导语
本⽂主要针对波分运营管理系统展开介绍,即波分事件中⼼主要⽬的与技术⼿段浅谈。⽽开放光系统运营关键核⼼就是事件(event),运营事件的⽬标是⼀个事件解决⽹络的⼀个具体的问题。事件中⼼则是将⽹络所经历的所有事件准确的记录并汇集在⼀起。事件中⼼的每个事件需要准确描述⼀个具体的问题,并描述该问题带来的影响。所以我们研发了波分数据处理平台,其包含对性能数据标准定义、采集、数据实时计算功能。
Flink基本概念
无界和有界数据。任何类型的数据都可以形成一种事件流。信用卡交易、传感器测量、机器日志、网站或移动应用程序上的用户交互记录,所有这些数据都形成一种流。数据可以被作为 无界 或者 有界 流来处理。
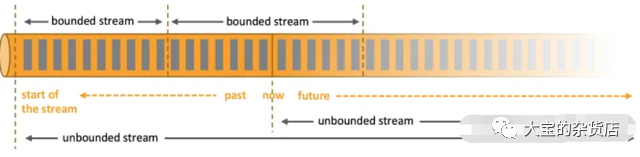
无界流 有定义流的开始,但没有定义流的结束。它们会无休止地产生数据。无界流的数据必须持续处理,即数据被摄取后需要立刻处理。我们不能等到所有数据都到达再处理,因为输入是无限的,在任何时候输入都不会完成。处理无界数据通常要求以特定顺序摄取事件,例如事件发生的顺序,以便能够推断结果的完整性。
有界流 有定义流的开始,也有定义流的结束。有界流可以在摄取所有数据后再进行计算。有界流所有数据可以被排序,所以并不需要有序摄取。有界流处理通常被称为批处理。
Flink重要特点
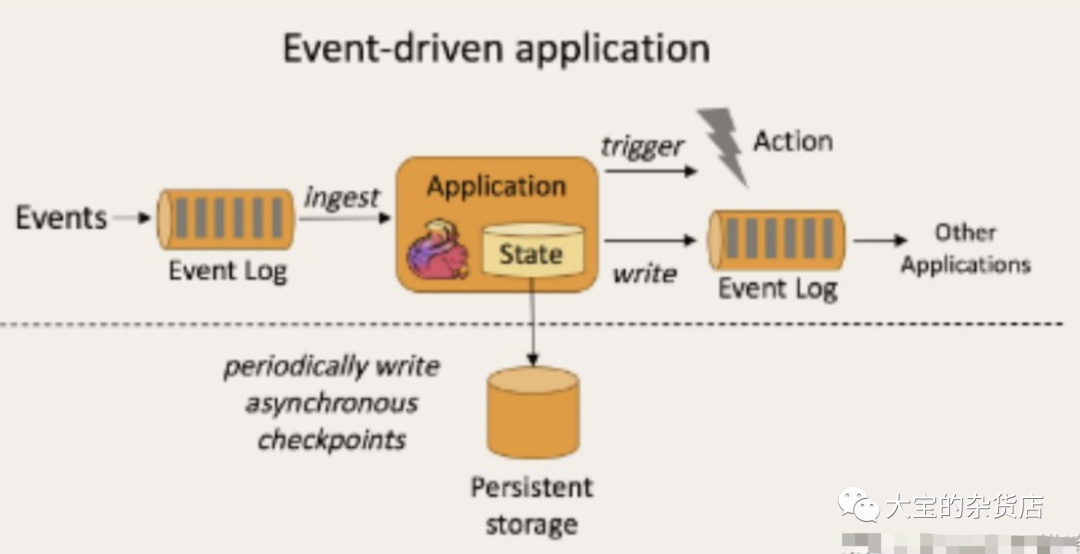
事件驱动型应用是一类具有状态的应用,它从一个或多个事件流提取数据,并根据到来的事件触发计算、状态更新或其他外部动作。比较典型的就是以kafka为代表的消息队列几乎都是事件驱动型应用。
与之不同的就是SparkStreaming微批次,如图:

事件驱动型:
Flink集群架构
Flink 运行时由两种类型的进程组成:一个 JobManager 和一个或者多个 TaskManager。
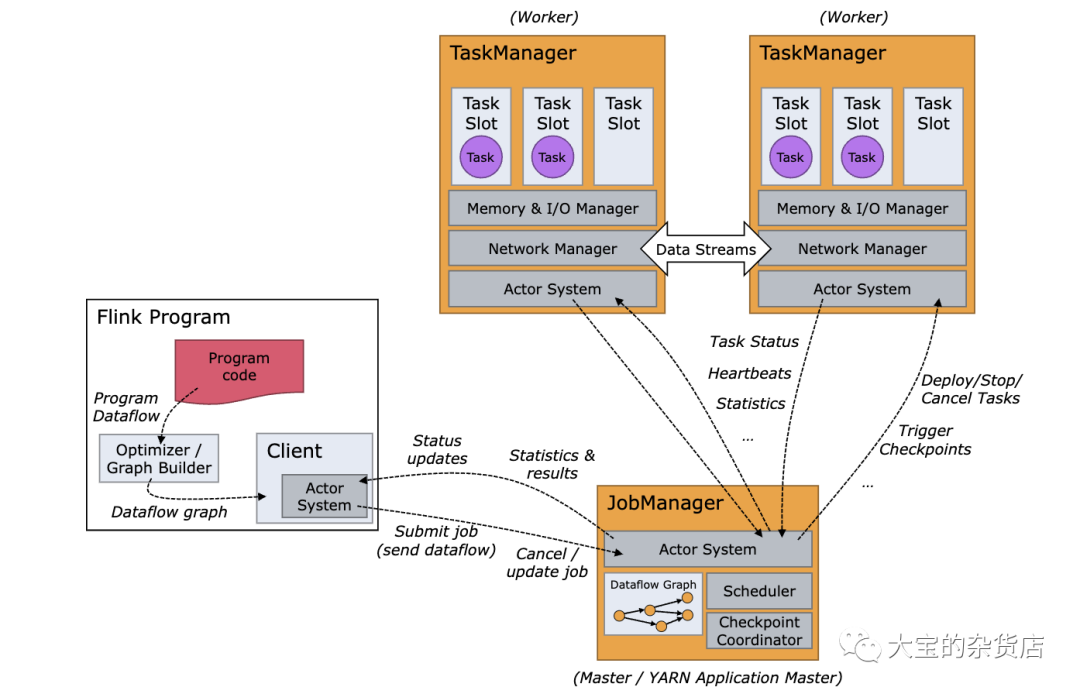
Client 不是运行时和程序执行的一部分,而是用于准备数据流并将其发送给 JobManager。之后,客户端可以断开连接(分离模式),或保持连接来接收进程报告(附加模式)。客户端可以作为触发执行 Java/Scala 程序的一部分运行,也可以在命令行进程./bin/flink run ...中运行。
可以通过多种方式启动 JobManager 和 TaskManager:直接在机器上作为standalone 集群启动、在容器中启动、或者通过YARN或Mesos等资源框架管理并启动。TaskManager 连接到 JobManagers,宣布自己可用,并被分配工作。
数据实时计算平台
在传统的离线批处理场景中,⽤户⾸先需要将数据存放到数据库或者数据仓库中,之后通过发送查询语句来对数据进⾏分析,并根据查询结果进⾏下⼀步的⾏动。
在这个过程中,数据的查询常常需要在完成数据收集之后才可以进⾏,不必要的数据迁移和数据存储使得查询结果的时效性⼗分有限。此外,由于查询操作是由外部动作⽽⾮数据本身触发,因此⽤户也很难实现对数据的持续分析。实时数据流处理技术作为离线批处理技术的有效补充,能够为⽤户提供及时和持续的数据分析能⼒。基于开放光TOOP事件产⽣的计算逻辑以及庞⼤的数据流(1s采集/单台设备),综合对⽐我们选⽤了Flink分布式计算引擎做为monitor实时计算服务的⼯具。Flink是⼀个针对流数据和批数据的分布式处理引擎, 其前身是柏林理⼯⼤学的项⽬Stratosphere, 在2014年被apache孵化器所接受, 成为Apache Software Foundation的顶级项⽬之⼀.。与spark相⽐, flink⽀持实时的流处理, 同时如果将输⼊数据定义为有界的, ⼜可以视为批处理,同时flink⽀持本地的快速迭代以及⼀些环形的迭代任务。
Flink的架构是基于master-slaver的⽅式的
⽤户提交⼀个flink任务时, 会创建⼀个Client, 对任务进⾏预处理, 将StreamGraph转为JobGraph, 然后提交给JobManager. JobManager再将JobGraph⽣成并发版的ExecutionGraph, 并在TaskManager上部署执⾏任务. TaskManager将⼼跳和统计信息汇报给JobManager.
JobManager是整个系统的协调者, 负责接收Job, 调度组成Job的多个Task的执⾏, 收集Job的状态信息, 以及管理 Taskmanager.
TaskManager是实际负责执⾏计算的Worker, 从JobManager接收需要Task进⾏部署, 上报任务状态, ⼼跳和统计信息给JobManager。
JobManager
JobManager 具有许多与协调 Flink 应用程序的分布式执行有关的职责:它决定何时调度下一个 task(或一组 task)、对完成的 task 或执行失败做出反应、协调 checkpoint、并且协调从失败中恢复等等。这个进程由三个不同的组件组成:
- ResourceManager ResourceManager 负责 Flink 集群中的资源提供、回收、分配 - 它管理 task slots,这是 Flink 集群中资源调度的单位(请参考TaskManagers)。Flink 为不同的环境和资源提供者(例如 YARN、Mesos、Kubernetes 和 standalone 部署)实现了对应的 ResourceManager。在 standalone 设置中,ResourceManager 只能分配可用 TaskManager 的 slots,而不能自行启动新的 TaskManager。
- Dispatcher Dispatcher 提供了一个 REST 接口,用来提交 Flink 应用程序执行,并为每个提交的作业启动一个新的 JobMaster。它还运行 Flink WebUI 用来提供作业执行信息。
- JobMaster JobMaster 负责管理单个JobGraph的执行。Flink 集群中可以同时运行多个作业,每个作业都有自己的 JobMaster。 始终至少有一个 JobManager。高可用(HA)设置中可能有多个 JobManager,其中一个始终是 leader,其他的则是 standby(请参考 高可用(HA))。TaskManagersTaskManager(也称为 worker)执行作业流的 task,并且缓存和交换数据流。 必须始终至少有一个 TaskManager。在 TaskManager 中资源调度的最小单位是 task slot。TaskManager 中 task slot 的数量表示并发处理 task 的数量。请注意一个 task slot 中可以执行多个算子(请参考Tasks 和算子链)。
Tasks与算子链
对于分布式执行,Flink 将算子的 subtasks 链接成 tasks。每个 task 由一个线程执行。将算子链接成 task 是个有用的优化:它减少线程间切换、缓冲的开销,并且减少延迟的同时增加整体吞吐量。链行为是可以配置的。
下图中样例数据流用5个subtask智行,因此有5个并行线程
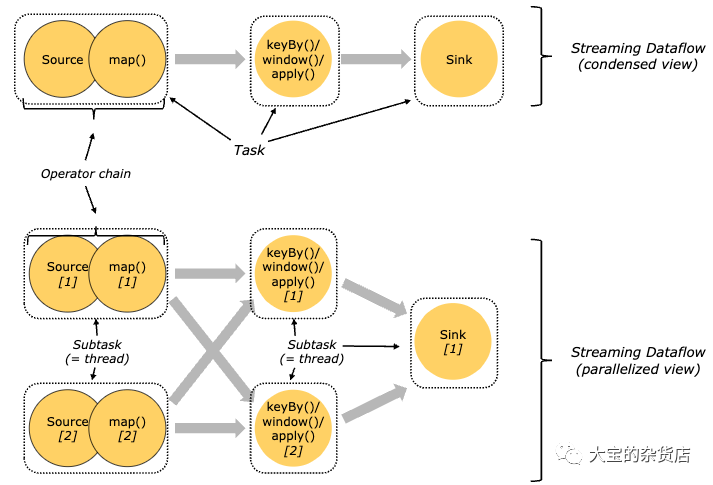
Task Slots与资源
每个 worker(TaskManager)都是一个 JVM 进程,可以在单独的线程中执行一个或多个 subtask。为了控制一个 TaskManager 中接受多少个 task,就有了所谓的 task slots(至少一个)。
每个 task slot 代表 TaskManager 中资源的固定子集。例如,具有 3 个 slot 的 TaskManager,会将其托管内存 1/3 用于每个 slot。分配资源意味着 subtask 不会与其他作业的 subtask 竞争托管内存,而是具有一定数量的保留托管内存。注意此处没有 CPU 隔离;当前 slot 仅分离 task 的托管内存。
通过调整 task slot 的数量,用户可以定义 subtask 如何互相隔离。每个 TaskManager 有一个 slot,这意味着每个 task 组都在单独的 JVM 中运行(例如,可以在单独的容器中启动)。具有多个 slot 意味着更多 subtask 共享同一 JVM。同一 JVM 中的 task 共享 TCP 连接(通过多路复用)和心跳信息。它们还可以共享数据集和数据结构,从而减少了每个 task 的开销。

- 默认情况下,Flink 允许 subtask 共享 slot,即便它们是不同的 task 的 subtask,只要是来自于同一作业即可。结果就是一个 slot 可以持有整个作业管道。允许 slot 共享有两个主要优点: Flink 集群所需的 task slot 和作业中使用的最大并行度恰好一样。无需计算程序总共包含多少个 task(具有不同并行度)。
- 容易获得更好的资源利用。如果没有 slot 共享,非密集 subtask(source/map())将阻塞和密集型 subtask(window) 一样多的资源。通过 slot 共享,我们示例中的基本并行度从 2 增加到 6,可以充分利用分配的资源,同时确保繁重的 subtask 在 TaskManager 之间公平分配。

实时计算逻辑
实时计算其实是在满⾜⼀定吞吐量的情况下,尽可能的降低执⾏任务的延迟。
*Stream执⾏环境配置初始化
final StreamExecutionEnvironment streamEnv = StreamExecutionEnvironment
.getExecutionEnvironment();
streamEnv.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
long checkpointInterval = params.getLong(PARAM_CHECKPOINT_INTERVAL, 1000l);
streamEnv.enableCheckpointing(checkpointInterval, CheckpointingMode.EXACTLY_ONCE);
streamEnv.setRestartStrategy(RestartStrategies.fixedDelayRestart(5, 50000));这里其实增加了source,即消费Kafka的数据(Topic)
DataStream<byte[]> messageStream = streamEnv.addSource(
new FlinkKafkaConsumer011<>(kafkaTopic, new ByteArrayDeserializerSchema(),
kafkaConsumerProperties))
.uid("kafka-consume-id");
DataStream<PmDataModel> oaPmStream = messageStream
.flatMap(new xxxCollector())
.assignTimestampsAndWatermarks(new WatermarkExtractor(0))
.uid("xxx-id");因为kafka的源流中的数据类型不满⾜我们的需求,这⾥我们利⽤flatmap进⾏了数据结构的转换,将嵌套集合转换并平铺成⾮嵌套集合,这⾥我们定义了转换的⽅式,即xxxCollector类⾥重写了flatMap,将原始的proto定义的性能数据list做了⼀层转换到HashMap,之后通过Collect对数据平铺,也就是多⾏处理。
for (PmDataModel pmDataModel : pmDataModels.values()) {
if (pmDataModel.isValid()) {
collector.collect(pmDataModel);
} else {
log.warn("Invalid PM data received: {}, dropped.", pmDataModel);
}
}- 开启计算窗口
DataStream<Item> xxxDataStream = pmStream.keyBy(pm -> pm.getKey())
.connect(broadcastTopo)
.process(new xxxCreator())
.uid("initxxxStream-id");
OutputTag<xxItem> lateOutputTag = new OutputTag<xxItem>("xxx-data") {
};
SingleOutputStreamOperator<xxxCompareResultPair> compareResult1 = xxxStream
.keyBy(item -> item.getKey())
.window(TumblingEventTimeWindows.of(Time.seconds(1)))
.allowedLateness(Time.seconds(5))
.sideOutputLateData(lateOutputTag)
.process(new xxxProcessor(xxx))
.uid("xxx-id");⾸先明确⼀个Flink极为关键的计算基础:Time、Watermark、Window;这⾥的Time分为EventTime(事件的创建事件)、IngestionTime(事件进⼊Flink数据流的source的时间)、ProcessingTime(某个Operator对事件进⾏处理时的本地系统时间),⽽Flinl的⽆限数据流是⼀个持续的过程,时间是我们判断业务状态是否滞后,数据处理是否及时的重要数据。Watermark⽔位线在Flink中属于特殊事件,其精髓在于某个运算值收到带有时间戳"T"的Watermark时就意味着它不会收到新的数据,代表了整个流的推进进度。Window,流处理中的聚合操作,不同于批处理,图标为数据流是⽆限的,⽆法在其上应⽤聚合,所以通过限定窗⼝(Window)的范围,来进⾏流的聚合操作;xxxProcessor这⾥会对1s内窗⼝的双端性能数据做计算。
获取到性能数据后,我们就可以开窗⼝算⼦计算,这⾥⾸先获取到性能数据流keyBy的id对应linkId,也就是每根光纤,因为我们的数据1s采集上报,所以这⾥滚动窗⼝⼤⼩设为1s,Watermark2s,这⾥还要考虑到kafka分区原因,数据到达是乱序的或者说有⼀定的数据延迟情况出现,所以我们还需要设置allowedLateness,这⾥设置成5s,allowedLateness针对eventTime⽽⾔,对于Watermark超过超过end-of-window之后,还允许有⼀段时间(也是以eventTime来衡量)来等待之前的数据到达,以便再次处理这些数据。
当然正整个波分系统中,数据的采集消费⼀些场景中会存在延迟数据的情况,这⾥我们使⽤Flink的sideOutputLateData⽅式将迟到数据发送到另外⼀个流,如果想对这些迟到数据处理,我们可以使⽤Flink的侧输出(Side Output)功能,将迟到数据发到某个特定的流上。后续我们可以根据业务逻辑的要求,对迟到的数据流进⾏处理。波分这⾥的做法⽬前只是将延迟的数据放⼊⼀个流中通过getSideOutput获取打印出来。还有值得注意的⼀点就是,通过之前的compareResult1计算出的事件数据流(是有多个简单事件组成的)。
Pattern<xxxCompareResultPair, ?> xxxPattern = Pattern.<xxxCompareResultPair>begin( "first") .next("second") .within(Time.milliseconds(2000));
PatternStream<xxxCompareResultPair> xxxEventPatternStream = CEP
.pattern(compareResult1.keyBy(item -> item.getKey()), xxxEventPattern);
ernStream
.process(new xxxPatternProcessFunction()).uid("xxx-id");
DataStream<xxxEvent> events = compareResult2
.keyBy(resultPair -> resultPair.getKey())
.flatMap(new xxxEventCreator(xxx))
.uid("xxx-id");
如上⾯的代码所示,我们定义了pattern规则,我们通过CEP进⾏处理,也就是对于A-Z端的⼀根光纤来说,我们会保证进⾏两次的相同事件的计算,⽐如第⼀组性能数据计算出光纤的劣化事件,那么第⼆组数据也需要计算出光纤劣化事件,但两组数据的值可能不会相等,但都是命中了出光纤劣化事件的逻辑,这样我们得到的comareResult2就是⼀个光纤正常或光纤有事件的数据流,这样做的⽬的是为了防⽌数据因素或系统性的问题带来了频繁出事件或事件逻辑计算不准确的影响。xxxEventCreator就是根据之前得到的事件数据流进⾏⼆次处理,计算出下游可获取到的光纤事件结构,过滤出光纤事件,排除掉光纤正常事件,输出到kafka队列中⽤于下游节点的订阅处理展现。