👆点击“博文视点Broadview”,获取更多书讯


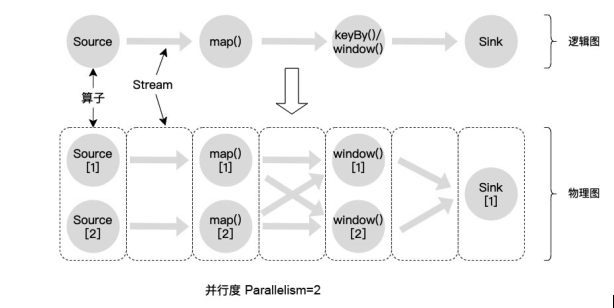
Flink是如何处理一个流数据计算任务的,整个流程如图所示,分为以下几个步骤:
(1)Flink先将用户编写的应用程序转换为逻辑图(Logical Graph),逻辑图的节点代表算子,边代表算子要计算的输入/输出数据流。
(2)Flink会对生成的逻辑图进行一些优化,比如将两个或多个连续相同的算子组合成算子链(Operator Chain),算子链内的算子可以直接传递数据,这样可以减少数据在节点之间传输产生的开销,这一步的作用类似数据库系统中优化器的作用。
(3)Flink会将逻辑图转换为真正可执行的物理图(Physical Graph),物理图的节点是任务(Task),边依然表示输入/输出的数据流。任务是指封装了一个或多个算子的并行执行的实例。
(4)Flink将具体的任务调度到集群中的执行节点上,并行执行任务。Flink支持对任务配置并行度(Parallelism),即一个任务的并行实例数。
内容摘自《深入理解分布式系统》,作者唐伟志,曾任网易游戏、腾讯基础架构工程师。

本书主要讲解分布式系统常用的基础知识、算法和案例,经笔者对文献海洋中晦涩艰深的原理和算法进行提炼,辅以图示和代码,并结合实际经验进行分析总结而成。通过阅读本书,读者可以快速、轻松地掌握分布式系统的基本原理,以及Paxos或Raft共识算法,并通过典型的案例学习如何设计大型分布式系统。
本书首先介绍什么是分布式系统、分布式系统带来的挑战,以及如何对分布式系统进行建模,这部分内容偏向概念性介绍。接着介绍了分布式数据的基础知识,包括数据分区技术、数据复制技术、CAP定理、一致性模型和隔离级别,尝试厘清一些十分容易混淆的术语,比如一致性、线性一致性、最终一致性和一致性算法等。本书还介绍了分布式系统的核心算法——Paxos和Raft算法,不仅补充了大量图示进行讲解,还从零实现了一个Paxos算法。此外,本书分析了常见的分布式事务,并讨论了分布式系统中的时间问题,整理了一些实际发生的编程陷阱。最后结合一些对工业界产生重大影响的论文或开源系统,学习前人在设计大型分布式系统时的思路、取舍和创新。

扫码了解本书详情!


