按照以下步骤指南,使用 BentoML、LangChain 和 MyScaleDB 创建自定义 AI 应用程序。
译自 Develop a Cloud-Hosted RAG App With an Open Source LLM,作者 Usama Jamil。
检索增强生成 (RAG) 通常用于开发定制的 AI 应用程序,包括 聊天机器人、推荐系统 和其他个性化工具。该系统利用向量数据库和 大型语言模型 (LLM) 的优势来提供高质量的结果。
为任何 RAG 模型选择合适的 LLM 非常重要,需要考虑成本、隐私问题和可扩展性等因素。OpenAI 的 GPT-4 和 Google 的 Gemini 等商业 LLM 非常有效,但可能很昂贵并引发数据隐私问题。一些用户更喜欢 开源 LLM,因为它们灵活且节省成本,但它们需要大量资源进行 微调 和部署,包括 GPU 和专用基础设施。此外,使用本地设置管理模型更新和可扩展性可能具有挑战性。
更好的解决方案是选择一个 开源 LLM 并将其部署在 云 上。这种方法提供了必要的计算能力和可扩展性,而无需本地托管的高成本和复杂性。它不仅节省了初始基础设施成本,而且还最大限度地减少了维护问题。
让我们探索一种类似的方法来开发使用云托管开源 LLM 和可扩展向量数据库的应用程序。
工具和技术
开发此基于 RAG 的 AI 应用程序需要使用多种工具。这些工具包括:
- BentoML: BentoML 是一个开源平台,简化了机器学习模型的部署到生产就绪的 API,确保可扩展性和易于管理。
- LangChain: LangChain 是一个用于使用 LLM 构建应用程序的框架。它提供模块化组件,便于集成和定制。
- MyScaleDB: MyScaleDB 是一个高性能、可扩展的数据库,针对高效的数据检索和存储进行了优化,支持高级查询功能。
在本教程中,我们将使用 LangChain 的 WikipediaLoader 模块从维基百科中提取数据,并在该数据上构建 LLM。
准备
设置环境
通过打开终端并输入以下内容,开始设置您的环境以在系统中使用 BentoML、MyScaleDB 和 LangChain:
pip install bentoml langchain clickhouse-connect这将在您的系统中安装所有三个软件包。之后,您就可以编写代码并开发 RAG 应用程序了。
加载数据
首先从 langchain_community.document_loaders.wikipedia 模块导入 WikipediaLoader。您将使用此加载器来获取与 “阿尔伯特·爱因斯坦”相关的维基百科文档。
from langchain_community.document_loaders.wikipedia import WikipediaLoader loader = WikipediaLoader(query="Albert Einstein")Load the documents
docs = loader.load()
Display the content of the first document
print(docs[0].page_content)
这使用 load 方法检索“阿尔伯特·爱因斯坦”文档,并使用 print 方法打印第一个文档的内容以验证加载的数据。
将文本拆分为块
导入来自 CharacterTextSplitter langchain_text_splitters,将所有页面的内容合并到一个字符串中,然后将文本拆分为可管理的块。
from langchain_text_splitters import CharacterTextSplitterSplit the text into chunks
text = ' '.join([page.page_content.replace('\t', ' ') for page in docs])
text_splitter = CharacterTextSplitter(
separator="\n",
chunk_size=400,
chunk_overlap=100,
length_function=len,
is_separator_regex=False,
)
texts = text_splitter.create_documents([text])
splits = [item.page_content for item in texts]
CharacterTextSplitter 配置为将此文本拆分为 400 个字符的块,重叠 100 个字符,以确保块之间不会丢失任何信息。page_content 或文本存储在 splits 数组中,该数组仅包含文本内容。您将使用 splits 数组来获取 嵌入。
在 BentoML 上部署模型
... 您的数据已准备就绪,下一步是在 BentoML 上部署模型并在您的 RAG 应用程序中使用它们。首先部署 LLM。您需要一个免费的 BentoML 帐户,如果您需要,可以 在 BentoCloud 上注册一个。接下来,导航到 部署 部分,然后单击右上角的 创建部署 按钮。将打开一个新页面,如下所示:
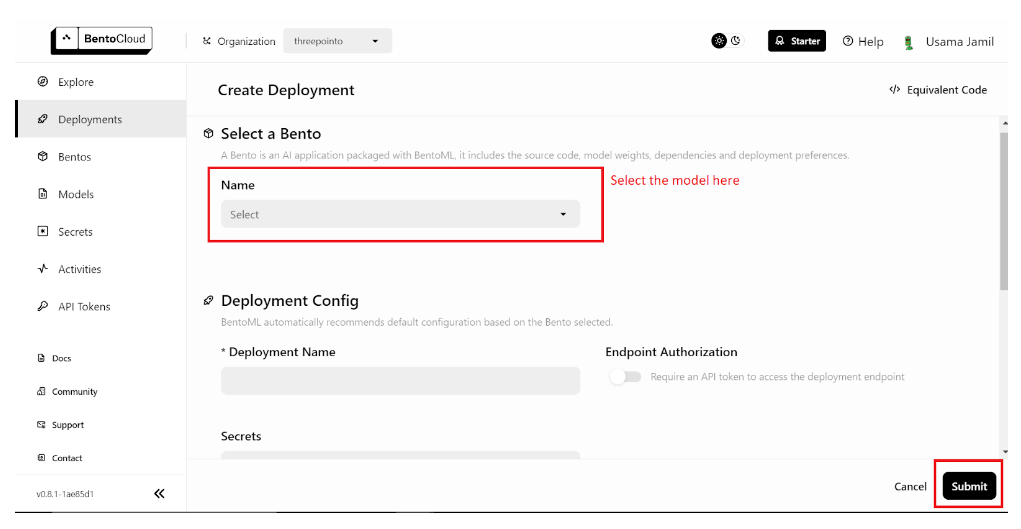
BentoML 部署页面
从下拉菜单中选择 bentoml/bentovllm-llama3-8b-instruct-service 模型,然后单击右下角的“提交”。这将开始部署模型。将打开一个新的页面,如下所示:
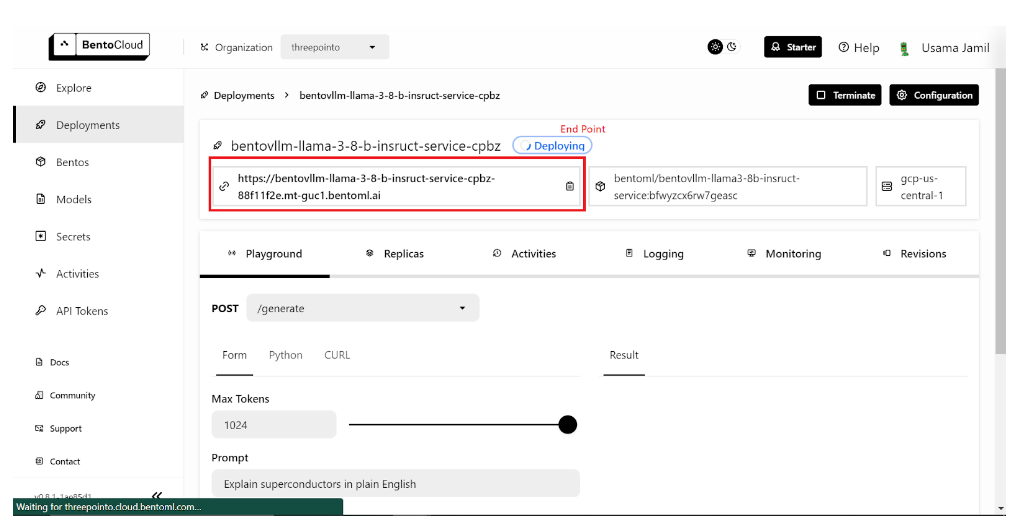
LLM 配置页面
部署可能需要一些时间。部署完成后,复制端点。
注意:BentoML 的免费层级只允许部署单个模型。如果您有付费计划并且可以部署多个模型,请按照以下步骤操作。如果没有,不用担心 - 我们将在本地使用开源模型进行嵌入。
部署嵌入模型与您部署 LLM 所采取的步骤非常相似:
- 转到 部署 页面。
- 点击 创建部署 按钮。
- 选择
sentence-transformers模型,然后单击 提交。 - 部署完成后,复制端点。
接下来,转到 API 令牌页面 并生成一个新的 API 密钥。现在您已准备好将部署的模型用于您的 RAG 应用程序。
定义嵌入方法
您将定义一个名为 get_embeddings 的函数来为提供的文本生成嵌入。此函数接受三个参数。如果提供了 BentoML 端点和 API 令牌,则该函数使用 BentoML 的嵌入服务;否则,它使用本地 transformers 和 torch 库来加载 sentence-transformers/all-MiniLM-L6-v2 模型并生成嵌入。
# Import the libraries
import subprocess
import sys
import numpy as npInstall the packages if the API key isn't provided
def install(package):
subprocess.check_call([sys.executable, "-m", "pip", "install", package])Define the embedding method
def get_embeddings(texts: list, BENTO_EMBEDDING_MODEL_END_POINT=None, BENTO_API_TOKEN=None) -> list:
If the BentoML KEY is provided, the method will use BENTOML model to get embeddings
if BENTO_EMBEDDING_MODEL_END_POINT and BENTO_API_TOKEN:
import bentoml
embedding_client = bentoml.SyncHTTPClient(BENTO_EMBEDDING_MODEL_END_POINT, token=BENTO_API_TOKEN)
return embedding_client.encode(sentences=texts).tolist()Otherwise it'll use transformers library
else:
# Install transformers and torch if not already installed
try:
import transformers
except ImportError:
install("transformers")
try:
import torch
except ImportError:
install("torch")from transformers import AutoTokenizer, AutoModel # Initialize the tokenizer and model for embeddings tokenizer = AutoTokenizer.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") model = AutoModel.from_pretrained("sentence-transformers/all-MiniLM-L6-v2") inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt", max_length=512) with torch.no_grad(): outputs = model(**inputs) embeddings = outputs.last_hidden_state.mean(dim=1) return embeddings.numpy().tolist()</code></pre></div></div><p>此设置允许免费层级 BentoML 用户灵活使用,他们一次只能部署一个模型。如果您有付费版本的 BentoML 并且可以部署两个模型,则可以传递 BentoML 端点和 Bento API 令牌以使用部署的嵌入模型。</p><h4 id="3lrn3" name="%E8%8E%B7%E5%8F%96%E5%B5%8C%E5%85%A5">获取嵌入</h4><p>以 <code>25</code> 的批次迭代文本块 (<code>splits</code>) 以使用上面定义的 <code>get_embeddings</code> 函数生成嵌入。</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>javascript</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-javascript"><code class="language-javascript" style="margin-left:0">all_embeddings = []Pass the splits in a batch of 25
for i in range(0, len(splits), 25):
batch = splits[i:i+25]Pass the batch to the get_embeddings method
embeddings_batch = get_embeddings(batch)
Append the embeddings to the all_embeddings list holdng the embeddings of the whole dataset
all_embeddings.extend(embeddings_batch)
这可以防止一次将过多的数据加载到嵌入模型中,这对于管理内存和计算资源特别有用。
创建数据帧
现在,创建一个 pandas 数据帧来存储文本块及其相应的嵌入。
import pandas as pd
df = pd.DataFrame({
'page_content': splits,
'embeddings': all_embeddings
})这种结构化格式使在 MyScaleDB 中操作和存储数据变得更加容易。
连接到 MyScaleDB
知识库已完成,现在是将数据保存到向量数据库的时候了。此演示使用 MyScaleDB 进行向量存储。通过遵循 快速入门指南 在云环境中启动 MyScaleDB 集群。然后,您可以使用 clickhouse_connect 库建立与 MyScaleDB 数据库的连接。 此处创建的客户端对象将用于执行 SQL 命令并与数据库交互。
import clickhouse_connect
client = clickhouse_connect.get_client(
host='your-host-name',
port=443,
username='your-user-name',
password='your-password'
)创建表并插入数据
在 MyScaleDB 中创建一个表来存储文本块和嵌入。表模式包括一个 id、page_content 和 embeddings。
# Create the table named RAG
client.command("""
CREATE TABLE IF NOT EXISTS default.RAG (
id Int64,
page_content String,
embeddings Array(Float32),
CONSTRAINT check_data_length CHECK length(embeddings) = 384
) ENGINE = MergeTree()
ORDER BY id
""")Insert data into the table
batch_size = 100
num_batches = (len(df) + batch_size - 1) // batch_size
for i in range(num_batches):
batch_data = df[i * batch_size: (i + 1) * batch_size]
client.insert('default.RAG', batch_data.values.tolist(), column_names=batch_data.columns.tolist())
print(f"Batch {i+1}/{num_batches} inserted.")
这确保嵌入具有 384 的固定长度。然后将数据帧中的数据以批次插入表中,以有效地管理大量数据。
创建向量索引
下一步是在 RAG 表中的 embeddings 列中添加向量索引。
client.command("""
ALTER TABLE default.RAG
ADD VECTOR INDEX vector_index embeddings
TYPE MSTG
""")向量索引允许进行有效的相似性搜索,这对于检索增强生成任务至关重要。
检索相关向量
定义一个函数,根据用户查询检索相关文档。查询嵌入是使用 get_embeddings 函数生成的,并且执行高级 SQL 向量查询以在数据库中找到最接近的匹配项。
def get_relevant_docs(user_query, top_k):
query_embeddings = get_embeddings(user_query)[0]
results = client.query(f"""
SELECT page_content,
distance(embeddings, {query_embeddings}) as dist FROM default.RAG ORDER BY dist LIMIT {top_k}
""")
relevant_docs = " "for row in results.named_results():
relevant_docs=relevant_docs + row["page_content"]return relevant_docs
Example query
message="Who is albert einstein?"
relevant_docs = get_relevant_docs(message, 8)
print(relevant_docs)
结果按距离排序,并返回前 k 个匹配项。此设置找到了给定查询的最相关文档。
注意:distance 方法接受一个嵌入列和用户查询的嵌入向量,通过应用余弦相似度来查找相似的文档。
连接到 BentoML LLM
建立与您在 BentoML 上托管的 LLM 的连接。llm_client 对象将用于与 LLM 交互,以根据检索到的文档生成响应。
import bentoml
BENTO_LLM_END_POINT = "add-your-end-point-here"
llm_client = bentoml.SyncHTTPClient(BENTO_LLM_END_POINT, token="your-token-here")
替换 BENTO_LLM_END_POINT 以及 token 使用您之前在 LLM 部署期间复制的值。
执行 RAG
定义一个执行 RAG 的函数。该函数以用户问题和检索到的上下文作为输入。它为 LLM 构建一个提示,指示它根据提供的上下文回答问题。然后将 LLM 的响应作为答案返回。
def dorag(question: str, context: str):Define the prompt template
prompt = (f"You are a helpful assistant. The user has a question. Answer the user question based only on the context: {context}. \n"
f"The user question is {question}")Call the LLM endpoint with the prompt defined above
results = llm_client.generate(
max_tokens=1024,
prompt=prompt,
)
res = ""
for result in results:
res += result
return res
进行查询
最后,您可以通过对 RAG 应用程序进行查询来测试它。询问“谁是阿尔伯特·爱因斯坦?”并使用 dorag 函数根据之前检索到的相关文档获取答案。
query = "Who is albert einstein?"
dorag(question=query, context=relevant_docs)输出提供了对问题的详细响应,证明了 RAG 设置的有效性。

LLM 响应
如果您询问 RAG 模型关于阿尔伯特·爱因斯坦的死亡,响应应该如下所示:

LLM 响应
结论
BentoML 作为部署机器学习模型(包括 LLM)的出色平台而脱颖而出,无需费心管理资源。使用 BentoML,您可以快速部署和扩展您的 AI 应用程序到云端,确保它们已准备好投入生产并高度可访问。它的简单性和灵活性使其成为开发人员的理想选择,使他们能够更多地专注于创新,而无需过多关注部署复杂性。
另一方面,MyScaleDB 是专门为 RAG 应用程序开发的,提供高性能 SQL 向量数据库。它熟悉的 SQL 语法使开发人员可以轻松地将其集成到他们的应用程序中并使用它,因为学习曲线很小。MyScaleDB 的 多尺度树图 (MSTG) 算法在速度和准确性方面明显优于其他向量数据库。此外,MyScaleDB 为每个新用户提供高达 500 万个向量的免费存储空间,使其成为希望实施高效且可扩展的 AI 解决方案的开发人员的理想选择。
您对此项目有何看法?在 Twitter 和 Discord 上分享您的想法。