作者:熊彪,腾讯云监控高级工程师
前言
腾讯云应用性能观测(APM)是一款应用性能管理产品,基于实时的多语言应用探针全量采集技术,为用户提供分布式应用性能分析和故障自检能力。本文主要讲述了 APM 链路指标计算场景下,性能优化提升若干方案。通过上述方案,将 APM 指标计算的整体性能提升了 2-3 倍效果。
什么是 APM 指标计算?
应用性能观测(APM)上报的原始数据是一个一个的链路 Span,要计算服务的错误率、平均响应时间、Apdex 等指标,需要将原始链路 Span 转换为相关的指标数据,再通过 Flink 流计算按一分钟窗口聚合出相关指标具体值。上述的过程称作 APM 指标计算。
名词解释:自研高性能指标计算中台 —— Barad
应用性能监控 —— APM腾讯云 Flink 计算资源-1核 CPU —— 1CU
海量数据上报面临的挑战
APM 现阶段随着业务接入的增长,上报流量也在不停的创造新的流量洪峰,某个地域最新的峰值流量已达到了数亿/分钟。跟随着上报调用链路数据的增长,指标计算消耗 Flink 资源也在不停的飙升。在不考虑成本情况下, Flink 作业资源若是能够支持不停的横向扩展,事情也有回转的余地,但让人沮丧的是当 Flink 作业的资源达到某 CU 值 的时候,就达到了瓶颈点——导致作业的稳定性会变得极差。那么我们该如何去解决指标计算 Flink 所面临的性能压力的挑战? 并提升系统整体的稳定性?我们该如何去解决指标计算 Flink 所面临的性能压力的挑战? 并提升系统整体的稳定性?接下来,我们将一一剖析问题的根因。
提升稳定性:拆分作业
1. 为什么扩容了还是高负载?
指标计算的 Flink 作业已经在 Barad 基础指标计算业务运行的很平稳,相同的程序迁移到 APM 指标计算为什么就变得这么不稳定,且资源已经扩容了,为什么 CPU 负载还这么高? 先让我们来看一下 Flink 失败日志信息,截图如下所示:
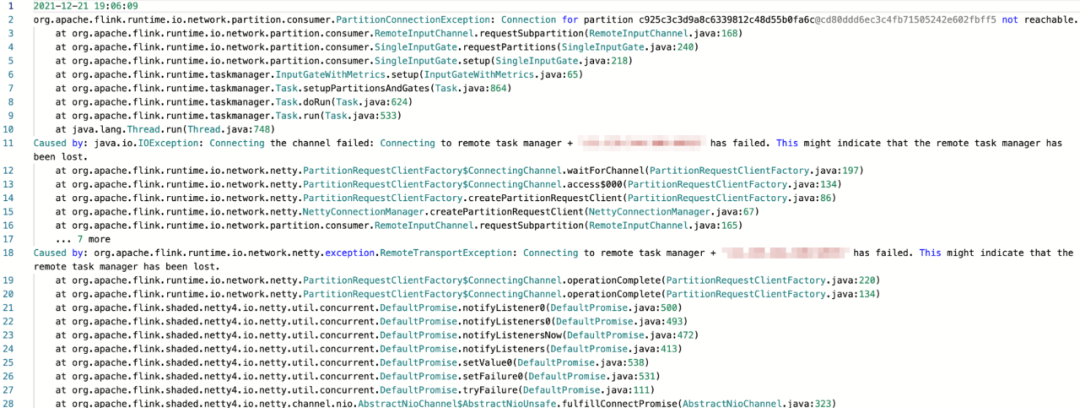
[点击查看大图]从上图我们可以看出,Flink 集群有节点掉了,那是什么原因导致的呢? 经过 APM 团队协力分析,发现失联是因为所在节点 CPU 过高导致网络丢包率(15%-25%)飙升引起的。那又是什么导致的 CPU 过高呢? 故障复盘发现是因为集群节点过多导致大量节点的 CPU 耗费在大量网络传输方面而引起,结果就导致作业稳定性变差,经常性作业重启引发业务指标链路数据丢失,且 Yarn 对大 CU 的作业在启动上会耗费大量的时间。
2. 作业拆分依据为了提升 APM 指标计算 Flink 作业的稳定性,我们采纳了 Oceanus (流计算)技术,先将一个大作业拆分成几个小作业,以此来提升 APM 指标计算作业的稳定性,那么我们以什么维度来拆分我们 APM 指标作业呢?按照 brarad 基础指标计算的经验,我们拆分作业的依据主要有以下几个:
- 业务上报量
- 业务上报数据延迟度
- 业务自身稳定性要求
- 业务上报完整调用琏整体时间窗口的耗时
通过上面四个拆分原则,我们将 APM 指标计算拆分成三个作业,具体如下图所示:
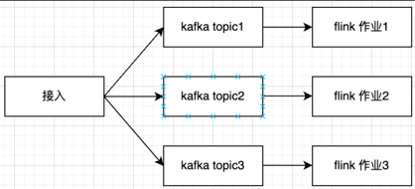
[点击查看大图]在完成对大作业的拆分之后,APM 指标计算的整体稳定性得到了极大的提升, 满足了 APM 业务对指标计算正确性的诉求. 虽然指标计算的稳定性提升了,但是整体资源 CU 的消耗并未降低,那么我们如何去降低 APM 指标计算资源的消耗呢?我们横向对比了 Barad 基础指标计算,发现 APM 指标计算在相同上报量情况下,资源消耗更大。APM 指标计算上报流量为 Barad 某业务基础指标上报流量的四分之一,但 CU 的消耗却是 2倍,为何上报量低的业务,CU 反而更高?APM 与 Barad 基础指标计算的资源消耗差距是哪里导致的?带着这个疑问,我们对比了两个不同业务间数据的不同点,来展开第二、三次的优化工作点。
提高吞吐量:Batch 大法
1. 指标协议
在展开优化前,让我们来熟悉一下云监控指标计算协议的 PB 结构,如图所示:
message MetricList { string appID = 1; string namespace = 2; repeated Metric metrics = 3;}从上图可以看出,我们可以将多个指标的数据,合并放到一个 MetricList 中。为了解相对应的数据结构,我们需要设定两个作业资源消耗相同的两个业务。APM 某实例上报的指标与自研高性能指标计算中台某基础指标计算在指标合并方面的差异:我们设定了作业资源消耗相同的两个 APM 和 Barad 测试业务。上报效果如下:
2. APM 上报合并效果
2.1 APM 某测试实例指标计算,接入层整体上报流量 25M:

[点击查看大图]
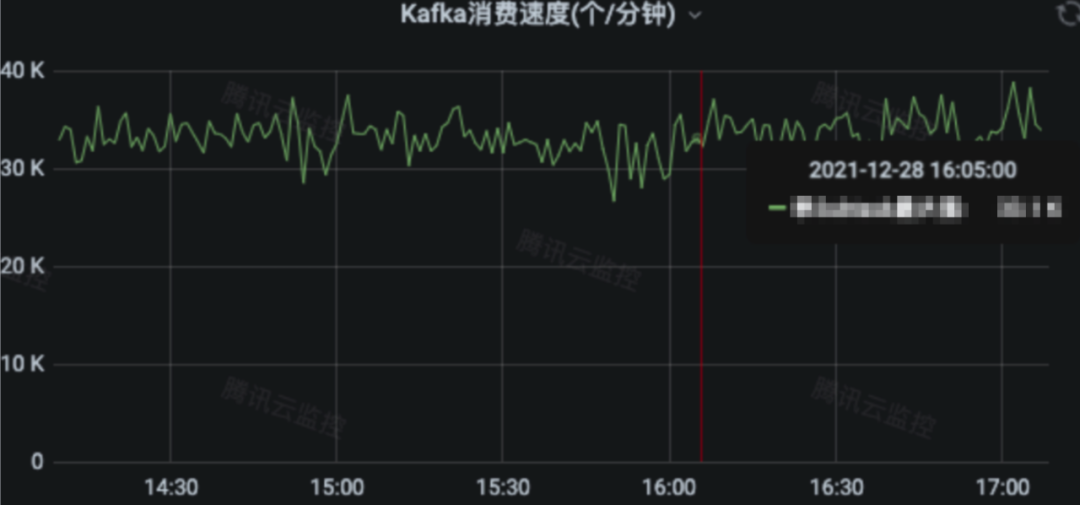
2.2 APM 指标计算 Flink 处理 kafka 消息数/分钟,展示在 1CU 并行下,该业务的处理消息数为 33K 左右:
[点击查看大图]
3. Barad 上报合并效果
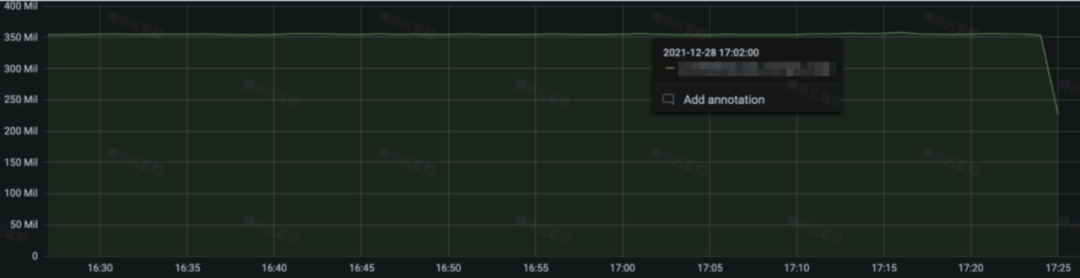
3.1 自研高性能指标计算中台某测试业务,接入层整体上报流量 350M:
[点击查看大图]
3.2 Barad 指标计算处理 kafka 消息数/分钟,展示了 1CU 并行度的处理消息数为约 907K 左右:
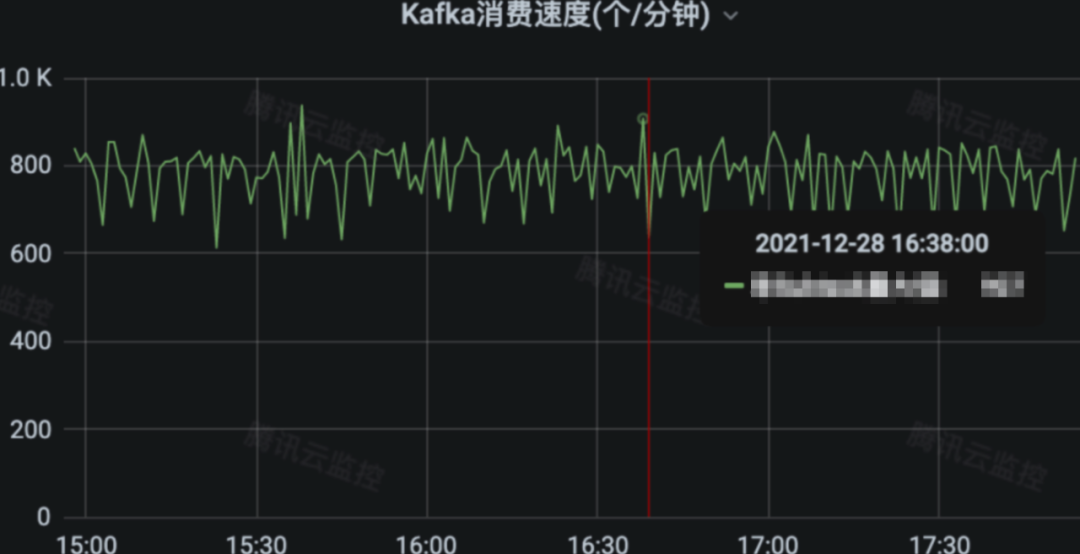
[点击查看大图]从上图两个测试业务数据的对比,可以看出来 APM 指标计算某业务上报处理的消息数是 8750000,跟上报量 25M 的数据转换为 MetricList 的压缩比是1比3。Barad 某基础指标有上报处理的消息数是 230400,跟上报量 350M 的数据转换为 MetricList 的压缩比是 1比1519 。
4. Batch 解决方案
从上述对比的两组数据,大胆地推断出 MetricList 合并压缩比越高,指标计算 Flink可以承载的吞吐量就越高,那么我们如何提高 APM 指标计算 MetricList 合并压缩比呢? 具体方案如下图所示:
APM 指标计算优化前处理方式:
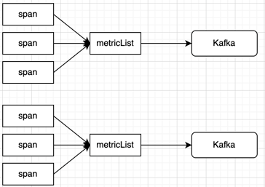
[点击查看大图]
APM 指标计算优化后处理方式:
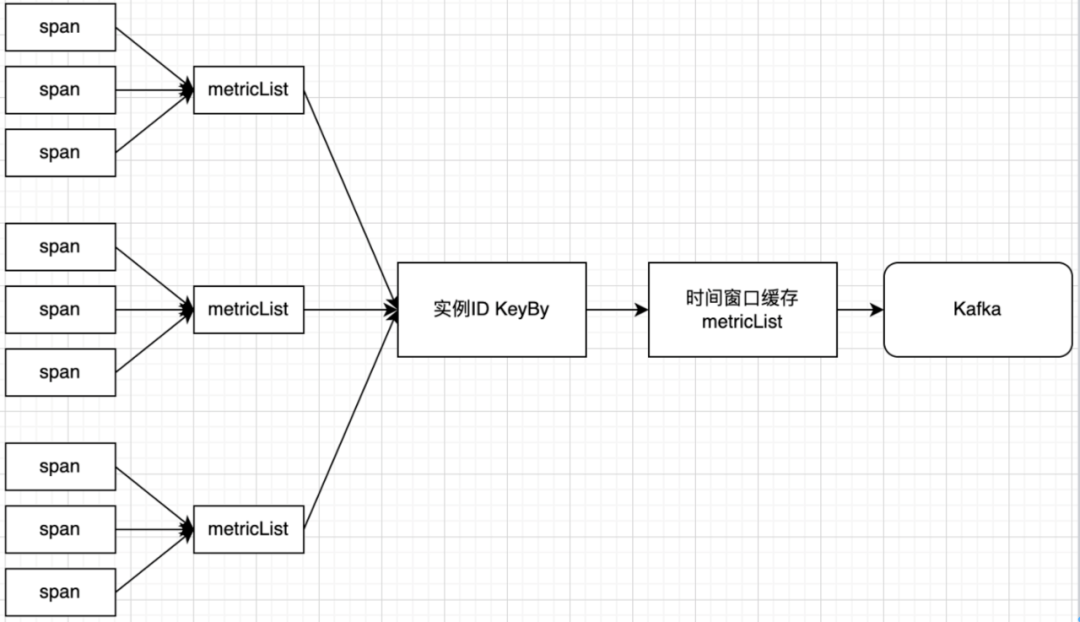
[点击查看大图]
通过上图可以看出,通过增加一个时间窗口的方式,来提高 MetricList 合并压缩比,后续 Metric 做聚合计算所需要的网络传输就越少,故而提高了指标计算 Flink 自身处理的效率,对 Span 转 MetriclList 做一个 Batch 合并的操作,提高 Span 转 MetricLis t合并压缩比,具体优化效果如下图所示:
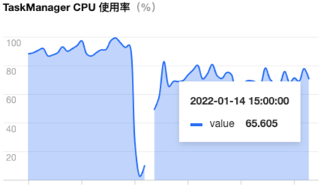
[点击查看大图]
降低内存:维度剪枝大法
APM 现阶段是默认将 Span 中的 Tag 维度字段全量转换为 Metric 维度字段上报给 Flink 指标计算,这么做的好处是后续指标视图需要新增字段,刷新视图规则即可,接入层 Span 转 Metric 维度字段不需要修改。 但是这么做的弊端是无关的字段,耗费了大量的 kafka 与 Flink 的资源。那么精简指标维度字段势在必行,APM 现阶段的视图规则表中,统计总共只需要有 17个维度字段就能够满足,具体如下所示:

[点击查看大图]
那么我们就需要对现在的维度字段进行数据的清洗,规整出指标计算视图需要的维度字段,提升资源的利用率,具体操作如下图所示:
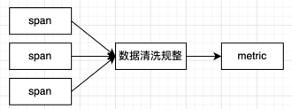
[点击查看大图]
通过对数据清理规整后,达到了降低指标计算 Flink 内存资源消耗,具体效果如下图所示:
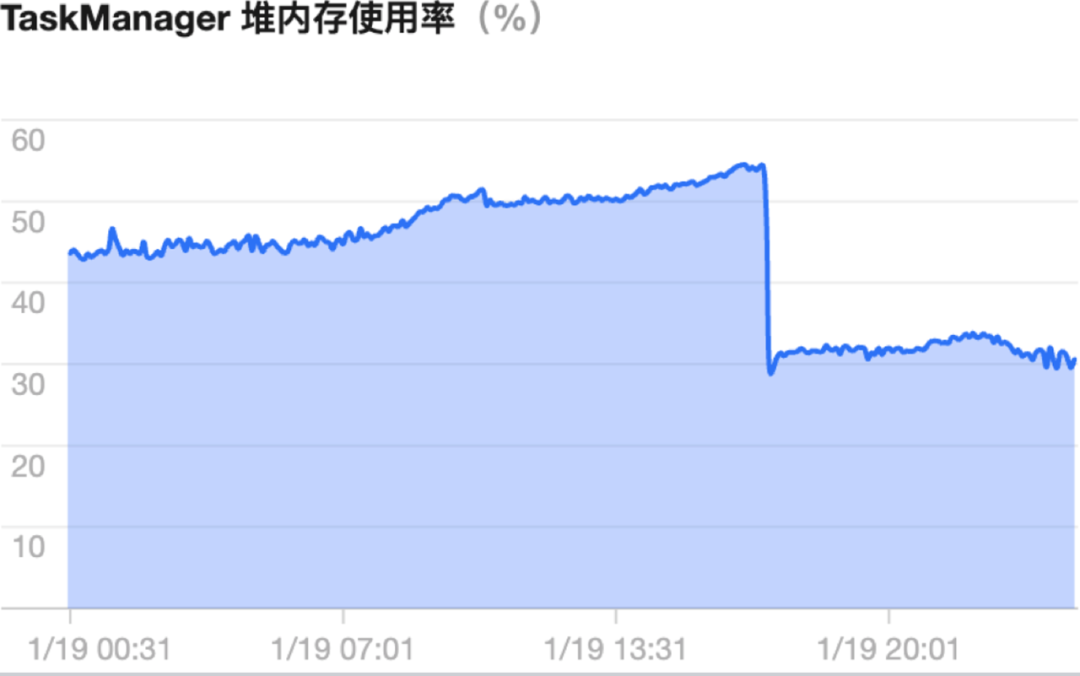
[点击查看大图]
整体优化效果
通过上述两种措施的优化,我们将某业务指标计算 Flink 资源的消耗整体降低至原来的 30% 左右,如表所示:
业务名称 | 优化前资源使用情况 | 优化后资源使用情况 |
|---|---|---|
某业务 | 650 CU | 230 CU |
从上图表格可以看出通过上述几种方式优化,极大地提升了 APM 指标计算的性能,从而达到了降低资源消耗的目的。而对大数据处理优化本质是对细节的优化,单一数据优化的一小步在海量数据下就是一大步。
腾讯云应用性能监控(APM) 在稳定性与性能上做了很多优化,不仅仅深入优化了 APM 指标计算方面,还通过对存储层进行冷热分离,数据写入高并发优化,尾部采样,接入层性能提升等一系列的优化措施,大幅提升了整体数据处理性能,可承载的 QPS远超开源自建的监控系统,极大提升了腾讯云监控在这个领域赛道内的竞争力。
联系我们
如有任何疑问,欢迎加入腾讯云监控技术交流群

精选文章推荐:





关注我们,了解腾讯云监控的最新动态