众所周知,系统调用很昂贵。而针对CPU漏洞的软件缓解措施(如Meltdown)甚至使其更加昂贵。但它们到底有多贵呢?为了开始回答这个问题,我写了一个小型的微型测试,以测量系统调用的最低成本。意思是说,无论上下文切换是否发生,人们都必须支付系统调用的成本,即使在内核中的工作微不足道,即从用户模式切换到内核模式再返回的成本。
方法
用户内核模式切换微型基准测试使用谷歌的基准库进行测量,在git仓库中可用。存储库还包含一些辅助脚本,例如,用于将其分发到一堆主机上并执行的游戏手册。基准库重复每个案例,直到结果被认为是稳定的,而使用手册则允许重复执行测试案例。在下面的章节中,报告了100次重复的中值(实时时间为纳秒)。
在基准测试中,调用了一堆系统调用,这些系统调用被认为是非常便宜的,如获取用户ID(UID)、程序ID(PID)、关闭无效的文件描述符、调用不存在的系统调用等。因此,一个测量确实应该只包括两个模式开关。作为控制,少数情况下不进行系统调用,而是做其他便宜的事情。
我在一组异构的主机上运行了这个基准测试,也就是说,不同的内核、操作系统和配置。
更多的细节,也可以参见如下主机部分。
结果和讨论
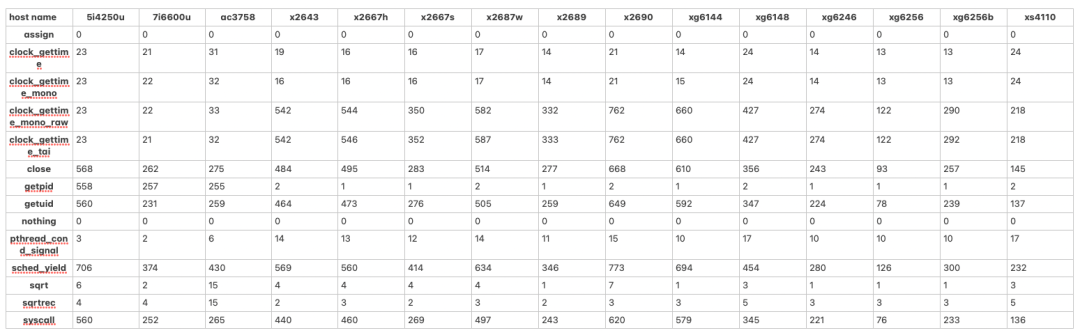
下表显示了不同情况下的实时时间(ns)。
变量控制
用作控制的情况是 "nothing",它实际上什么都不做,assign 只是赋值给一个变量,sqrt计算一个小常数的平方根,sqrtrec则堆叠了一堆sqrt调用。这些结果都是可信的,也就是说,什么都不做的情况下,真正的测量结果是10**-7 ns左右,赋值花费0.5 ns左右,计算平方根只需要几ns。也许最显著的结果是,在Atom CPU(ac3758)上计算平方根在这两种情况下是相当稳定的,而在其他主机上其运行时间取决于其参数。
控制
用作控制的情况是 "nothing",它实际上什么都不做,"assign "只是赋值给一个变量,sqrt计算一个小常数的平方根,sqrtrec则堆叠了一堆sqrt调用。这些结果都是可信的,也就是说,什么都不做的情况下,真正的测量结果是10**-7 ns左右,赋值花费0.5 ns左右,计算平方根只需要几ns。也许最显著的结果是,在Atom CPU(ac3758)上计算平方根在这两种情况下是相当稳定的,而在其他主机上其运行时间取决于其参数。
获取时钟时间
看一下系统调用,一个在所有主机上都成立的关系是,clock_gettime(CLOCK_REALTIME)系统调用比getuid()或close()快很多。这可以解释为,在Linux上,clock_gettime(CLOCK_REALTIME)和其他一些系统调用是通过高效的vDSO机制实现的。这意味着当它们被调用时,不会发生模式切换。
clock_gettime()支持不同的时钟,而且并不是所有的时钟在所有的内核上都被vDSO优化。表中显示,在RHEL 7上查询CLOCK_MONOTIC_RAW和CLOCK_TAI会调用一个真正的系统调用,而在Fedora 33内核(5.12/5.13)上,这些时钟读数也被实现为vDSO。
假信号
同样的,在没有监听的情况下发出信号,假的pthread_cond_signal()场景, 比真正的系统调用要便宜得多--因为C库不需要调用真正的系统调用,而只是调用一些相对便宜的原子操作。
Getpid
getpid()系统调用在RHEL 7上的速度令人惊讶。事实证明,RHEL 7提供了一个旧的glibc版本,它缓存了一个进程的ID!这可以说是一个奇怪的现象。这可以说是一个奇怪的优化,因为,这有什么意义呢?我的意思是,在一个程序中,你有多少次需要调用getpid()?在某些时候(大约在Fedora 26),这个功能被删除了,因为它显然造成了更多的麻烦,而不是它的价值。
真实的系统调用
所以看一下真实的系统调用,在所有的主机上,用户-内核模式切换的成本在几百纳秒左右。一些主机上的成本较高,可以解释为启用了CPU错误缓解措施(默认情况下是启用的)和/或某种较旧/较低端的硬件。一些细节也请参见主机部分。
最快的主机是xg6256,它能在不到100纳秒的时间内切换模式。它有一个快速的CPU,具有良好的单核性能(Xeon Gold 6256),禁用了频率缩放功能,并以高于其基本频率的恒定4.1GHz频率运行。
Sched Yield
sched_yield()系统调用可以被认为是一个最小的工作系统调用,例如,当没有什么需要让出的时候(yield 即 “谦让”,也是 Thread 类的方法。它让掉当前线程 CPU 的时间片,使正在运行中的线程重新变成就绪状态,并重新竞争 CPU 的调度权。它可能会获取到,也有可能被其他线程获取到。)。
另外,基准进程是在标准调度策略下运行的,在Linux上sched_yield()被描述为:sched_yield()旨在与实时调度策略(即SCHED_FIFO或SCHED_RR)一起使用。在非确定性调度策略(如SCHED_OTHER)下使用sched_yield()是不明确的,很可能意味着你的应用设计被破坏。
因此,未指定可能意味着在进程的调度策略与SCHED_OTHER比较靠后,系统调用就会跳出。
在大多数主机上,SCHED_Yield比一个真正最小的系统调用(如getuid())要贵150 ns左右--这表明有更多的开销,但不一定是上下文切换。
Nanosleep
Nanosleep()系统调用耗时比较。

调用nanosleep()来睡眠0 ns或1 ns似乎也是一个非常便宜的系统调用,甚至是一个空操作。
然而,在第一种情况下,所有主机都需要50微秒。顺便说一下,50微秒也是Linux上正常调度进程的默认定时器松弛值。定时器松弛机制将定时器的到期时间延长到松弛值,以便对多个定时器进行分组,因为这样可以减少唤醒,从而节省能量。由于nanosleep()创建了一个定时器,它也会受到这个机制的影响。
因此,其他的nanosleep案例设置了一个最小的定时器松弛值为1ns,这就减少了运行时间,正如预期的那样。然而,它仍然比其他的系统调用要昂贵得多。当然,定时器过期的精度是有限的。然而,在0 ns或1 ns的情况下,真的没有必要让定时器过期。事实证明,无条件地调用nanosleep()会产生一个(自愿的)上下文切换。即使是在孤立的内核上,调度器也会愉快地切换到交换器的内核线程。因此,最后两个nanonsleep案例真正衡量的是上下文切换的成本,它比简单的模式切换更昂贵。
上下文切换的成本与其他人所测量的一致(除以2的模数)。
Hosts
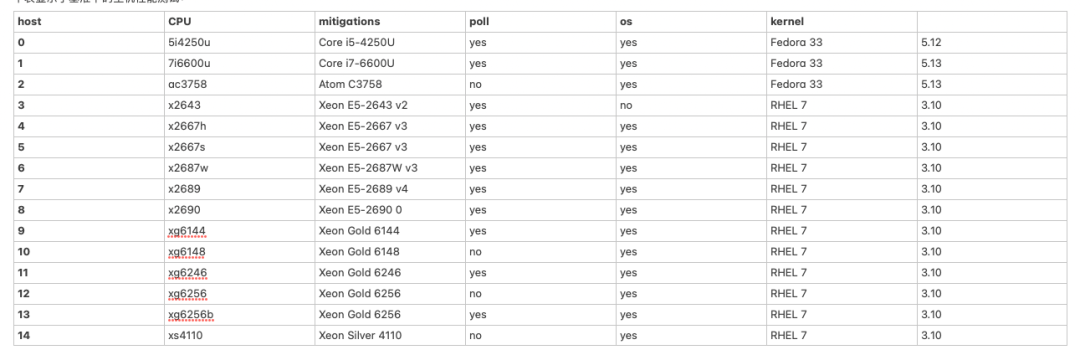
下表显示了基准下的主机性能测试:
注意事项:
- 内核是由发行版打包的。
- 大多数RHEL主机都在RHEL 7.9上。
- 通过 mitigations=off 内核参数或类似参数禁用CPU缓解措施。
- 轮询意味着CPU频率调整和省电是通过内核参数和调整PM QoS设置来禁用的
- 所以主机的CPU运行在一个固定的频率上;在可能的情况下,这个频率被设置为略高于基础频率,例如在Xeon Gold 6256 CPU上,它被设置为4.1 GHz
- Atom CPU不支持超线程,所有Xeon主机上的超线程都被禁用。
- 所有主机都启用了SELinux和/或Auditing(在Fedora/RHEL上,这些功能默认是启用的),这在一定程度上增加了一些系统调用的开销。
术语
在上述讨论中,基本上有两个重要的独立术语需要区分。
- 模式切换(或模式转换)
- 上下文切换
这些术语的定义在不同的文献和不同的操作系统中可能有所不同。另外,在其他情况下(没有双关语的意思!),人们可能会把不同的模式描述为不同的语境。然而,维基百科的链接文章中给出的定义被广泛使用并适用于Linux。
基本上,模式转换表示在用户模式和内核模式之间(或者在用户空间和内核空间之间)的切换,而上下文切换表示在不同任务之间的切换,这是由内核推动的。上下文转换比模式转换需要更多的工作,因此也更昂贵。
参考
- https://gms.tf/on-the-costs-of-syscalls.html
- https://en.wikipedia.org/wiki/System_call
- https://en.wikipedia.org/wiki/Transient_execution_CPU_vulnerability
- https://manpath.be/f34/2/getpid#L43
- https://github.com/gsauthof/osjitter/blob/f1a4ca9cbf7516efc61c3bab2fe06ffe83cfb43c/bench_syscalls.cc#L117
- https://en.wikipedia.org/wiki/Context_switch#User_and_kernel_mode_switching
- https://en.wikipedia.org/wiki/Context_switch