系统:Windows 10 编辑器:JetBrains PyCharm Community Edition 2018.2.2 x64 pandas:1.1.5
- 这个系列讲讲Python的科学计算及可视化
- 今天讲讲pandas模块
- 抽取Df中两列构成一个字典
Part 1:场景描述
- 已知df1,包括6列,
"time", "pos", "value1", "value2", "value3", "value4 - 抽取其中的
pos和value1列构成一个字典
由df生成字典
Part 2:代码
import pandas as pddict_1 = {"time": ["2019-11-02", "2019-11-03", "2019-11-04", "2019-11-05",
"2019-12-02", "2019-12-03", "2019-12-04", "2019-12-05"],
"pos": ["A", "A", "C", "D", "E", "E", "G", "H"],
"value1": [10, 20, 30, 40, 50, 60, 70, 80],
"value2": [100, 200, 300, 400, 500, 600, 700, 800],
"value3": [50, 20, 30, 90, 50, 60, 80, 80],
"value4": [10, 30, 90, 40, 60, 60, 70, 80]}df_1 = pd.DataFrame(dict_1, columns=["time", "pos", "value1", "value2", "value3", "value4"])
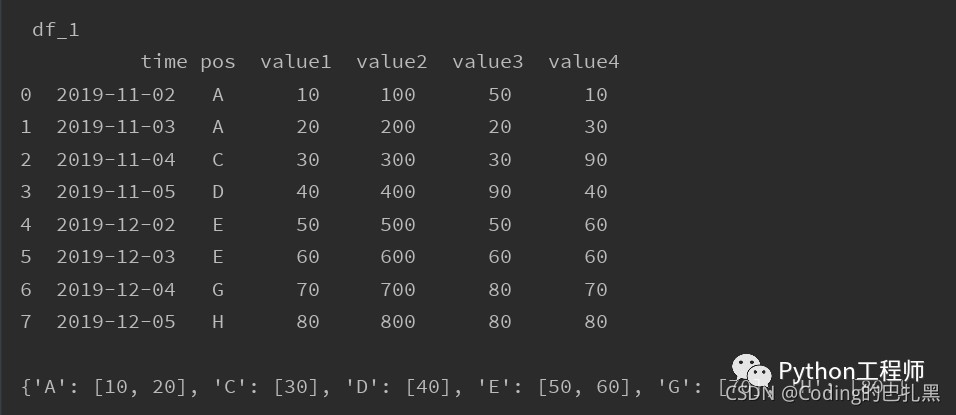
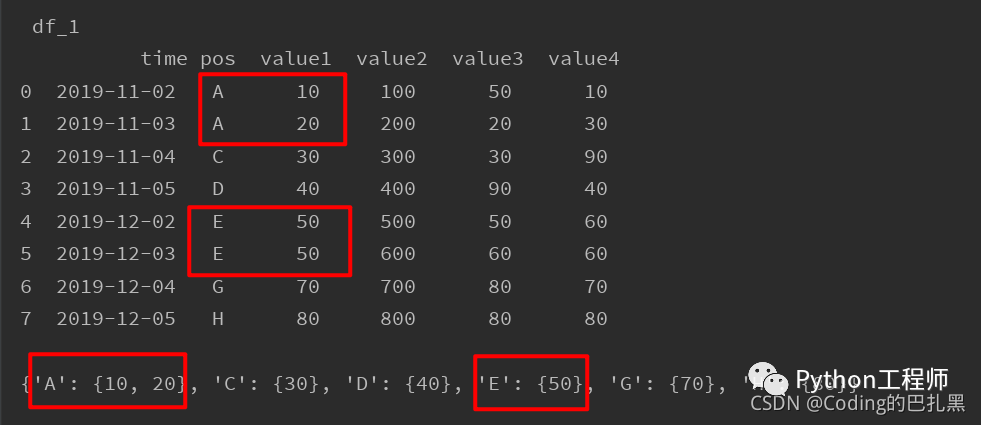
print("\n", "df_1", "\n", df_1, "\n")dict_map = df_1.groupby('pos')['value1'].apply(list).to_dict()
print(dict_map)
print("\n分步骤")
step_1 = df_1.groupby('pos')
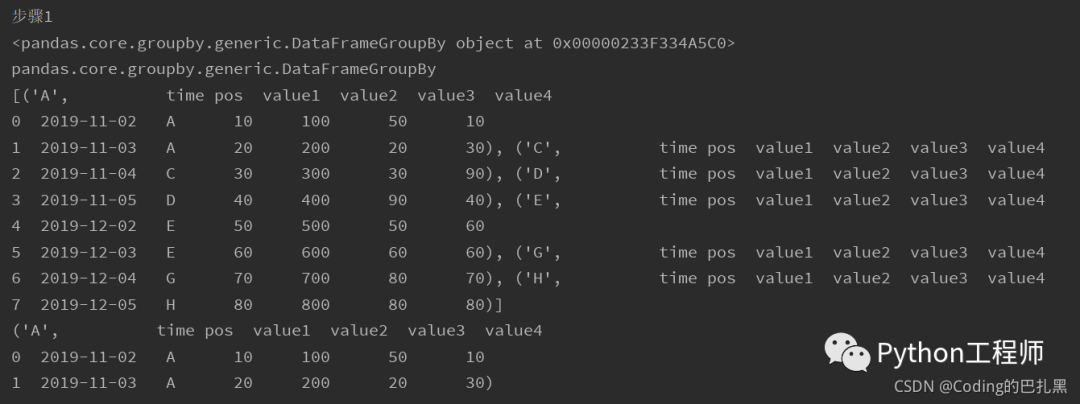
print("\n步骤1")
print(step_1)
print(type(step_1))
print(list(step_1))
print(list(step_1)[0])step_2 = step_1['value1']
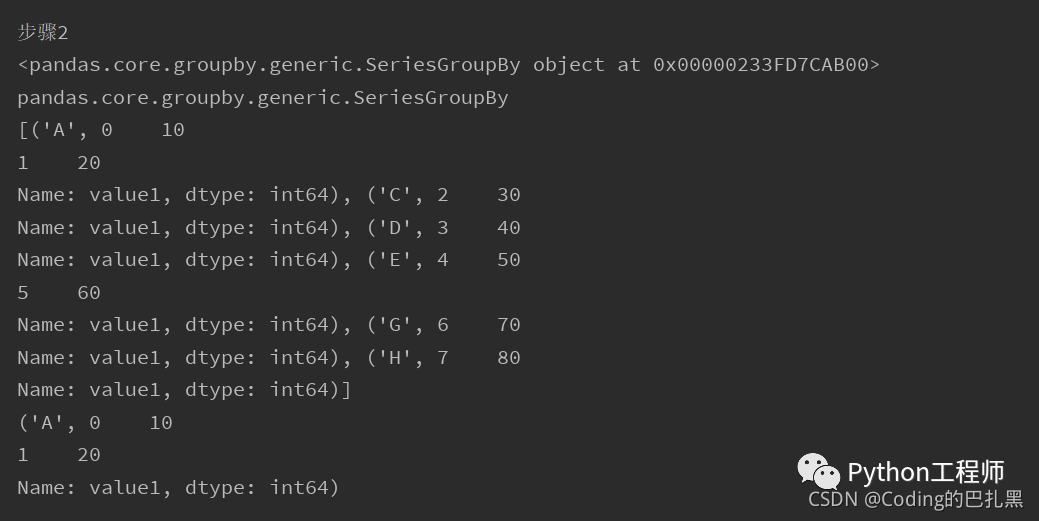
print("\n步骤2")
print(step_2)
print(type(step_2))
print(list(step_2))
print(list(step_2)[0])step_3 = step_2.apply(list)
print("\n步骤4")
print(step_3)
print(type(step_3))
step_4 = step_3.to_dict()
print("\n步骤3")
print(step_4)
print(type(step_4))
代码截图


Part 3:输出结果

Part 4:部分代码解读
dict_map = df_1.groupby('pos')['value1'].apply(list).to_dict()- dict_map = df_1.groupby(字典键对应列名)[字典值对应列名].apply(字典值组织方式).to_dict()
- 将字典值组织方式改为集合,
dict_map = df_1.groupby('pos')['value1'].apply(set).to_dict(),结果如下,修改了一下数据源,可以实现去重的效果。同样的数据源两种方式差别如下
dict_map = df_1.groupby(‘pos’)[‘value1’].apply(set).to_dict()
dict_map = df_1.groupby(‘pos’)[‘value1’].apply(list).to_dict()

本文为原创作品,欢迎分享朋友圈