导语:公司项目,越来越多的系统在计划上云。如何监控云上的系统运行,是每个系统上云的过程中都会碰到的一个问题。在这里,我们以公司的某个项目为例,向大家详细阐述该项目上云后的日志监控方案,详细讲解如何通过ELK集群,实现每天百G日志的监控。
此项目原本是一个包含众多业务流的一个 APP 监控系统,在迁移到腾讯云之后,希望接入更多的业务,日志监控压力也随之剧增,每天的日志数量将达到百 G 以上,为满足这个项目的日志监控需求,特意在腾讯云的 kubernetes(K8s) 上配置了一套 ELK 集群。
1.ELK 系统介绍
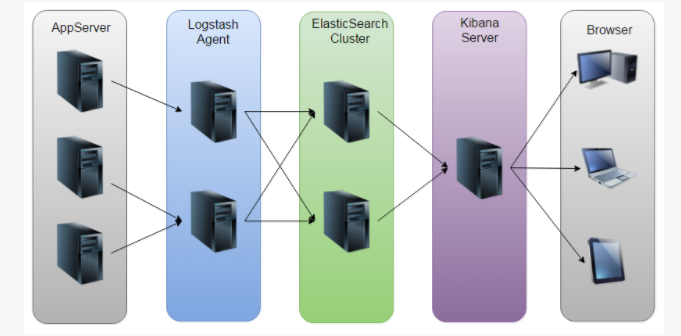
我们在 SNGAPM 项目这个配置的 ELK 系统主要包含四个部分 filebeat,logstash,elasticsearch 以及 kibana。其中
- filebeat 主要负责日志的收集,能自动感知日志文件中增加的 log 条目。
- logstash 主要负责日志文件的转发,并且在转发过程中对日志进行过滤和整理。
- elasticsearch 可以看作一个高效的集群化的数据库,可以直接通过 url 对其进行访问,在 ELK 中,主要负责 ELK 的存储,也是整个ELK 系统的核心。
- kibana 可以看作 elasticsearch 的一个前端页面,其将用户的操作转化为 elasticsearch 的查询指令,并将从 elasticsearch 查询到的数据进行图形化展示。
2. ELK 集群预览
在物理机上,可以通过多台服务器构建一个 ELK 的集群,在腾讯云上,配置 ELK 集群的另一种方式就是通过 kubernetes 管理一个包含多个 pods 的 ELK。
3. ELK 集群配置
集群化的 ELK 系统的关键就是配置集群化的 elasticsearch 系统,通过配置 elasticsearch 的集群,实现海量日志的存储,和快速查询。
配置 elasticsearch 集群,我们主要参考了 github 上的一个样例 kubernetes-elasticsearch-cluster。
我们将 elasticsearch 节点,分为 master, client, data 三种类型,分别负责不同的任务,其中
Master节点 - 只复杂集群的管理,不存储日志数据,也不接受 HTTP 请求Client节点 - 主要负责接受 HTTP 请求,不存储日志数据Data节点 - 主要负责数据的存储,不接受 HTTP 请求
在这,我们给出我们的配置文件供大家参考和借鉴
首先,给出 elasticsearch 的集群配置方法
cluster: name: ${CLUSTER_NAME}node:
master: ${NODE_MASTER}
data: ${NODE_DATA}
name: ${NODE_NAME}
ingest: ${NODE_INGEST}
max_local_storage_nodes: ${MAX_LOCAL_STORAGE_NODES}network.host: ${NETWORK_HOST}
path:
data: //
logs: //bootstrap:
memory_lock: truehttp:
enabled: ${HTTP_ENABLE}
compression: true
cors:
enabled: ${HTTP_CORS_ENABLE}
allow-origin: ${HTTP_CORS_ALLOW_ORIGIN}
discovery:
zen:
ping.unicast.hosts: ${DISCOVERY_SERVICE}
minimum_master_nodes: ${NUMBER_OF_MASTERS}
其次是配置 kibana,只需要提供 elasticsearch 的访问 url,就能直接与 elasticsearch 进行直接交互(如果配置了 x-pack 插件,还须提供相应的用户名以及密码才能访问)。
server.host: "0.0.0.0"elasticsearch.url: "http://elasticsearch.default.svc.cluster.local:9200"
elasticsearch.username: ""
elasticsearch.password: ""
最后是配置 logstash 以及 filebeat
在 filebeat 中设置日志文件的路径,并在输入的日志数据上加上标签,方便 logstash 对日志进行分类,对不同的日志类型进行不同的处理。
filebeat.prospectors:
- input_type: log
paths:
- /.log
- /.log
document_type: json_log
tags: ["json-log", "itrans"]output.logstash:
hosts: ${LOGSTASH_HOSTS:?No logstash host configured. Use env var LOGSTASH_HOSTS to set hosts.}
logging.level: info
logging.files:
path: /home
name: filebeat.log
在这里,logstash 根据日志的标签,对不同类型的日志,执行不同的处理(如果配置了 x-pack 插件,还须提供相应的用户名以及密码才能访问)。
input {
beats {
port => 5043
congestion_threshold => 60
}
}filter {
if "json-log" in [tags] {
json {
source => "message"
remove_field => [ "message"]
}
mutate {
replace => { "type" => "json-log" }
}
}
}
output {
if "json-log" in [tags] {
elasticsearch {
hosts => ["elasticsearch:9200"]
manage_template => false
index => "%{label}-%{ YYYY.MM.dd.HH}"
user => ******
password => ******
}
} else {
elasticsearch {
hosts => ["elasticsearch:9200"]
manage_template => false
index => "unlabeled-%{ YYYY.MM.dd.HH}"
user => ******
password => ******
}
}
}
4.在 Kubernetes 上运行所需的 yaml 文件
想要实现 ELK 集群在 Kubernetes 上的运行自然少不了相应的 yaml 文件,我们使用的 yaml 文件主要参考了 kubernetes-elk-cluster、kubernetes-elasticsearch-cluster等仓库。