1 解决方案描述
1.1 概述
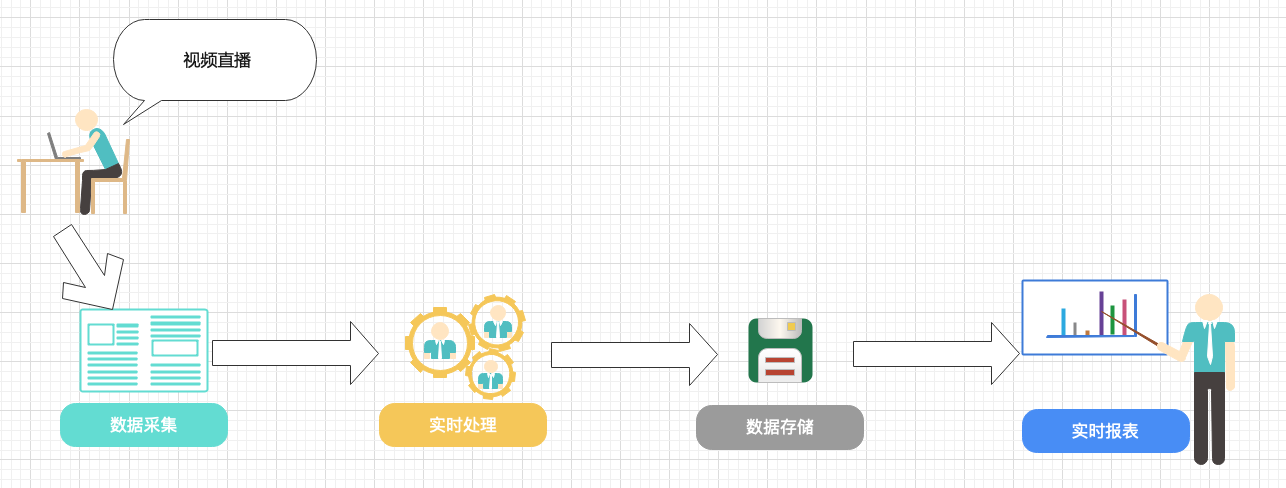
本方案结合腾讯云 CKafka、流计算 Oceanus、私有网络 VPC、商业智能分析BI等,对视频直播行业数字化运营进行实时可视化分析。分析指标包含观看直播人员的地区分布、各级别会员统计、各模块打赏礼物情况、在线人数等。
1.2 方案架构及优势
根据以上视频直播场景,设计了如下架构图:
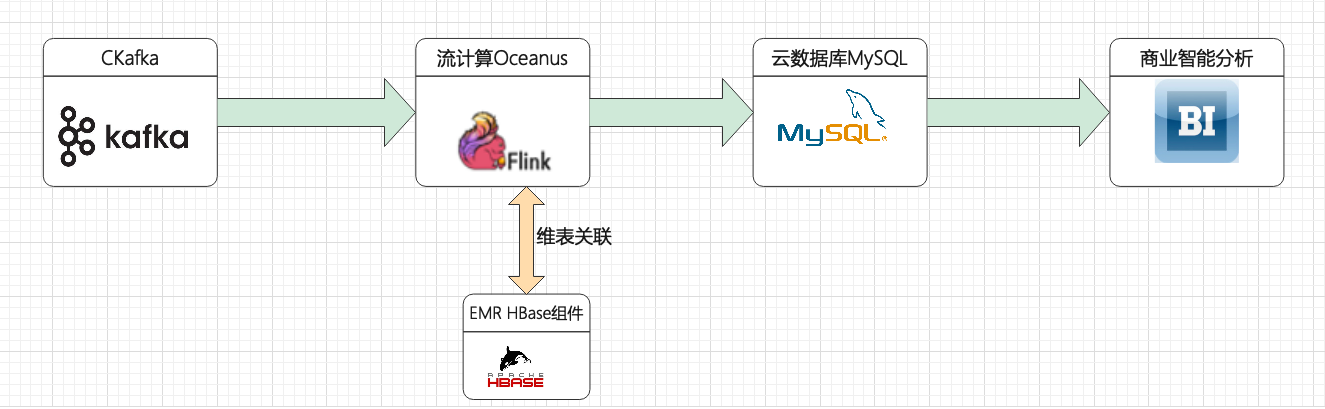
涉及产品列表:
- 流计算 Oceanus
- 私有网络 VPC
- 消息队列 CKafka
- 云数据库 MySQL
- EMR 集群 HBase 组件
- 商业智能分析服务
2 前置准备
购买并创建相应的大数据组件。
2.1 创建VPC私有网络
私有网络是一块您在腾讯云上自定义的逻辑隔离网络空间,在构建MySQL、EMR,ClickHouse集群等服务时选择的网络必须保持一致,网络才能互通。否则需要使用对等连接、VPN等方式打通网络。页面地址:https://console.cloud.tencent.com/vpc/vpc?rid=8
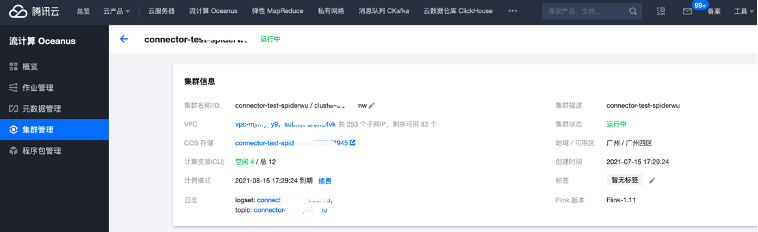
2.2 创建 Oceanus 集群
流计算 Oceanus 服务兼容原生的Flink任务。在 Oceanus 控制台的【集群管理】->【新建集群】页面创建集群,选择地域、可用区、VPC、日志、存储,设置初始密码等。VPC及子网使用刚刚创建好的网络。创建完后Flink的集群如下:
2.3 创建消息队列Ckafka
消息队列 CKafka(Cloud Kafka)是基于开源 Apache Kafka 消息队列引擎,提供高吞吐性能、高可扩展性的消息队列服务。消息队列 CKafka 完美兼容 Apache kafka 0.9、0.10、1.1、2.4、2.8版本接口,在性能、扩展性、业务安全保障、运维等方面具有超强优势,让您在享受低成本、超强功能的同时,免除繁琐运维工作。页面地址:https://cloud.tencent.com/product/ckafka
2.2.1创建Ckafka集群
注意私有网络和子网选择之前创建的网络和子网
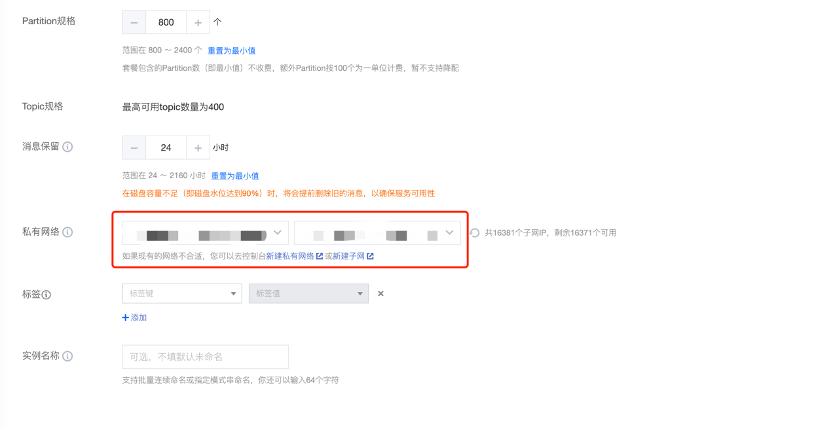
2.2.2创建topic

2.2.3 模拟发送数据到topic
1)kafka客户端
进入同子网的CVM下,启动kafka客户端,模拟发送数据,具体操作文档参考官网:
https://cloud.tencent.com/document/product/597/56840
2)使用脚本发送
脚本一:Java参考地址:https://cloud.tencent.com/document/product/597/54834
脚本二:Python脚本生成模拟数据:
#!/usr/bin/python3 # 首次使用该脚本,需 "pip3 install kafka" 安装kafka模块 import json import random import time from kafka import KafkaProducerTIME_FORMAT = "%Y-%m-%d %H:%M:%S"
PROVINCES = ["北京", "广东", "山东", "江苏", "河南", "上海", "河北", "浙江", "香港",
"陕西", "湖南", "重庆", "福建", "天津", "云南", "四川", "广西", "安徽",
"海南", "江西", "湖北", "山西", "辽宁", "台湾", "黑龙江", "内蒙古",
"澳门", "贵州", "甘肃", "青海", "新疆", "西藏", "吉林", "宁夏"]broker_lists = ['172.28.28.13:9092']
topic_live_gift_total = 'live_gift_total'
topic_live_streaming_log = 'live_streaming_log'producer = KafkaProducer(bootstrap_servers=broker_lists,
value_serializer=lambda m: json.dumps(m).encode('ascii'))模拟几天前,几小时前的数据
pre_day_count = 0
pre_hour_count = 0
hour_unit = 3600
day_unit = 3600 * 24def generate_data_live_gift_total():
# construct time
update_time = time.time() - day_unit * pre_day_count
update_time_str = time.strftime(TIME_FORMAT, time.localtime(update_time))
create_time = update_time - hour_unit * pre_hour_count
create_time_str = time.strftime(TIME_FORMAT, time.localtime(create_time))
results = []for _ in range(0, 10): user_id = random.randint(2000, 4000) random_gift_type = random.randint(1, 10) random_gift_total = random.randint(1, 100) msg_kv = {"user_id": user_id, "gift_type": random_gift_type, "gift_total_amount": random_gift_total, "create_time": create_time_str, "update_time": update_time_str} results.append(msg_kv) return resultsdef generate_live_streaming_log():
# construct time
update_time = time.time() - day_unit * pre_day_count
leave_time_str = time.strftime(TIME_FORMAT, time.localtime(update_time))
create_time = update_time - hour_unit * pre_hour_count
create_time_str = time.strftime(TIME_FORMAT, time.localtime(create_time))
results = []for _ in range(0, 10): user_id = random.randint(2000, 4000) random_province = random.randint(0, len(PROVINCES) - 1) province_name = PROVINCES[random_province] grade = random.randint(1, 5) msg_kv = {"user_id": user_id, "ip": "123.0.0." + str(user_id % 255), "room_id": 20210813, "arrive_time": create_time_str, "create_time": create_time_str, "leave_time": leave_time_str, "region": 1122, "grade": (user_id % 5 + 1), "province": province_name} results.append(msg_kv) return resultsdef send_data(topic, msgs):
count = 0# produce asynchronously for msg in msgs: import time time.sleep(1) count += 1 producer.send(topic, msg) print(" send %d data...\n %s" % (count, msg)) producer.flush()if name == 'main':
count = 1
while True:
time.sleep(60)
#for _ in range(count):
msg_live_stream_logs = generate_live_streaming_log()
send_data(topic_live_streaming_log, msg_live_stream_logs)msg_topic_live_gift_totals = generate_data_live_gift_total() send_data(topic_live_gift_total, msg_topic_live_gift_totals)</code></pre></div></div><h3 id="f5mdc" name="2.4%09%E5%88%9B%E5%BB%BAEMR%E9%9B%86%E7%BE%A4">2.4 创建EMR集群</h3><p>EMR 是云端托管的弹性开源泛 Hadoop 服务,支持 Spark、HBase、Presto、Flink、Druid 等大数据框架,本次示例主要需要使用 Hbase 组件。页面地址https://console.cloud.tencent.com/emr</p><p>1)在EMR集群中安装HBase组件。</p><p></p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723306415896360951.png" /></div><div class="figure-desc">HBase组件</div></div></div></figure><p>2)如果生产环境,服务器配置可根据实际情况选择,示例中选择了低配服务器,网络需要选择之前创建好的VPC网络,始终保持服务组件在同一VPC下。</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723306416018888425.png" /></div><div class="figure-desc">网络选择</div></div></div></figure><p>3)进入HBase Master节点</p><figure class=""><div class="rno-markdown-img-url" style="text-align:center"><div class="rno-markdown-img-url-inner" style="width:100%"><div style="width:100%"><img src="https://cdn.static.attains.cn/app/developer-bbs/upload/1723306416243097968.png" /></div><div class="figure-desc">HBaseMaster节点</div></div></div></figure><p>4)点击登录进入服务器</p><p>5)创建 Hbase 表</p><div class="rno-markdown-code"><div class="rno-markdown-code-toolbar"><div class="rno-markdown-code-toolbar-info"><div class="rno-markdown-code-toolbar-item is-type"><span class="is-m-hidden">代码语言:</span>txt</div></div><div class="rno-markdown-code-toolbar-opt"><div class="rno-markdown-code-toolbar-copy"><i class="icon-copy"></i><span class="is-m-hidden">复制</span></div></div></div><div class="developer-code-block"><pre class="prism-token token line-numbers language-txt"><code class="language-txt" style="margin-left:0"># 进入HBase命令[root@172~]# hbase shell
建表语句
create ‘dim_hbase’, ‘cf’
2.5 创建云数据库 MySQL
云数据库 MySQL(TencentDB for MySQL)是腾讯云基于开源数据库 MySQL 专业打造的高性能分布式数据存储服务,让用户能够在云中更轻松地设置、操作和扩展关系数据库。页面地址:https://console.cloud.tencent.com/cdb
新建MySQL服务的页面需要注意选择的网络是之前创建好的。

创建完MySQL服务后,需要修改binlog参数,如图修改为FULL(默认值为MINIMAL)
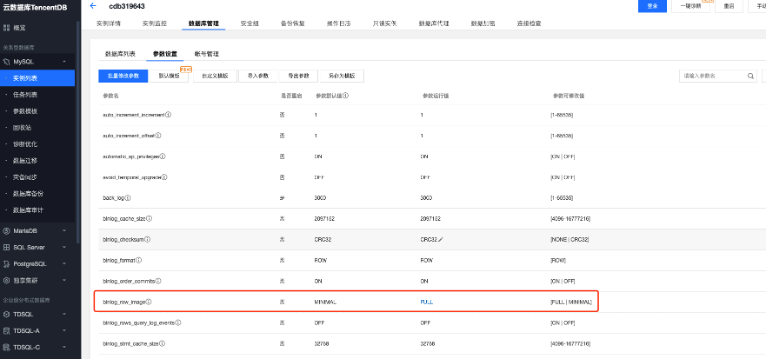
修改完参数后,登陆MySQL创建示例所需要的数据库和数据库表。
1) 登陆MySQL云数据库
2) 新建数据库
打开SQL窗口或可视化页面创建数据库和表
CREATE DATABASE livedb; --创建数据库列表2.6 创建商业智能分析
商业智能分析 BI(Business Intelligence,BI)提供从数据接入到模型分析、数据可视化呈现全流程 BI 能力,有效整合企业多业务数据源,帮助经营者快速获取决策数据依据。系统采用敏捷自助式设计,使用者仅需通过简单拖拽即可完成复杂的报表输出过程,通过和企业微信、公众号的打通,快速实现报表的分享、推送、评论互动等协作场景。
2.6.1购买商业智能分析
1) 登录 商业智能分析 BI 控制台,使用主账号购买资源,购买时需根据创建的子账号数来进行购买。
2) 子用户提出申请。
3) 主账号审核通过。并给子用户授予添加权限。

具体可参考 商业智能分析 BI 五分钟入门
2.6.2添加MySQL数据源
(这里选用开启外网方式连接,更多连接方式见官方文档:https://cloud.tencent.com/document/product/590/19294)
1) 打开购买的MySQL实例,开启外网
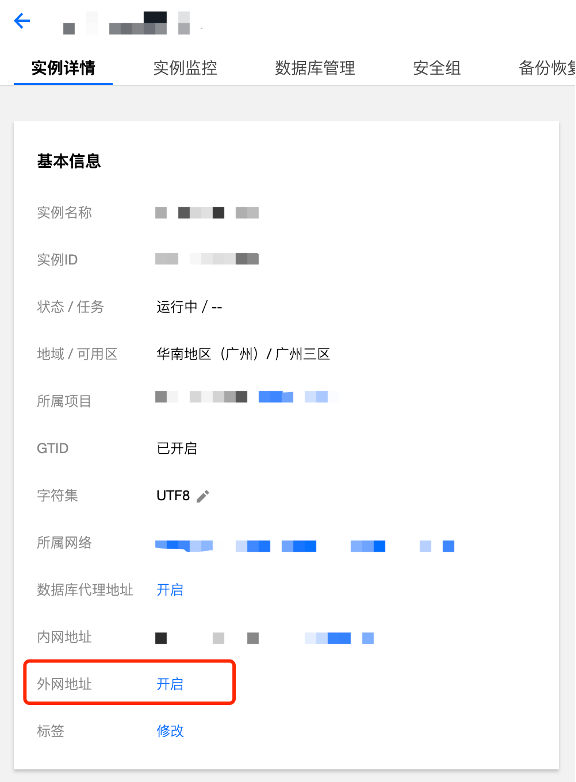
2) 将SaaS BI(119.29.66.144:3306)添加到MySQL数据库安全组
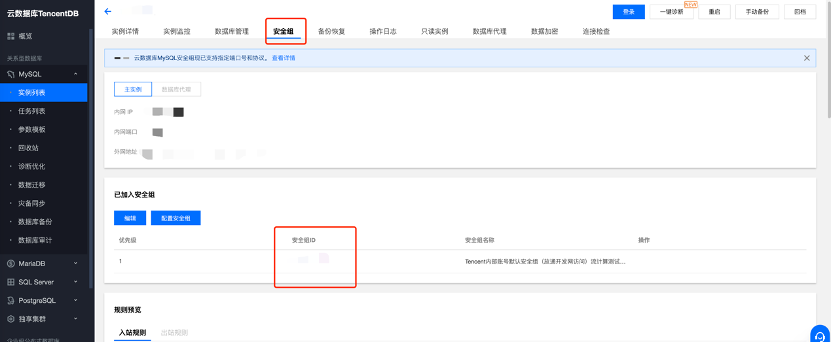
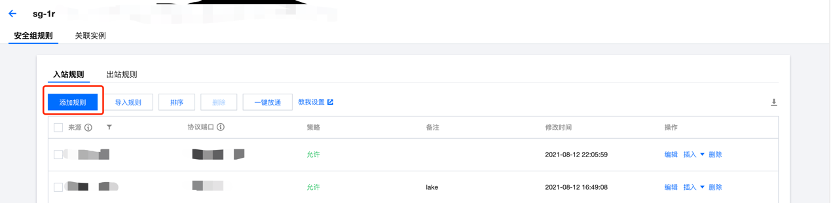
注意添加的是MySQL 3306端口,不是外网映射的端口。
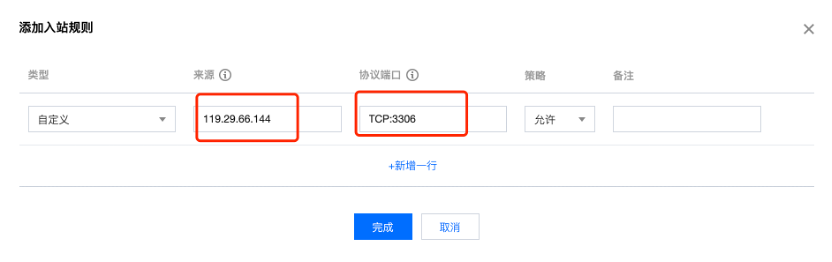
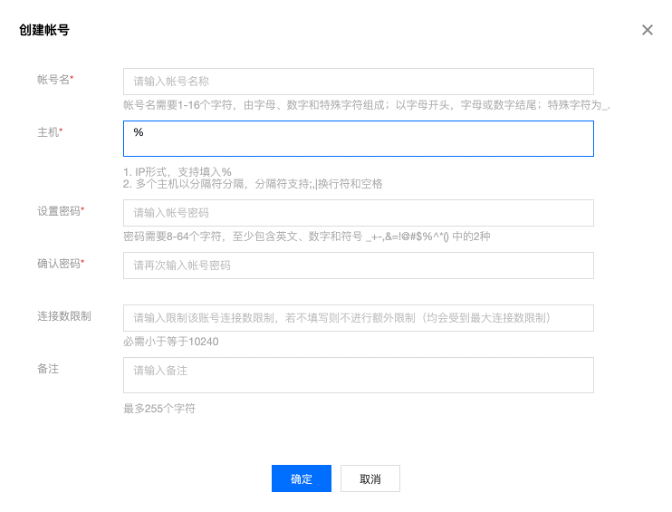
3) 创建MySQL账户并配置权限
创建账户,并设置账号密码,注意主机IP设置为%

设置账号权限,

4) 进入智能商业分析,连接MySQL数据库。添加数据源->MySQL,填写完成后点击测试连接。
3 方案实现
接下来通过案例为您介绍如何利用流计算服务Oceanus实现视频直播数字化运营的实时可视化数据处理与分析。
3.1 解决方案
3.1.1 业务目标
这里只列取以下3种统计指标:
- 全站观看直播用户分布
- 礼物总和统计
- 各模块礼物统计3.1.2 源数据格式
事件log:live_streaming_log(topic)
字段 | 类型 | 含义 |
|---|---|---|
user_id | bigint | 客户号 |
ip | varchar | 客户ip地址 |
room_id | bigint | 房间号 |
arrive_time | timestamp | 进入房间时间 |
leave_time | timestamp | 离开房间时间 |
create_time | timestamp | 创建时间 |
region_code | int | 地区编码 |
grade | int | 会员等级 |
province | varchar | 所在省份 |
Ckafka内部采用json格式存储,展现出来的数据如下所示:
{
'user_id': 3165
, 'ip': '123.0.0.105'
, 'room_id': 20210813
, 'arrive_time': '2021-08-16 09:48:01'
, 'create_time': '2021-08-16 09:48:01'
, 'leave_time': '2021-08-16 09:48:01'
, 'region': 1122
, 'grade': 1
, 'province': '浙江'
}礼物记录:live_gift_log(topic名)
字段 | 类型 | 含义 |
|---|---|---|
user_id | bigint | 客户号 |
gift_type | int | 礼物类型 |
room_id | bigint | 房间号 |
gift_total_amount | int | 礼物数量 |
ip | varchar | ip地址 |
create_time | timestamp | 创建时间 |
{
'user_id': 3994
, 'gift_type': 3
, 'gift_total_amount': 28
, 'room_id': 20210813
, 'ip': '123.0.0.105'
, 'create_time': '2021-08-16 09:46:51'
, 'update_time': '2021-08-16 09:46:51'
}模块记录表:live_module_roomid(Hbase维表)
字段 | 例子 | 含义 |
|---|---|---|
room_id | 20210813 | 房间号 |
mudule_id | 1001 | 所属直播模块 |
3.1.3 Oceanus SQL作业编写
全网观看直播用户分布(需提前在MySQL建表)
1、定义source
CREATE TABLE live_streaming_log_source (
user_id BIGINT,
ip VARCHAR,
room_id BIGINT,
arrive_time TIMESTAMP,
leave_time TIMESTAMP,
create_time TIMESTAMP,
region_code INT,
grade INT,
province VARCHAR
) WITH (
'connector' = 'kafka',
'topic' = 'live_streaming_log',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '172.28.28.13:9092',
'properties.group.id' = 'joylyu-consumer-2',
'format' = 'json',
'json.ignore-parse-errors' = 'false',
'json.fail-on-missing-field' = 'false'
);2、定义sink
CREATE TABLE live_streaming_log_sink (
user_id BIGINT,
ip VARCHAR,
room_id BIGINT,
arrive_time TIMESTAMP,
leave_time TIMESTAMP,
create_time TIMESTAMP,
region_code INT,
grade INT,
province VARCHAR,
primary key(user_id, ip,room_id,arrive_time) not enforced
) WITH (
'connector' = 'jdbc',
'url' ='jdbc:mysql://172.28.28.227/livedb?
rewriteBatchedStatements=true&serverTimezon=Asia/Shanghai',
'table-name' = 'live_streaming_log',
'username' = 'root',
'password' = 'xxxxx',
'sink.buffer-flush.max-rows' = '5000',
'sink.buffer-flush.interval' = '2s',
'sink.max-retries' = '3'
);3、业务逻辑
INSERT INTO live_streaming_log_sink
SELECT * FROM live_streaming_log_source; 礼物总和统计(需提前在MySQL建表)
1、 定义source
CREATE TABLE live_gift_total_source (
user_id VARCHAR,
gift_type VARCHAR,
gift_total_amount BIGINT,
ip VARCHAR,
create_time VARCHAR
) WITH (
'connector' = 'kafka',
'topic' = 'live_gift_total',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '172.28.28.13:9092',
'properties.group.id' = 'joylyu-consumer-1',
'format' = 'json',
'json.ignore-parse-errors' = 'false',
'json.fail-on-missing-field' = 'false'
); 2、 定义sink
CREATE TABLE live_gift_total_amount_sink (
gift_type VARCHAR,
gift_total_amount BIGINT,
primary key(user_id, gift_type) not enforced
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://172.28.28.227/livedb?
rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai',
'table-name' = 'live_gift_total_amount',
'username' = 'root',
'password' = 'xxxxx',
'sink.buffer-flush.max-rows' = '5000',
'sink.buffer-flush.interval' = '2s',
'sink.max-retries' = '3'
);3、 业务逻辑
INSERT INTO live_gift_total_sink
SELECT gift_type,
SUM(gift_total_amount) as gift_total_amount_all
FROM live_gift_total_source
GROUP BY gift_type;
各模块礼物统计(需提前在MySQL建表)1、 定义source
CREATE TABLE live_gift_total_source (
user_id VARCHAR,
gift_type VARCHAR,
gift_total_amount BIGINT,
ip VARCHAR,
create_time VARCHAR,
proc_time AS PROCTIME()
) WITH (
'connector' = 'kafka',
'topic' = 'live_gift_total',
'scan.startup.mode' = 'earliest-offset',
'properties.bootstrap.servers' = '172.28.28.13:9092',
'properties.group.id' = 'joylyu-consumer-1',
'format' = 'json',
'json.ignore-parse-errors' = 'false',
'json.fail-on-missing-field' = 'false'
);2、 定义Hbase维表
CREATE TABLE dim_hbase (
rowkey STRING,
cf ROW <module_id STRING>,
PRIMARY KEY (rowkey) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'dim_hbase',
'zookeeper.quorum' = '用户自己的hbase服务器zookeeper地址'
);3、 定义sink
CREATE TABLE module_gift_total_sink (
module_id BIGINT,
module_gift_total_amount BIGINT,
primary key(module_id) not enforced
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://172.28.28.227/livedb?
rewriteBatchedStatements=true&serverTimezone=Asia/Shanghai',
'table-name' = 'live_gift_total',
'username' = 'root',
'password' = 'xxxxx',
'sink.buffer-flush.max-rows' = '5000',
'sink.buffer-flush.interval' = '2s',
'sink.max-retries' = '3'
);4、业务逻辑
INSERT INTO module_gift_total_sink
SELECT
b.cf.module_id,
SUM(a.gift_total_amount) AS module_gift_total_amount
FROM live_gift_total_source AS a
LEFT JOIN dim_hbase AS b for SYSTEM_TIME as of a.proc_time
ON a.room_id = b.rowkey
GROUP BY b.cf.module_id;3.2 实时大屏可视化展示
创建项目
开通服务后,进入 商业智能分析 BI 控制台,单击创建项目开始创建项目。在弹层中输入项目名称,选择项目 icon 颜色,单击创建并进入刚创建的项目。
添加数据源
数据源用于连接客户本地数据库或云数据库,是数据表加工的基础;数据表是对数据源进行加工后的结果,用于报表创作时使用。 进入之前创建的项目,点击左上方【数据】> 【数据源】> 【新建数据源】即可快速创建本地数据源或云上数据源。
创建页面
点击左上方【页面】>【创建页面】。编辑好后即可单击右上角【保存】>【发布】。
具体操作步骤可参见 商业智能分析 BI 五分钟入门。
查看页面
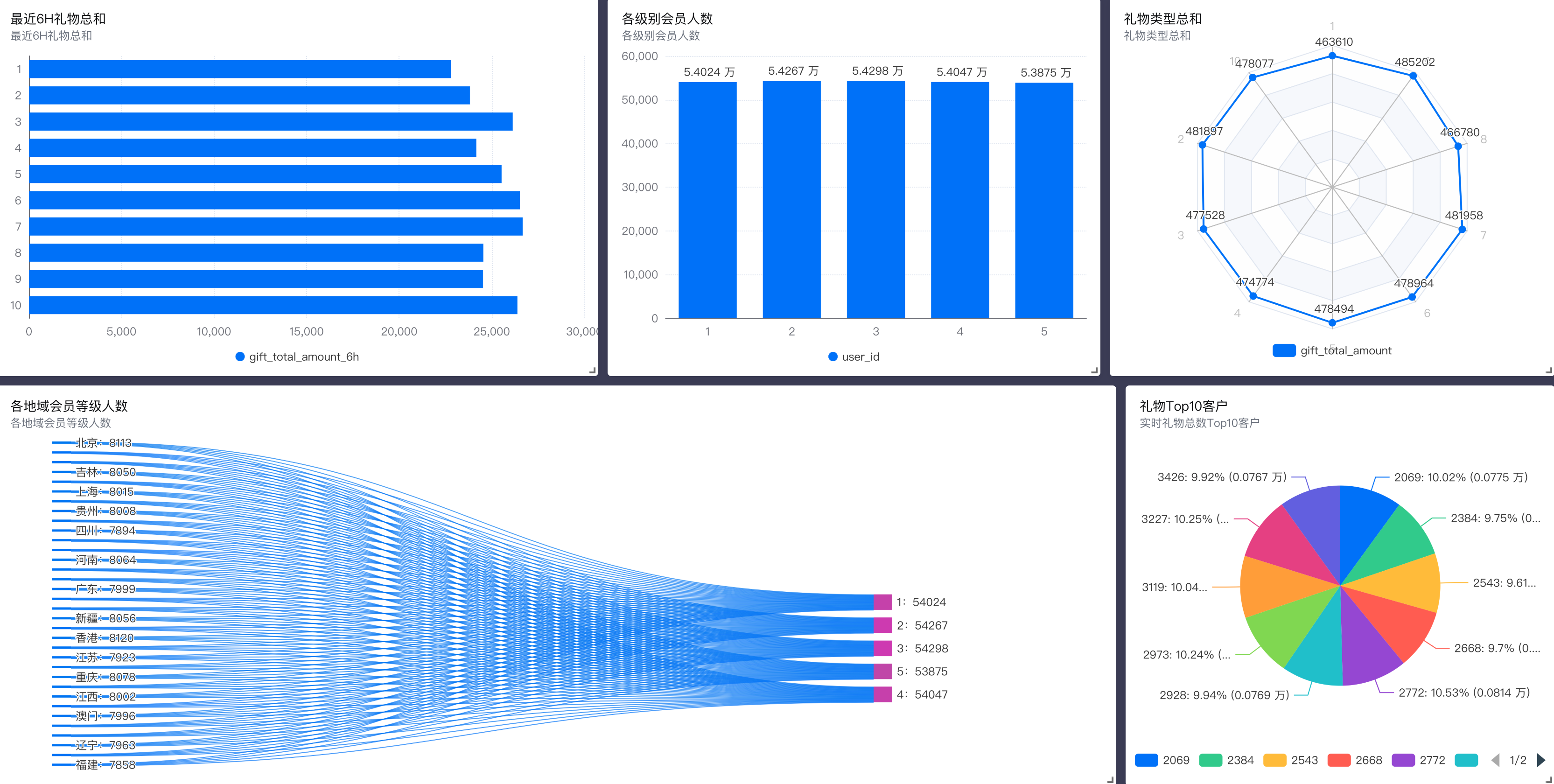
单击【看板】,选择刚才保存的报告,如下图所示,大屏中总共5个图表。
此处仅做展示使用,具体展示效果可根据业务情况做相应调整
- 图表1:最近6h礼物总数统计。表示最近6小时收到的礼物总计和。
- 图表2:各级别会员人数。表示各个会员等级的总人数。
- 图表3:礼物类型总和。表示收到各礼物类型的总和。
- 图表4:各地域会员等级人数。表示各个地域不同会员等级的人数
- 图表5:礼物 Top10 客户。表示刷礼物最多的10个客户。