二部图中的结点作为叶结点,并让父结点记录其子结点中的最小值,用以快速定位到该最小值所对应的叶结点,然后将其从二部图中删除,并更新网络可疑度、更新优先树。如此往复,低可疑度的结点逐步减少,网络剩余结点的全局平均可疑度G(·)逐步增大,直到最后一个结点被移除而归为0。回溯此过程中使G(·)达到最大的迭代,此时对应的留存结点即我们的目标结点,他们之间的关系网络是整个网络的最可疑致密子图。
1.3 D-cube算法
Kijung Shin 等在2017年提出D-Cube算法,它也是一种稠密子张量检测算法,以一个高阶张量的视角来考察图的关系数据。该方法可以看作是一种针对k维超图的稠密子图挖掘算法,相较于仅适用挖掘二部图中的稠密子图的 Fraudar 算法,D-Cube 算法能够从 k-均匀超图中挖掘稠密的高阶子图,可以支持从更高的数据维度来进行问题建模。
例如在店铺欺诈评论检测场景中,欺诈者出于任务约束以及资源约束会尽可能多的用他们控制的用户账号对目标店铺集进行虚假评论,当然同时也会存在大量的正常用户账号在一组热门店铺都有过评论,这时除了欺诈用户节点与他们的目标店铺节点会形成稠密子张量外,在建模时可以采用时间维度的信息,比如采用用户-店铺-时间三个维度构成的 3 阶张量建模来捕捉欺诈用户群体在时间维度的聚集性,这样能够从更高的信息维度辨别出真实的欺诈用户群体,如下图所示。
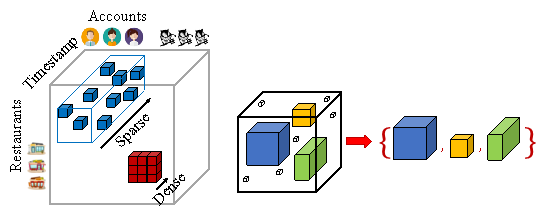
▲ D-cube张量方法
该算法将寻找欺诈团伙的问题,转化为寻找高阶张量矩阵中的top K个密度块的问题。一个块的密度按照平均可以计算为:
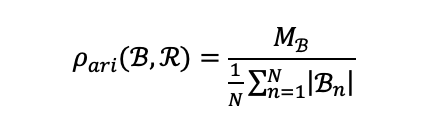
选择某一个维度,进行切片,如下图所示,按照以z轴为法向量进行切片,按照块的密度,先删去密度小于平均密度的块,并再随机挑选其它维度,执行相同的操作。D-Cube 算法与 Fraudar 算法的寻优过程类似,不同之处在迭代删除阶段,D-Cube 算法采用了剪枝加速技巧使得算法相较于 Fraudar 更快,同时 D-Cube 算法有对应的 Map-Reduce 实现版本,扩展性较好。


图深度学习在广告反作弊领域的应用
近些年随着图深度学习的迅猛发展,图神经网络在风控领域有着广泛的应用。图深度学习算法可以刻画图中的结构信息和节点自身的特征信息,并且深度学习方法有强大的泛化能力,能大幅提升识别效果。如下图所示,根据节点的上下文特征,我们希望采用图神经网络的方法,构建设备的二分类问题,预测用户群体是否属于作弊群体,来达到检测的目的。
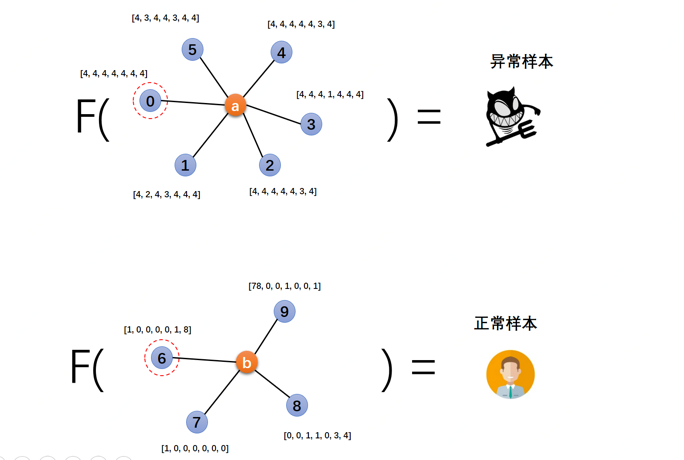
▲ 图神经网络预测示意图
2018年,Liu等提出了欺诈行为的图嵌入模型(Graph Embedding for Malicious accounts, GEM),认为同时存在设备聚集(Device Aggregation)和行为聚集(Activity Aggregation),并结合两者构建异质图挖掘支付宝上的欺诈行为。其中设备聚集可解释为,受购买设备花销考量,欺诈者一般并不会拥有大量的计算机设备,通常会在相同设备群上采用多个账号的方式实施欺诈行为,称为设备聚集;欺诈者往往需要在某个时期内,完成相应的欺诈任务,受时间的限制,会在设备上执行类似或者说重复性的任务,称为行为聚集。
建图是应用图算法的基础,良好的构图依赖对业务的理解。在现实生活中,相同的IP地址段内,可能同时存在着正常的用户与欺诈者,因此要综合考虑设备积聚和行为积聚。展开而言,设备聚集性表现为一个账户注册或登录同一个设备或一组公共设备,若这一个(一组)设备上有大量其他账户登录,那么此类账户是可疑的;行为聚集性具体表现为,如果共享设备的账户行为是批量进行的,那么此类账户是可疑的。实践中图模型包括,构建关系图、图上特征、图算法三个方面,本案例中采用的图算法模型为GraphSAGE模型,构图关系和图上的特征则需要精细的设计。
2.1 图关系
风控中一般将图构建为二部异质图,使用用户的行为数据作为数据源,其中一类节点表示用户(设备),另一类节点则表示为特征节点。如果在同一个时间窗口,多个用户使用了同一个IP,就可以将这个用户和IP关联到一起,构建了一个由用户和节点形成的二部图,边就是二者之间的关系。
2.2 风控场景图特征工程
针对图算法,特征工程和图的构建方式是非常重要的。如果图的结构不合理的话,即使算法模型再强大、特征工程处理得再好,算法训练出的结果也不是最终理想的效果。一些团伙攻击广告主,特征表现为Cookie、IP、utdid(设备唯一标识符)的排列组合,同时,为了绕开基于简单统计的反作弊系统,作弊团伙会让每个设备介质有较少的点击次数。作弊团伙虽然会不断切换IP和账户ID,但是受成本限制,作弊团伙使用过的账户和IP会不可避免的产生一些关联。相较于正常用户,欺诈用户之间具有较强的关联性,可以认为这个簇是一个高可疑作弊团伙。
下图是抽取的其中一个簇的行为示例,同颜色的表示使用同一资源,簇中的用户在不断点击京东的广告页面,并且在短时间内不断切换IP、Cookie、useragent等资源以绕过反作弊系统。
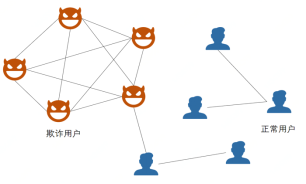
▲ 相较于正常用户,欺诈用户之间具有较强的关联性
GraphSAGE 是图神经网络模型中一个优秀的模型,它是一种归纳框架,可以利用节点特征信息来高效地为未出现过的节点生成节点向量,模型不是为每个节点专门训练节点向量,而是训练得到一个函数,这个函数功能是从节点的局部邻居节点采样并聚合特征信息,这使得GraphSAGE可以适应大规模图动态变化的场景,聚合函数也有平均聚合,LSTM,最大池化等选项进行调优。同时,GraphSAGE可采用小批量的训练方式,通过采样邻居节点以有效减少内存开销以及训练时间。
在流量风控中为检测出作弊设备,需要将网络关系图构建为包括设备统计节点和设备信息节点的二部图。设备统计节点的特征包含:时序特征(一段时间内的点击量分布)、统计特征(点击量、IP个数、操作系统个数)、节点度等相关特征。设备信息节点则包括设备端口、时间区段、用户代理(User Agent)。
GraphSAGE一般适用于同构图中,为了能让该异构网络适用于GraphSAGE,我们采用相同长度N的向量表示两种节点的特征, 前m维表示设备节点特征,后面N-m维表示信息节点特征,即采用一种扩展的特征向量,将异质图信息融合成同构图。
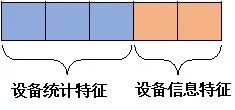
▲ 节点特征向量分段含义
在设备节点上并无信息节点特征,在信息节点占有的向量分量上按零填充,信息节点也做类似处理,进行初始化,以满足向量有意义的加减。下图中两种颜色分别表示设备节点特征数据占位和信息节点目标节点数据。两类节点,即设备节点和特征节点。设备信息作为关系纽带,将具有同一设备信息节点的设备特征节点关联到一起。
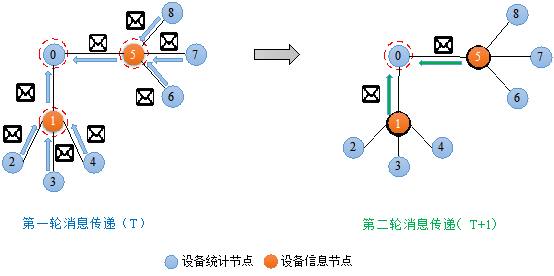
▲ GraphSAGE二阶信息传递过程
假设以计算节点为研究对象,采用两轮的邻域与信息聚合,用 表示聚合函数。第一轮时,计算一阶邻居节点 。以 节点为例子,采用特征更新方式 。同样地 ,。
第二轮,计算节点时候,采用融合后的,节点信息,,综合第一轮迭代可知,此时节点 ,包含设备统计节点 和设备信息节点 ,以及本身的初始特征输入,即经历两轮迭代后,可以融合一阶和二阶邻居的信息。若以平均聚合为例,则迭代过程依然可以概括为:
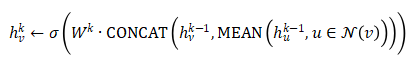
在实际业务中,通过无监督算法如Fraudar等,再由强规则得到的校验的黑白标签数据作为GraphSAGE算法的有监督学习样本部分,进行更大规模的召回。采用图模型后,召回率得到提升,可检出更多作弊设备和账号。
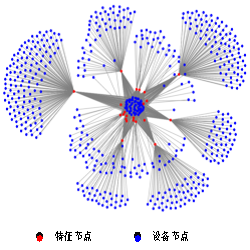
▲ 黑产设备(恶意点击)点击示意图
广告流量作为互联网变现的重要方式,虚假流量作为广告产业的灰色领域,是广告流量风控的重灾区。广告反作弊应运而生,成为广告系统的一部分。在实际应用中,我们采用Fraudar无监督学习方法得到的作弊设备作为GraphSAGE图神经网络的标签样本,然后做深度学习训练,召回更多的作弊设备。

包勇军,朱小坤,颜伟鹏,姚普 著
清华大学出版社 2022-05-01
ISBN: 9787302604884 定价: 89.00 元
新书推荐
🌟今日福利
|关于本书|
图神经网络是人工智能的一个热点方向,从图的视角解读大数据,可以灵活建模复杂的信息交互关系,吸引大量学者的关注并在多个工业领域得到广泛应用。《图深度学习从理论到实践》由浅入深,全面介绍图神经网络的基础知识、典型模型方法和应用实践。《图深度学习从理论到实践》不仅包括一般的深度学习基础和图基础知识,还涵盖了图表示学习、图卷积、图注意力、图序列等典型图网络模型,以京东自研的Galileo平台为代表的图学习框架,以及图神经网络在电商推荐和流量风控方面的两个典型工业应用。《图深度学习从理论到实践》既适合对数据挖掘、机器学习方向以及图建模交叉方向感兴趣的高年级本科生和研究生作为教材使用,也适合互联网电商、金融风控、社交网络分析、药物研发等企业的从业者参考学习。
