- 发展
- 知识点
- 腾讯AI
- 人脸技术
- 车辆技术
- 图像识别技术
- 文字识别技术
- 腾讯TI平台
- 发展趋势
- 人才岗位
发展
1950年,他那篇著名论文《计算机器与智能》的正式发表,里面有史以来 第一次触及到了“人工智能”,提出了“图灵测试”,这当中涉及了自动解释,和 自然语言的生成,作为判断智能的条件。1956年美国达特茅斯会议:“人工智能”概念诞生 人工智能(Artificial Intelligence,AI)是研究、开发用于模拟、延伸和扩展人的智能 的理论、方法、技术及应用系统的一门新技术科学。 人工智能的,主要 发展方向,分为三个层面: 分别是运算智能、感知智能、认知智能- 计算机具有
快速计算和记忆储存的能力 - 具备
视觉、听觉、触觉的感知能力:能听会说 、能看会认 - 能理解、思考、决策
- 计算机具有
知识点
人工智能(Artificial intelligence)人工智能亦称智械、机器智能,指由人制造出来的机器所表现出来的智能。通常人工智能是指通过普通计算机程序来呈现人类智能的技术。机器学习(Machine learning): 设计和分析一些让计算机可以自动“学习”的算法。机器学习是一类从数据中自动分析获得规律并利用规律对未知数据进行预测的算法深度学习(Deep learning): 深度学习是机器学习中一种基于对数据进行表征学习的算法。深度学习的好处是用非监督式或半监督式的特征学习和分层特征提取高效算法来替代手工获取特征。神经网络(NN)现代神经网络是一种非线性统计性数据建模工具,神经网络通常是通过一个基于数学统计学类型的学习方法得以优化,所以也是数学统计学方法的一种实际应用。监督学习(Supervised learning)机器学习的一种方法,可以由训练资料中学到 或建立一个模式(函数 / learning model), 并依此模式推测新的实例。无监督学习(Unsupervised learning)机器学习的一种方法,没有给定事先标记过的 训练示例,自动对输入的资料进行分类或分群- 监督、无监督:“有答案”去学习还是“没有答案”去学习
- 目前活体检测支持光线、读数、动作、静默等多种活体模式
- 动作活体: 皱纹
- 唇语活体: 数字和唇部口型
- 静默活体: 无需交互动作
- 通过检测
屏幕摩尔纹、屏幕边缘检测,通过大量活体和非活体的局部区域训练,实现客户不做动作, 也能判断活体
- 通过检测
- 光线活体: 屏幕发出
随机光信号同时采集图像,通过随机光不同的波长,照射脸部,验证 是否为人脸的三维形状和质感,再基于漫反射模型,算法先对人脸上的反射光增量进行建模,提取面部隐式含有的法向量信息,增强并重建人脸深度图。摄像头接收光信号序列,只有当前光特征、序列、面容特性全部匹配,并且验证采集的时效性,最后与防翻拍进行集合,全部匹配后才会返回成功结果。
- 人脸活体检测主要是通过识别活体上的生理信息来进行,它把生理信息作为生 命特征来区分用照片、硅胶、塑料等非生命物质伪造的生物特征。
- 介质攻击,类型可以分为三种:
2D屏幕攻击、3D立体攻击和降级攻击。- 降级攻击比较特殊,该攻击类型通过
镜面反射、投影、 注入等方式,破坏多模态数据之间的一致性,从而绕过部分活体模块,实现安全系统降级,达到攻击的目的 - 最具挑战性的就是高成本制作的高精头模/面具
- 降级攻击比较特殊,该攻击类型通过
- 介质攻击,类型可以分为三种:
- 发展
- 政策: 支持人工智能走向“泛在” 第四阶段*从2020年至今,人工智能被纳入“新基建”政策
- 需求: 智能应用场景持续涌现 第一,是将人口红利转化为创新红利的转型需求 第二,是超大规模且多样的应用场景**。 第三是抗疫加速了人工智能的应用。
- 供给侧: 智能产业生态不断丰富
- 腾讯正在从技术、场景和平台三个层
- 开源Angel 、ncnn 、TNN等 机器学习、深度学习平台,降低Al 开发门槛
- 腾讯正在从技术、场景和平台三个层
图像分割:- 语义分割:图像的每一个像素点属于哪一类的标签 -- 车、人、地面、天
- 实例分割:语义分割基础上,还需区分出同一类不同的个体 -- 几个人、几个车
- 全景分割:实例分隔基础上,对背景的每个像素点实现分类 --

应用: • 医学领域的脑部核磁共振图像与三维重建 • 遥感领域的定位卫星图像的道路和森林 • 交通领域的车辆轮廓提取
语音技术:- 自动语音识别技术(ASR):Automatic Speech Recognition
- 语音合成技术(TTS):(Text-To-Speech)技术,又称文语转换技术 应用场景:
- 语音识别:
- 语音合成:
- 声纹识别: 是生物识别技术的一种,也称为说话人识别,包括说话人辨认和 说话人确认。
- 声纹识别(Voice Print Recognition)
- 公安司法鉴定、 银行身份核对、证件防伪等
偏差&方差偏差的含义:偏差度量了学习算法的期望预测与真实结果的偏离程度,即刻画了学习算法本身的拟合能力。 个人理解:偏差度量的是单个模型的学习能力,而方差度量的是同一个模型在不同数据集上的稳定性。使偏差较小,即能够充分拟合数据,使方差较小,即使得数据扰动产生的影响小。偏差主导了泛化错误率;随着训练程度的加深,学习器的拟合能力逐渐增强,训练数据发生的扰动渐渐能被学习器学到,方差逐渐主导了泛化错误率Bias是用所有可能的训练数据集训练出的所有模型的输出的平均值与真实模型的输出值之间的差异。Variance是不同的训练数据集训练出的模型输出值之间的差异。- 降纬
一般常用的方法包括降维(PCA、ICA、LDA等)、图像方面的SIFT、Gabor、 HOG等、文本方面的词袋模型、词嵌入模型等
PCA:Principal Component Analysis (无监督)ICA:独立成分分析 (无监督)LDA:线性判别分析 (有监督)SIFT:即尺度不变特征变换,是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。Gabor: 特征是一种可以用来描述图像纹理信息的特征,Gabor 滤波器的频率和方向与人类的视觉系统类似,特别适合于纹理表示与判别。HOG: 方向梯度直方图(Histogram of Oriented Gradient, HOG) 特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子。HOG特征通过计算和统计图像局部区域的梯度方向直方图来构成特征 - 无监督&有监督
1、个人认为他们的区别在于
无监督学习一般是采用聚簇等算法来分类不同样本。而监督学习一般是利用教学值与实际输出值产生的误差,进行误差反向传播修改权值来完成网络修正的。但是无监督学习没有反向传播修改权值操作。 2、样本全部带标记/样本全部不带标记··· PS:部分带标记的是半监督学习 3、训练集有输入有输出是有监督,包括所有的回归算法分类算法,比如线性回归、决策树、神经网络、KNN、SVM等;训练集只有输入没有输出是无监督,包括所有的聚类算法,比如k-means 、PCA、 GMM等 - 狭义上的机器学习框架,包括 Scikit-learn、Spark MLlib、Hadoop Mahout
- 见深度学习框架有:
Caffe,CNTK(微软),PyTorch(脸书),Keras,MXNet(Apache)、TensorFlow(谷歌) 等

- 最常用的集中开源协议有: • GPL :GNU 通用公共许可协议 • LGPL :GNU 宽通用公共许可协议 • BSD : 伯克利软件分发许可协议 • MIT :MIT 许可协议之名源自麻省理工学院, 又称“X许可协议”或“X11许可协议” • Apache :Apache 许可协议 • MPL :Mozilla 公共许可协议
- Git - 开源的分布式版本控制系统 • GitHub:面向开源及私有软件项目的托管平 台 (世界上最大的代码托管平台) • GitLab:用于仓库管理系统的开源项目 (适合管理团队对仓库的访问) • Bitbucket:采用 Mercurial 做为分布式版本 控制系统 (无限制的磁盘空间可供使用) • CODING: 面向开发者的云端开发平台 (发布以腾讯云云服务器为基础的国内第一款 完全基于云端的 IDE 工具:Cloud Studio, ) • Gitee 码云:代码托管协作开发平台 (企业级代码托管服务)
- TPU && NPU
TPU是一款为机器学习而定制的芯片 提供15-30倍的性能提升,以及30-80倍的效率(性能/瓦特)提升NPU处理器专门为物联网人工智能而设计,用于加速神经网络的运算
- 提供动线分析能力
这里提供的动线分析能力包括
人体坐标轨迹、人体比对、人体检索、单摄像头ReID、跨摄像头 ReID、人体优选、人体聚类、多传感器信息融合 - 多技术关联能力 如人 货关系识别、多视图人体定位、多视图场景拼接等服务能力
腾讯AI
各类奖项了解下就行
- 人体人脸技术布局

人脸技术
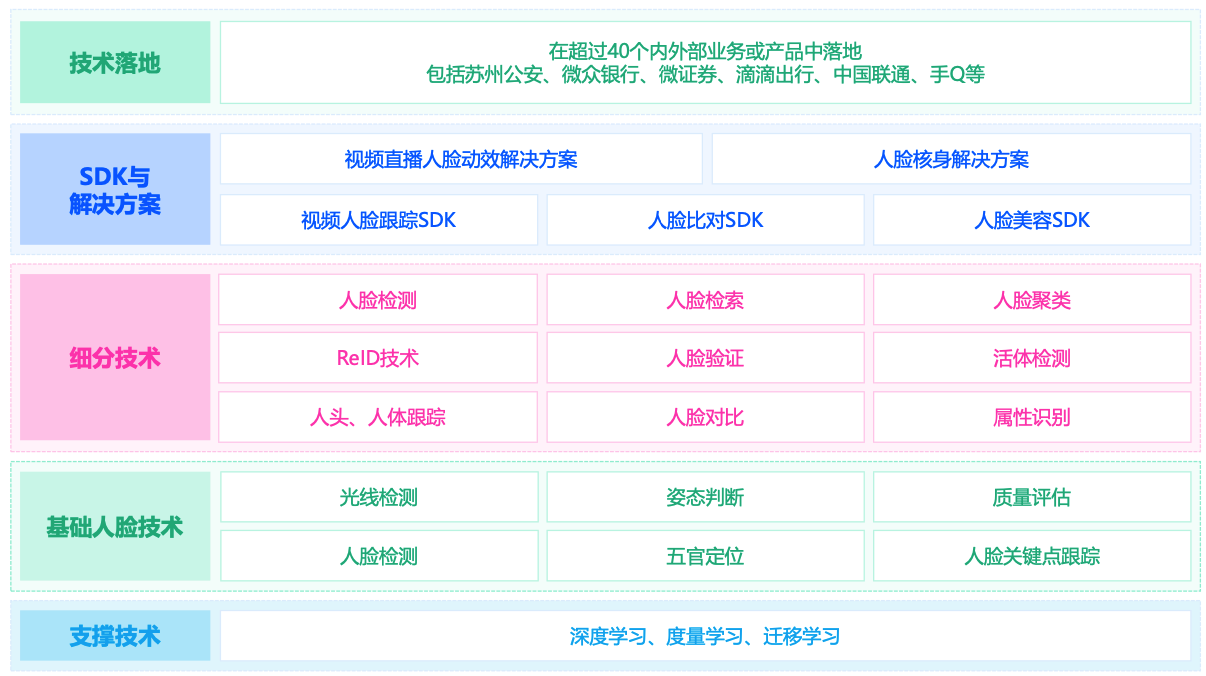
人脸检测: 腾讯优图提出的DSFD人脸检测算法,在世界上两个权威的人脸检测数据集WIDER FACE和FDDB上,均取得了第一五官定位: 90点五官定位,平均定位像素偏差 <1.5Px,业界领先 普通手机上运行平均耗时 <15ms模型数据 <2MB,可根据不同平台灵活配置,应用范围广人脸识别: 1:1的人脸验证技术 + 1:N的人脸检索技术LFW 99.80%刷新世界纪录1:1人脸核身,自拍对比身份证,十万分之一错误率下,通过率99%+ • 1:N人脸检索,安防场景,3000万规模测试库,Top1命中率95%以上 • 刷脸支付场景,人脸对比的错误率可以做到亿分之一以下人脸验证: RealFace 在谷歌联合建立的FaceForensics Benchmark上达到了综合结果业界第一,并且在Facebook主 办的Deepfake Detection Challenge公开榜单上达到Top1%,最终私有榜单上获得金牌 对于“人脸生成”伪造方式的检测精度高达99.961%; 对于“人脸编辑”伪造方式的检测精度可达到98.018%; 对于“人脸替换”伪造方式的检测精度可达到98.714%;人头人体检测跟踪: 多目标关联算法的设计与优化 近景场景的人体检测识别准确率高达99%,人头检测准确率可达 98.5%; 在复杂场景下的人体检测识别准确率可达96%,人头检测准确率可达 96%; 场景:地铁站ReID:- 人重识别(Person re-identification)也称行人再识别,是利用计算机视觉技术判断图像或者视频序列中是否存在特定行人的技术。广泛被认为是一个图像检索的子问题。 跨设备
- 刷 新了三项主流数据库记录,继旷视、云从之后,刷新
Duke,Market,CUHK三项主流数据库, 成果被CVPR2019接受 - 通用场景中: 轨迹检索准确率达到98%,召回率85%以上
车辆技术

- 多目标检测技术
刷新国际权威目标检测评测集
MOT17Det世界记录 - 多目标追踪技术
在国际权威交通场景数据集
KITTI上追踪效果多次刷新世界纪录 - 车辆属性识别技术 属性识别准确率>90%,车牌识别准确率>98%
- 车辆搜索技术 开源数据集VehicleID上刷新记录,业界领先 检索平均准确率mAP>80%
图像识别技术

- 优图DeepEye智能
鉴黄技术双模型级联架构 高效模型设计:DeepSmart 在 CPU上速度仅30ms/img 获AI领域顶级会议IJCAI会议(CCF-A 类)长文接受 《Towards Convolutional Neural Networks Compression via Global Error Reconstruction》 - 暴恐图片识别
- 货架商品识别
文字识别技术

- 通用OCR识别技术 国际权威的ICDAR 2015文本检测和识别评测中均刷新世界纪录
- OCR垂直场景技术 身份证、驾照等
腾讯TI平台
- AI落地面临的挑战
- 碎片化(场景、技术、厂商)
- 从0做机器学习太麻烦
- 从0交付AI应用太麻烦
- 应对挑战:
- 全栈AI平台,实现AI落地各环节要素的高效配合
- 业务AI平台,打造AI应用开发新模式的最佳实践

- TI DataTruth持续提升数据采集和数据标注能力
- 数据采集、算法应用、工程开发、边缘适配和应用集成这五项AI应用落地的关键能力, 解决了AI从模型到业务落地“最后一公里”的问题
自动学习AI 平台各模块之核心功能应用服务编排作为 AI 中台的调度中枢管理中心为AI平台 提供最全面的基础支撑与管理功能
发展趋势
- 人工智能未来发展的
十个趋势方向: 1)自动机器学习 2)无监督/弱监督学习 3)3D视觉应用 4)多模态融合 5)数字内容新范式 6)加速与边缘计算融合 7)类脑神经计算 8)算法公平 9)隐私保护 10)安全智能
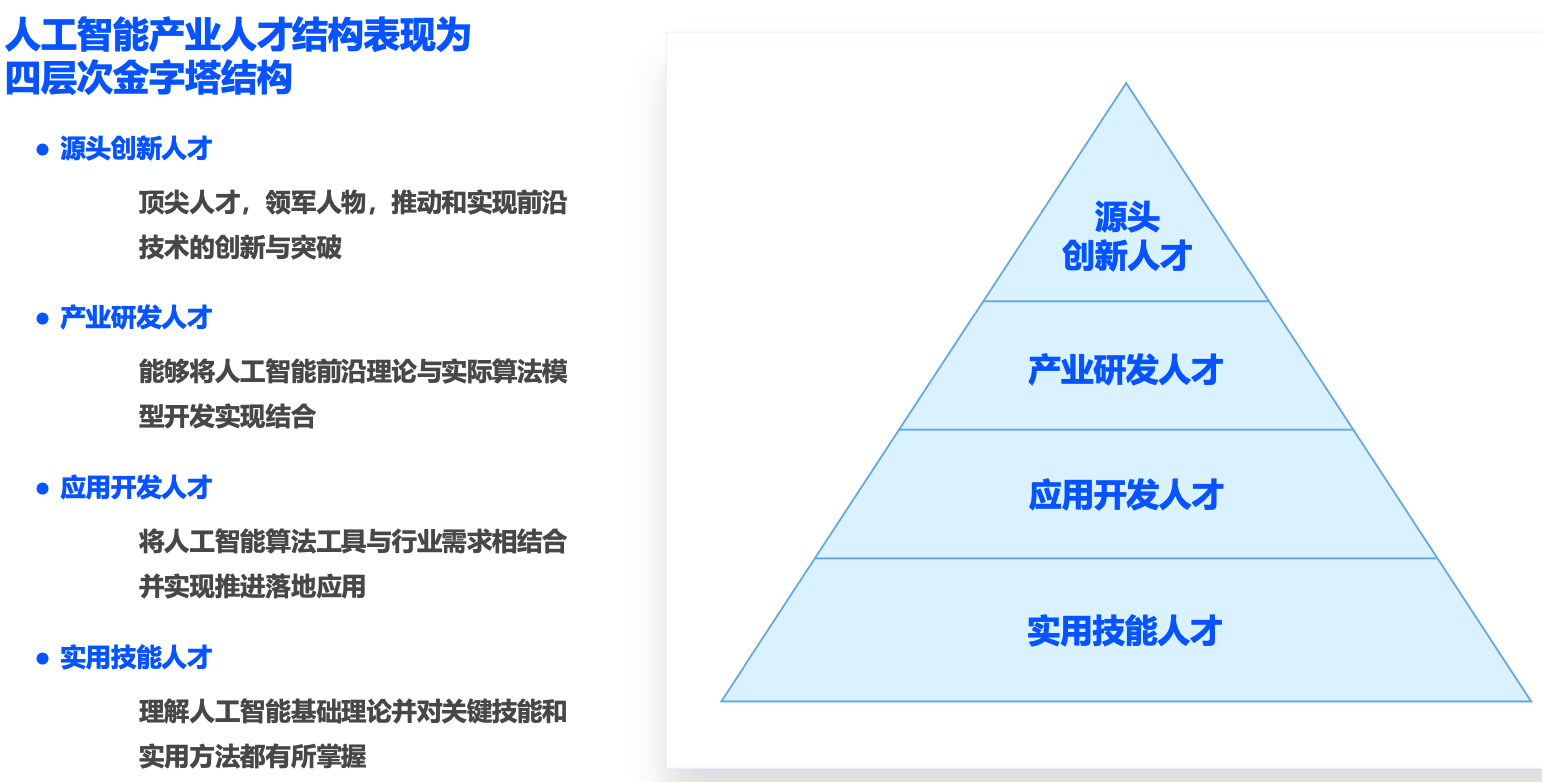
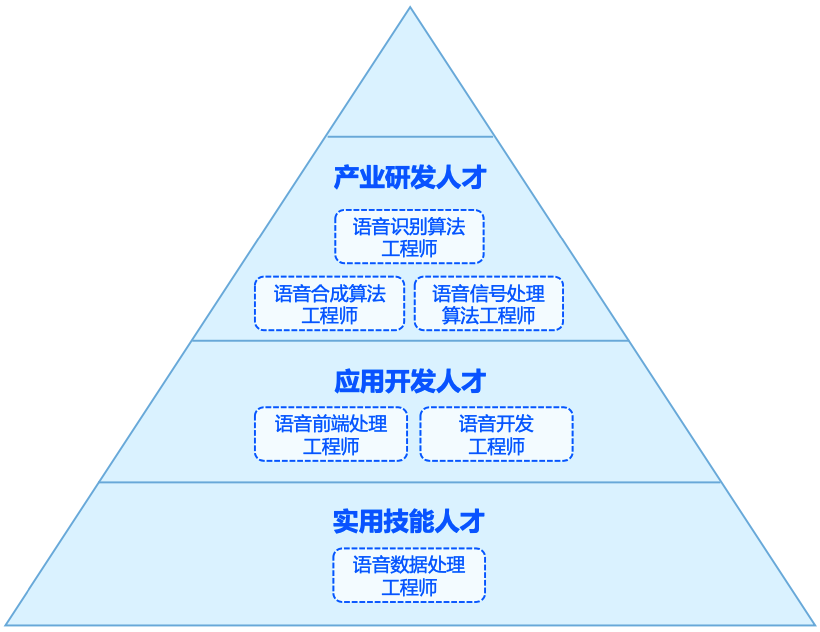
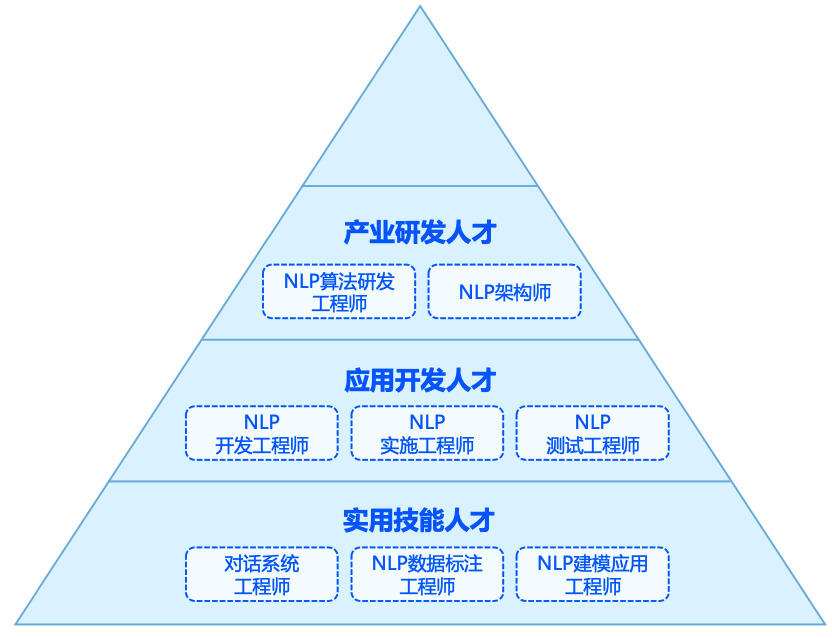
人才岗位
了解人才分层,和相关的大致能力要求
人才分层
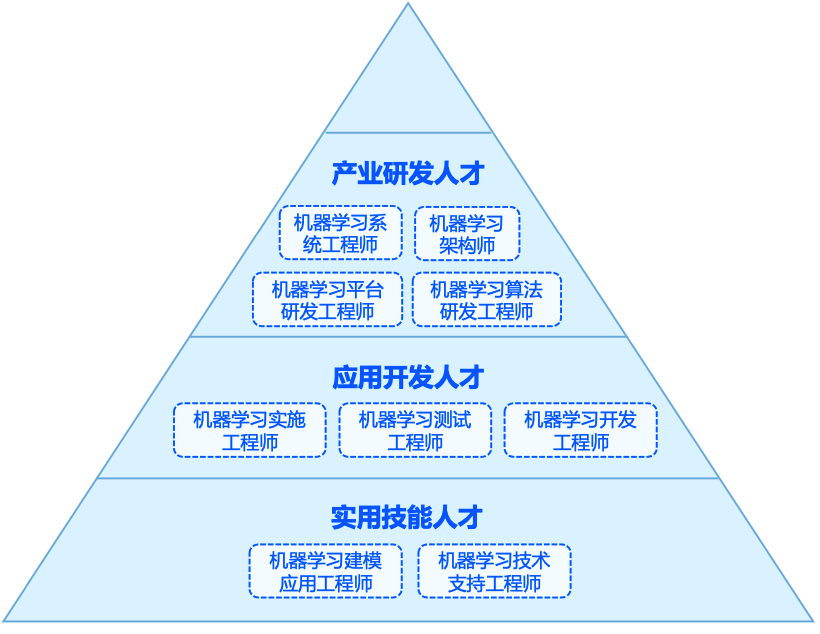
人才能力: 综合能力 专业知识能力 技能能力 工程实践能力- 智能芯片

- 机器学习
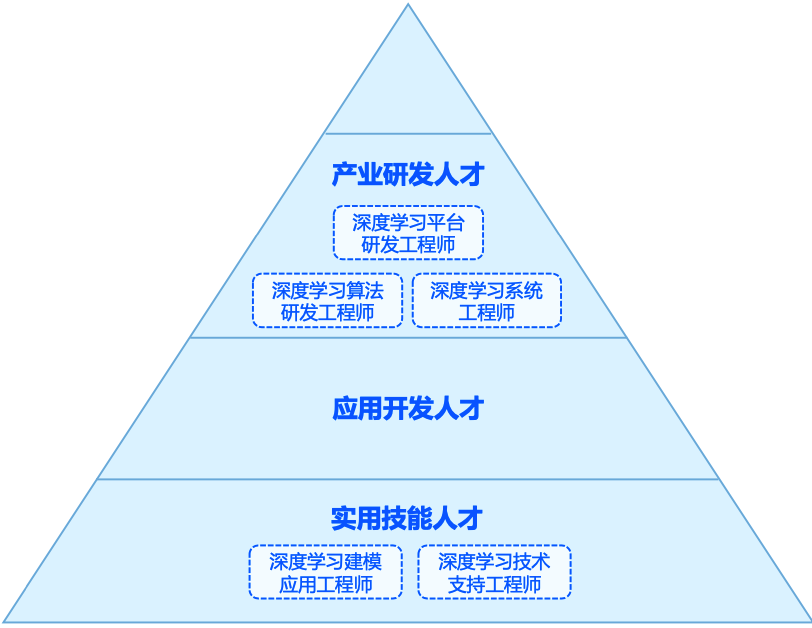
- 深度学习
- 语音识别
- NLP
- CV

- AI+工业
