说明
本文描述问题及解决方法同样适用于 腾讯云 Elasticsearch Service(ES)。
背景
客户自建近100个ES集群,服务于多个核心重要业务。随着业务日益增长、需求各有所异、集群容量利用率参差较大、部分混布集群资源成本难以继续细分,出于人员不足,运维压力、增强稳定性保障、优化利用率和成本等角度考虑,计划将全部自建ES集群基于业务属性、重要等级等方向按批次迁移至 腾讯云 Elasticsearch Service(ES)。
问题
问题一:Shard Lock
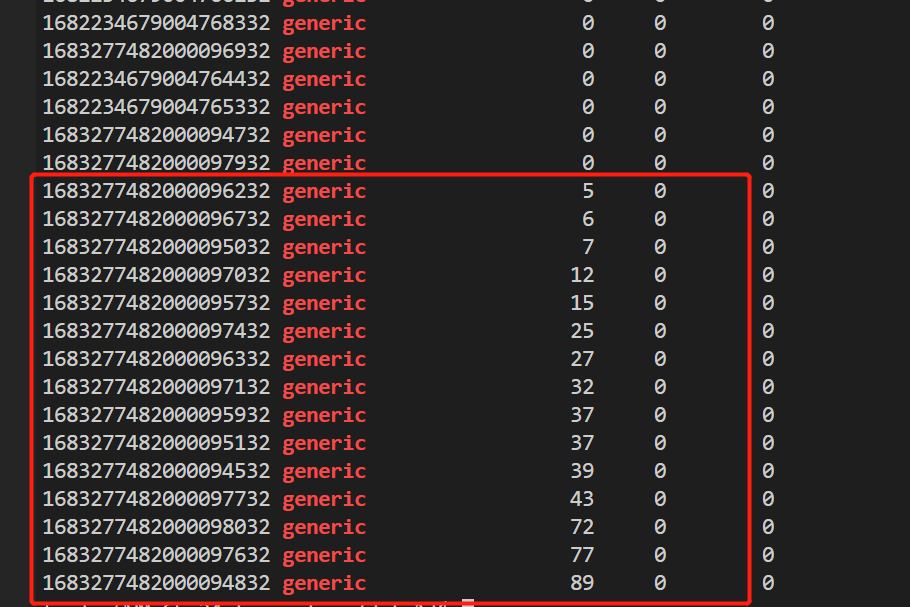
集群缩容时,有部分分片无法搬迁,恢复进度到一定百分比后,不再继续执行

直到shard recovery任务超时(30min)
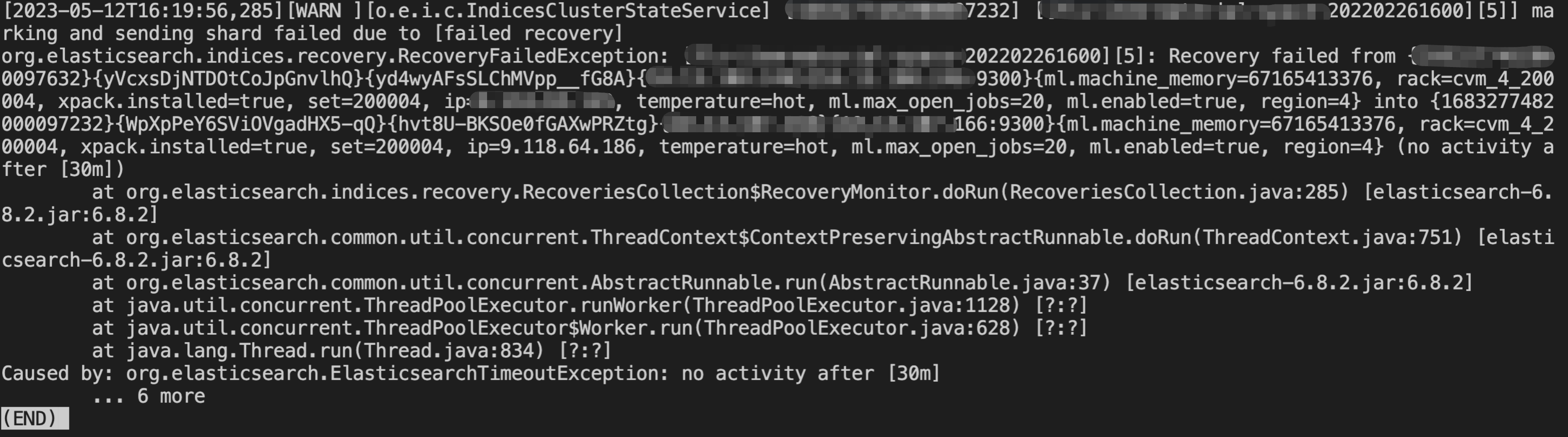
期间有待恢复的分片出现 failed to obtain shard lock 报错
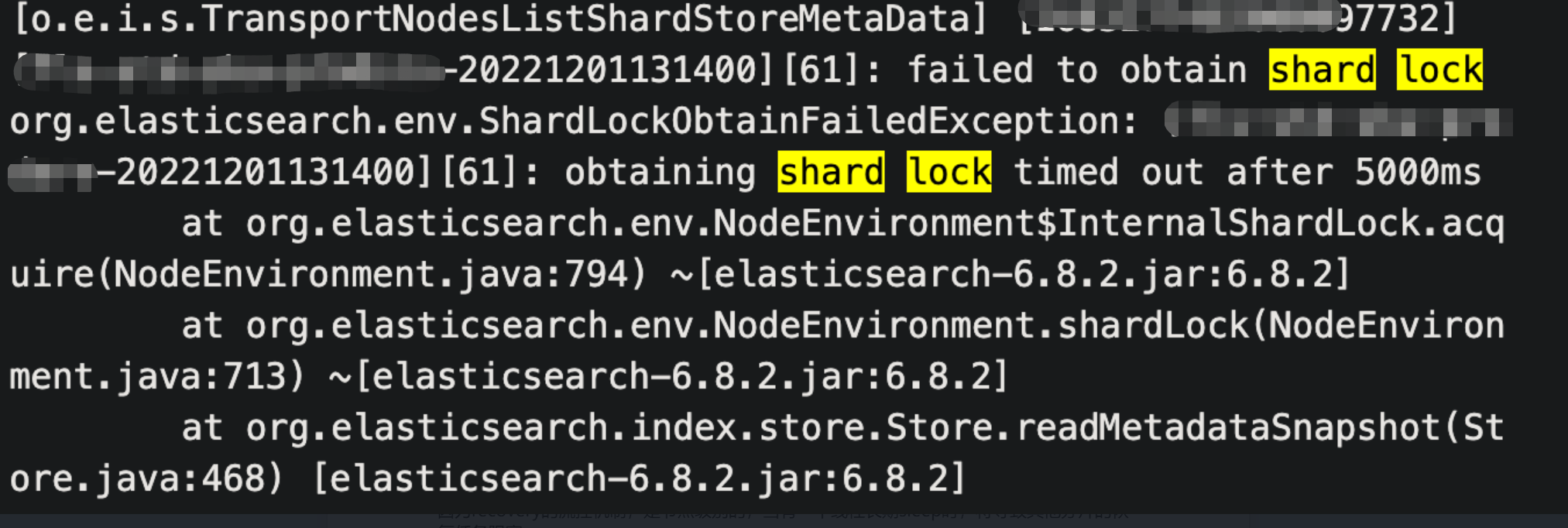
原因分析
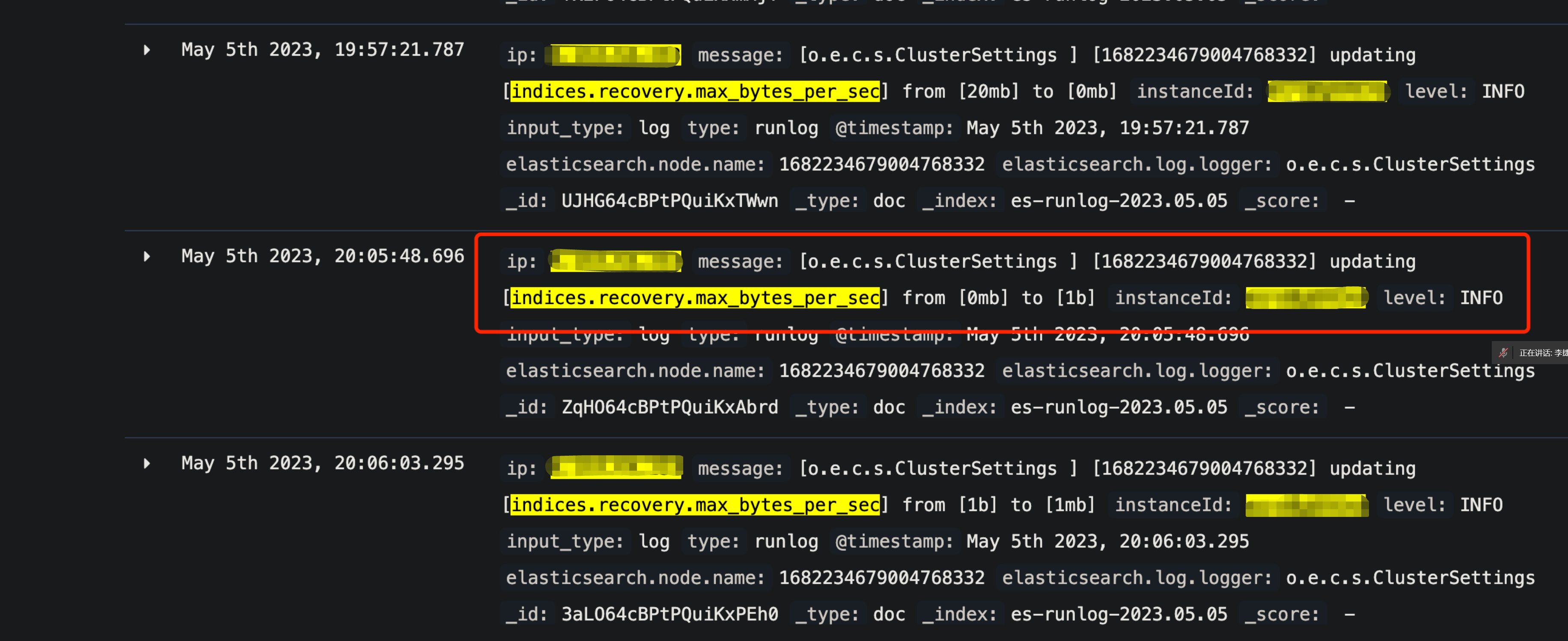
Recovery 的带宽限流改成过1b,这将导致 recovery 线程长期流控,sleep 时间有累积效应,很久无法退出。
由于 recovery 的流控机制,是节点级别的,当有一个线程长期 sleep 时,将导致其他分片的恢复任务阻塞。
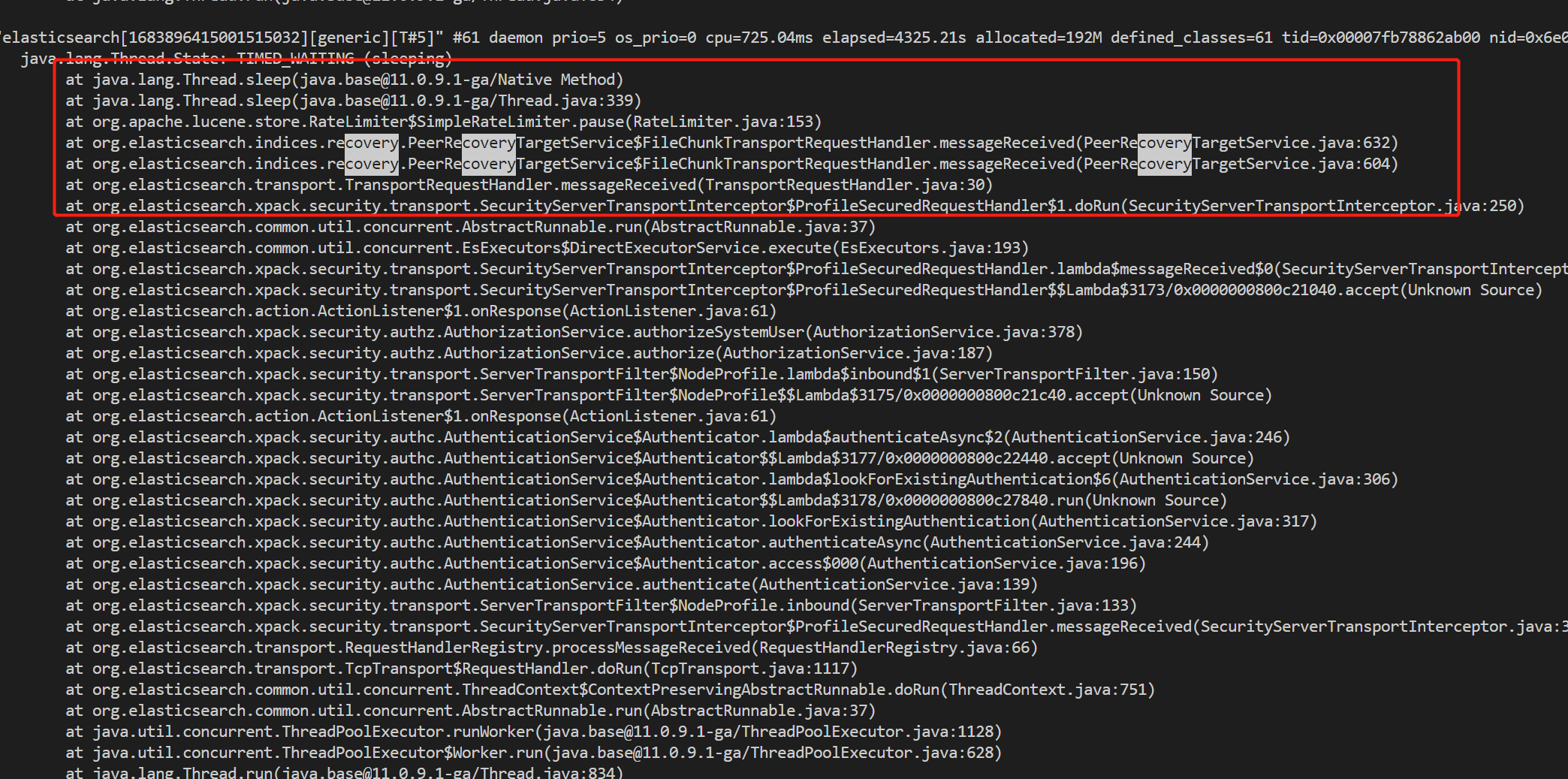
最终导致部分节点 generic 线程被长期占用,无法释放。

解决方案
短期方案
重启generic 线程被长期占用的节点,释放 recovery 资源,集群恢复 green
长期方案
内核级别干预 indices.recovery.max_bytes_per_sec
- 腾讯云 ES 内核添加限制,避免 max_bytes_per_sec 设置过小(1MB)
- 腾讯云 ES 智能诊断系统,发现 max_bytes_per_sec 设置过小时,自动纠正
问题二:RT上涨
集群偶现部分节点长时间gc,无法恢复,导致查询时延上涨
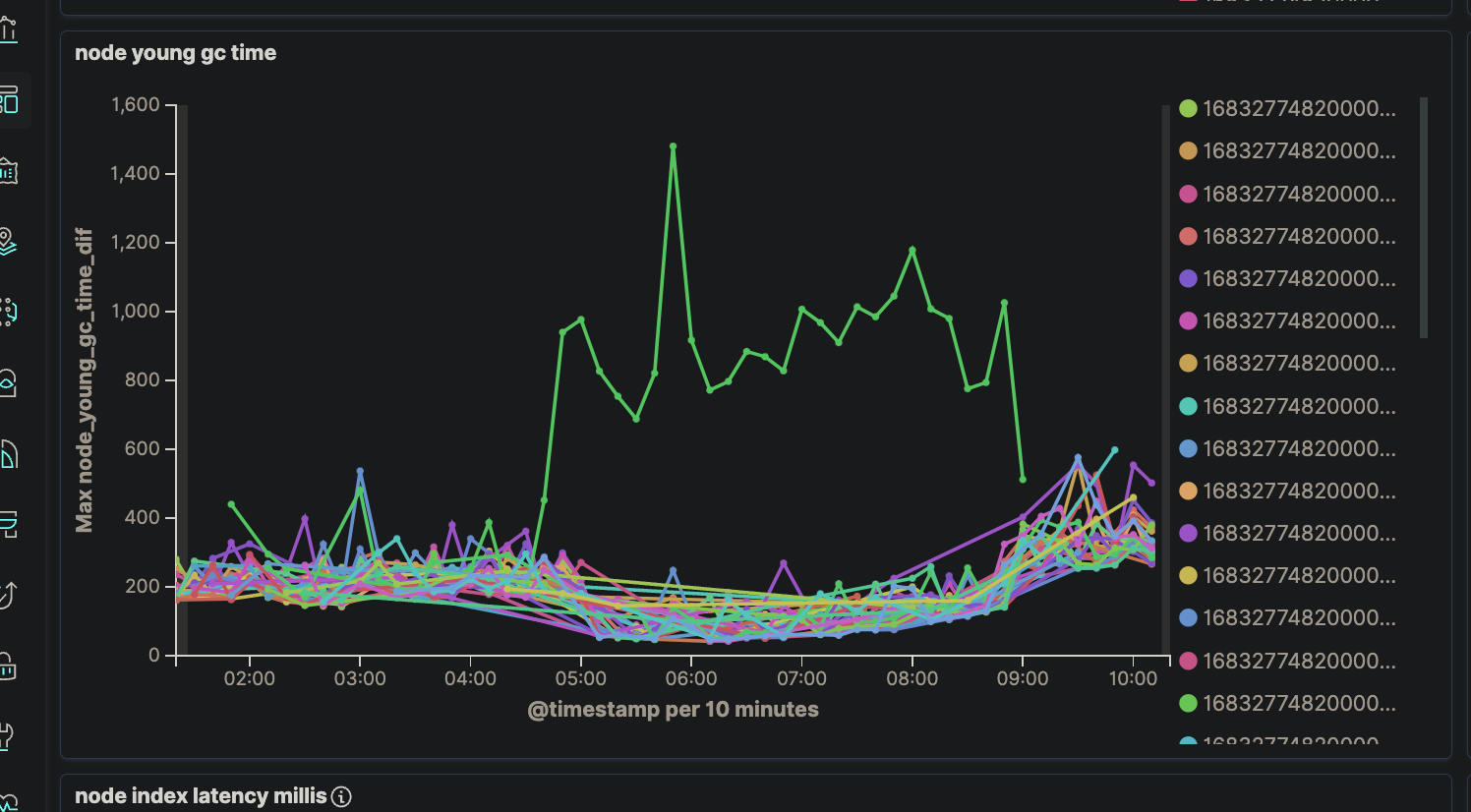
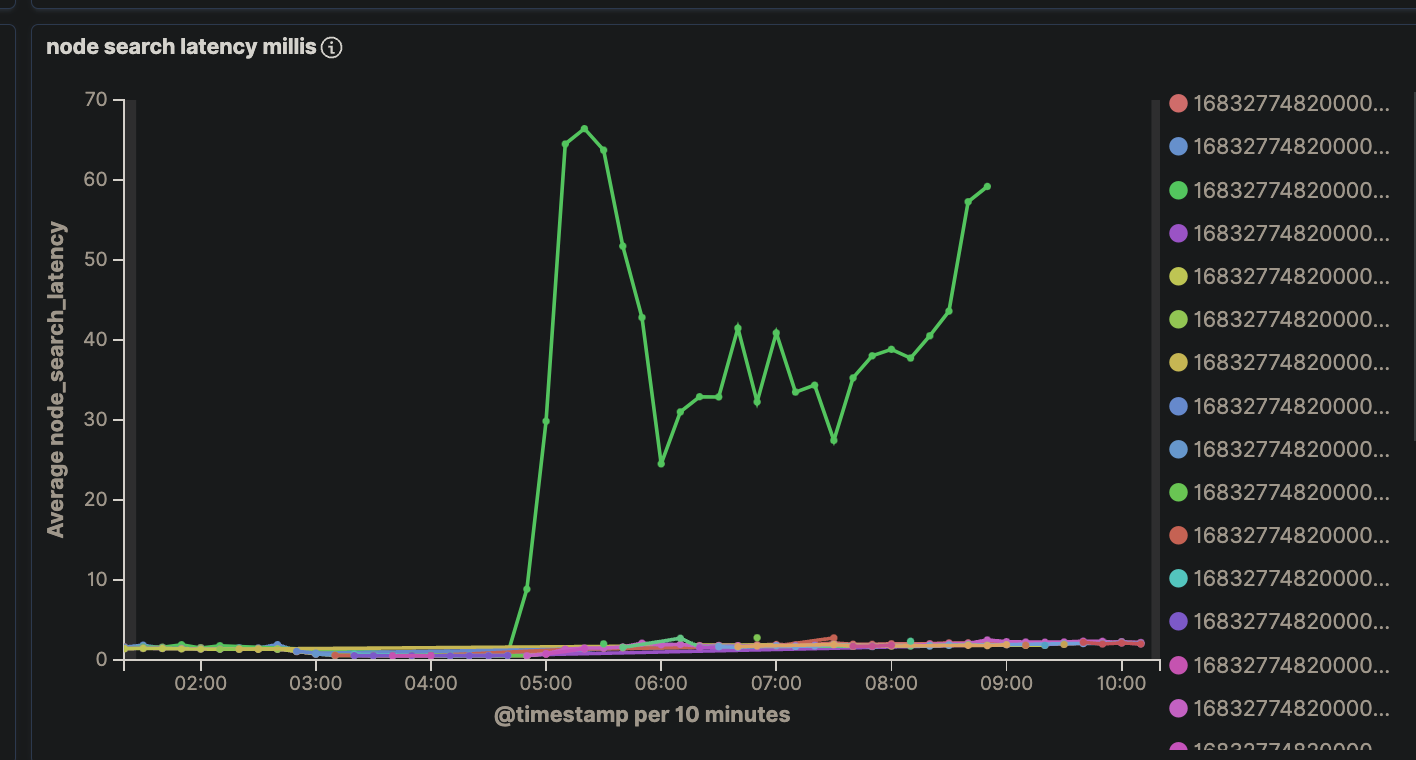
原因分析
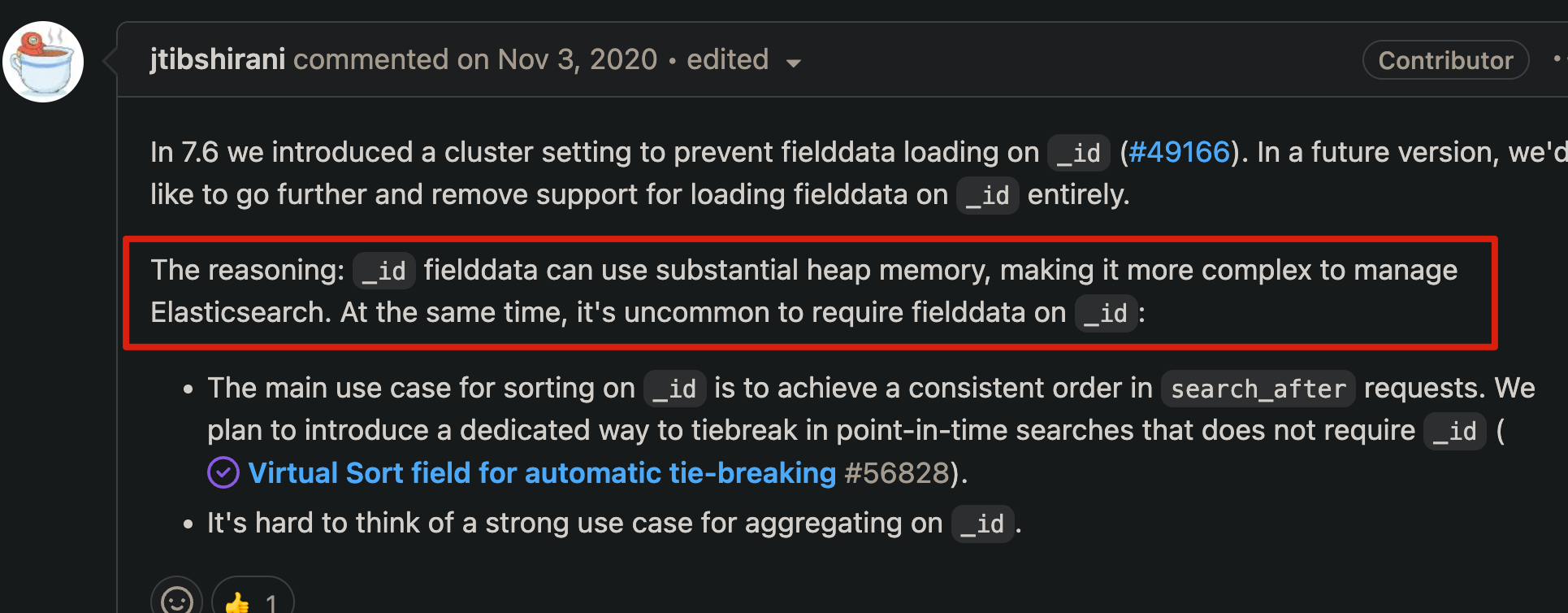
- fielddata cache 使用过量内存
故障节点有大量 fielddata cache 在等待 lock 的线程,导致查询线程的阻塞

从保存现场的dump 内存分析看,也是 fielddata 占据大量内存
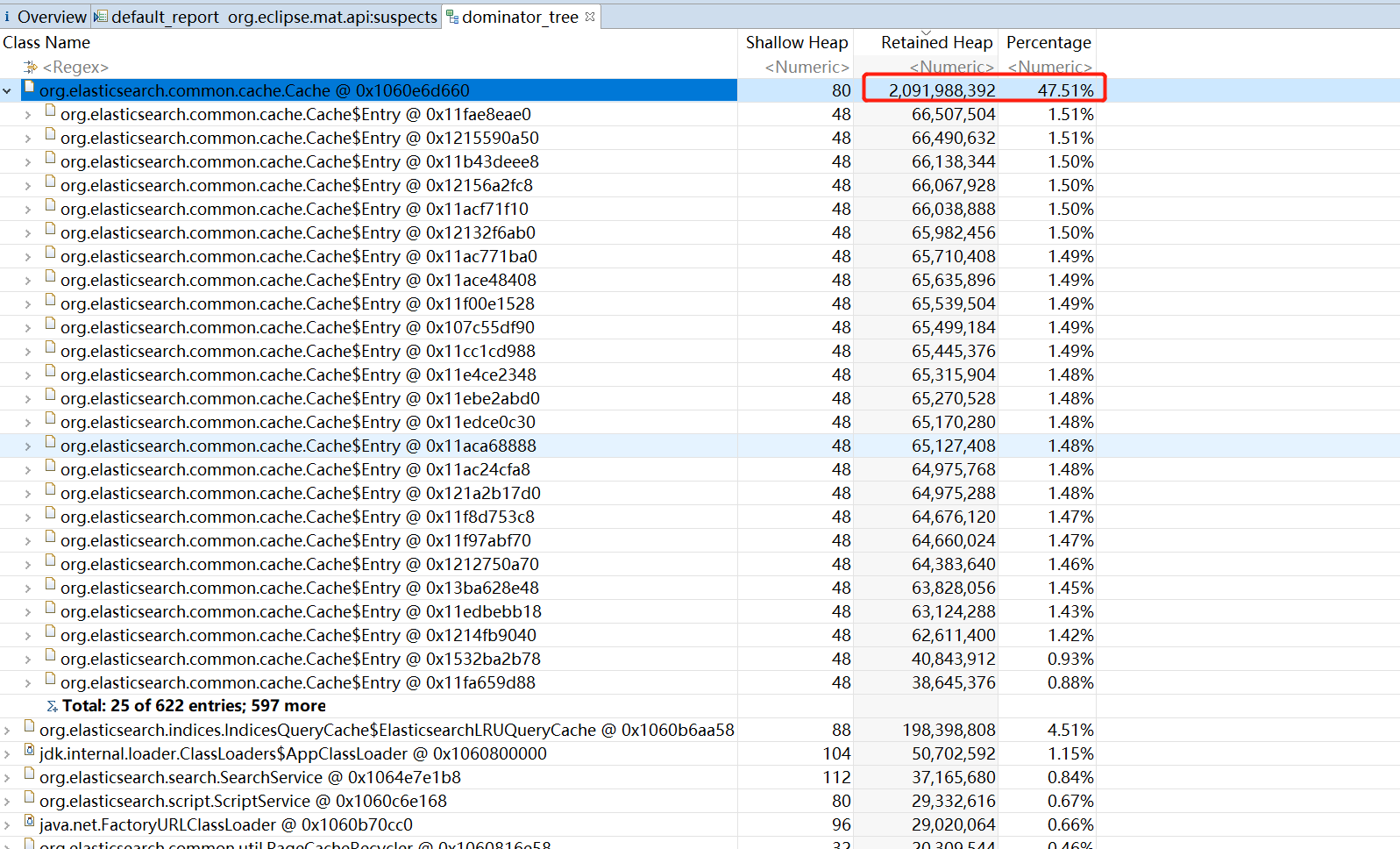
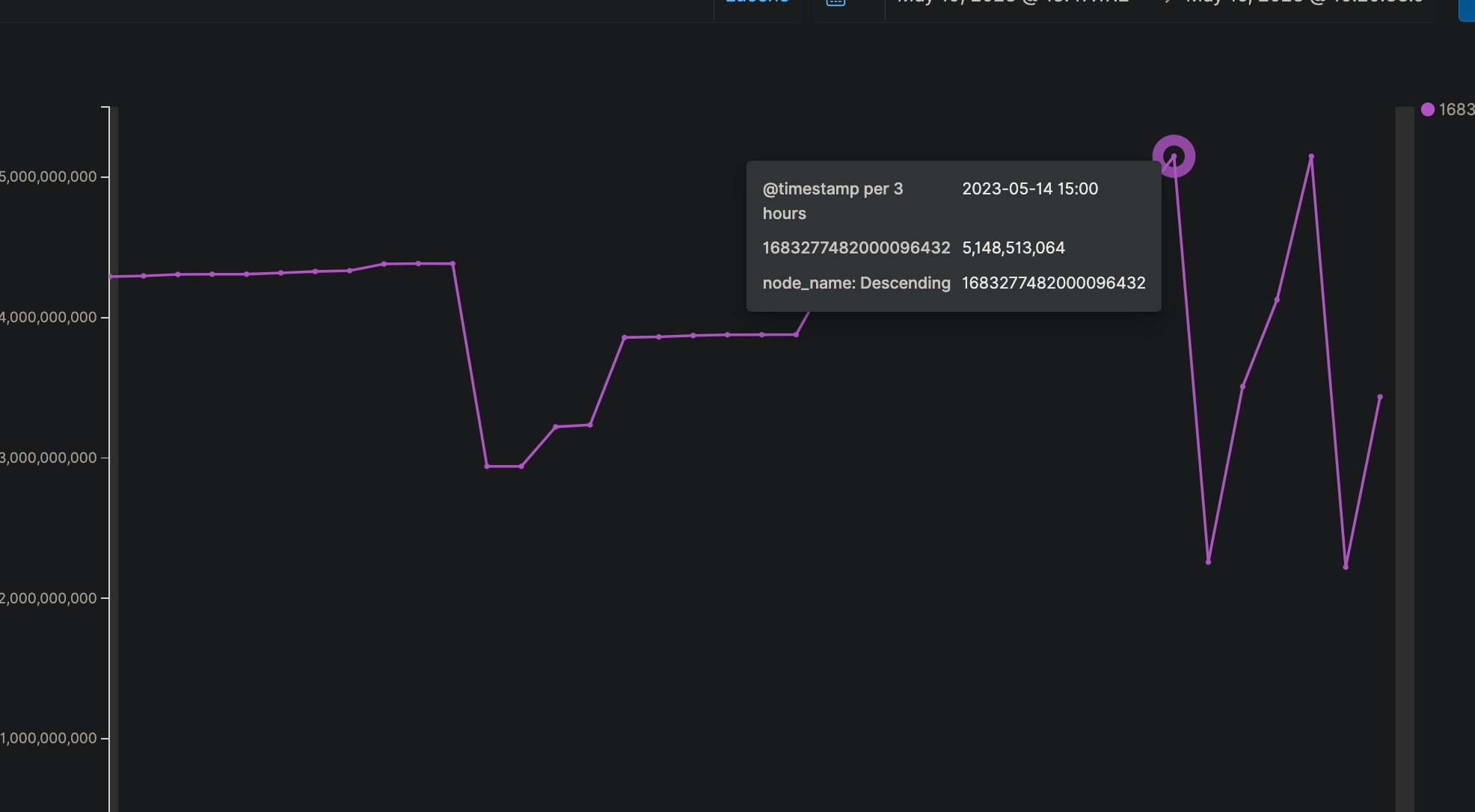
结合当时节点的慢日志分析,原因是类似下面的查询语句,对 _id 字段做排序,使用了大量的 field data,占用 jvm 堆内存

由于 _id 字段底层存储时只存储store field(行存),不存储 doc value(列存)。
而对其做排序、聚合时,需要使用列存,因此es会在heap内存中构建列存,使用大量的 fielddata。从而导致了field data线程卡住和使用过量内存。
- 节点间负载不均
还有一个原因是,节点直接负载不均衡,不同节点查询速率差异有2倍多
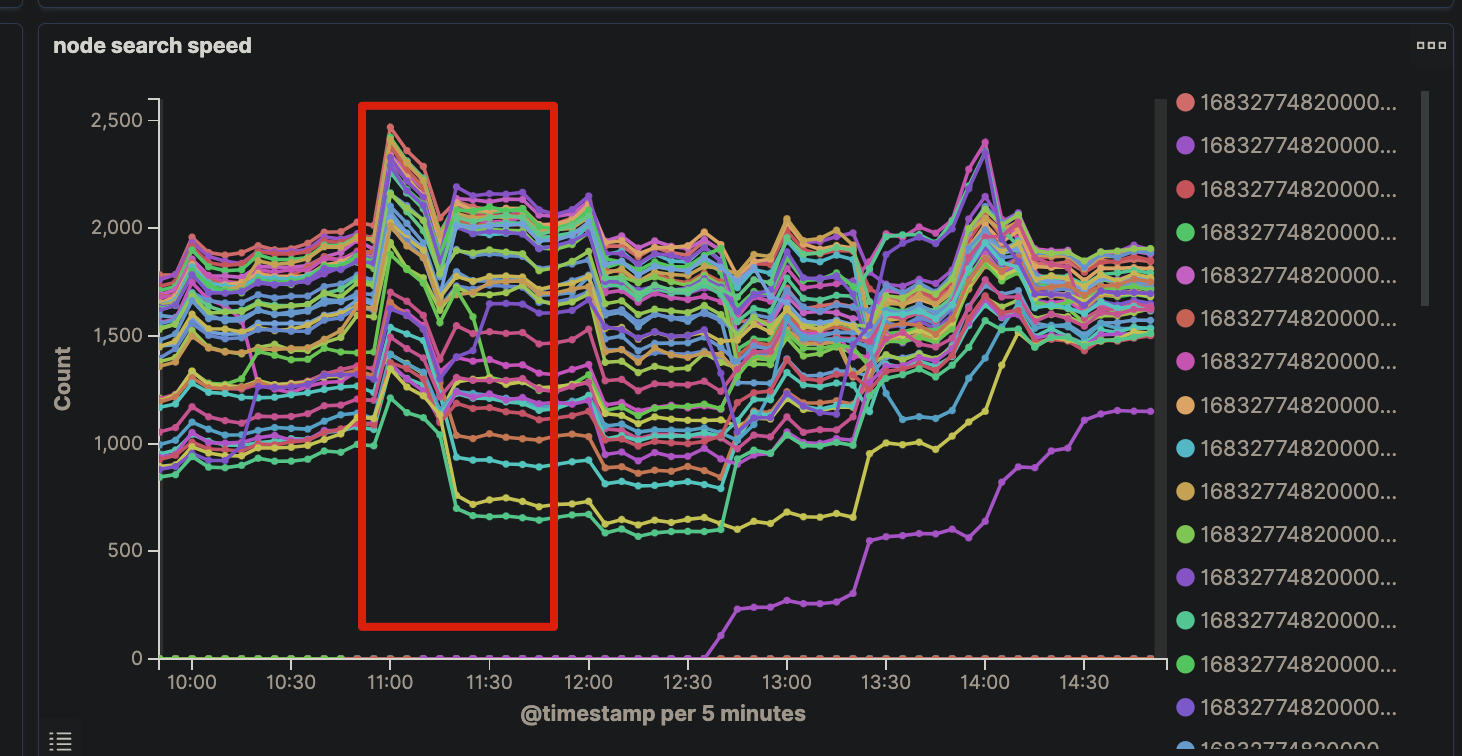
查询负载的不均,也导致了节点之间 fielddata 内存使用量不均,加重了问题的产生
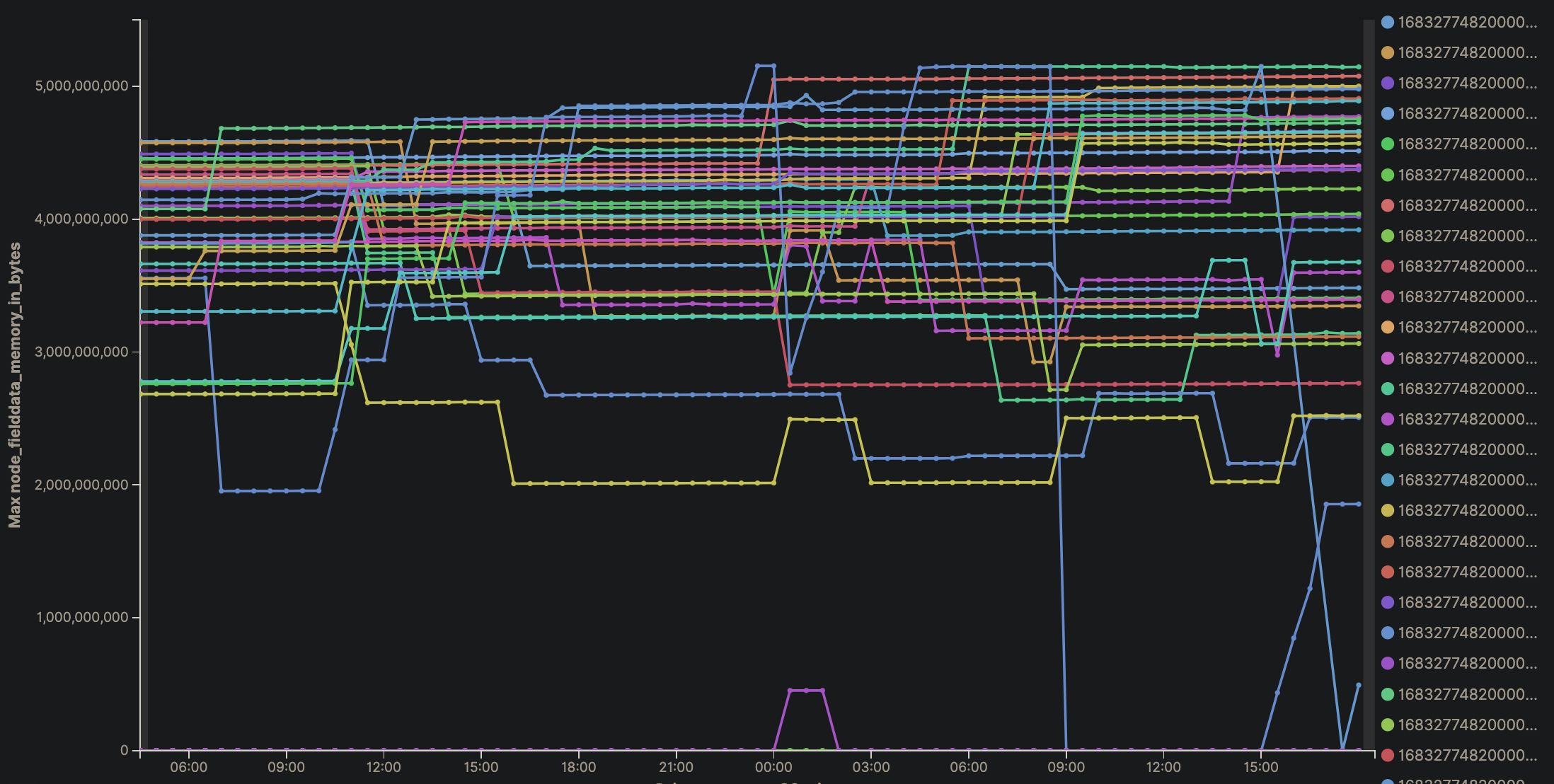
以一个出问题的节点为例,是在fielddata内存打满后,出现的问题:
优化方案
- 优化查询,使用其他字段代替 _id 来排序
7.6 之后版本的es,可以通过参数设置,不允许对 _id 字段做排序和聚合,避免此类问题。
相关issue:Remove on-heap fielddata. · Issue #64612 · elastic/elasticsearch · GitHub
长期方案
替换sort字段。
- 负载不均
集群的节点之间,分片数不均,导致负载不均
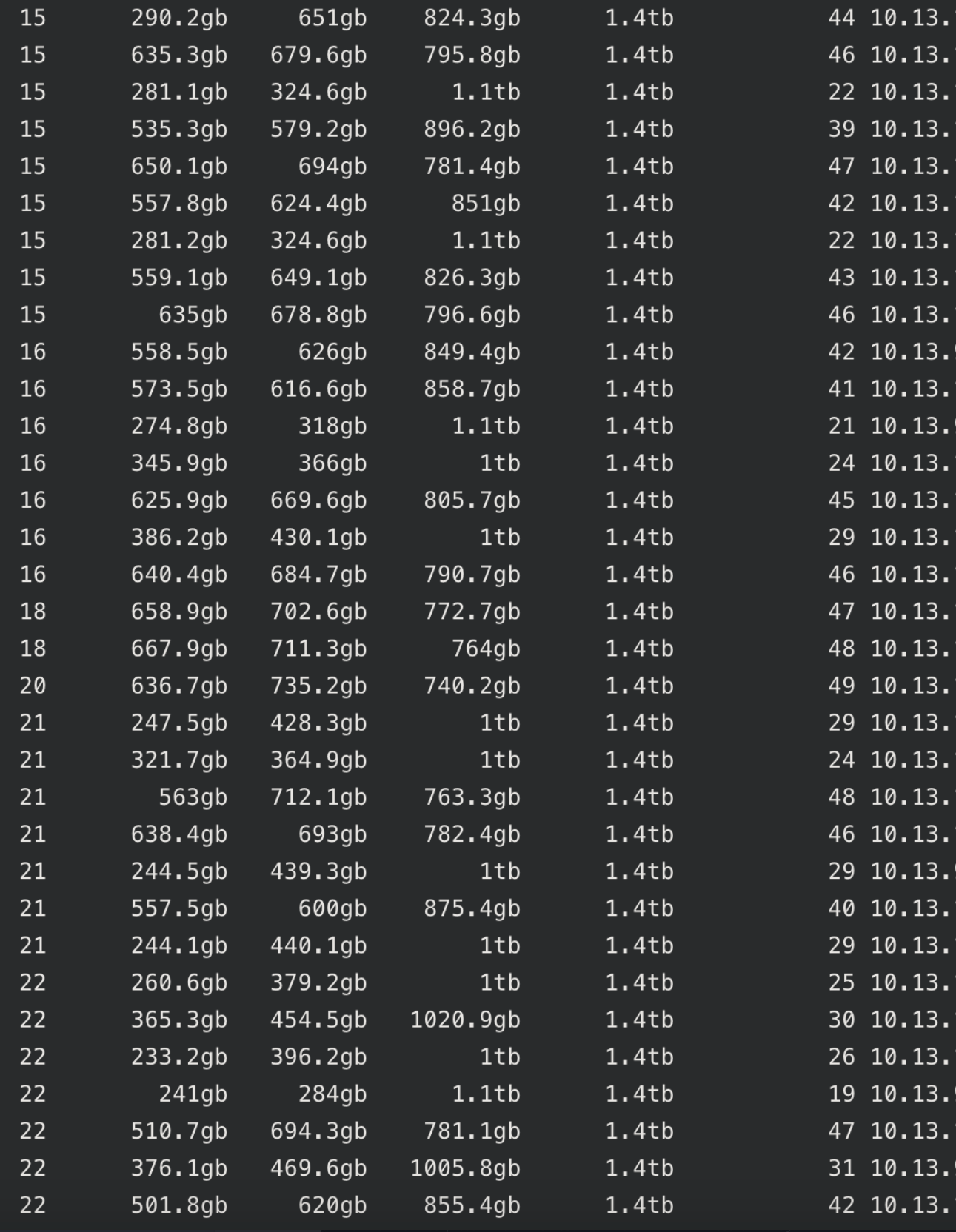
原因是集群中存在一些较大的分片(250GB+),使得某些节点的磁盘使用率超过水位线,导致节点间分片数不均匀


- 解决方案
扩容磁盘后,集群开始均衡,节点之间的查询量、fielddata趋于均衡
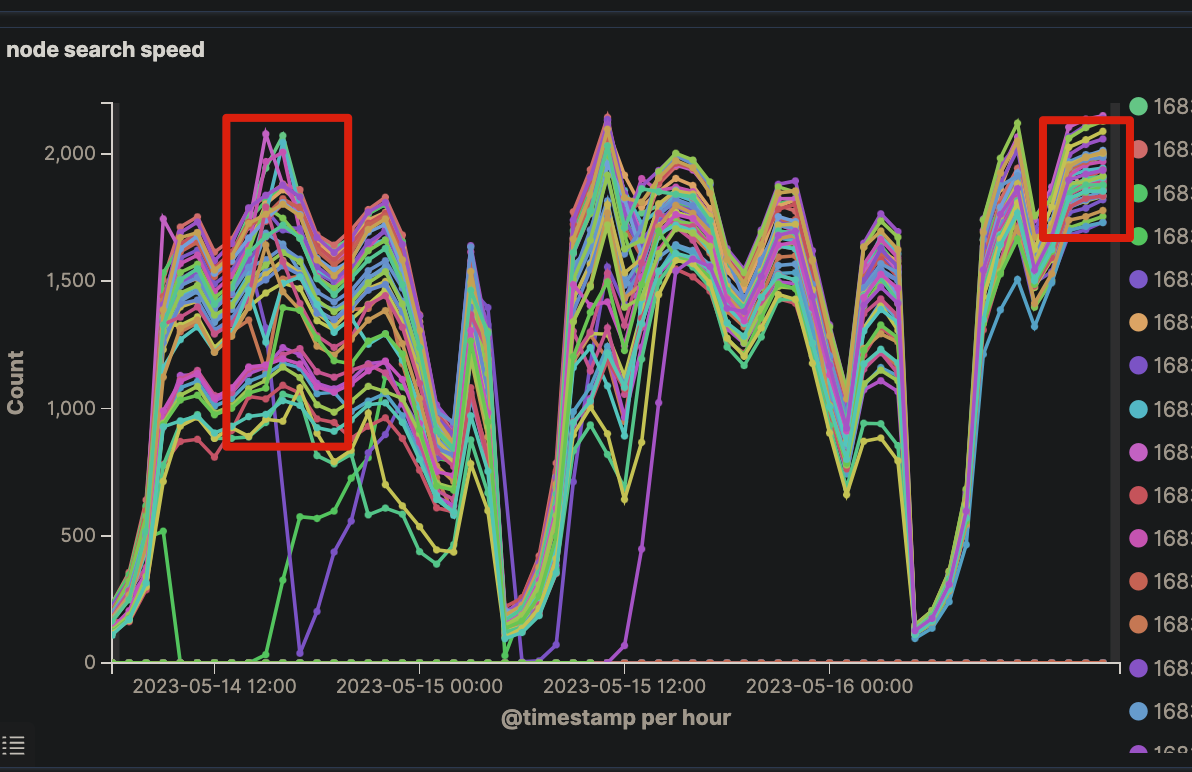
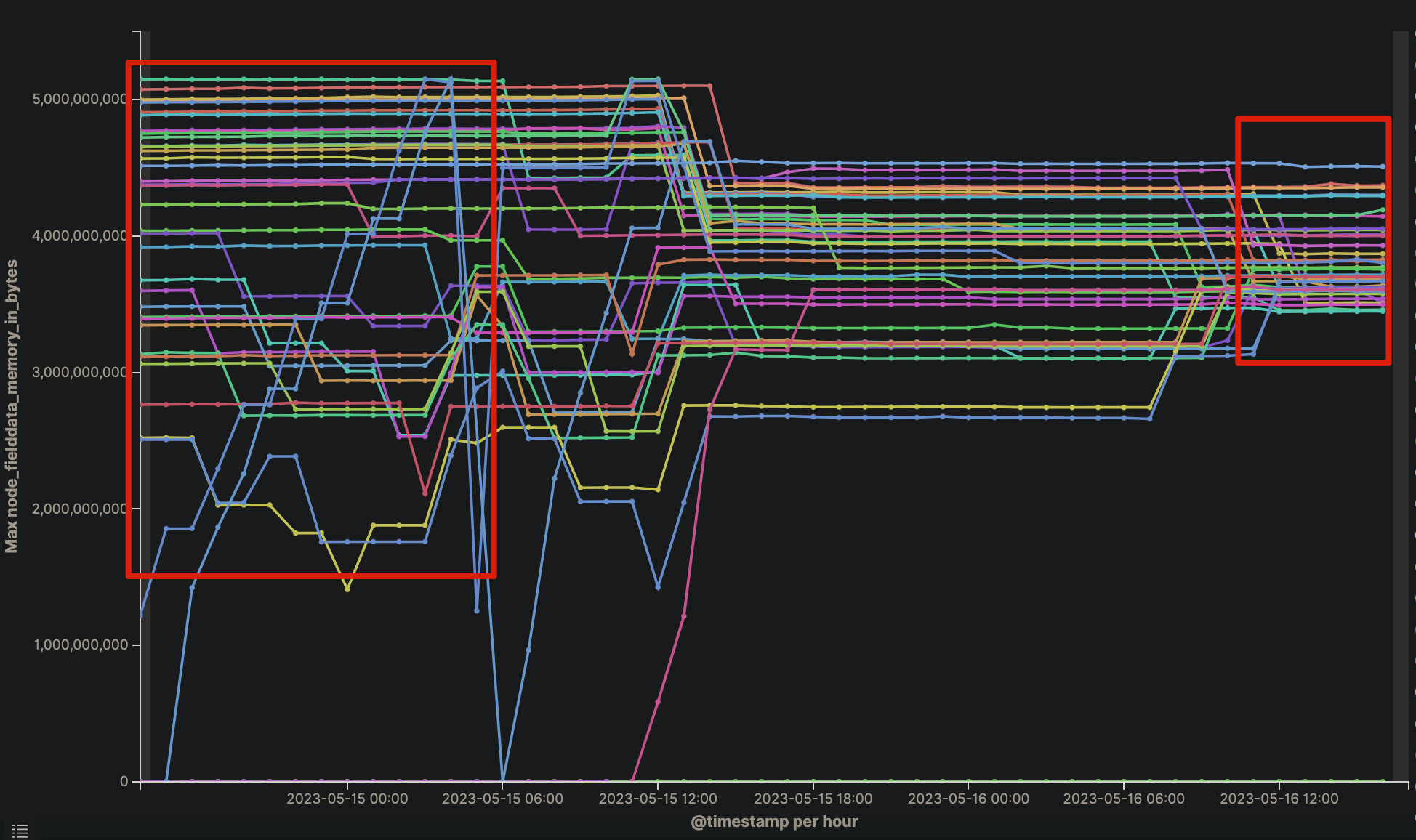
最终效果
未再出现长时间GC的情况
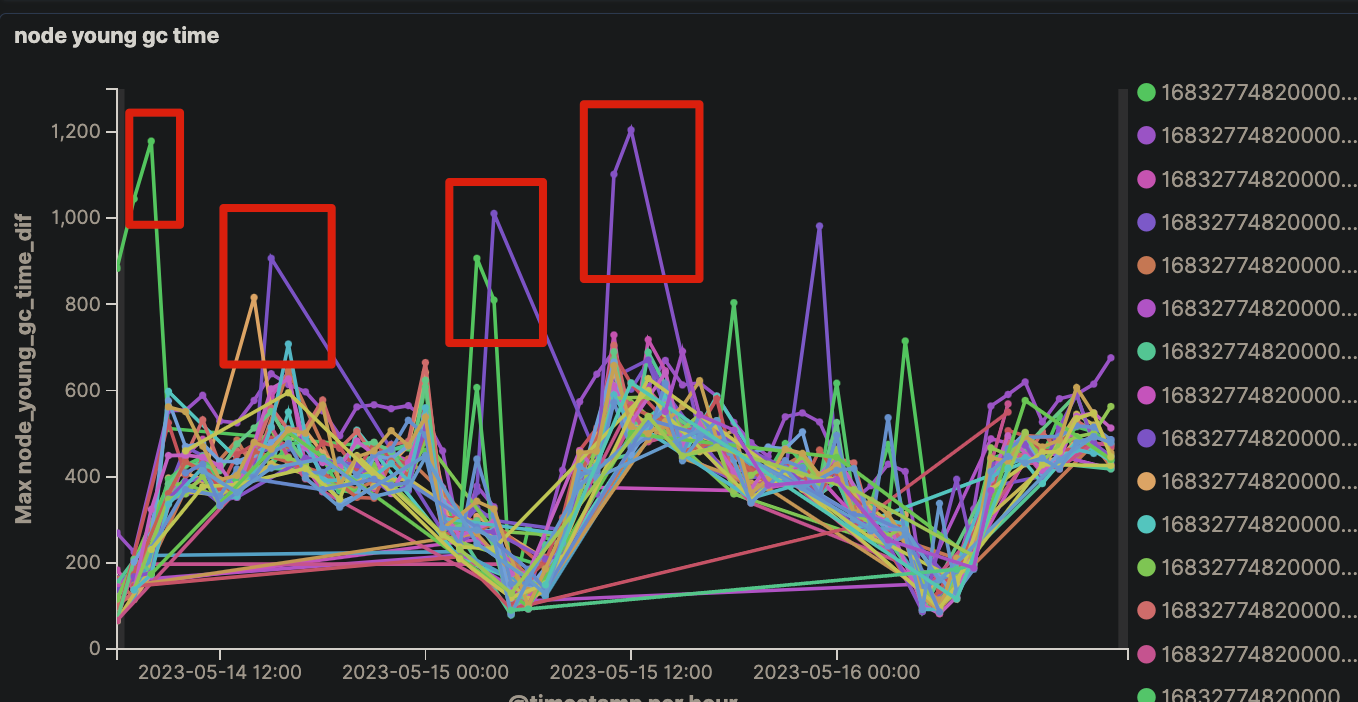
同时间段P90查询时延几秒级毛刺出现频率也大幅降低

问题三:磁盘IO过高
当前集群中的节点,IO util 普遍偏高,高峰期普遍在 60%以上,最大的节点达到91%,节点之间IO也不是很均衡
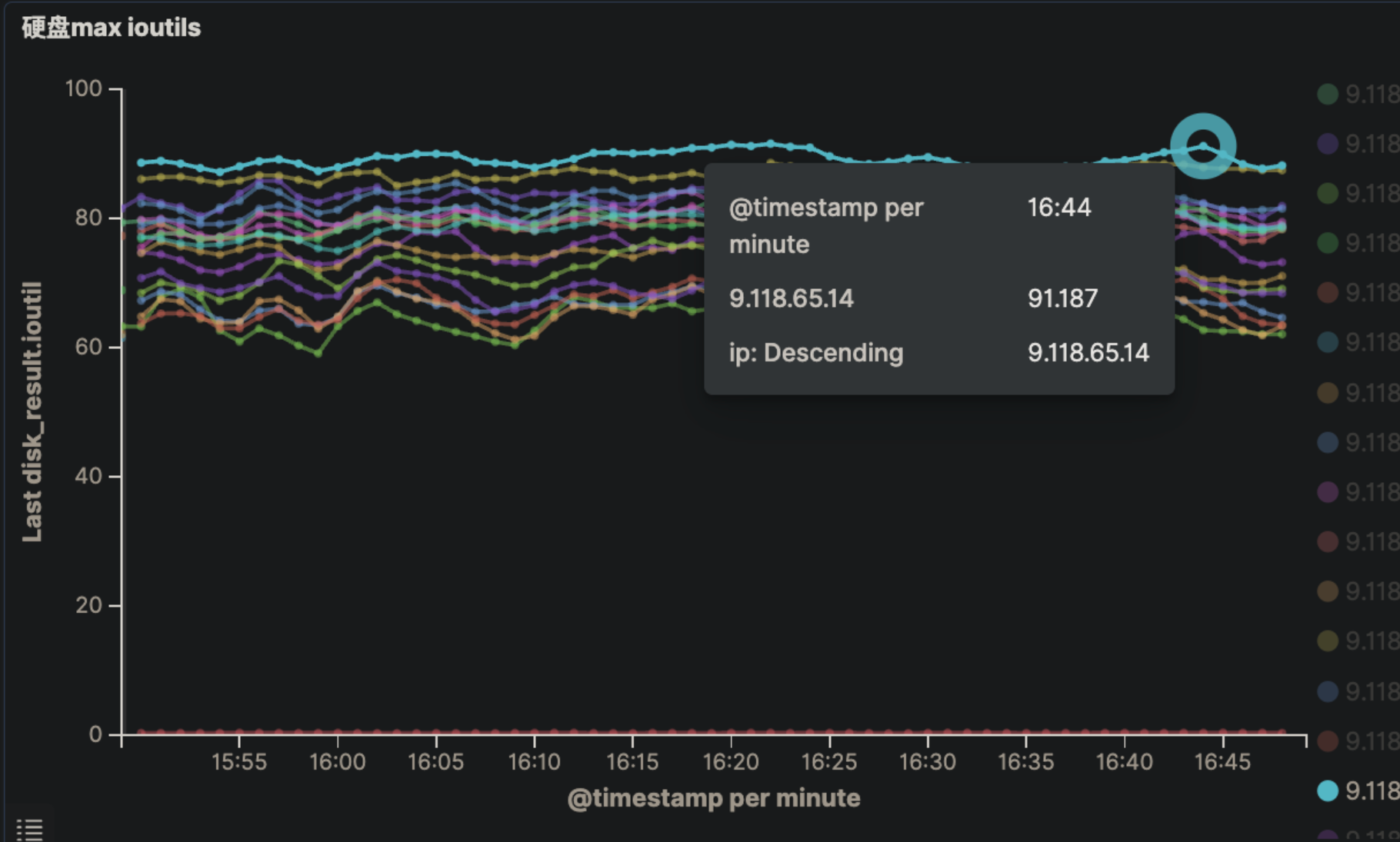
原因
原因是集群中分片容量大小差异较大,大的260GB+,小的1GB
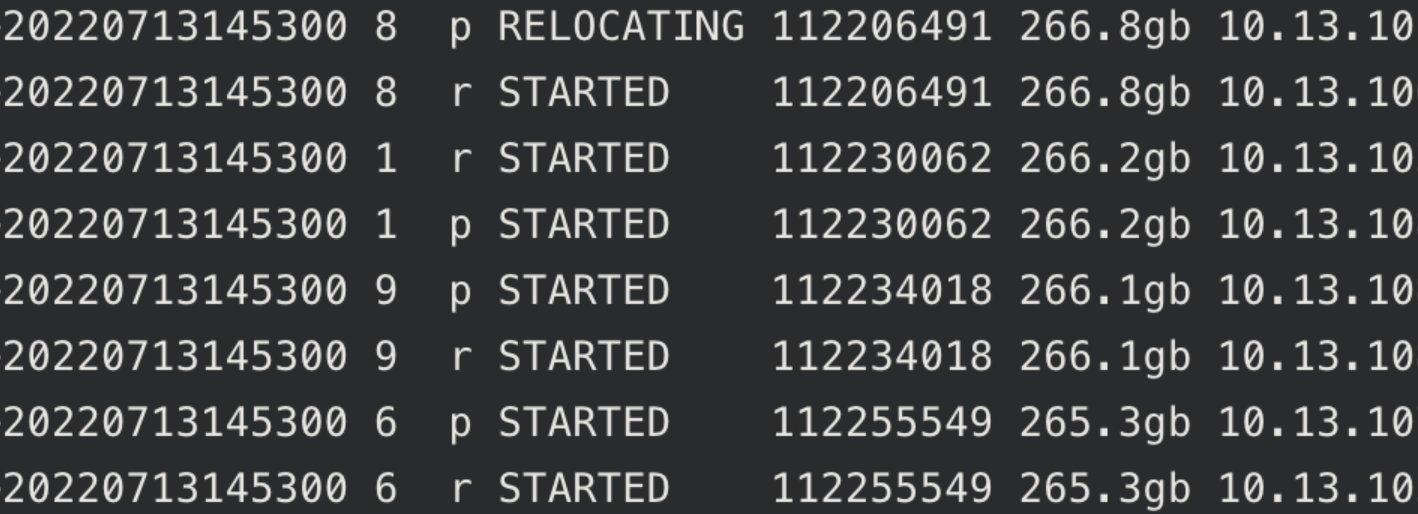
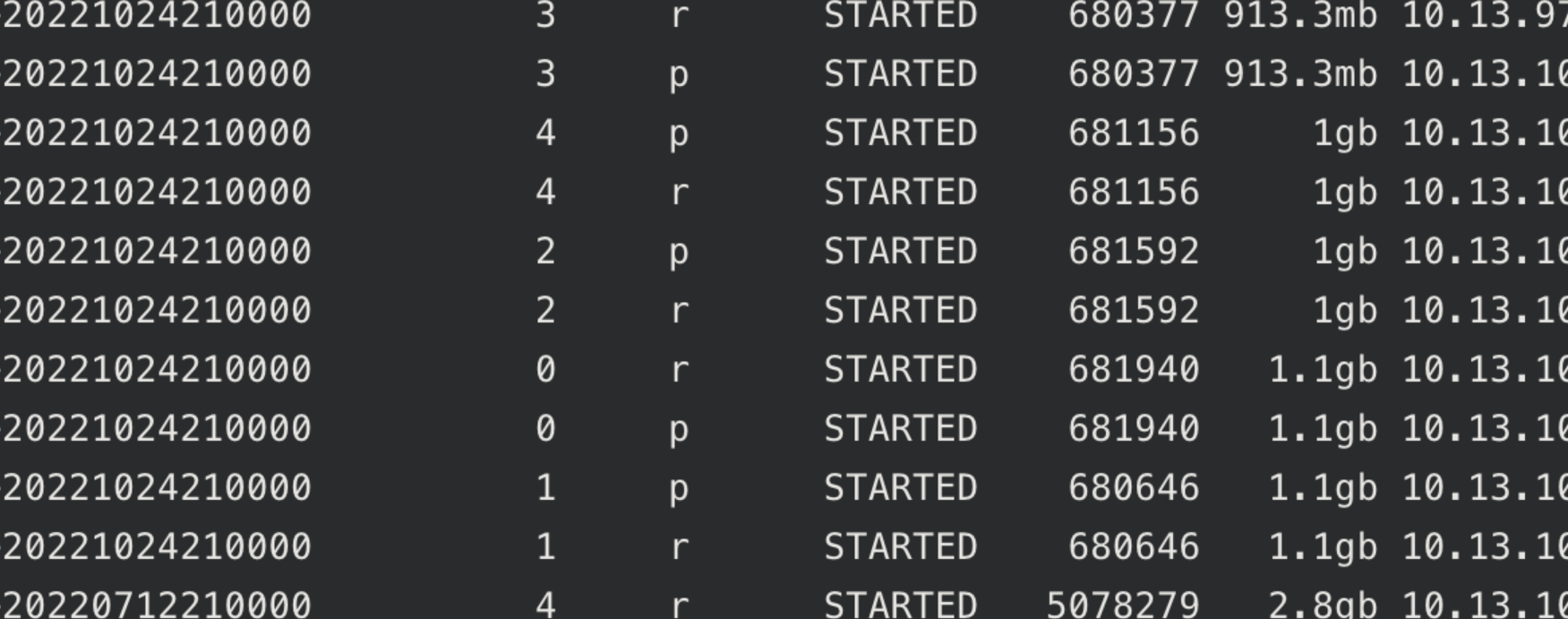
导致节点间磁盘使用率不均匀、IO不均匀
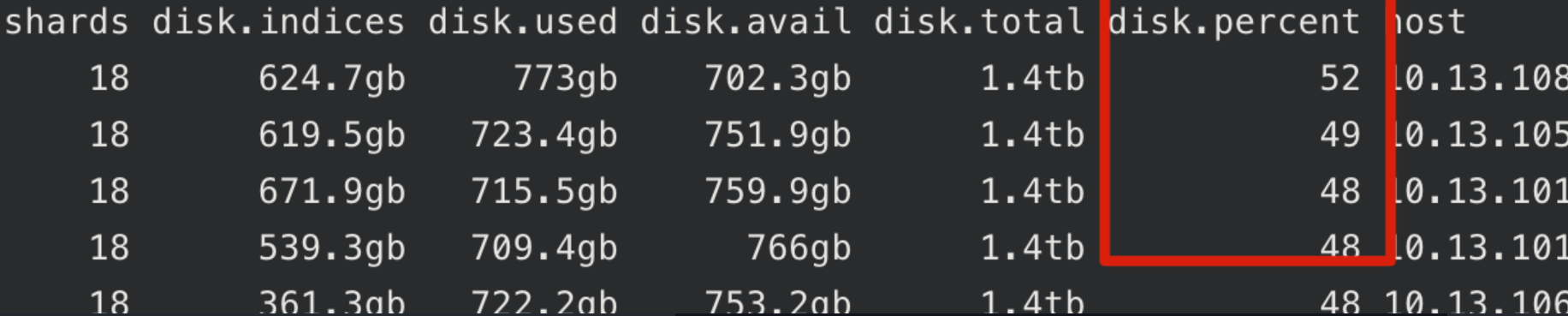

主要是读IO比较高,跟查询压力较大有关,且数据也是带id写入的,每次写入也会产生一次查询

优化方案
长期方案
- 扩容磁盘数,分摊IO压力
当前集群各个节点容量较大(1.5T),且只使用了一块盘
建议扩充每个节点的磁盘数(500 GB * 3块盘)
- 调整分片数,拆分容量较大的index
这一步需要在扩充完磁盘数,降低IO压力后才能做
对于当前单分片容量较大的index,增大分片数,使单个分片在20GB~50GB左右
同时考虑分片数为节点数的整数倍(40、80)