
作者|葛星
编辑|黎安
网易云音乐(以下简称“云音乐”)的前端团队大概在 4 年前初具规模,4 年多的快速发展过程当中做了很多 0 到 1 的平台,造成了平台深井,比如研发的体系,部署的体系,监控的体系等,这些体系在云音乐初期快速发展中起到了非常大的作用。但是随着人员的更迭及业务不断的发展,初期各自发展的垂直体系遇到了和产品后期同样的问题,新增一个功能越来越复杂,涉及的链路越来越长,花费的代价越来越高,用户需要在各自的平台跳入跳出,会有各种各样的卡点,导致效率降低。如何串联各平台场景,打破平台深井,这是云音乐前端工程化面临的第一个挑战。
除去研发之外,所有的应用在上线前还需要经历测试和部署以及上线后的运维,但是每种应用类型在每个阶段的关注点不一样,所依赖的服务也不一样,比如 Node 应用的部署会依赖云原生,但是 H5 的应用依赖 NOS 的静态资源服务。如何使用一套架构支持不同应用类型的全生命周期发布,这是云音乐前端工程化面临的第二个挑战。
云音乐的业务从单一的播放器发展到社区生态的过程中,为了体验和效率之间的平衡,涌现了多种多样的应用形态,比如 H5 的应用、RN 的应用、中后台的应用、Node 应用等;为了一些极致的体验,在 H5 下又细分离线和闪开,RN 又细分为拆包应用。这些不同的应用类型,工程规范不一致,脚手架也不一致,导致开发同学在上手时有一定的成本,也造成了维护上的困难。如何使用一套架构去收敛这些不同的研发体系,这是云音乐前端工程化面临的第三个挑战。
本篇文章着重针对前两个挑战分享解决思路,我们也发起了一个代号为 Febase 的项目,这个项目目标是针对前端开发者,通过一站式应用研发平台,提升开发部署的效率和体验,并且降低后续应用扩展的维护成本。
产品设计
在 Febase 之前,云音乐没有完整流程的研发体系,部署前的流程基本都在线下完成,也没有研发流程管控的概念,开发在即将上线之前,先将代码合并到 master 再进行部署。这里会存在几个问题,一个是没有统一的研发流程,无法做标准化;一个是有可能上线前的代码存在问题,即便是经过了 QA 的测试,但是代码已经合并到 master,有可能会让其他人再次将错误的代码带上线。所以在产品层面上,我们设计了以应用为中心的全生命周期的研发工作流,将各自分散的体系按照研发的维护来串联各平台的关键节点,每种应用类型都会经历从初始化、开发、构建、编译、部署、监控的流程,在各自垂直的链路上提供不同的差异化能力来完成,这样既收敛了用户的心智,也有了统一的工具产品来提升整体的基建水平。
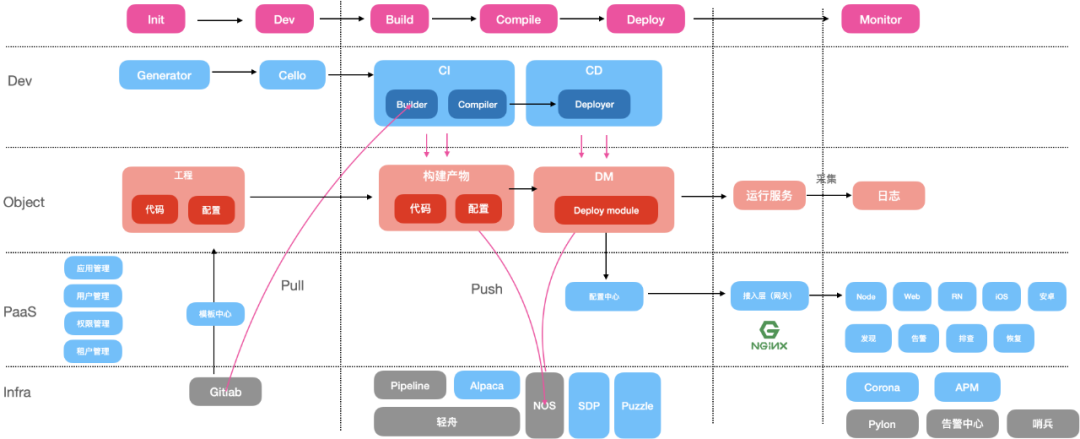
整体架构
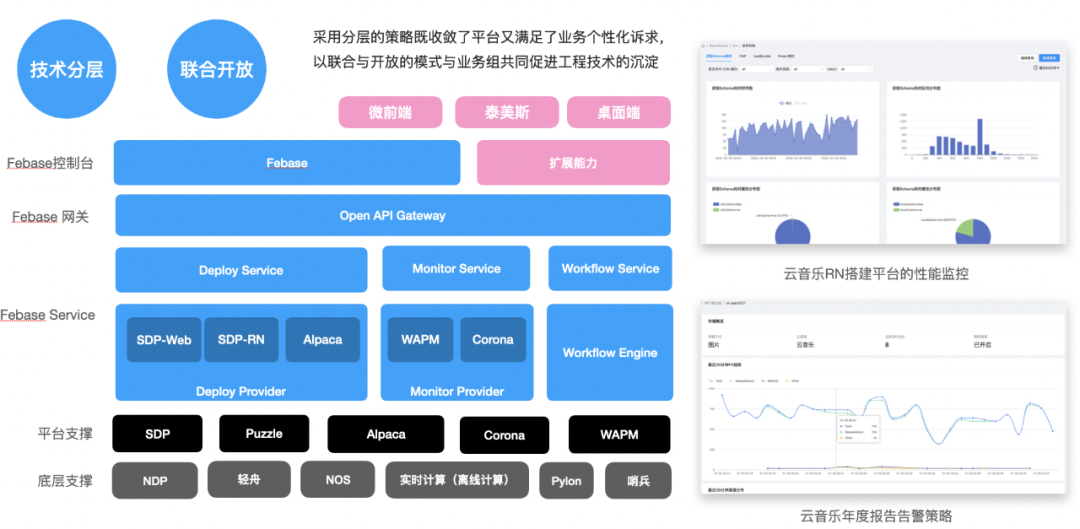
我们先来看下 Febase 的整体架构,我们将各类公共技术所属平台进行服务下沉,统一整个控制台入口,中间层通过自研的流程引擎来编排不同应用类型的部署流程,极大提升了后续新增业务类型的扩展性,前端通过微前端的方式进行自定义扩展,各业务组可以基于此扩展能力定制属于自己的页面,无须另起平台。
研发管控
流程引擎编排
工程化里最重要的就是研发过程管控,由于 Febase 本身需要支持多种不同的应用,而每种应用类型的研发流程是不同的,下面展示了 GraphQL 应用和 RN 应用的差异。


可以看到不仅流程不一样,UI 也不一样,传统的方式,硬编码当然也可以解决问题,但是随着应用类型不断扩充,代码可维护性会直线降低。
那么如何能够更好的使用技术手段进行解耦呢,我们想到了流程引擎,业界比较流行的流程引擎就是BPMN,也有对应的 Node 实现,但对于我们而言,一方面是场景没有这么复杂,另一方面还需要针对 UI 进行编排,所以我们选择自研一个简单的编排引擎,最终效果是针对上面的场景可以通过下面的代码来实现,比如 GraphQL 的研发流程:
服务端侧定义:
export default workflow({ extra: { appType: 'GraphQL', },}) .next({ name: '开发', proc: { endpoint: 'fn:dev', parameters: { sprintId: 'extra.sprintId', }, }, }) .next( sequential({ name: '卡点' }) .add( parallel({ name: '质量验证' }).add({ name: 'Review', proc: { endpoint: 'fn:review', parameters: { sprintId: 'extra.sprintId', sprintService: 'instantExtra.sprintService', }, }, }) )前端侧定义:
bindViewOfWorkflow('graphql', '0.0.1') .withOverview(Overview) .withNodeView('开发', StageDev) .withNodeView('卡点', StageCheck) .withNodeView('回归', StageReg) .withNodeView('质量验证', NodeInTabs) .withNodeView('Review', CodeReviewCheck) .withNodeView('卡点手动确认', ManuallyCheck) .withNodeView('预发', StagePre) .withNodeView('上线', StageOnline) .withNodeView('完成', StageComplete);只需要分别定义 Node 侧和前端侧就可以完成一种应用类型的扩展。在 Node 侧的定义中endpoint指定了推进到该节点时需要执行的服务,比如 Review 节点,下面就创建了一个 CR 的流程:
Review 节点 Node 侧:
export default async function review({ sprintId, sprintService,}: { sprintId: number; sprintService: SprintService;}) { try { await sprintService.requestCodeReview(sprintId); return { code: NodeStatus.Suspended, }; } catch (error) { return { code: NodeStatus.Error, msg: (error as Error).message, }; }}前端侧只需要通过 useWorkflow 的 hooks 传入当前发布的 ID 即可获取到流程进行到哪里的状态:
流程视图侧代码:
import { useWorkflow } from '@ripplet/engine-react';
function Detail(props: DetailProps) { const { sprintId } = props; const { Overview } = useWorkflow(sprintId);
return ( <Card> <Overview /> </Card> )}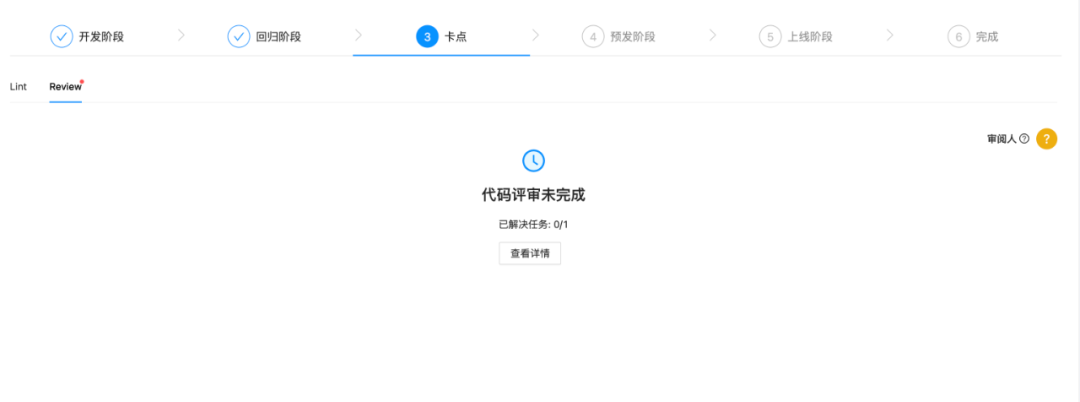
通过自研的流程引擎,我们将流程状态管理与具体的业务逻辑解耦,并通过流程引擎驱动前端视图的变更,以此降低了业务逻辑开发的复杂度。
流程引擎实现
实际上在 Febase 的流程相对较为简单,只需要支持并行、串行、跳过、回退能力即可,业界大部分流程编排都是通过 XML 文件来定义的,我们这里采用了 JS 的方式,主要是省去了解析 XML 的成本,JS 的定义可以直接存储为 JSON 格式;其次我们提供了前端的视图配合套件,可以方便地进行前后端状态的绑定。当用户创建一次开发需求的时候就创建了一个流程,这个流程状态关联了流程的 ID,每当流程触发了下一步,流程引擎就会执行对应的逻辑并更新流程的状态进行存储,回退同样是对流程的状态进行变更然后存储。调试阶段可以将状态放置在内存中,如果是生产环境我们就将流程的状态存储在 MongoDB 中,因为流程的状态非常适合文档型数据库的存储。
那么,流程引擎核心的一个点是如何处理需要挂起的逻辑的?很多节点的逻辑是需要三方服务来完成的,在 Febase 里是通过下面的方式:
- 引擎通知外部系统进行处理,通知时会传递 fid 和 pid,fid 是当前流程 ID,其中 pid 表示发出此 RPC 请求的 Stage 对应的是 process ID
- 外部系统通过返回 pending 状态码,表示该请求需要异步处理
- 引擎接收到 pending 状态码后,会设置自身状态为 Suspended,并对当前的快照进行保存
- 外部系统处理完毕后,通过之前的 fid 和 pid 让引擎继续之前的流程
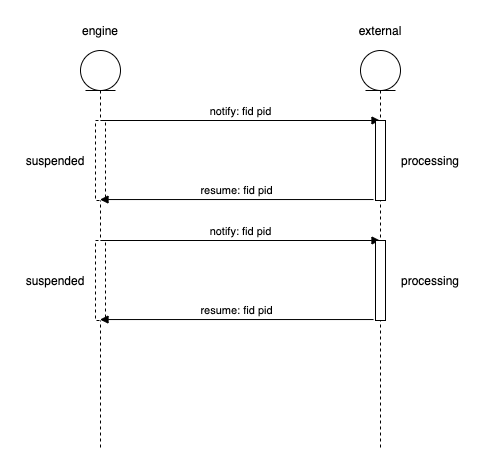
举个例子,下面的代码首先注册了两个 RPC 服务,然后定义了'quality'的并行的流程,分别是 Lint 和 Review,Review 这里返回的状态‘suspended’,是因为 Review 是需要手动执行的,这里就是一个挂起的异步操作:
Engine.externalFnsProvider.registerFn("Basic", "0.0.1", "pass", async () => ({ code: NodeStatus.Succeeded,}));
Engine.externalFnsProvider.registerFn("Basic", "0.0.1", "async", async () => ({ code: NodeStatus.Suspended,}));
(async function() {const w = workflow({ name: "Basic", version: "0.0.1", }) .next( parallel({ name: "quality" }) .add({ name: "Lint", proc: { endpoint: "fn:pass", }, }) .add({ name: "Review", proc: { endpoint: "fn:async", }, }) ) .settle();
await engine.exec(w);})();上面的代码执行将会产生下面的数据结构:
{ "fid":"d5b27302-442e-4a12-a0ce-93eb6036a798", "workflow":{ "name":"Basic", "version":"0.0.1", "desc":"", "status":"running", "isLocked":true, "nodes":{ "Lint":{ "type":"single", "name":"Lint", "status":"succeeded", "isTerminal":false, "proc":{ "endpoint":"fn:pass", "parameters":{
}, "parent":"Lint", "pid":"0aa64a29-c69a-4bc3-8bbc-073ea6432d2b", "result":{ "code":"succeeded" } }, "parent":"quality" }, "Review":{ "type":"single", "name":"Review", "status":"suspended", "isTerminal":false, "proc":{ "endpoint":"fn:async", "parameters":{
}, "parent":"Review", "pid":"3671a0c0-98c6-4ef0-8921-c62a16cacfb7", "result":{ "code":"suspended" } }, "parent":"quality" }, "quality":{ "type":"parallel", "name":"quality", "status":"suspended", "isTerminal":true, "sub":[ "Lint", "Review" ], "strategy":"all_of", "prev":"Basic" } }, "next":"quality", "reach":"quality" }, "runnings":[ "0aa64a29-c69a-4bc3-8bbc-073ea6432d2b" ], "extra":{
}}在执行后的数据结构里,因为 Lint 是直接通过的,所以 Lint 节点的状态是'succeeded',Review 是一个挂起操作,所以 Review 的状态是'suspended',当其他用户进行 Review 通过的动作后, 就会通知流程引擎继续根据这个数据结构进行后续的执行。流程引擎的执行其实就是遍历这个数据结构调用服务的过程。
部署能力的抽象
针对不同应用类型的发布,我们定义了如下接口,这样我们就可以通过不同的实现来解耦掉部署服务的调用,这样是面向对象中常见的操作方式。
DeployProvider 定义:
interface IDeployProvider { // 发布 publish(params: ProviderEnv): Promise<void>;
// 获取发布状态 getStatus(params: ProviderEnv): Promise<ProviderStatus[]>;
// 获取部署日志 getLog(params: ProviderEnv): Promise<ProviderLog[]>;
// 回滚 rollback(params: ProviderEnv): Promise<void>;
// 其他公共抽象方法 ...}针对静态部署我们实现上述定义的接口:
H5 部署:
class SdpStDeployProvider implements IDeployProvider {
sdpRpc: SdpRpc;
// 发布 async publish(params): Promise<any> { // 简化逻辑 this.sdpRpc.projectPublish({ ... }) }
// 实现其他抽象接口...}这样我们就可以通过统一的部署服务来屏蔽不同应用的差异:
部署服务:
class DeployService {
async publish(params) { const { appId } = params; const provider = this.getProvider(appId); return provider.publish({ ... // 省略参数 }); }
// 获取 Provider async getProvider(appId) { const appType = this.getAppType(appId); switch(appType){ case 'Web': return this.sdpStDeployProvider; case 'NodeJS': return this.alpacaDeployProvider; case ... } }}开放能力
Febase 除去为自身提供服务外,业务还有一些基于 Febase 本身的扩展,比如云音乐桌面端的日志平台,Febase 充当了元数据信息管理的角色;第二个是每个业务组或多或少有一些特定的业务诉求,这些诉求不适合通过公共的产品方式来承载,比如对于活动的监控,只是其中某个业务组的诉求,所以 Febase 通过开放能力来支持业务的二次开发,既降低了成本,又避免了多烟囱的产生。
开放网关
对第三方平台,使用特殊请求头。通过白名单的方式来指定开放接口,然后在每个业务逻辑实现中,根据请求来源,单独地做权限校验。过去这种职责不单一、面向过程式的鉴权方式,将会导致开放接口难以维护和扩展,无法承载多变的业务对 Febase 底层能力开放的诉求,我们的解法是提供声明式的鉴权配置及多消费场景的统一认证机制,抽取单独的接口网关。

在后端的接口中,用声明式的方式描述接口所需的最低权限。在应用启动时,会收集全部的路由 + 权限声明,并存入数据库中。并将路由与权限信息注册至网关。由于路由与权限信息都做了入库,所以也可以在管理后台中,对接口的权限做配置管理。对于多消费场景,统一使用 Febase 派发的用户 Token 进行认证和鉴权。只有满足权限要求的请求,才会打到 Febase 后端。
单独的网关设计还有另外一个好处,就是第三方应用同样可以将接口注册到网关上,使用统一的鉴权服务,比如下方的云鹿素材就属于业务组维护的第三方应用:
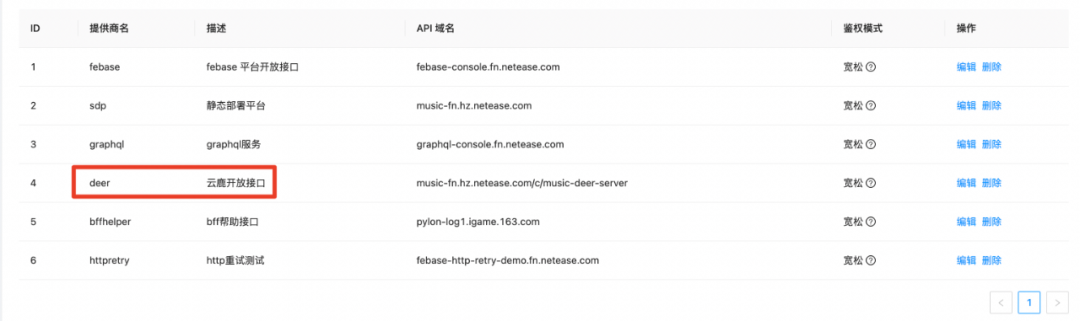
微前端接入
除去接口外,Febase 在产品侧提供了多个维度的自定义能力,分别是业务组 - 应用 - 概览三级维度,下图描述了 Febase 提供的三个扩展点:
业务组维度用户可以在业务组维度插入多个自定义的页面,用来管理团队各项技术建设。

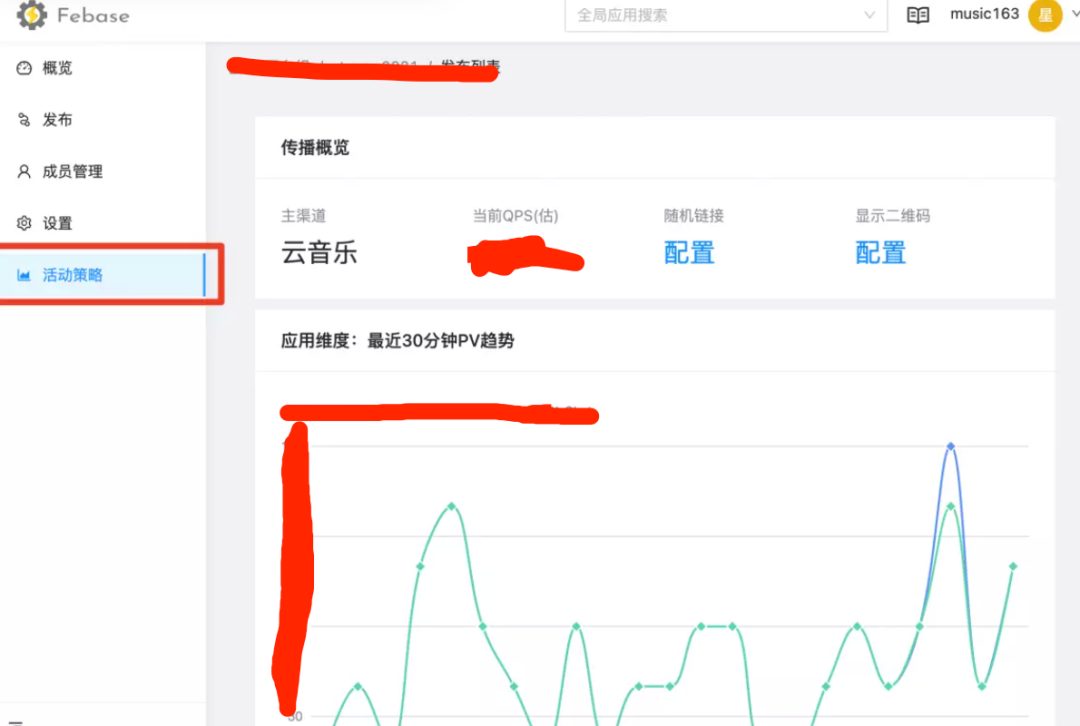
应用维度
同样在应用维度,针对应用的特殊场景也可以定义,比如下方的活动策略就是专门为云音乐的年度报告所创建的,也是业务组基于 Febase 的开放能力自行开发的。
概览维度
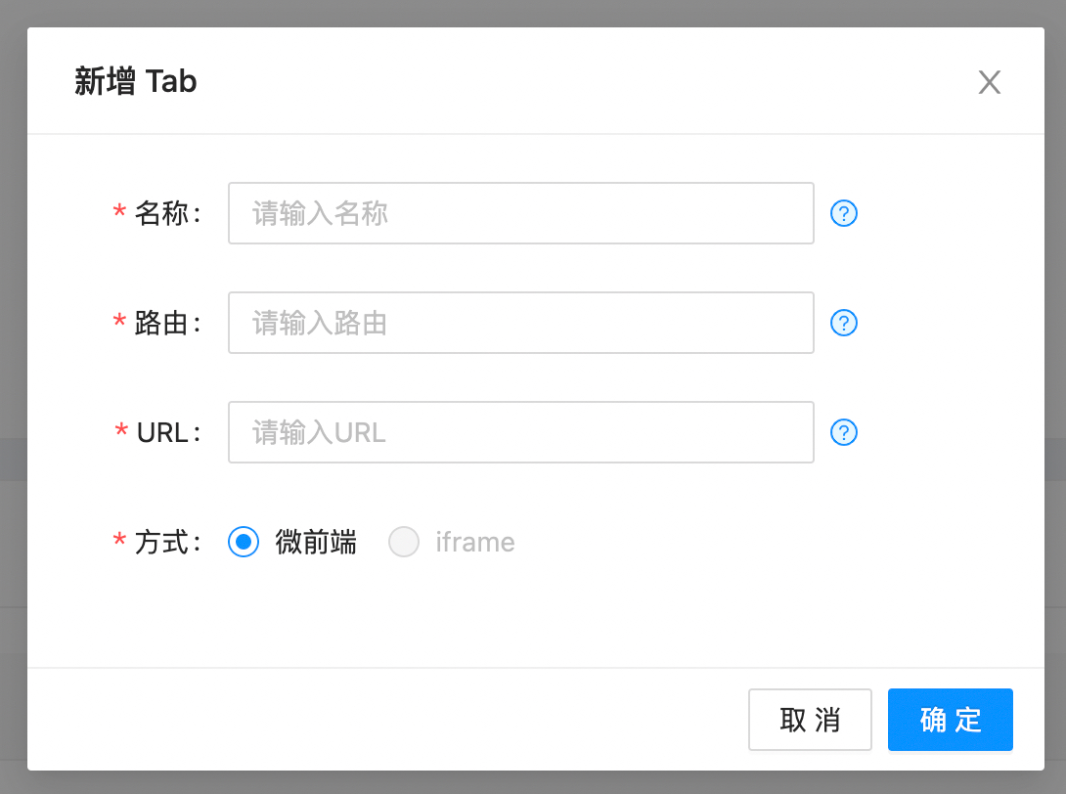
用户只需要在设置页面填写如下信息就可以导入一个页面,平台支持微前端和 iframe 两种方式:
其核心是借助了 qiankun 的能力,只需要根据设定的 URL 来动态加载对应的资源然后渲染即可,关键代码如下:
import { loadMicroApp, MicroApp } from 'qiankun';
function MicroAppComponent({ name, title, entry, container, customProps = {}, match,}: MicroAppProps & RouteComponentProps) { const app = useRef<MicroApp>(); const [err, setErr] = useState<Error | null>(null);
useEffect(() => { app.current = loadMicroApp( { name, entry, container: `#${container}`, } as any, { sandbox: { experimentalStyleIsolation: true }, } );
return () => { if (app?.current) { app.current!.unmount(); app.current = undefined; } }; }, [container, name, match.url, customProps, entry, title]);
return ( <div id={container} /> );}总 结
最终我们通过 Febase 使用联合与开放的策略成功统一了云音乐的前端基础设施,覆盖音乐事业部所有前端研发人员,日均构建次数 350+,活跃应用 220+;也提供了自定义的扩展能力,帮助业务最小成本地接入到 Febase 平台。后续针对应用类型的扩展也变得非常简单,比如我们针对 GraphQL 提供的支持,基本复用了当前的平台能力。
如果你也面临同样的问题与挑战,期望通过一种非常优雅的方式来解决,希望这篇文章的过程和实现能够带给你一些启发。最后也感谢蚂蚁提供的 Kitchen 插件,在产品交互设计上给我们提供了很多灵感。
作者简介
葛星,网易云音乐前端开发专家,前端公共技术团队负责人,网易集团大前端委员会委员。十余年从业经历,曾是阿里集团最大的中后台设计系统工厂 Fusion Design 核心架构师,从前端工程化到全栈技术体系,以及前端智能化均有所涉猎。
在前端规模化 UI 生产领域及架构领域有深入的研究,包括但不限于设计系统、应用框架、低代码搭建、微前端等。
今日好文推荐
Node.js 之父着急宣布:Deno 将迎来重大变革,更好地兼容 Node 和 npm 包
操作系统的“冷板凳”要坐多久?万字长文解读 16 年开源老兵的坚持
我认为前端的职责可能需要重新划分
传美的被勒索千万美元,连夜天价聘请安全专家;软银抵押一半阿里股票,孙正义:“为过去贪图暴利感到羞愧”;谷歌数据中心爆炸 |Q 资讯
活动推荐
将于 9 月 15-16 日举办的 GMTC 全球大前端技术大会(北京站)上,葛星担任了「大前端设计协同」专题的出品人,探索大前端如何与设计进行更好的协同,减少设计与大前端的沟通成本,提升双方的协作效率,目前已上线 2 个议题,分别是《消除动效研发成本:腾讯 PAG 动效解决方案》、《网易云音乐基于 C2D2C 的无损设计协同》。
此外,会议还设置了 TypeScript、跨端技术选型、前端 DevOps 实践、IoT 动态应用开发、低代码等共 12 个专题,50+ 大厂技术专家现场分享,点击底部【阅读原文】查看更多精彩内容,感兴趣的同学联系票务经理:+86 13269078023
