| 导语 ES集群的分片均衡一直以来都显得比较神秘,他好像很有规律,但好像又很随机
背景
默认情况下,ES集群会出现磁盘使用率或者分片分配不均衡的现象(有的磁盘使用90%以上,有的却是20%左右,有的节点分片数偏少,有的节点分片数偏多),因此熟悉ES分片均衡相关的策略,合理调节均衡相关参数,才能保证ES集群的稳定性和资源的充分利用。
一个分片为什么被平衡到某台节点而不是其他节点,集群以及索引的分片如何保证在每台节点上大致相同,什么条件下会触发平衡等等问题都困扰了我好久,今天我们以例子的方式深入浅出的分析分析分片均衡的算法策略
参数
ES8.0主要有以下3个参数赋能分片均衡的策略,index和shard因子是用来计算权重的系数
cluster.routing.allocation.balance.index: 0.55f #索引因子所占比重
cluster.routing.allocation.balance.shard: 0.45f #分片因子所占比重
cluster.routing.allocation.balance.threshold: 1.0f #阈值大小,超过该值才会触发平衡
复制
使用方式
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.balance.index": "0.55f",
"cluster.routing.allocation.balance.shard": "0.45f",
"cluster.routing.allocation.balance.threshold": "1.0f"
}
}
复制
举个栗子
分片分配、迁移、平衡,这三个算法的逻辑都相对比较复杂,今天我们用一个非常简单的例子只解释下平衡分片算法的逻辑(实际过程要复杂的多,该过程阉割了不必要的逻辑和实现的细节)
我们首先创建2个索引index1和index2,每个索引6个主分片无副本,如下表:
索引名 | 分片数 | 副本数 |
|---|---|---|
index1 | 6 | 0 |
index2 | 6 | 0 |
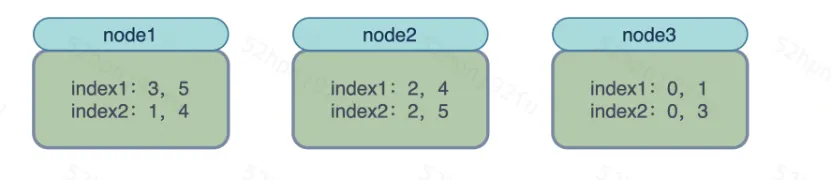
假设集群共有3台datanode,刚开始分片分配如下图(显然此时分片是不均衡的):

1、创建权重对象
cluster.routing.allocation.balance.index: 0.55f #索引因子所占比重
cluster.routing.allocation.balance.shard: 0.45f #分片因子所占比重
cluster.routing.allocation.balance.threshold: 1.0f #阈值大小,超过该值才会触发平衡 从ES的Settings中获取上面3个参数的值,创建权重对象WeightFunction,默认值如下:
index因子: indexBalance=0.55
shard因子: shardBalance=0.45
阈值: threshold=1
复制
2、创建平衡器并计算相关属性值
avgShardsPerNode:理想状态下,平均每个节点应该分配的分片数等于 (6+6)/3=4
avgShardsPerIndex:一个索引平均分配到每个节点上的分片数,由于两个索引分片数一样,所以都等于 6/3=2
复制
3、权重公式
float weight(Balancer balancer, ModelNode node, String index) {
final float weightShard = node.numShards() - balancer.avgShardsPerNode();
final float weightIndex = node.numShards(index) - balancer.avgShardsPerNode(index);
return shardBalance * weightShard + indexBalance * weightIndex;
}解释:
node.numShards():该节点目前总共的分片数
balancer.avgShardsPerNode():理想情况下,平均每个节点的应该分配的分片数
node.numShards(index):该索引在该节点的分片个数
balancer.avgShardsPerNode(index):理想情况下,该索引平均分配到每个节点上的分片数
因此权重公式使用文字描述如下:
shard因子(shardBalance=0.45) * (该节点所有分片数 - 平均每台节点分片数) + index因子(indexBalance=0.55) * (该索引在该节点的分片数 - 该索引平均在每台节点的分片数)
复制
4、计算每个索引在所有节点的权重及差值
假设先遍历到index1,index1在3台节点上的分片个数分别为3、2、1,index1在每台节点上的权重分别为:
node1:(5-4)* 0.45 + (3-2)*0.55 = 1
node2:(5-4)* 0.45 + (2-2)*0.55 = 0.45
node3:(2-4)* 0.45 + (1-2)*0.55 = -1.45
index1在3台节点的权重差为最大值减去最小值=1+1.45=2.45 > 1
复制
index2在3台节点上的分片个数分别为2、3、1,index2在每台节点上的权重分别为:
node1:(5-4)* 0.45 + (2-2)*0.55 = 0.45
node2:(5-4)* 0.45 + (3-2)*0.55 = 1
node3:(2-4)* 0.45 + (1-2)*0.55 = -1.45
index2在3台节点的权重差为最大值减去最小值=1+1.45=2.45 > 1
复制
5、根据权重差值倒序排序,优先平衡差值较大的索引
由于index1的权重差和index2的权重差相同,假设平衡分片时的索引顺序为["index1", "index2"],平衡的逻辑是优先将权重值大的节点上的分片迁移到权重值小的节点
先平衡index1,假设将index1的分片0从node1试图迁移到node3(此时就是node1上的分片少了一个,node3上的分片多了一个),试图迁移中index1在每个节点上的权重分别为:
node1:(4-4)* 0.45 + (2-2)*0.55 = 0.0
node2:(5-4)* 0.45 + (2-2)*0.55 = 0.45
node3:(3-4)* 0.45 + (2-2)*0.55 = -0.45
index1在3台节点的权重差为最大值减去最小值=0.45+0.45=0.9 < 1
此时已经小于阈值1,说明index1已经平衡了,其余分片就不需要在处理了
复制
继续平衡index2,假设将node2上的分片0试图迁移到node3(此时就是node2上的分片少了一个,node3上的分片多了一个),试图迁移中index2在每个节点上的权重分别为:
node1:(4-4)* 0.45 + (2-2)*0.55 = 0.0
node2:(4-4)* 0.45 + (2-2)*0.55 = 0.0
node3:(4-4)* 0.45 + (2-2)*0.55 = 0.0
index2在3台节点的权重差为最大值减去最小值=0-0=0 < 1
此时已经小于阈值1,说明index2已经平衡了,其余分片就不需要在处理了
复制
6、平衡完毕
至此所有索引已平衡完毕,当然平衡的时候,比如将index1的分片0从node1迁移到node3的过程中还会经历十几个决策者的判断,判断该分片能不能迁移,比如主副分片不能在一台节点上,磁盘有没有达到高低水位线等等,最终平衡如下图:
总结
1、平衡分片时缺少了对磁盘的评估,如果能保证每台节点每块磁盘的使用率大致一样就更好了,不然可能导致磁盘使用不均
2、平衡分片时缺少了对QPS的预估,如果能保证每台节点写入和查询的QPS大致一样,就不会存在热点问题了
3、ES基于这种随机的算法,也基本上都保证每台节点磁盘使用率、QPS、分片个数等大致相同