版权声明:本文为博主原创文章,转载请注明源地址。 https://cloud.tencent.com/developer/article/1433772
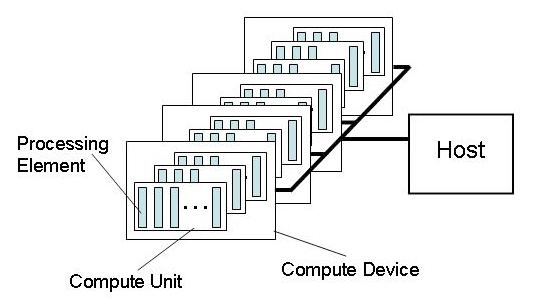
OpenCL 平台模型的定义如下图。模型中有一个主机,并且有一个或多个OpenCL
设备与其相连。每个OpenCL 设备可划分成一个或多个计算单元(CU),每个计算单元又可划分
成一个或多个处理元件(PE)。设备上的计算是在处理元件中进行的。
OpenCL 应用程序会按照主机平台的原生模型在这个主机上运行。主机上的OpenCL 应用程
序提交命令(command queue)给设备中的处理元件以执行计算任务(kernel)。计算单元中的处理元件会作为SIMD 单元(执行
指令流的步伐一致)或SPMD 单元(每个PE 维护自己的程序计数器)执行指令流。
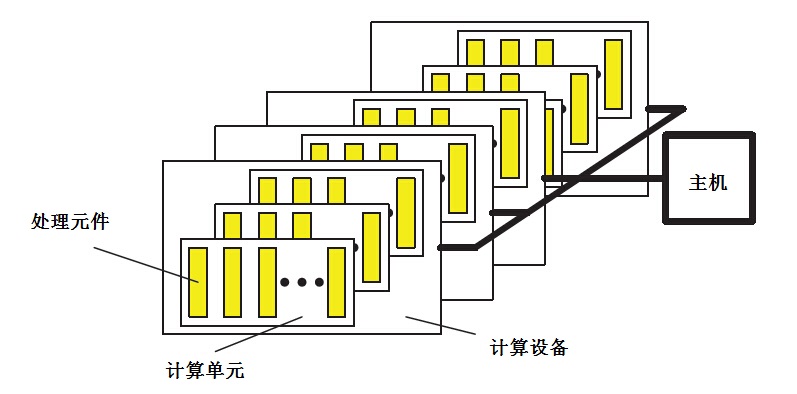
对应的中文名字模型
我们知道,可以通过调用clGetDeviceInfo获取CL_DEVICE_MAX_COMPUTE_UNITS参数就可以得到OpcnCL设备的计算单元(CU)数目,但是如何获取每个计算单元(CU)中处理元件(PE)的个数呢?
clGetDeviceInfo函数不能提供PE个数,如果要获取PE数目,需要调用clGetKernelWorkGroupInfo函数,获取CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE参数,就是每个CU的PE数目。
下面是对CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE参数的描述:

我的电脑CPU是4核心的,显卡是AMD R7350(8个计算单元,512个流处理器),运行clinfo的结果如下(内容太长只节选片段,中文部件为作者加注),可以看出Kernel Preferred work group size multiple这一项正是每个计算单元的PE数量,
Number of platforms: 1 Platform Profile: FULL_PROFILE Platform Version: OpenCL 2.0 AMD-APP (1800.8) Platform Name: AMD Accelerated Parallel Processing Platform Vendor: Advanced Micro Devices, Inc. Platform Extensions: cl_khr_icd cl_khr_d3d10_sharing cl_khr_d3d11_sharing cl_khr_dx9_media_sharing cl_amd_event_callback cl_amd_offline_devices
Platform Name: AMD Accelerated Parallel Processing
Number of devices: 2
Device Type: CL_DEVICE_TYPE_GPU
Vendor ID: 1002h
Board name: AMD Radeon R7 350 Series
Device Topology: PCI[ B#1, D#0, F#0 ]
Max compute units: 8 // 8个计算单元
Max work items dimensions: 3
Max work items[0]: 256
Max work items[1]: 256
Max work items[2]: 256
Max work group size: 256
...
Kernel Preferred work group size multiple: 64// AMD GPU显卡每个计算单元PE为64
Device Type: CL_DEVICE_TYPE_CPU
Vendor ID: 1002h
Board name:
Max compute units: 4 // 4核心处理器
Max work items dimensions: 3
Max work items[0]: 1024
Max work items[1]: 1024
Max work items[2]: 1024
Max work group size: 1024
.....
Kernel Preferred work group size multiple: 1// CPU每个计算单元的PE为1
c++下实现代码也很简单,写个最简单的kernel编译后,调用getWorkGroupInfo获取CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE就可以了:
/*
获取OpenCL设备每个计算单元(CU)中处理单元(PE)个数
*/
size_t cl_utilits::kernel_preferred_work_group_size_multiple(const cl::Device& device) const {
// 编译一个空的kernel函数
cl::Program program(cl::Context({device}), "__kernel void test(){}", true);
std::vector<cl::Kernel> kernels;
program.createKernels(std::addressof(kernels));
//调用getWorkGroupInfo获取CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE,
//返回结果就是指定OpenCL设备(device)的每个CU的PE数目
return kernels[0].getWorkGroupInfo<CL_KERNEL_PREFERRED_WORK_GROUP_SIZE_MULTIPLE>(device);
}
注:图片摘自opencl-1.2.pdf,opencl-spec-zh-beta2.pdf